Learning to Fold: prizewinning solution at LeHome Challenge 2026 (1st place online, 2nd offline)
Pith reviewed 2026-06-26 04:56 UTC · model grok-4.3
The pith
A vision-language-action policy can act as its own value function by predicting success, progress, and future quantities to improve bimanual garment folding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The author establishes that the identical network used to predict actions can also predict success, progress, and a few task-relevant future quantities, and that these predictions are sufficient to drive advantage estimation, live failure detection, and candidate selection inside an RL loop for the folding task.
What carries the argument
The policy network serving as its own value function, where its outputs for success and progress replace separate value networks in advantage estimation and failure detection.
If this is right
- Advantage estimation for policy improvement can be performed directly from the policy outputs without a separate critic.
- Live failure detection becomes possible by monitoring the policy's own success predictions during rollout.
- Action candidates can be ranked and selected using the policy's predictions of future task quantities.
- Inference-time hyperparameter tuning via Thompson sampling can be applied on top of the self-value estimates.
- Sim-to-real transfer is supported by combining camera alignment, heavy augmentation, and DAgger-style human-in-the-loop collection.
Where Pith is reading between the lines
- The same self-prediction pattern could be tested on other long-horizon manipulation tasks that currently rely on separate value heads.
- Removing the need for an explicit value network might lower memory and compute costs when scaling vision-language-action models to new robots.
