Explainable AI for Mental Health Prediction in Drug-Affected Populations with Dragonfly Algorithm and GAN Oversampling
Pith reviewed 2026-06-26 09:22 UTC · model grok-4.3
The pith
A Dragonfly Algorithm optimized XGBoost model with GAN oversampling predicts mental health in drug-affected populations at 94.17% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
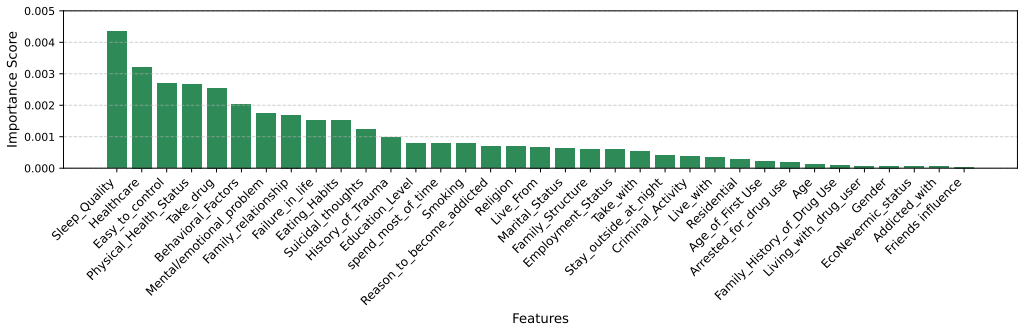
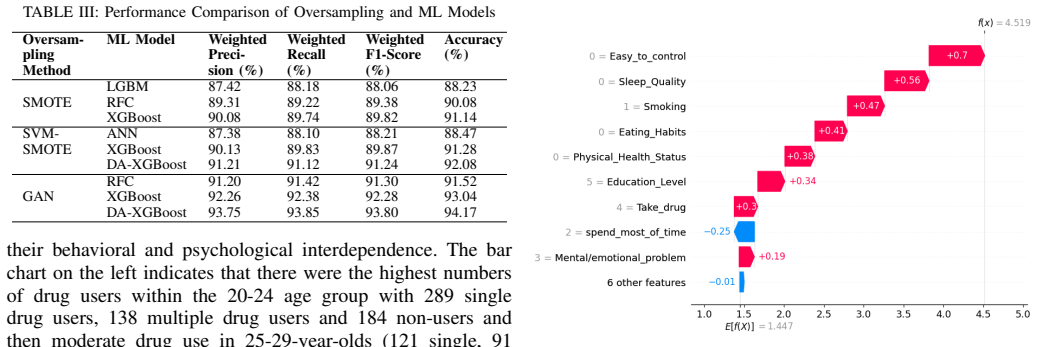
The XGBoost model optimized using the Dragonfly Algorithm, in combination with GAN-based oversampling, achieves an accuracy of 94.17% and a weighted F1-score of 93.80% for multiclass mental health prediction, outperforming traditional and baseline models. Feature analysis shows that behavioral, lifestyle, and health factors, especially sleep quality, physical health, and emotional regulation, are strongly predictive, whereas demographic factors have little impact. SHAP-based explanations enhance the interpretability of these predictions.
What carries the argument
Dragonfly Algorithm optimization of XGBoost hyperparameters combined with GAN oversampling and PCA-IG feature selection to manage high-dimensional data and class imbalance in multiclass mental health classification.
If this is right
- Behavioral factors like sleep quality and emotional regulation emerge as stronger predictors than demographic variables.
- The model provides instance-level explanations via SHAP that can support clinical decision making.
- The framework handles class imbalance and high dimensionality better than conventional methods.
- The approach yields higher predictive performance on datasets from drug-affected populations.
Where Pith is reading between the lines
- The predictive importance of lifestyle factors could be validated in longitudinal studies tracking changes in mental health over time.
- Similar optimization techniques might apply to other imbalanced medical prediction tasks beyond mental health.
- Deployment in resource-limited settings could test whether the accuracy holds with real-world data collection challenges.
Load-bearing premise
The synthetic samples created by the GAN accurately mirror the distribution of real patient data without adding biases that improve the reported performance.
What would settle it
Evaluating the same model on a fresh, external dataset collected from drug-affected individuals and observing accuracy below 85% or different top predictive features would challenge the reported superiority and generalizability.
