Belief Engine: Configurable and Inspectable Stance Dynamics in Multi-Agent LLM Deliberation
Pith reviewed 2026-05-19 15:53 UTC · model grok-4.3
pith:CZU3WWQD Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{CZU3WWQD}
Prints a linked pith:CZU3WWQD badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
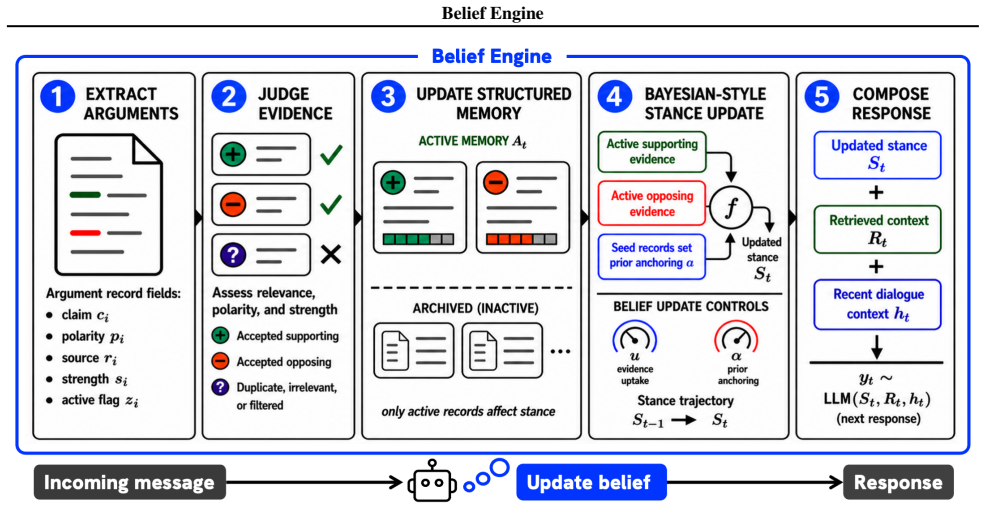
The Belief Engine makes stance changes in LLM deliberation auditable by extracting arguments and updating beliefs through a log-odds rule controlled by evidence uptake and prior anchoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Belief Engine treats belief as an evidential state over a proposition, exposes it as scalar stance, extracts arguments into structured memory, and updates stance with a log-odds rule controlled by evidence uptake u and prior anchoring a. Parameter sweeps across multiple base LLMs show these controls reliably shape stance dynamics while preserving an evidence-level update trail. On the DEBATE dataset, the model best reconstructs participants whose final stance follows extracted evidence, whereas stable and evidence-opposed cases point to anchoring or factors outside the extracted evidence stream.
What carries the argument
The Belief Engine, which extracts arguments from deliberation transcripts into structured memory and updates scalar stance via a log-odds rule whose rate is set by evidence uptake and prior anchoring parameters.
If this is right
- Stance dynamics in LLM agents become reliably controllable by tuning evidence uptake and anchoring while an evidence trail remains inspectable.
- Reconstruction accuracy is highest for participants whose final stances align with arguments extracted from the transcript.
- Stable stances or those opposing extracted evidence indicate that prior anchoring is the dominant influence.
- Concepts such as openness, commitment, convergence, and disagreement can be linked directly to explicit update assumptions rather than hidden prompt effects.
Where Pith is reading between the lines
- The same extraction-plus-log-odds structure could be used to compare convergence rates across different anchoring strengths in simulated negotiations.
- Mismatch cases on real human data could help isolate non-evidential influences such as social echoing or role drift that the current evidence stream misses.
- Inspectable update trails may make it easier to debug when LLM agents drift from evidence toward prompt-driven repetition over long exchanges.
Load-bearing premise
That extracting arguments and updating via a log-odds rule balancing evidence uptake against prior anchoring sufficiently captures the main drivers of stance change in both LLM agents and human participants on the DEBATE dataset.
What would settle it
On the DEBATE dataset, measure how closely the Belief Engine's reconstructed stances match actual pre-to-post opinion shifts when evidence is present but participants remain stable; if anchoring parameters cannot close the gap, the model fails to account for the discrepancy.