- The asynchronous training and hub-based rollout pipeline could be reused in other distributed robot learning setups even without the folding-specific components.
Load-bearing premise
The policy network's own predictions of success, progress, and future quantities are accurate and unbiased enough to support advantage estimation, failure detection, and candidate selection.
What would settle it
Replace the network's predicted success and progress values with random or constant numbers during both training and execution and measure whether the resulting policy still achieves top ranks on the same folding tasks.
Figures


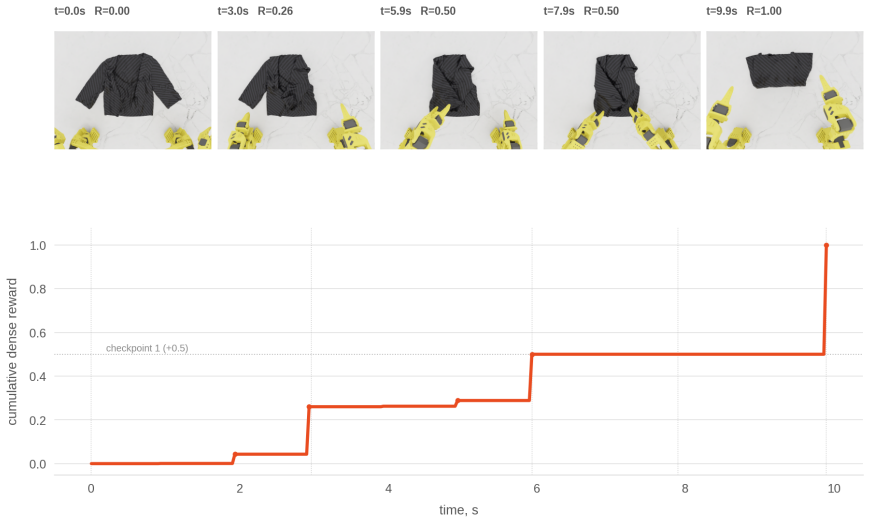

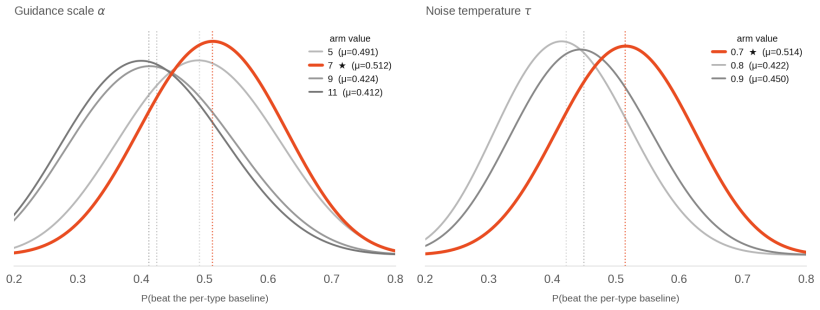
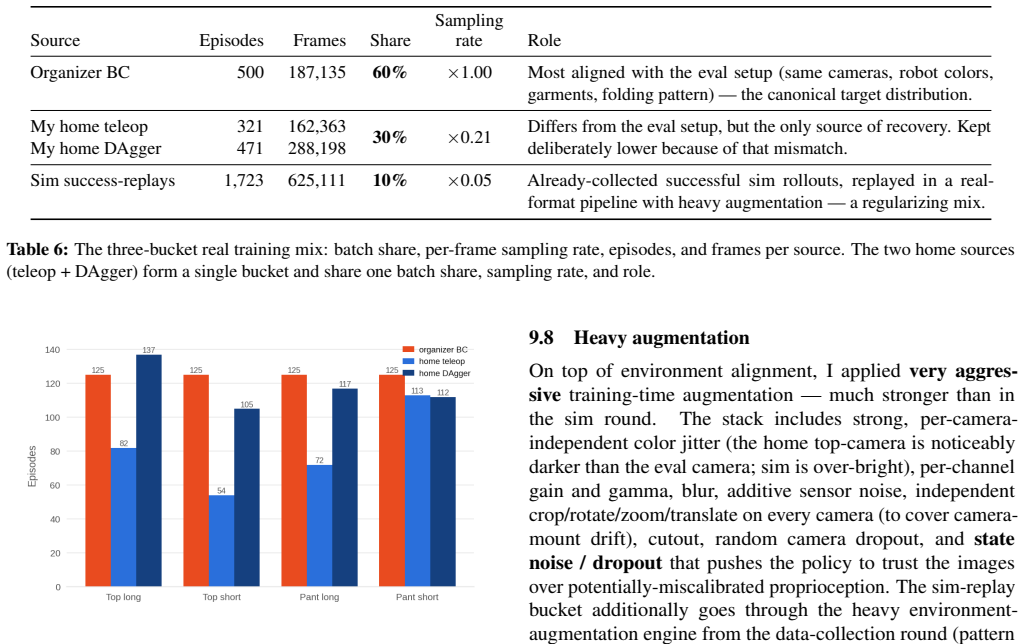





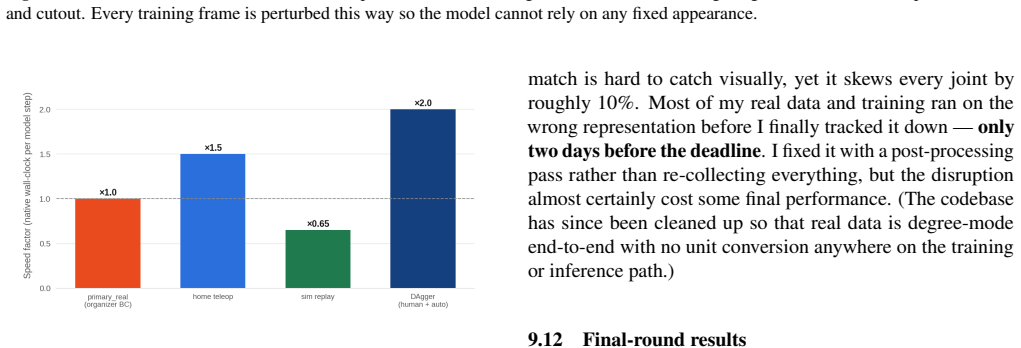

read the original abstract
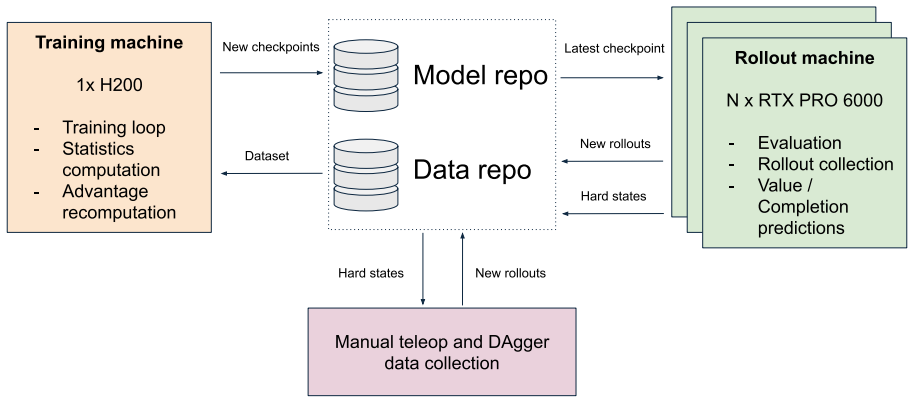
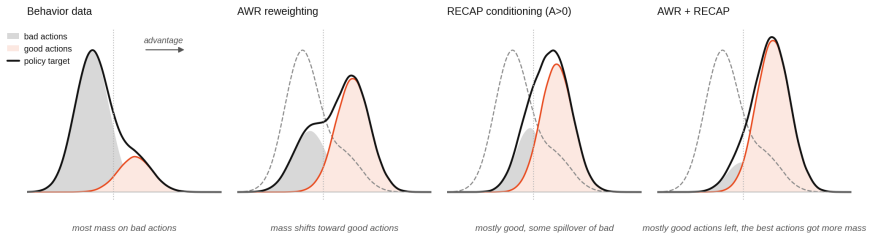
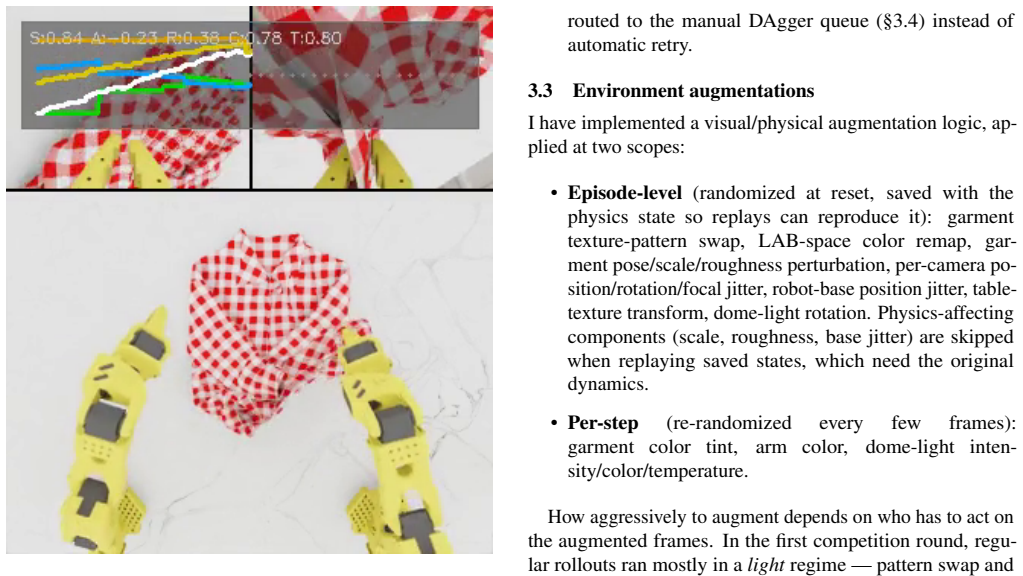
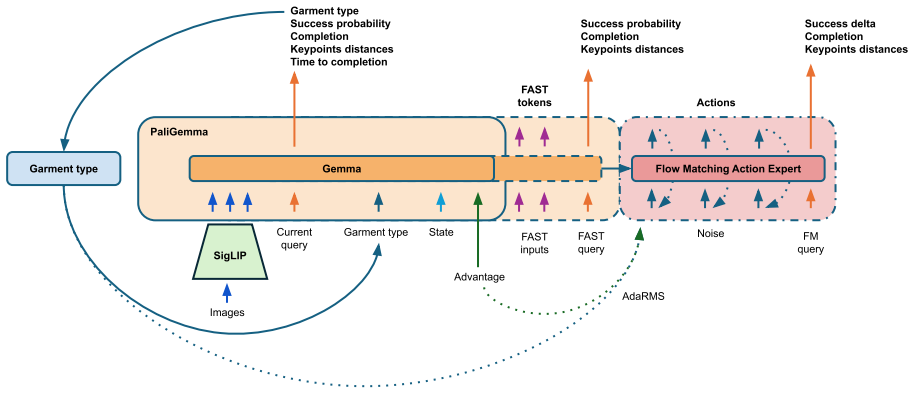
I describe my solution to the LeHome Challenge 2026, an ICRA 2026 competition on bimanual garment folding. The system placed 1st of 62 teams in the online (simulation) round and 2nd in the real-world final. It improves a vision-language-action (VLA) policy with a reinforcement-learning loop. The policy is its own value function: the same network that predicts actions also predicts success, progress, and a few task-relevant future quantities, and those predictions drive advantage estimation, live failure detection, and candidate selection. The work mostly recombines existing RL ideas with engineering and optimization contributions that can be used together as one recipe or individually: AWR + RECAP combined for flow-matching VLA; an asynchronous distributed training / rollout pipeline through HuggingFace Hub; inference-time hyperparameters optimization via Thompson sampling; a sim-to-real recipe with camera-alignment tooling, heavy