VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
Pith reviewed 2026-06-27 07:08 UTC · model grok-4.3
The pith
A depth-weighted 2D reprojection loss trains 3D motion diffusion models from video alone and nearly matches full 3D supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VideoMDM is a diffusion-based framework that trains 3D human motion priors directly from accurate 2D poses extracted from monocular videos without any 3D ground truth. A pretrained 2D-to-3D lifter provides approximate 3D pose sequences that serve as a noisy teacher: these are diffused, denoised by the model in 3D, and supervised in 2D by reprojecting the prediction and comparing against accurate keypoints. Under mild assumptions a depth-weighted 2D reprojection loss is equivalent in expectation to direct 3D supervision, and standard 3D motion regularizers are adapted to this 2D setting.
What carries the argument
depth-weighted 2D reprojection loss that equates in expectation to direct 3D supervision
If this is right
- The model learns a coherent 3D motion manifold throughout training instead of lifting only at inference time.
- On HumanML3D the FID reaches 0.88, close to the 0.54 of a fully 3D-supervised MDM.
- Velocity consistency and over-parameterized representation alignment regularizers can be adapted to the 2D supervision setting.
- On real video datasets the generated motions are consistently preferred by human evaluators.
Where Pith is reading between the lines
- The same equivalence could allow scaling motion training to far larger collections of unlabeled video.
- Other 3D generative tasks that currently require expensive capture data might adopt similar 2D reprojection supervision.
- If the lifter signal degrades during training, performance would be expected to plateau below the 3D-supervised ceiling.
Load-bearing premise
The mild assumptions hold under which the depth-weighted 2D reprojection loss equals direct 3D supervision in expectation, and the pretrained lifter continues to supply an informative noisy teacher signal.
What would settle it
A mathematical derivation or empirical measurement showing that the expected value of the depth-weighted 2D reprojection loss differs from the expected 3D loss by a non-zero amount when the stated mild assumptions are satisfied.
Figures


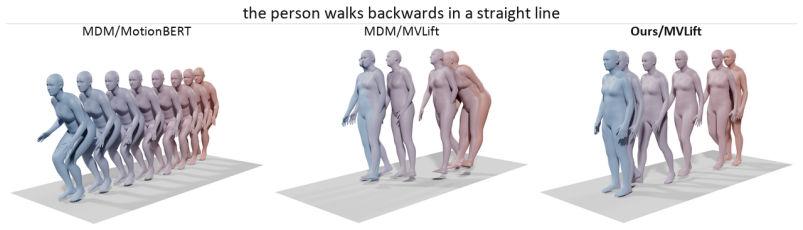
read the original abstract
We introduce VideoMDM, a diffusion-based framework that trains 3D human motion priors directly from accurate 2D poses extracted from monocular videos, without any 3D ground truth. A pretrained 2D-to-3D lifter provides approximate 3D pose sequences that serve as a noisy teacher: these are diffused, denoised by the model in 3D, and supervised in 2D by reprojecting the prediction and comparing against accurate keypoints. We show that, under mild assumptions, a depth-weighted 2D reprojection loss is equivalent in expectation to direct 3D supervision, and we adapt standard 3D motion regularizers - velocity consistency and over-parameterized representation alignment - to this 2D setting. Unlike methods that lift 2D to 3D only at inference, VideoMDM learns a coherent 3D motion manifold during training. On HumanML3D it nearly closes the gap to fully 3D-supervised MDM (FID 0.88 vs 0.54); On real video datasets Fit3D and NBA the method learns to generate motions consistently preferred by humans, with strong quantitative results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoMDM, a diffusion-based framework for generating 3D human motions trained directly from accurate 2D keypoints extracted from monocular videos, without any 3D ground truth. A pretrained 2D-to-3D lifter supplies noisy 3D pose sequences that are diffused and denoised in 3D space, with supervision provided via a depth-weighted 2D reprojection loss against the accurate 2D keypoints. The central claim is that this loss is equivalent in expectation to direct 3D supervision under mild assumptions; the method also adapts velocity consistency and representation alignment regularizers to the 2D setting. Experiments report FID 0.88 on HumanML3D (vs. 0.54 for fully 3D-supervised MDM) and human preference on Fit3D and NBA video datasets.