Figures




read the original abstract
LLM-based agents are increasingly used to simulate deliberative interactions such as negotiation, conflict resolution, and multi-turn opinion exchange. Yet generated transcripts often do not reveal why an agent's stance changes: movement may reflect evidence uptake, anchoring, role drift, echoing, or changed prompt and retrieval context. We introduce the Belief Engine (BE), an auditable belief-update layer that treats "belief" as an evidential state over a proposition and exposes it as scalar stance. BE extracts arguments into structured memory and updates stance with a log-odds rule controlled by evidence uptake u and prior anchoring a. Across multiple base LLMs, parameter sweeps show that these controls reliably shape stance dynamics while preserving an evidence-level update trail. On DEBATE, a human deliberation dataset with pre/post opinions, BE best reconstructs participants whose final stance follows extracted evidence; stable and evidence-opposed cases instead point to anchoring or factors outside the extracted evidence stream. BE provides configurable infrastructure for studying evidence-grounded deliberation, where openness, commitment, convergence, and disagreement can be tied to explicit update assumptions rather than hidden prompt effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Belief Engine (BE), an auditable belief-update layer for LLM-based agents in multi-agent deliberation. BE extracts arguments from transcripts into structured memory and updates a scalar stance via a log-odds rule governed by two configurable parameters: evidence uptake u and prior anchoring a. Parameter sweeps across base LLMs demonstrate that these controls reliably shape stance dynamics while preserving an evidence trail. On the DEBATE human deliberation dataset (pre/post opinions), BE achieves best reconstruction for participants whose final stance aligns with extracted evidence; stable and evidence-opposed cases are attributed to anchoring or external factors.
Significance. If the reconstruction results and parameter controllability hold under rigorous validation, the work provides useful infrastructure for making LLM deliberation more inspectable and evidence-grounded. It allows stance changes to be tied to explicit update assumptions rather than hidden prompt effects, which could support studies of convergence, disagreement, and anchoring in simulated deliberation.
major comments (2)
- [Abstract and §4] Abstract and §4 (DEBATE reconstruction): The manuscript reports that BE 'best reconstructs' participants whose final stance follows extracted evidence, yet provides no details on the fitting objective for u and a (e.g., likelihood, exact-match error, or thresholded delta), the optimization procedure, search ranges, or any regularization. Without these, the separation between evidence-following and anchored cases cannot be distinguished from the flexibility of a two-parameter log-odds model that can approximate arbitrary stance deltas.
- [§3.2] §3.2 (log-odds update rule): The claim that the update is 'parameter-free' in its evidence-level trail is undercut by the dependence on fitted u and a; the paper should clarify whether reconstruction success is measured against a null model (fixed u=0 or a=1) or a single-parameter baseline to establish that the two-parameter form adds diagnostic power beyond flexibility.
minor comments (2)
- [Abstract] The abstract mentions 'parameter sweeps across base LLMs' but does not report the specific LLMs, number of runs, or error bars; these should be added for reproducibility.
- [§3] Notation for the log-odds update (Eq. likely in §3) should explicitly define how extracted arguments are mapped to evidence increments before the u/a scaling.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important gaps in the presentation of our fitting procedure and the interpretation of the 'parameter-free' claim. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (DEBATE reconstruction): The manuscript reports that BE 'best reconstructs' participants whose final stance follows extracted evidence, yet provides no details on the fitting objective for u and a (e.g., likelihood, exact-match error, or thresholded delta), the optimization procedure, search ranges, or any regularization. Without these, the separation between evidence-following and anchored cases cannot be distinguished from the flexibility of a two-parameter log-odds model that can approximate arbitrary stance deltas.
Authors: We agree that the manuscript does not currently specify the fitting objective, optimization procedure, search ranges, or regularization used to select u and a for the DEBATE reconstruction. This omission makes it difficult to evaluate whether the reported separation reflects genuine diagnostic power or simply the flexibility of a two-parameter model. We will add a new subsection in §4 that details the procedure: a grid search over u ∈ [0, 2] and a ∈ [0, 1] minimizing absolute stance prediction error, with explicit comparison to a null model (u = 0, no update) and a single-parameter baseline (a fixed at 0.5). These additions will allow readers to assess whether the two-parameter form provides explanatory value beyond flexibility for evidence-aligned participants. revision: yes
-
Referee: [§3.2] §3.2 (log-odds update rule): The claim that the update is 'parameter-free' in its evidence-level trail is undercut by the dependence on fitted u and a; the paper should clarify whether reconstruction success is measured against a null model (fixed u=0 or a=1) or a single-parameter baseline to establish that the two-parameter form adds diagnostic power beyond flexibility.