augmentation and DAgger-like HIL data collection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a 1st-place (online, 62 teams) and 2nd-place (offline) solution to the LeHome Challenge 2026 on bimanual garment folding. It augments a vision-language-action (VLA) policy with an RL loop in which the same network predicts actions together with success, progress, and task-relevant future quantities; these predictions are used for advantage estimation (via AWR+RECAP on a flow-matching VLA), live failure detection, and candidate selection. The work emphasizes engineering contributions—an asynchronous distributed training/rollout pipeline via Hugging Face Hub, Thompson sampling for inference-time hyperparameters, and a sim-to-real recipe with camera alignment, heavy augmentation, and DAgger-style HIL collection—that can be used individually or together.
Significance. If the self-value mechanism is shown to be reliable, the manuscript supplies a practical, modular recipe for applying RL to VLA policies in contact-rich robotics without separate value networks. The competition rankings provide external empirical support for the integrated system, and the listed engineering components (async pipeline, sim-to-real augmentations) are independently reusable. The absence of component-level validation, however, prevents clear attribution of performance gains to the self-predicted quantities versus the surrounding infrastructure.
major comments (2)
- [Abstract] Abstract: the claim that the policy network's own auxiliary heads for success, progress, and future quantities 'drive' advantage estimation, live failure detection, and candidate selection is load-bearing, yet the manuscript supplies no calibration metrics, bias analysis, or comparison against ground-truth outcomes for these heads.