Significance. If the equivalence result and empirical claims hold, the work would be significant for enabling scalable training of 3D motion diffusion models from abundant unlabeled video data rather than scarce 3D motion capture, while learning a coherent 3D manifold during training rather than lifting only at inference.
major comments (2)
- [Abstract] Abstract: The claim that 'under mild assumptions, a depth-weighted 2D reprojection loss is equivalent in expectation to direct 3D supervision' is load-bearing for the entire training justification, yet the abstract (and by extension the manuscript) provides neither an explicit list of the assumptions nor any derivation showing how the expectation identity is obtained. Without these, the observed FID gap cannot be attributed to the claimed equivalence, and the training objective's validity as a 3D proxy remains unverified.
- [§4] §4 (Experiments): No error bars, standard deviations, or details of the experimental protocol (number of runs, random seeds, exact FID computation) are reported for the HumanML3D FID numbers (0.88 vs 0.54) or the human preference studies on Fit3D/NBA. This makes it impossible to assess whether the gap to MDM is statistically meaningful or reproducible.
minor comments (2)
- The manuscript should include a dedicated subsection or appendix deriving the equivalence (with all assumptions stated) so that readers can verify the conditions under which the depth-weighted reprojection loss matches 3D supervision in expectation.
- Notation for the depth-weighting term and the lifter noise model should be introduced formally with equations rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important areas for clarification and rigor. We address each below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'under mild assumptions, a depth-weighted 2D reprojection loss is equivalent in expectation to direct 3D supervision' is load-bearing for the entire training justification, yet the abstract (and by extension the manuscript) provides neither an explicit list of the assumptions nor any derivation showing how the expectation identity is obtained. Without these, the observed FID gap cannot be attributed to the claimed equivalence, and the training objective's validity as a 3D proxy remains unverified.
Authors: We agree that the abstract and main text should make the assumptions and derivation more explicit to support the central claim. The current manuscript states the result under 'mild assumptions' but does not enumerate them or derive the expectation identity in the main body. In the revision we will (1) list the assumptions explicitly in a new paragraph of Section 3, (2) provide a concise derivation (or clear reference to the supplementary derivation) showing why the depth-weighted 2D reprojection loss equals direct 3D supervision in expectation, and (3) update the abstract to reference these assumptions. This change directly addresses the concern that the training objective's validity remains unverified. revision: yes
-
Referee: [§4] §4 (Experiments): No error bars, standard deviations, or details of the experimental protocol (number of runs, random seeds, exact FID computation) are reported for the HumanML3D FID numbers (0.88 vs 0.54) or the human preference studies on Fit3D/NBA. This makes it impossible to assess whether the gap to MDM is statistically meaningful or reproducible.
Authors: We acknowledge that the reported results lack error bars, standard deviations, and full experimental-protocol details, which limits assessment of statistical significance and reproducibility. In the revised manuscript we will add: (i) standard deviations computed over at least three independent runs with distinct random seeds for all HumanML3D FID scores, (ii) explicit description of the FID computation protocol (including feature extractor, number of samples, and distance metric), (iii) the number of runs and seeds used, and (iv) for the human preference studies, the number of raters, inter-rater agreement, and any statistical significance tests. These additions will allow readers to evaluate whether the observed gap is meaningful. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper claims to show an equivalence (under mild assumptions) between a depth-weighted 2D reprojection loss and direct 3D supervision, but this is presented as a derived mathematical result rather than a self-definitional identity or a fitted quantity renamed as a prediction. The loss itself is defined directly from accurate 2D keypoints extracted from video, with no equations or self-citation chains that reduce the reported FID or human-preference results to the inputs by construction. No load-bearing self-citations, uniqueness theorems from the same authors, or smuggled ansatzes are evident. The derivation chain is self-contained against external benchmarks such as comparison to fully 3D-supervised MDM and evaluation on real video datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Alliegro, Y . Siddiqui, T. Tommasi, and M. Nießner. Polydiff: Generating 3d polygonal meshes with diffusion models, 2023. URLhttps://arxiv.org/abs/2312.11417
arXiv 2023
-
[2]
X. Bie, W. Guo, S. Leglaive, L. Girin, F. Moreno-Noguer, and X. Alameda-Pineda. Hit- dvae: Human motion generation via hierarchical transformer dynamical vae, 2022. URL https://arxiv.org/abs/2204.01565
arXiv 2022
-
[3]
Bi´nkowski, D
M. Bi´nkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying MMD GANs. In International Conference on Learning Representations, 2018. URL https://openreview. net/forum?id=r1lUOzWCW
2018
-
[4]
G. Bradski. The OpenCV Library.Dr . Dobb’s Journal of Software Tools, 2000
2000
-
[5]
Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y . Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields, 2019. URLhttps://arxiv.org/abs/1812.08008
Pith/arXiv arXiv 2019
-
[6]
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, and G. Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18000–18010, 2023
2023
-
[7]
Deitke, R
M. Deitke, R. Liu, M. Wallingford, H. Ngo, O. Michel, A. Kusupati, A. Fan, C. Laforte, V . V oleti, S. Y . Gadre, E. VanderBilt, A. Kembhavi, C. V ondrick, G. Gkioxari, K. Ehsani, L. Schmidt, and A. Farhadi. Objaverse-xl: a universe of 10m+ 3d objects. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, R...