Authors: The phrase 'parameter-free' in §3.2 was intended to refer exclusively to the evidence extraction and logging step, which records structured arguments independently of the numerical values chosen for u and a. The parameters affect only the magnitude of the stance update, not the content or presence of the evidence trail itself. We acknowledge that this distinction is not stated clearly enough. We will revise the wording in §3.2 to emphasize that the inspectable evidence trail remains available regardless of parameter settings. In addition, the baseline comparisons described in our response to the first comment will be included in the DEBATE analysis to demonstrate that the two-parameter model improves reconstruction specifically where evidence alignment is observed. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the Belief Engine as a configurable, auditable layer that extracts arguments and applies a log-odds stance update controlled by explicit parameters u (uptake) and a (anchoring). It then evaluates reconstruction performance on the independent external DEBATE dataset containing pre/post human opinions. The central result—that BE best reconstructs participants whose final stance aligns with extracted evidence while stable or opposed cases indicate anchoring—is obtained by applying the model to this separate data source rather than by any self-referential fit, self-citation chain, or definitional equivalence. No equation or claim reduces the reported distinction to the inputs by construction; the parameters are presented as tunable controls whose effects are demonstrated via sweeps, not as quantities optimized to force the classification outcome. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- evidence uptake u
- prior anchoring a
axioms (2)
- domain assumption Belief can be represented as a scalar stance over a proposition
- domain assumption Log-odds rule is a suitable update mechanism for stance based on extracted evidence
invented entities (1)
-
Belief Engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Knowledge Conflicts for LLM s: A Survey
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei. Knowledge Conflicts for LLM s: A Survey. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.486
-
[2]
arXiv preprint arXiv:2504.19622 , year =
From Evidence to Belief: A Bayesian Epistemology Approach to Language Models , author =. arXiv preprint arXiv:2504.19622 , year =
-
[3]
arXiv preprint arXiv:2503.17523 , year =
Bayesian Teaching Enables Probabilistic Reasoning in Large Language Models , author =. arXiv preprint arXiv:2503.17523 , year =
-
[4]
Taubenfeld, Amir and Dover, Yaniv and Reichart, Roi and Goldstein, Ariel , year = 2024, eprint =. Systematic. Proceedings of the 2024. doi:10.18653/v1/2024.emnlp-main.16 , urldate =
-
[5]
arXiv preprint arXiv:2512.18489 , year =
Large Language Models as Discounted Bayesian Filters , author =. arXiv preprint arXiv:2512.18489 , year =
-
[6]
arXiv preprint arXiv:2510.25110 , year =
DEBATE: A Large-Scale Benchmark for Multi-Agent Opinion Dynamics , author =. arXiv preprint arXiv:2510.25110 , year =
-
[7]
A Survey on the Memory Mechanism of Large Language Model based Agents
A Survey on the Memory Mechanism of Large Language Model based Agents , author =. arXiv preprint arXiv:2404.13501 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Kang, Jiazheng and Ji, Mingming and Zhao, Zhe and Bai, Ting , journal =. Memory
-
[9]
arXiv preprint arXiv:2511.01448 , year =
LiCoMemory: Lightweight and Cognitive Agentic Memory for Efficient Long-Term Reasoning , author =. arXiv preprint arXiv:2511.01448 , year =
-
[10]