- [Abstract] Abstract: no ablations, error bars, or controlled comparisons are reported that isolate the contribution of the self-value mechanism from the other listed engineering elements (asynchronous pipeline, Thompson sampling, sim-to-real augmentations).
minor comments (1)
- The abstract and title emphasize competition placement; a short methods overview paragraph would help readers locate the technical novelty before the results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our competition entry. We address the two major comments below, focusing on validation of the self-predicted quantities and isolation of contributions. The work is primarily an engineering recipe validated through competition rankings rather than controlled lab experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the policy network's own auxiliary heads for success, progress, and future quantities 'drive' advantage estimation, live failure detection, and candidate selection is load-bearing, yet the manuscript supplies no calibration metrics, bias analysis, or comparison against ground-truth outcomes for these heads.
Authors: We acknowledge that the manuscript lacks explicit calibration metrics, bias analysis, or direct ground-truth comparisons for the auxiliary heads. This stems from the paper's focus on the integrated competition system rather than isolated head validation. In revision we will add available post-hoc analysis from rollout logs (e.g., success prediction accuracy against observed outcomes and simple bias checks) where data permits, while noting that full controlled ground-truth collection was outside the competition scope. revision: partial
-
Referee: [Abstract] Abstract: no ablations, error bars, or controlled comparisons are reported that isolate the contribution of the self-value mechanism from the other listed engineering elements (asynchronous pipeline, Thompson sampling, sim-to-real augmentations).