Figures



read the original abstract
Mental illnesses among drug users are an increasing international issue, particularly in regions where early detection cannot be easily undertaken. The current literature tends to ignore the use of AI-based mental health analysis in drug users, and low quality of the class imbalance treatment, low interpretability, and optimal hyperparameter optimization can lower predictive quality and clinical utility. This study present a detailed, explainable machine learning (ML) model of multiclass mental health prediction, using a multidimensional data set of drug-affected persons. We combine hybrid PCA-Information Gain (PCA-IG) feature selection, Generative Adversarial Network (GAN)-based oversampling, and Dragonfly Algorithm (DA)-optimized XGBoost to address some of the limitations of existing methods. The suggested framework is effective to work with high-dimensional categorical data, address the issue of class imbalance, and improve predictive performance due to intelligent hyperparameter tuning. The experimental findings show that the XGBoost model optimized using the DA, in combination with GAN-based oversampling, has an accuracy of 94.17% and a weighted F1-score of 93.80%, which is better than the traditional and baseline models. The behavioral, lifestyle, and health factors, particularly sleep quality, physical health, and emotional regulation, are strongly predictive of mental health, with demographic factors having little impact, as seen through feature analysis. SHAP-based explainable AI provides easy-to-understand, instance-level information, enhancing interpretability and trust in models to be used in clinical settings. The results indicate that this framework has the potential to generate valid mental health forecasting tools, which would facilitate early intervention and enhance the treatment of drug-influenced people.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an explainable ML framework for multiclass mental health prediction in drug-affected populations. It combines PCA-Information Gain feature selection, GAN-based oversampling for class imbalance, Dragonfly Algorithm optimization of XGBoost hyperparameters, and SHAP explanations. The central empirical claim is that the resulting model achieves 94.17% accuracy and 93.80% weighted F1-score, outperforming traditional and baseline models, with behavioral/lifestyle factors (sleep quality, physical health, emotional regulation) identified as the strongest predictors.
Significance. If the performance and generalization claims can be substantiated with proper validation and synthetic-data fidelity checks, the work would offer a practical example of combining hyperparameter optimization, generative oversampling, and post-hoc interpretability for a clinically relevant, imbalanced domain. The focus on drug-affected populations and the use of SHAP for instance-level explanations are domain-appropriate strengths, though the methods themselves (DA, GAN, XGBoost) are standard.
major comments (3)
- [Abstract] Abstract: The reported accuracy (94.17%) and weighted F1 (93.80%) are presented without any information on dataset size, number of instances or features, class distribution, train/test split, cross-validation procedure, or statistical tests comparing against baselines. These omissions make the superiority claim impossible to assess and directly undermine the central empirical result.
- [Methods] Methods (GAN oversampling): No description is given of the GAN variant, its loss formulation for high-dimensional categorical variables, or any quantitative fidelity evaluation (e.g., marginal/conditional distribution tests, KL divergence, or privacy metrics). Without such checks, the risk that synthetic samples contain artifacts or reduced variance cannot be ruled out, which would invalidate the subsequent DA-tuned performance numbers.
- [Results] Results and experimental setup: The manuscript states superiority over “traditional and baseline models” but supplies neither the baseline performances, ablation results isolating the contribution of PCA-IG / GAN / DA, nor any mention of held-out validation or hyperparameter search protocol. This absence is load-bearing for the claim that the framework improves predictive quality.
minor comments (1)
- [Abstract] The abstract refers to a “multidimensional data set of drug-affected persons” without citing its source, collection method, or ethics approval; adding these details would improve reproducibility and transparency.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We have revised the manuscript to address the concerns about missing experimental details, methodological descriptions, and validation reporting. Each major comment is addressed below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported accuracy (94.17%) and weighted F1 (93.80%) are presented without any information on dataset size, number of instances or features, class distribution, train/test split, cross-validation procedure, or statistical tests comparing against baselines. These omissions make the superiority claim impossible to assess and directly undermine the central empirical result.