Xiong, Zidi and Lin, Yuping and Xie, Wenya and He, Pengfei and Liu, Zirui and Tang, Jiliang and Lakkaraju, Himabindu and Xiang, Zhen , journal =. How Memory Management Impacts
-
[11]
Steinnberger, Peter and Community , year =
-
[12]
https://arxiv.org/abs/2601.10825
Reasoning Models Generate Societies of Thought , author =. arXiv preprint arXiv:2601.10825 , year =
-
[13]
AgentSociety: Large-Scale Simulation of
Piao, Jinghua and Yan, Yuwei and Zhang, Jun and Li, Nian and Yan, Junbo and Lan, Xiaochong and Lu, Zhihong and Zheng, Zhiheng and Wang, Jing Yi and Zhou, Di and Gao, Chen and Xu, Fengli and Zhang, Fang and Rong, Ke and Su, Jun and Li, Yong , journal =. AgentSociety: Large-Scale Simulation of
-
[14]
Xu, Yuwei and Zhang, Shulun and Zhou, Yingli and Zeng, Shipei and Lakshmanan, Laks V. S. and Ma, Chenhao , journal =. Topology-Aware
-
[15]
arXiv preprint arXiv:2306.01032 , year =
Chaos Persists in Large-Scale Multi-Agent Learning Despite Adaptive Learning Rates , author =. arXiv preprint arXiv:2306.01032 , year =
-
[16]
Proceedings of AAMAS 2026 , year =
R-Debater: Retrieval-Augmented Debate Generation through Argumentative Memory , author =. Proceedings of AAMAS 2026 , year =
work page 2026
-
[17]
Advances in Neural Information Processing Systems , year=
Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models? , author=. Advances in Neural Information Processing Systems , year=
-
[18]
From Debate to Equilibrium: Belief-Driven Multi-Agent
Xie, Yi and Zhou, Zhanke and Cao, Chentao and Niu, Qiyu and Liu, Tongliang and Han, Bo , booktitle =. From Debate to Equilibrium: Belief-Driven Multi-Agent
-
[19]
On the Generality and Cognitive Basis of Base-Rate Neglect , author =. Cognition , volume =. doi:10.1016/j.cognition.2022.105160 , urldate =
-
[20]
Holt, Charles A. and Smith, Angela M. , year = 2009, month = feb, journal =. An Update on. doi:10.1016/j.jebo.2007.08.013 , urldate =
-
[21]
PLOS Computational Biology , volume =
The Effects of Base Rate Neglect on Sequential Belief Updating and Real-World Beliefs , author =. PLOS Computational Biology , volume =. doi:10.1371/journal.pcbi.1010796 , urldate =
-
[22]
Olsson, Erik J. , editor =. A. Bayesian. doi:10.1007/978-94-007-5357-0_6 , urldate =
-
[23]
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , journal =. doi:10.48550/arXiv.2111.09543 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2111.09543
-
[24]
Simulating Society Requires Simulating Thought , author=. The Thirty-Ninth Annual Conference on Neural Information Processing Systems Position Paper Track , year=
-
[25]
Li, Chance Jiajie and Mo, Zhenze and Tang, Yuhan and Qu, Ao and Wu, Jiayi and Zhao, Kaiya Ivy and Gan, Yulu and Fan, Jie and Yu, Jiangbo and Jiang, Hang and Liang, Paul Pu and Zhao, Jinhua and Pastor, Luis Alberto Alonso and Larson, Kent , journal =. HugAgent: Benchmarking
-
[26]
Journal of the American Statistical Association , volume =
Reaching a consensus , author =. Journal of the American Statistical Association , volume =
-
[27]
Journal of Artificial Societies and Social Simulation , volume =
Opinion dynamics and bounded confidence: models, analysis, and simulation , author =. Journal of Artificial Societies and Social Simulation , volume =
-
[28]
Advances in Complex Systems , volume =
Mixing beliefs among interacting agents , author =. Advances in Complex Systems , volume =
-
[29]
Utilizing Python for Agent-Based Modeling: The Mesa Framework , ISBN =
Kazil, Jackie and Masad, David and Crooks, Andrew , year =. Utilizing Python for Agent-Based Modeling: The Mesa Framework , ISBN =. doi:10.1007/978-3-030-61255-9_30 , booktitle =
-
[30]
Second Agent Learning in Open-Endedness Workshop , year=
AgentTorch: Agent-based Modeling with Automatic Differentiation , author=. Second Agent Learning in Open-Endedness Workshop , year=