2023
-
[8]
H.-S. Fang, J. Li, H. Tang, C. Xu, H. Zhu, Y . Xiu, Y .-L. Li, and C. Lu. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time.IEEE Trans. Pattern Anal. Mach. Intell., 45(6):7157–7173, June 2023. ISSN 0162-8828. doi: 10.1109/TPAMI.2022.3222784. URLhttps://doi.org/10.1109/TPAMI.2022.3222784
-
[9]
Fieraru, M
M. Fieraru, M. Zanfir, S.-C. Pirlea, V . Olaru, and C. Sminchisescu. Aifit: Automatic 3d human- interpretable feedback models for fitness training. InThe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021
2021
-
[10]
R. Gao, A. Holynski, P. Henzler, A. Brussee, R. Martin-Brualla, P. Srinivasan, J. T. Barron, and B. Poole. Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024
Pith/arXiv arXiv 2024
-
[11]
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, E. Byrne, Z. Chavis, J. Chen, F. Cheng, F.-J. Chu, S. Crane, A. Dasgupta, J. Dong, M. Escobar, C. Forigua, A. Gebreselasie, S. Haresh, J. Huang, M. M. Islam, S. Jain, R. Khirodkar, D. Kukreja, K. J. Liang, J.-W. Liu, S. Majumder, Y . Mao, ...
arXiv 2024
-
[12]
C. Guo, X. Zuo, S. Wang, S. Zou, Q. Sun, A. Deng, M. Gong, and L. Cheng. Action2motion: Conditioned generation of 3d human motions. InProceedings of the 28th ACM International Conference on Multimedia, pages 2021–2029, 2020
2021
-
[13]
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5152–5161, 2022
2022
-
[14]
C. Guo, Y . Mu, M. G. Javed, S. Wang, and L. Cheng. Momask: Generative masked modeling of 3d human motions, 2023. URLhttps://arxiv.org/abs/2312.00063
arXiv 2023
-
[15]
R. Guo, H. Pi, Z. Shen, Q. Shuai, Z. Hu, Z. Wang, Y . Dong, R. Hu, T. Komura, S. Peng, and X. Zhou. Motion-2-to-3: Leveraging 2d motion data for 3d motion generations. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14305–14316, October 2025
2025
-
[16]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models, 2020. URL https: //arxiv.org/abs/2006.11239
Pith/arXiv arXiv 2020
-
[17]
S.-E. Hong, S. Lim, J. Hwang, M. Chang, and H. Kang. Bipo: Bidirectional partial occlusion network for text-to-motion synthesis, 2025. URLhttps://arxiv.org/abs/2412.00112
arXiv 2025
-
[18]
Jiang, P
T. Jiang, P. Lu, L. Zhang, N. Ma, R. Han, C. Lyu, Y . Li, and K. Chen. Rtmpose: Real-time multi-person pose estimation based on mmpose, 2023. URL https://arxiv.org/abs/2303. 07399
2023
-
[19]
Kapon, G
R. Kapon, G. Tevet, D. Cohen-Or, and A. H. Bermano. Mas: Multi-view ancestral sampling for 3d motion generation using 2d diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1965–1974, 2024
1965
-
[20]
K. Karunratanakul, K. Preechakul, S. Suwajanakorn, and S. Tang. Guided motion diffusion for controllable human motion synthesis, 2023. URLhttps://arxiv.org/abs/2305.12577
arXiv 2023
-
[21]
3D Gaussian Splatting for Real-Time Radiance Field Rendering,
B. Kerbl, G. Kopanas, T. Leimkuehler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4), July 2023. ISSN 0730-0301. doi: 10.1145/3592433. URLhttps://doi.org/10.1145/3592433
-
[22]
T. Kynkäänniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila. Improved precision and recall metric for assessing generative models.CoRR, abs/1904.06991, 2019
arXiv 1904
-
[23]
J. Li, Y . Yuan, D. Rempe, H. Zhang, C. Lu, J. Kautz, and U. Iqbal. Coin: Control-inpainting diffusion prior for human and camera motion estimation. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[24]
J. Li, J. Cao, H. Zhang, D. Rempe, J. Kautz, U. Iqbal, and Y . Yuan. Genmo: Generative models for human motion synthesis.arXiv preprint arXiv:2505.01425, 2025
arXiv 2025
-
[25]
J. Li, C. K. Liu, and J. Wu. Lifting motion to the 3d world via 2d diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17518–17528, 2025
2025
-
[26]
M. Liu, C. Xu, H. Jin, L. Chen, M. Varma T, Z. Xu, and H. Su. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization.Advances in Neural Information Processing Systems, 36:22226–22246, 2023. 11
2023
-
[27]
M. Liu, R. Shi, L. Chen, Z. Zhang, C. Xu, X. Wei, H. Chen, C. Zeng, J. Gu, and H. Su. One-2- 3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10072–10083, 2024