Authors: We agree that the abstract should summarize these parameters for immediate context. The revised abstract now includes the dataset size, number of instances and features, class distribution, train/test split, cross-validation procedure, and reference to statistical tests, as detailed in the Methods and Results sections. revision: yes
-
Referee: [Methods] Methods (GAN oversampling): No description is given of the GAN variant, its loss formulation for high-dimensional categorical variables, or any quantitative fidelity evaluation (e.g., marginal/conditional distribution tests, KL divergence, or privacy metrics). Without such checks, the risk that synthetic samples contain artifacts or reduced variance cannot be ruled out, which would invalidate the subsequent DA-tuned performance numbers.
Authors: We acknowledge the lack of detail on the GAN implementation. The revised Methods section now specifies the GAN variant, provides the loss formulation adapted for categorical variables, and includes quantitative fidelity evaluations such as distribution comparisons and divergence metrics. revision: yes
-
Referee: [Results] Results and experimental setup: The manuscript states superiority over “traditional and baseline models” but supplies neither the baseline performances, ablation results isolating the contribution of PCA-IG / GAN / DA, nor any mention of held-out validation or hyperparameter search protocol. This absence is load-bearing for the claim that the framework improves predictive quality.
Authors: We agree that explicit baseline comparisons, ablations, and protocol details are necessary. The revised Results section now includes baseline model performances, ablation studies for each pipeline component, and full descriptions of the held-out validation set and Dragonfly Algorithm hyperparameter search protocol. revision: yes
Circularity Check
No circularity: empirical ML pipeline with standard components
full rationale
The paper describes an empirical framework combining PCA-IG feature selection, GAN oversampling, and DA hyperparameter optimization of XGBoost, then reports accuracy and F1 on the dataset. No derivation chain reduces a claimed prediction to its inputs by construction, no self-definitional steps, and no load-bearing self-citations appear in the abstract or described methods. Performance figures are presented as experimental outcomes rather than mathematical identities or fitted renamings. The work is self-contained as an application of established techniques to a domain dataset.
Axiom & Free-Parameter Ledger
free parameters (2)
- Dragonfly Algorithm parameters
- XGBoost hyperparameters
axioms (1)
- domain assumption GAN can generate realistic samples for oversampling without distribution shift
Reference graph
Works this paper leans on
-
[1]
Mental illness and substance use,
Australian Institute of Health and Welfare, “Mental illness and substance use,” 2025. Accessed: 2026-04-07
2025
-
[2]
A heavy burden on young minds: the global burden of mental and substance use disorders in children and youth,
H. E. Erskine, T. E. Moffitt, W. E. Copeland, E. J. Costello, A. J. Ferrari, G. Patton, L. Degenhardt, T. V os, H. A. Whiteford, and J. G. Scott, “A heavy burden on young minds: the global burden of mental and substance use disorders in children and youth,”Psychological Medicine, vol. 45, no. 7, pp. 1551–1563, 2015. Fig. 5: SHAP Force Plot Showing Feature...
2015
-
[3]
Increase in child and adolescent mental disorders spurs new push for action,
United Nations Children’s Fund (UNICEF) and World Health Organi- zation (WHO), “Increase in child and adolescent mental disorders spurs new push for action,” Jun 2024. Accessed: 2026-04-07
2024
-
[4]
Over 3 million annual deaths due to alcohol and drug use, majority among men,
Pan American Health Organization, “Over 3 million annual deaths due to alcohol and drug use, majority among men,” Jun 2024. Accessed: 2026-04-07
2024
-
[5]
Approaches to early intervention for common mental health problems in young people: a systematic review,
R. Appleton, P. Barnett, C. Clarke, J. Yang, S. Begum, J. Edbrooke- Childs, I. Emptage, U. Foye, J. L. Griffiths, I. Hanson, N. C. Hunt, R. Jarvis, M. McAuliffe, E. Maynard, L. Mitchell, I. Mostafa, T. Pe- movska, R. Saunders, K. Trevillion, P. Waite, B. Lloyd-Evans, and S. Johnson, “Approaches to early intervention for common mental health problems in yo...