-
[31]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages =
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages =
-
[32]
Advances in Neural Information Processing Systems , volume =
CAMEL: Communicative Agents for ``Mind'' Exploration of Large Language Model Society , author =. Advances in Neural Information Processing Systems , volume =
-
[33]
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and others , journal =. AutoGen: Enabling Next-Gen. 2023 , doi =
work page 2023
-
[34]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author =. arXiv preprint arXiv:2306.05685 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , volume =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , volume =. Advances in Neural Information Processing Systems , editor =
-
[36]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author =. arXiv preprint arXiv:2305.10250 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , author =. ACL , year =
-
[38]
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis , journal =
Shai Gretz and Roni Friedman and Edo Cohen. A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis , journal =
-
[39]
European Political Science Review , volume =
Measuring Political Deliberation: A Discourse Quality Index , author =. European Political Science Review , volume =
-
[40]
Liu, Yuhan and Liu, Yuxuan and Zhang, Xiaoqing and Chen, Xiuying and Yan, Rui , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3730092 , abstract =
-
[41]
Examining Identity Drift in Conversations of
Choi, Junhyuk and Hong, Yeseon and Kim, Minju and Kim, Bugeun , journal =. Examining Identity Drift in Conversations of
-
[42]
Echoing: Identity Failures When
Shekkizhar, Sarath and Cosentino, Romain and Earle, Adam and Savarese, Silvio , journal =. Echoing: Identity Failures When
-
[43]
arXiv preprint arXiv:2402.14846 , year =
Stick to Your Role! Stability of Personal Values Expressed in Large Language Models , author =. arXiv preprint arXiv:2402.14846 , year =
-
[44]
Ratnakar, Shivam and Raghavendra, Sanjay , journal =. The Chameleon Nature of
-
[45]
Proceedings of SIGIR 2025 , year =
The Truth Becomes Clearer Through Debate! Multi-Agent Systems with Large Language Models Unmask Fake News , author =. Proceedings of SIGIR 2025 , year =
work page 2025
-
[46]
Findings of EMNLP 2021 , year =
DebateSum: A Large-scale Argument Mining and Summarization Dataset , author =. Findings of EMNLP 2021 , year =
work page 2021
-
[47]
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , journal =. A-MEM: Agentic Memory for
-
[48]
Collaborative Memory: Multi-User Memory Sharing in
Rezazadeh, Alireza and Li, Zichao and Lou, Ange and Zhao, Yuying and Wei, Wei and Bao, Yujia , journal =. Collaborative Memory: Multi-User Memory Sharing in
-
[49]
doi:10.48550/arXiv.2506.06254 , author =
arXiv preprint arXiv:2506.06254 , year =. doi:10.48550/arXiv.2506.06254 , author =
-
[50]
Wang, Tiannan and Tao, Meiling and Fang, Ruoyu and Wang, Huilin and Wang, Shuai and Jiang, Yuchen Eleanor and Zhou, Wangchunshu , journal =
-
[51]
arXiv preprint arXiv:2405.20839 , year =
APersona: A Persona-Aware LLM-Enhanced Framework for Multi-Session Personalized Dialogue Generation , author =. arXiv preprint arXiv:2405.20839 , year =
-
[52]
arXiv preprint arXiv:2406.05925 , year =
Hello Again!. arXiv preprint arXiv:2406.05925 , year =. doi:10.48550/arXiv.2406.05925 , author =
-
[53]
Tan, Zhen and Yan, Jun and Hsu, I-Hung and Han, Rujun and Wang, Zifeng and Le, Long and Song, Yiwen and Chen, Yanfei and Palangi, Hamid and Lee, George and Iyer, Anand Rajan and Chen, Tianlong and Liu, Huan and Lee, Chen-Yu and Pfister, Tomas , year =. In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents , DO...