2024
-
[28]
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023
2023
-
[29]
Z. Liu, Y . Feng, M. J. Black, D. Nowrouzezahrai, L. Paull, and W. Liu. Meshdiffusion: Score- based generative 3d mesh modeling, 2023. URLhttps://arxiv.org/abs/2303.08133
arXiv 2023
-
[30]
A. Macario Barros, M. Michel, Y . Moline, G. Corre, and F. Carrel. A comprehensive survey of visual slam algorithms.Robotics, 11(1), 2022. ISSN 2218-6581. doi: 10.3390/robotics11010024. URLhttps://www.mdpi.com/2218-6581/11/1/24
-
[31]
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. Amass: Archive of motion capture as surface shapes, 2019. URLhttps://arxiv.org/abs/1904.03278
Pith/arXiv arXiv 2019
-
[32]
Y . Mu, X. Zuo, C. Guo, Y . Wang, J. Lu, X. Wu, S. Xu, P. Dai, Y . Yan, and L. Cheng. Gsd: View-guided gaussian splatting diffusion for 3d reconstruction, 2024. URL https://arxiv. org/abs/2407.04237
arXiv 2024
-
[33]
H. Nam, G. Kwon, G. Y . Park, and J. C. Ye. Contrastive denoising score for text-guided latent diffusion image editing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9192–9201, 2024
2024
-
[34]
C. Peng, I. Sobol, M. Tomizuka, K. Keutzer, C. Xu, and O. Litany. A lesson in splats: Teacher- guided diffusion for 3d gaussian splats generation with 2d supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[35]
E. Pinyoanuntapong, M. U. Saleem, P. Wang, M. Lee, S. Das, and C. Chen. Bamm: Bidirectional autoregressive motion model, 2024. URLhttps://arxiv.org/abs/2403.19435
arXiv 2024
-
[36]
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
Pith/arXiv arXiv 2022
-
[37]
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents, 2022. URLhttps://arxiv.org/abs/2204.06125
Pith/arXiv arXiv 2022
-
[38]
B. Roessle, N. Müller, L. Porzi, S. Rota Bulò, P. Kontschieder, A. Dai, and M. Nießner. L3dg: Latent 3d gaussian diffusion. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400711312. doi: 10.1145/3680528.3687699. URLhttps://doi.org/10.1145/3680528.3687699
-
[39]
M. Shi, K. Aberman, A. Aristidou, T. Komura, D. Lischinski, D. Cohen-Or, and B. Chen. Motionet: 3d human motion reconstruction from monocular video with skeleton consistency. ACM Transactions on Graphics, 40(1):1–15, Sept. 2020. ISSN 1557-7368. doi: 10.1145/ 3407659. URLhttp://dx.doi.org/10.1145/3407659
-
[40]
R. Shi, H. Chen, Z. Zhang, M. Liu, C. Xu, X. Wei, L. Chen, C. Zeng, and H. Su. Zero123++: a single image to consistent multi-view diffusion base model.arXiv preprint arXiv:2310.15110, 2023
Pith/arXiv arXiv 2023
-
[41]
S. Shin, J. Kim, E. Halilaj, and M. J. Black. WHAM: Reconstructing world-grounded humans with accurate 3D motion. InIEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2024
2024
-
[42]
R. C. Smith and P. Cheeseman. On the representation and estimation of spatial uncer- tainty.The International Journal of Robotics Research, 5(4):56–68, 1986. doi: 10.1177/ 027836498600500404. URLhttps://doi.org/10.1177/027836498600500404
- [43]
-
[44]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Pith/arXiv arXiv 2010
-
[45]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations, 2021. URL https://arxiv. org/abs/2011.13456
Pith/arXiv arXiv 2021
-
[46]
Tevet, S
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-or, and A. H. Bermano. Human motion diffusion model. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=SJ1kSyO2jwu
2023
-
[47]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning. InProceedings of the 31st International Conference on Neural Information Processing Sys- tems, NIPS’17, page 6309–6318, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
2017
-
[48]
B. Wandt, J. J. Little, and H. Rhodin. ElePose: Unsupervised 3D Human Pose Estimation by Predicting Camera Elevation and Learning Normalizing Flows on 2D Poses . In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6625–6635, Los Alami- tos, CA, USA, June 2022. IEEE Computer Society. doi: 10.1109/CVPR52688.2022.00652. URLhtt...