Authors: We agree that component-level ablations would aid attribution. However, the manuscript reports an integrated system whose performance was externally validated by competition rankings (1st/62 online, 2nd offline). Conducting new controlled ablations isolating the self-value heads from the pipeline, Thompson sampling, and sim-to-real recipe is not feasible within the post-competition timeline and resource constraints. We will revise the text to more clearly state that the engineering elements are modular and reusable independently, and to frame the competition results as system-level evidence rather than per-component proof. revision: no
Circularity Check
No circularity; external competition ranking validates performance independently of internal predictions.
full rationale
The paper describes an applied engineering system (VLA policy with auxiliary heads for success/progress/future quantities driving AWR-style advantage, failure detection, and selection) that recombines existing RL methods plus engineering contributions. Its central claim is competition placement (1st/62 online, 2nd offline), an external benchmark independent of any fitted parameters or self-referential equations. No derivation chain, equations, or load-bearing self-citations are present that reduce to the paper's own inputs by construction. The auxiliary predictions are used as described but their accuracy is not claimed via internal math; success is measured externally. This matches the default expectation of no circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- inference-time hyperparameters
Reference graph
Works this paper leans on
-
[1]
1st Simulation- Driven Competition on Deformable Object Manipula- tion
R. Wu, Y . Wang, Z. Li, Y . Chen, A. Longhini, et al. (LeHome Challenge Organizers).LeHome Chal- lenge 2026 — Challenge on Garment Manipulation Skill Learning in Household Scenarios(“1st Simulation- Driven Competition on Deformable Object Manipula- tion”; ICRA 2026 competition, Vienna, 1–5 June 2026). Website: https://lehome-challenge.com/ ; code: https:/...
2026
-
[2]
Cadene, S
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zoui- tine, et al.LeRobot: State-of-the-art Machine Learning for Real-World Robotics in PyTorch.2024. https: //github.com/huggingface/lerobot
2024
-
[3]
SO-ARM100 / SO-ARM101: Standard Open Arms.2024
The Robot Studio, in collaboration with Hugging Face. SO-ARM100 / SO-ARM101: Standard Open Arms.2024. https://github.com/TheRobotStudio/SO -ARM100
2024
-
[4]
S. Gao, M. Pagnucco, T. Bednarz, Y . Song.NVIDIA Isaac Sim: Enabling Scalable, GPU-Accelerated Simu- lation for Robotics.arXiv:2606.03551, 2026. https: //arxiv.org/abs/2606.03551
Pith/arXiv arXiv 2026
-
[5]
X. B. Peng, A. Kumar, G. Zhang, S. Levine.Advantage- Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning.arXiv:1910.00177, 2019. ht tps://arxiv.org/abs/1910.00177
Pith/arXiv arXiv 1910
-
[6]
π∗ 0.6: a VLA That Learns From Experience.arXiv:2511.14759, 2025
Physical Intelligence et al. π∗ 0.6: a VLA That Learns From Experience.arXiv:2511.14759, 2025. https: //arxiv.org/abs/2511.14759
Pith/arXiv arXiv 2025
-
[7]
I. Larchenko, G. Zarin, A. Karnatak.Task Adaptation of Vision-Language-Action Model: 1st Place Solution for the 2025 BEHAVIOR Challenge.arXiv:2512.06951, 2025.https://arxiv.org/abs/2512.06951
arXiv 2025
-
[8]
K. Black et al. (Physical Intelligence). π0.5: a Vision- Language-Action Model with Open-World Generaliza- tion.arXiv:2504.16054, 2025. https://arxiv.or g/abs/2504.16054
Pith/arXiv arXiv 2025
-
[9]
A. Nair, A. Gupta, M. Dalal, S. Levine.AWAC: Ac- celerating Online Reinforcement Learning with Offline Datasets.arXiv:2006.09359, 2020. https://arxiv. org/abs/2006.09359