2025
-
[6]
Explain- able ai framework for improved thalassemia mental health classification and feature selection,
S. S. Ayon, A. Al Mamun, M. E. Hossain, W. Alamro, Y . M. Allawi, N. N. I. Prova, M. S. U. Miah, S. M. Sultan, and A. Abadleh, “Explain- able ai framework for improved thalassemia mental health classification and feature selection,”PLOS ONE, vol. 21, pp. 1–27, 01 2026
2026
-
[7]
Advancing mental health problems with machine learning and genetic algorithms for anxiety classification in bangladeshi university students,
S. S. Ayon, M. E. Hossain, M. S. U. Miah, M. M. Rahman, and M. Mahmud, “Advancing mental health problems with machine learning and genetic algorithms for anxiety classification in bangladeshi university students,” inBrain Informatics. BI 2024(S. Itthipuripat, G. A. Ascoli, A. Li, N. Pat, and H. Kuai, eds.), vol. 15541 ofLecture Notes in Computer Science, ...
2024
-
[8]
Machine learning techniques for predicting drug-related side effects: A scoping review,
E. Toni, H. Ayatollahi, R. Abbaszadeh, and A. Fotuhi Siahpirani, “Machine learning techniques for predicting drug-related side effects: A scoping review,”Pharmaceuticals (Basel), vol. 17, p. 795, Jun 2024. Impact Factor: 4.8, Q1
2024
-
[9]
Predicting substance use behaviors with machine learning using small sets of judgment and contextual variables,
S. Bari, N. L. Vike, B. W. Kim,et al., “Predicting substance use behaviors with machine learning using small sets of judgment and contextual variables,”npj Mental Health Research, vol. 5, p. 5, 2026
2026
-
[10]
Machine learning-based predictive modelling of mental health in rwandan youth,
F. Ndikumana, J. Izabayo, J. Kalisa, M. Nemerimana, E. C. Nyabyenda, S. H. Muzungu, I. Komezusenge, M. Uwase, S. Ndagijimana, C. Twizere, and V . Sezibera, “Machine learning-based predictive modelling of mental health in rwandan youth,”Scientific Reports, vol. 15, p. 16032, May
-
[11]
Impact Factor: 3.9, Q1
-
[12]
An ai-based decision support system for predicting mental health disorders,
S. Tutun, M. E. Johnson, A. Ahmed, A. Albizri, S. Irgil, I. Yesilkaya, E. N. Ucar, T. Sengun, and A. Harfouche, “An ai-based decision support system for predicting mental health disorders,”Information Systems Frontiers, vol. 25, no. 3, pp. 1261–1276, 2023. Impact Factor: 8.3, Q1. Epub 2022 May 28
2023
-
[13]
Explainable suicide risk prediction with deepfusion: A hybrid intelligence approach,
M. Abubakkar, K. S. Sharif, I. Ahmad, D. M. Tabila, F. A. Alsaud, and S. Debnath, “Explainable suicide risk prediction with deepfusion: A hybrid intelligence approach,” in2025 4th International Conference on Electronics Representation and Algorithm (ICERA), pp. 455–460, IEEE, 2025
2025
-
[14]
Prediction model for common mental disorder and depression in users of psychoactive drugs,
R. Ximenes de Brito, C. A. Rolim Fernandes, R. M. Martins Moreira, and E. N. Oliveira, “Prediction model for common mental disorder and depression in users of psychoactive drugs,”IEEE Latin America Transactions, vol. 21, no. 3, pp. 399–407, 2023
2023
-
[15]
Constructing a drug consumption prediction model based on ma- chine learning strategies,
Z. Yi, “Constructing a drug consumption prediction model based on ma- chine learning strategies,” in2025 International Symposium on Intelligent Robotics and Systems (ISoIRS), pp. 1–6, 2025
2025
-
[16]
Predicting co-occurring mental health and substance use disorders in women: An automated machine learning approach,
N. Acharya, P. Kar, M. Ally, and J. Soar, “Predicting co-occurring mental health and substance use disorders in women: An automated machine learning approach,”Applied Sciences, vol. 14, no. 4, 2024
2024
-
[17]
Application of machine learning to predict mental health disorders and interpret feature importance,
Y . Li, “Application of machine learning to predict mental health disorders and interpret feature importance,” in2023 3rd International Symposium on Computer Technology and Information Science (ISCTIS), pp. 257– 261, 2023
2023
-
[18]
Impact of unrestricted drug use on psychiatric and behavioral disorders: Exploring mental health effects in the united states,