-
[49]
J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y . Zhao, D. Liu, Y . Mu, M. Tan, X. Wang, W. Liu, and B. Xiao. Deep high-resolution representation learning for visual recognition, 2020. URL https://arxiv.org/abs/1908.07919
arXiv 2020
-
[50]
Y . Wang, Z. Wang, L. Liu, and K. Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild videos. InEuropean Conference on Computer Vision, pages 467–487. Springer, 2024
2024
-
[51]
Z. Wang, C. Lu, Y . Wang, F. Bao, C. LI, H. Su, and J. Zhu. Prolificdreamer: High- fidelity and diverse text-to-3d generation with variational score distillation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8406–8441. Curran Associates, Inc., 2023. URL ...
2023
-
[52]
K. Xie, J. Lorraine, T. Cao, J. Gao, J. Lucas, A. Torralba, S. Fidler, and X. Zeng. Latte3d: Large-scale amortized text-to-enhanced3d synthesis. InEuropean Conference on Computer Vision, pages 305–322. Springer, 2024
2024
-
[53]
X. Zeng, A. Vahdat, F. Williams, Z. Gojcic, O. Litany, S. Fidler, and K. Kreis. Lion: Latent point diffusion models for 3d shape generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[54]
Zhang, Z
M. Zhang, Z. Cai, L. Pan, F. Hong, X. Guo, L. Yang, and Z. Liu. Motiondiffuse: Text-driven human motion generation with diffusion model, 2022. URL https://arxiv.org/abs/2208. 15001
2022
- [55]
- [56]
-
[57]
W. Zhu, X. Ma, Z. Liu, L. Liu, W. Wu, and Y . Wang. Motionbert: A unified perspective on learning human motion representations. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[58]
Q. Zou, S. Yuan, S. Du, Y . Wang, C. Liu, Y . Xu, J. Chen, and X. Ji. Parco: Part-coordinating text-to-motion synthesis, 2024. URLhttps://arxiv.org/abs/2403.18512. 13 A Weights for 3D to 2D Loss Equivalence In standard DDPM and DDIM training, given a sample x∼p and denoiser output ˆx, the reconstruc- tion loss is the mean squared error: L3d =E x∼p ∥ˆx−x∥ ...
arXiv 2024
-
[59]
J Explicit HumanML Channel Partitioning HumanML3D’s representation [13] is composed of:
EPnP solver and Levenberg-Marquardt pose refinement, both with default parameters. J Explicit HumanML Channel Partitioning HumanML3D’s representation [13] is composed of:
-
[60]
1 channel for angular velocity around the y-axis, 2 channels for root velocity in the XZ plane, 1 channel for root height
-
[61]
3 channels per non-root joint, representing X (root coordinate frame) Y (global) and Z (root coordinate frame)
-
[62]
6 channels per non-root joint, representing the 6D continuous rotations of the joints in relation to the rest pose angle (T-shape human), each joint rotation is calculated as the normalized displacement from its ancestor
-
[63]
3 channels per joint (including root) representing the per-joint velocity
-
[64]
For the NBA dataset with only 2 foot joints we replicate these flags per foot
4 channels representing the 4 foot contact flags. For the NBA dataset with only 2 foot joints we replicate these flags per foot. So in total our x is composed of AJ = 4+(J−1)×3 channels and r of BJ = (J−1)×6+J×3+4 channels. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.