Pith/arXiv arXiv 2006
-
[10]
S. Ross, G. Gordon, D. Bagnell.A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning (DAgger).AISTATS 2011, PMLR 15, pp. 627– 635.https://arxiv.org/abs/1011.0686
Pith/arXiv arXiv 2011
-
[11]
J. Luo, C. Xu, J. Wu, S. Levine.Precise and Dexter- ous Robotic Manipulation via Human-in-the-Loop Rein- forcement Learning (HIL-SERL).Science Robotics, vol. 10, eads5033, 2025. DOI:10.1126/scirobotics.ads5033. arXiv:2410.21845. https://www.science.org/ doi/10.1126/scirobotics.ads5033
-
[12]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov.Proximal Policy Optimization Algorithms. arXiv:1707.06347, 2017. https://arxiv.org/ abs/1707.06347
Pith/arXiv arXiv 2017
-
[13]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, et al. DeepSeekMath: Pushing the Limits of Mathematical Rea- soning in Open Language Models.arXiv:2402.03300, 2024.https://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[14]
Y . Sun, J. Shen, Y . Wang, T. Chen, Z. Wang, M. Zhou, H. Zhang.Improving Data Efficiency for LLM Reinforce- ment Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay.arXiv:2506.05316, 2025.https://arxiv.org/abs/2506.05316
arXiv 2025
-
[15]
X. Zhai, B. Mustafa, A. Kolesnikov, L. Beyer.Sigmoid Loss for Language Image Pre-Training.ICCV 2023. arXiv:2303.15343. https://arxiv.org/abs/23 03.15343 24
Pith/arXiv arXiv 2023
-
[16]
Gemma Team, Google DeepMind.Gemma: Open Models Based on Gemini Research and Technology. arXiv:2403.08295, 2024. https://arxiv.org/ abs/2403.08295
Pith/arXiv arXiv 2024
-
[17]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, M. Le.Flow Matching for Generative Modeling.ICLR
-
[18]
https://arxiv.org/ab s/2210.02747
arXiv:2210.02747. https://arxiv.org/ab s/2210.02747
-
[19]
K. Pertsch et al.FAST: Efficient Action Tokenization for Vision-Language-Action Models.arXiv:2501.09747, 2025.https://arxiv.org/abs/2501.09747
Pith/arXiv arXiv 2025
-
[20]
Zhai.Exclusive Self Attention.arXiv:2603.09078, 2026.https://arxiv.org/abs/2603.09078
S. Zhai.Exclusive Self Attention.arXiv:2603.09078, 2026.https://arxiv.org/abs/2603.09078
arXiv 2026
-
[21]
TRI LBM Team.A Careful Examination of Large Be- havior Models for Multitask Dexterous Manipulation. arXiv:2507.05331, 2025. https://arxiv.org/ab s/2507.05331
Pith/arXiv arXiv 2025
-
[22]
J. Schulman, P. Moritz, S. Levine, M. I. Jordan, P. Abbeel.High-Dimensional Continuous Control Us- ing Generalized Advantage Estimation.ICLR 2016. arXiv:1506.02438. https://arxiv.org/abs/ 1506.02438
Pith/arXiv arXiv 2016
-
[23]
A. Deng, Y . Xu, R. Kohavi, T. Walker.Improving the Sensitivity of Online Controlled Experiments by Utiliz- ing Pre-Experiment Data.WSDM 2013, pp. 123–132. DOI:10.1145/2433396.2433413. https://exp-pla tform.com/Documents/2013-02-CUPED-I mprovingSensitivityOfControlledExper iments.pdf
-
[24]
K. Black, M. Y . Galliker, S. Levine (Physical Intelli- gence).Real-Time Execution of Action Chunking Flow Policies.arXiv:2506.07339, 2025. https://arxiv. org/abs/2506.07339
Pith/arXiv arXiv 2025
-
[25]
J. Ho, T. Salimans.Classifier-Free Diffusion Guidance. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications; arXiv:2207.12598, 2022. https://arxiv.org/abs/2207.12598
Pith/arXiv arXiv 2021
-
[26]
W. R. Thompson.On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples.Biometrika, vol. 25, no. 3–4, pp. 285– 294, 1933. DOI:10.1093/biomet/25.3-4.285. https: //doi.org/10.1093/biomet/25.3-4.285
-
[27]
Russo, B
D. Russo, B. Van Roy, A. Kazerouni, I. Osband, Z. Wen. A Tutorial on Thompson Sampling.Foundations and Trends in Machine Learning, vol. 11, no. 1, pp. 1–96,
-
[28]
DOI:10.1561/2200000070. https://arxiv. org/abs/1707.02038 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.