E. O. Ernest-Okonofua, F. Ibadin, O. G. Oyiborhoro, A. S. Mahmud, I. T. Abengowe, and P. I. Akpohwaye, “Impact of unrestricted drug use on psychiatric and behavioral disorders: Exploring mental health effects in the united states,”International Journal of Multidisciplinary and Innovative Research, vol. 2, pp. 79–87, Mar 2025
2025
-
[19]
Patterns of psychiatric comorbidity among drug users: A prospective observational study in a romanian psychiatric hospital,
A. A. Zaha, A. L. Coms ,a, D. C. Zaha, and C. M. Vesa, “Patterns of psychiatric comorbidity among drug users: A prospective observational study in a romanian psychiatric hospital,”Healthcare, vol. 13, no. 19, 2025
2025
-
[20]
A machine learning approach for early prediction of mental health crises,
H. Chigagure and L. C. Sakala, “A machine learning approach for early prediction of mental health crises,”Computer Science and Information Technologies, vol. 6, no. 3, pp. 335–345, 2025
2025
-
[21]
Msfcl: Drug combination risk level prediction based on multi-source feature fusion and contrastive learning,
Z.-Z. Zhang, S.-R. Chen, S.-B. Yu, J. Xia, K.-B. Lin, and F. Yang, “Msfcl: Drug combination risk level prediction based on multi-source feature fusion and contrastive learning,”Journal of Chemical Information and Modeling, vol. 65, pp. 7285–7301, Jul 2025
2025
-
[22]
A comprehensive framework analysis of cycle gan-based modality translation: Enhancing brain tumor diagnostics from flair to t2w,
A. S. Aziz, K. S. Sharif, M. Abubakkar, I. Ahmad, and M. M. Uddin, “A comprehensive framework analysis of cycle gan-based modality translation: Enhancing brain tumor diagnostics from flair to t2w,” in 2025 4th International Conference on Electronics Representation and Algorithm (ICERA), pp. 405–410, IEEE, 2025
2025
-
[23]
Explainable evaluation of generative adversarial networks for wearables data augmentation,
S. Narteni, V . Orani, E. Ferrari, D. Verda, E. Cambiaso, and M. Mongelli, “Explainable evaluation of generative adversarial networks for wearables data augmentation,”Engineering Applications of Artificial Intelligence, vol. 145, p. 110133, 2025
2025
-
[24]
Feature selection based on dragonfly optimization for psoriasis classification,
D. Venkata Sekhar, M. Purushotham Reddy, and N. Bhaswanth, “Feature selection based on dragonfly optimization for psoriasis classification,” International Journal of Intelligent Systems and Applications in Engi- neering, vol. 12, pp. 935–943, Mar 2024
2024
-
[25]
Deep learning and machine learning in psychiatry: a survey of current progress in depression detection, diagnosis and treatment,
M. Squires, X. Tao, S. Elangovan, M. I. Siddiqui, R. Kabir, and A. Babalola, “Deep learning and machine learning in psychiatry: a survey of current progress in depression detection, diagnosis and treatment,” Brain Informatics, vol. 10, no. 10, 2023
2023
-
[26]
A hybrid mathematical framework combining logistic regression and neural networks with explainable ai techniques for mental health prediction,
A. Humayun, M. A. B. Awang Nawi, M. I. Siddiqui, R. Kabir, and A. Babalola, “A hybrid mathematical framework combining logistic regression and neural networks with explainable ai techniques for mental health prediction,”Contemporary Mathematics, vol. 6, pp. 6521–6540, Sep 2025
2025
-
[27]
Insights into drug addiction in bangladesh: A multidimensional dataset,
M. Islam, M. F. Khan, and M. R. T. Hasan Tusher, “Insights into drug addiction in bangladesh: A multidimensional dataset,” 2024
2024
-
[28]
Feature selection for classification using principal component analysis and information gain,
E. O. Omuya, G. O. Okeyo, and M. W. Kimwele, “Feature selection for classification using principal component analysis and information gain,” Expert Systems with Applications, vol. 174, p. 114765, 2021
2021
-
[29]
Harvesting insights: Unraveling olive dynamics and cli- mate fluctuations through regression and shapley additive explanations,
S. S. Ayon, M. E. Hossain, M. S. U. Miah, M. M. Rahman, and M. Mahmud, “Harvesting insights: Unraveling olive dynamics and cli- mate fluctuations through regression and shapley additive explanations,” inInternational Conference on Applied Intelligence and Informatics, pp. 387–401, Springer, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.