Prompt, Plan, Extract: Zero-Shot Agentic LLMs Workflows for Lung Pathology Extraction from Clinical Narratives
Pith reviewed 2026-06-26 17:47 UTC · model grok-4.3
The pith
Zero-shot agentic LLMs populate 13 CAP fields from lung reports at 0.893 Micro-F1 without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
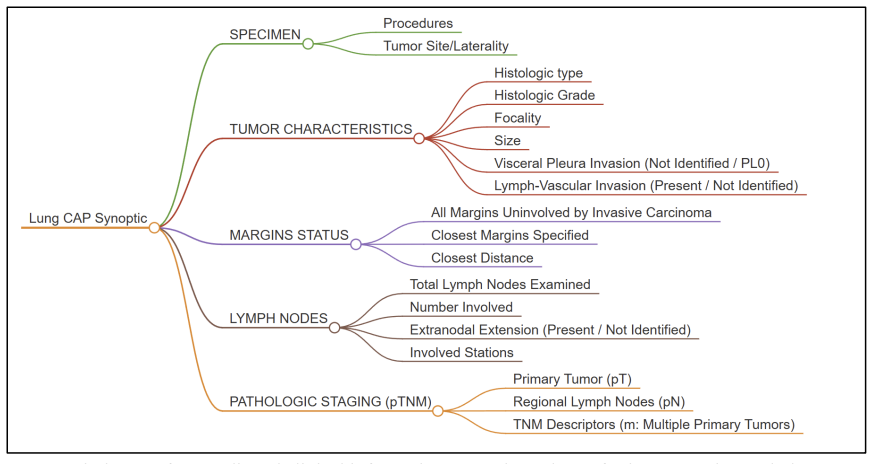
By applying a zero-shot agentic workflow to five open-source LLMs, the study populates the 13 College of American Pathologists synoptic fields from lung resection pathology reports, with the best model (GPT-OSS-20B) achieving a Micro-F1 of 0.893 and recall of 0.949, closely approaching the supervised GatorTron baseline's 0.960 while accurately handling complex relations such as Pathologic Stage.
What carries the argument
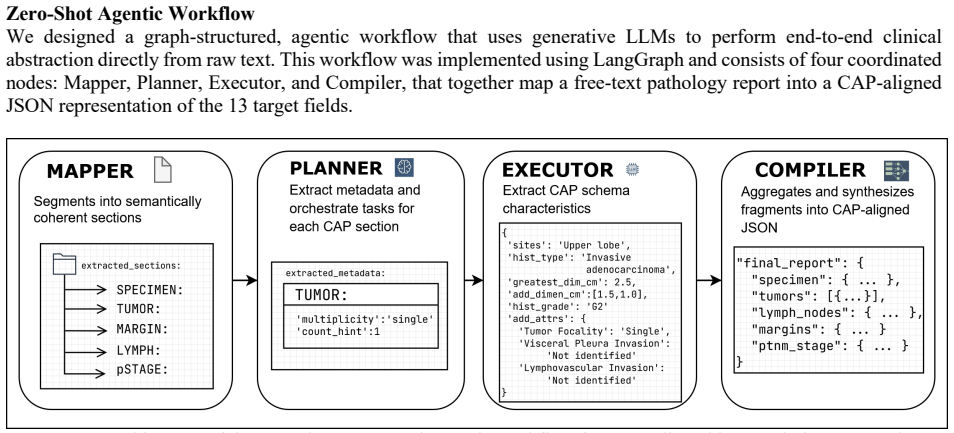
The zero-shot agentic workflow that decomposes extraction into prompt, plan, and extract steps using generative LLMs to fill the 13 CAP fields directly from narrative text.
If this is right
- The workflow avoids the need for expensive manual annotation required by supervised NER-RE pipelines.
- Cascading failures from missed upstream entities in traditional methods are reduced.
- Open-source models can serve as a low-cost solution for extracting lung pathology information.
- Complex relations such as pathologic stage can be extracted accurately without task-specific training.
Where Pith is reading between the lines
- The same workflow structure could be tested on pathology reports from other cancer sites to check transferability.
- Integration with existing registry systems might reduce the time and cost of manual abstraction.
- Performance on rarer or more complex fields could be measured separately to identify remaining gaps.
Load-bearing premise
The novel registry-aligned evaluation framework produces an unbiased, apples-to-apples comparison between the zero-shot LLM outputs and the supervised GatorTron baseline on the 13 CAP fields.
What would settle it
A manual gold-standard review on a new collection of lung resection reports where the best zero-shot model's Micro-F1 on the 13 fields falls substantially below 0.893.
Figures
read the original abstract
Information extraction from pathology reports is essential for cancer staging, tumor registry population. Yet key data remains embedded in narrative reports, making manual extraction labor-intensive and error-prone. Traditional supervised Natural Language Processing pipelines address this through fully supervised Named Entity Recognition and Relation Extraction, but require expensive manual annotation and suffer cascading failures when upstream entities are missed. In this study, we developed a zero-shot, agentic workflow, and evaluated five open-source generative Large Language Models (LLMs) to populate 13 College of American Pathologists synoptic fields from lung resection pathology reports. We compared them against a state-of-the-art supervised GatorTron NER-RE baseline using a novel, registry-aligned evaluation framework. The baseline achieved Micro-F1of 0.960, while the best zero-shot model (GPT-OSS-20B) achieved Micro-F1 of 0.893 (recall: 0.949), accurately extracting complex relations like Pathologic Stage without task-specific training. These results suggest that open-source, zero-shot agentic LLMs show great potential as a low-cost solution for extracting lung pathology information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a zero-shot agentic LLM workflow that populates 13 College of American Pathologists (CAP) synoptic fields from lung resection pathology reports. Five open-source generative LLMs are evaluated against a supervised GatorTron NER-RE baseline using a novel registry-aligned evaluation framework, reporting Micro-F1 scores of 0.960 (baseline) versus 0.893 (best LLM, GPT-OSS-20B with recall 0.949), and concludes that such models show potential as a low-cost alternative for lung pathology information extraction.