-
[54]
arXiv preprint arXiv:2501.07278 , year=
Lifelong Learning of Large Language Model based Agents: A Roadmap , author =. arXiv preprint arXiv:2501.07278 , year =
-
[55]
Tan, Juntao and Yang, Liangwei and Liu, Zuxin and Liu, Zhiwei and Murthy, Rithesh and Manoj Awalgaonkar, Tulika and Zhang, Jianguo and Yao, Weiran and Zhu, Ming and Kokane, Shirley and Savarese, Silvio and Wang, Huan and Xiong, Caiming and Heinecke, Shelby , journal =. PersonaBench: Evaluating
-
[56]
Tseng, Yu-Min and Huang, Yu-Chao and Hsiao, Teng-Yun and Chen, Wei-Lin and Huang, Chao-Wei and Meng, Yun-Nung , booktitle =. Two Tales of Persona in
-
[57]
Ming Wang and Peidong Wang and Lin Wu and Xiaocui Yang and Daling Wang and Shi Feng and Yuxin Chen and Bixuan Wang and Yifei Zhang , journal =
-
[58]
Nested Learning: The Illusion of Deep Learning Architectures , author =. NeurIPS 2025 , year =
work page 2025
-
[59]
EX - FEVER : A Dataset for Multi-hop Explainable Fact Verification
Ma, Huanhuan and Xu, Weizhi and Wei, Yifan and Chen, Liuji and Wang, Liang and Liu, Qiang and Wu, Shu and Wang, Liang. EX - FEVER : A Dataset for Multi-hop Explainable Fact Verification. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.556
-
[60]
arXiv preprint arXiv:2508.16539 , year =
A Bayesian framework for opinion dynamics models , author =. arXiv preprint arXiv:2508.16539 , year =
-
[61]
Opinion Dynamics with Bayesian Learning , author =. Complexity , volume =
-
[62]
A Survey on Nonstrategic Models of Opinion Dynamics , author =. Games , year =
-
[63]
Journal of Artificial Societies and Social Simulation , year =
Hegselmann, Rainer , title =. Journal of Artificial Societies and Social Simulation , year =
-
[64]
Dynamic Games and Applications , volume =
Opinion Dynamics and Learning in Social Networks , author =. Dynamic Games and Applications , volume =
-
[65]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =
LLM Voting: Human Choices and AI Collective Decision-Making , author =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2024 , month =
work page 2024
-
[66]
and Grandi, Umberto and Hidalgo, César , title =
Gudiño, Jairo F. and Grandi, Umberto and Hidalgo, César , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2024 , month =. doi:10.1098/rsta.2024.0100 , url =
- [67]
- [68]
-
[69]
The Place of Self-Interest and the Role of Power in Deliberative Democracy , journal =
Mansbridge, Jane and Bohman, James and Chambers, Simone and Estlund, David and F. The Place of Self-Interest and the Role of Power in Deliberative Democracy , journal =. 2010 , volume =
work page 2010
-
[70]
American Sociological Review , year =
Polletta, Francesca and Lee, John , title =. American Sociological Review , year =
-
[71]
Journal of Deliberative Democracy , year =
Nakazawa, Takashi and Tatsumi, Tomoyuki and Souma, Yume and Ohnuma, Susumu , title =. Journal of Deliberative Democracy , year =
-
[72]
Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , series =
Procedural Parity, Outcome Mismatch: Evaluating Human vs LLM Deliberation , author =. Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , series =. 2026 , address =
work page 2026
-
[73]
Agora: Teaching the Skill of Consensus-Finding with AI Personas Grounded in Human Voice , url =
Pradeep Fulay, Suyash and Ravi, Prerna and Gokhale, Om and Yi, Eugene and Bakker, Michiel A and Roy, Deb , year =. Agora: Teaching the Skill of Consensus-Finding with AI Personas Grounded in Human Voice , url =. doi:10.1145/3772363.3798888 , booktitle =
-
[74]
Advances in Neural Information Processing Systems , year =
AI Debate Aids Assessment of Controversial Claims , author =. Advances in Neural Information Processing Systems , year =
-
[75]
Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , series =
ArgueMate: Designing an Arguing Agent with Maximised Disagreement to Support Student Peer-Argumentation Exercise , author =. Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , series =. 2026 , address =
work page 2026
-
[76]
Advances in Neural Information Processing Systems , year =
Multi-Agent Debate for LLM Judges with Adaptive Stability Detection , author =. Advances in Neural Information Processing Systems , year =
-
[77]
Testing Deliberative Democracy Through Digital Twins , DOI =
Novelli, Claudio and Argota S\'anchez-Vaquerizo, Javier and Helbing, Dirk and Rotolo, Antonino and Floridi, Luciano , year =. Testing Deliberative Democracy Through Digital Twins , DOI =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.