Significance. If the evaluation framework produces a fair, apples-to-apples comparison, the work would demonstrate that zero-shot agentic LLMs can achieve competitive performance on structured clinical extraction tasks without task-specific training or annotation, offering a practical low-cost alternative to supervised pipelines for cancer registry population and staging.
major comments (3)
- [Abstract] Abstract: the central performance comparison (Micro-F1 0.893 vs 0.960) is presented without any dataset size, number of reports, definitions of the 13 CAP fields, or description of the agentic workflow steps (planning/extraction), rendering the claim unverifiable from the provided text and blocking assessment of reproducibility.
- [Evaluation Framework] Evaluation Framework (implied in methods/results): the registry-aligned framework is load-bearing for attributing the performance gap to the zero-shot approach, yet no explicit description is given of how LLM-generated outputs are parsed, string-matched, or semantically aligned versus the entity/relation-level errors of the NER-RE baseline; if matching rules differ (e.g., allowing multi-step correction or looser normalization for generative outputs), the scores are not directly comparable.
- [Results] Results: no error analysis or breakdown by field (especially for complex relations like Pathologic Stage) is supplied, which is required to substantiate the claim that the LLM 'accurately extracting complex relations' without task-specific training.
minor comments (1)
- [Abstract] Abstract: 'Micro-F1of' is missing a space before 0.960.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance comparison (Micro-F1 0.893 vs 0.960) is presented without any dataset size, number of reports, definitions of the 13 CAP fields, or description of the agentic workflow steps (planning/extraction), rendering the claim unverifiable from the provided text and blocking assessment of reproducibility.
Authors: We agree that the abstract should be more self-contained to support verifiability. In the revised manuscript we will expand the abstract to report the number of lung resection pathology reports in the dataset, provide a brief enumeration or definition of the 13 CAP synoptic fields, and include a concise description of the agentic workflow steps (prompt, plan, extract). revision: yes
-
Referee: [Evaluation Framework] Evaluation Framework (implied in methods/results): the registry-aligned framework is load-bearing for attributing the performance gap to the zero-shot approach, yet no explicit description is given of how LLM-generated outputs are parsed, string-matched, or semantically aligned versus the entity/relation-level errors of the NER-RE baseline; if matching rules differ (e.g., allowing multi-step correction or looser normalization for generative outputs), the scores are not directly comparable.
Authors: The Methods section introduces the registry-aligned evaluation framework, but we acknowledge that the parsing, string-matching, and semantic alignment steps for LLM outputs require more explicit detail to demonstrate comparability with the NER-RE baseline. We will revise the Methods to add a dedicated subsection describing the exact procedures for parsing generative outputs, normalization rules, and matching criteria, and we will explicitly state that identical alignment rules are applied to both the LLM and baseline outputs. revision: yes
-
Referee: [Results] Results: no error analysis or breakdown by field (especially for complex relations like Pathologic Stage) is supplied, which is required to substantiate the claim that the LLM 'accurately extracting complex relations' without task-specific training.
Authors: We agree that an error analysis and field-level breakdown would strengthen the results section and better support the claim regarding complex relations. In the revised manuscript we will add an error analysis subsection that includes per-field Micro-F1 scores and qualitative discussion of errors, with focused attention on Pathologic Stage and other complex relations. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study reporting Micro-F1 scores from zero-shot LLM agentic workflows on 13 CAP fields, compared directly to an external supervised GatorTron NER-RE baseline via a described registry-aligned evaluation. No equations, derivations, fitted parameters, or self-referential definitions appear in the chain; the performance delta is measured against an independent model rather than constructed from the LLM outputs themselves. The novel evaluation framework is presented as a methodological choice without reducing to prior self-citations or ansatzes that would force the result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lung resection pathology reports contain the 13 College of American Pathologists synoptic fields in narrative text that can be extracted by LLMs.
Reference graph
Works this paper leans on
-
[1]
specialized medical report expert
In the Mapper node, the model is instructed to behave as a “specialized medical report expert” and to segment each lung tumor pathology report into canonical clinical sections (SPECIMEN, TUMOR, MARGINS, LYMPH NODES, PATHOLOGIC STAGE), returning the full, unaltered section text without summarization or omission. 2. The Planner node operated as an “oncology...
2009
-
[2]
Clinical Relation Extraction Using Transformer-based Models
Yang X, Yu Z, Guo Y, Bian J, Wu Y. Clinical Relation Extraction Using Transformer-based Models. arXiv [csCL]. Published online July 19, 2021. http://arxiv.org/abs/2107.08957 6. Devlin J, Chang MW, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional Transformers for language understanding. arXiv [csCL]. Published online October 10, 2018. http://ar...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.