Envisage: Diffusion-Based Rhinoplasty Goal Visualization with Mask-Decomposed Evaluation
Pith reviewed 2026-06-30 00:33 UTC · model grok-4.3
The pith
Full-face identity metrics are structurally confounded under hard-composited edits, so mask-decomposed SurgicalScore is required to evaluate localized rhinoplasty visualization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Localized generative editing needs localized evaluation because full-image identity metrics are structurally confounded under hard-composited edits. Envisage combines FLUX.1-Fill inpainting with eight rhinoplasty clinical presets and hard-mask compositing to produce goal visualizations that preserve outside-mask pixels by construction. SurgicalScore, a mask-decomposed 0-1 protocol, scores edit direction, edit magnitude, masked LPIPS, realism, and outside-mask preservation; it assigns Envisage the highest value of 0.599 on 211 cases while all methods exhibit negative ArcFace gain. The results indicate that progress on localized edits should be measured with edit-region fidelity rather than fu
What carries the argument
SurgicalScore, a mask-decomposed 0-1 protocol that evaluates five separate components of a localized edit to isolate the changed region from preserved background pixels.
If this is right
- Envisage records the highest SurgicalScore of 0.599 among the tested methods on the 211-case set.
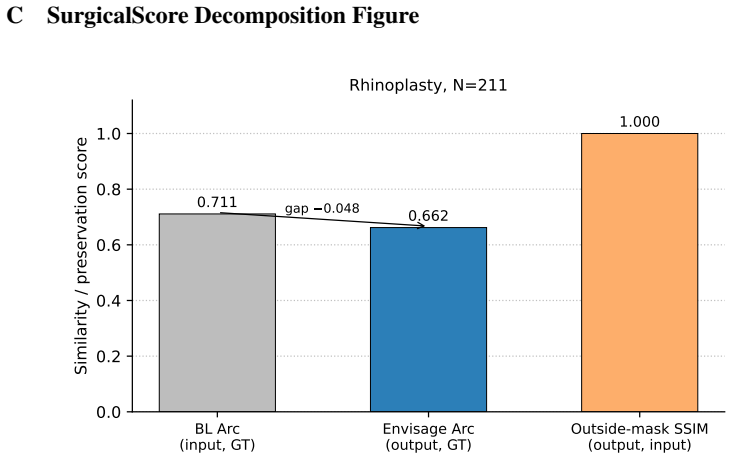
- Paired ArcFace gain remains negative for every method, with Envisage showing the smallest drop at -0.048.
- A 5-seed ground-truth oracle reduces the residual ArcFace gap by 73 percent and produces positive gain on 33.9 percent of cases.
- External validation on a 457-pair corpus confirms a larger negative ArcFace gap.
- For localized surgical edits, evaluation must shift from full-face identity to edit-region fidelity metrics.
Where Pith is reading between the lines
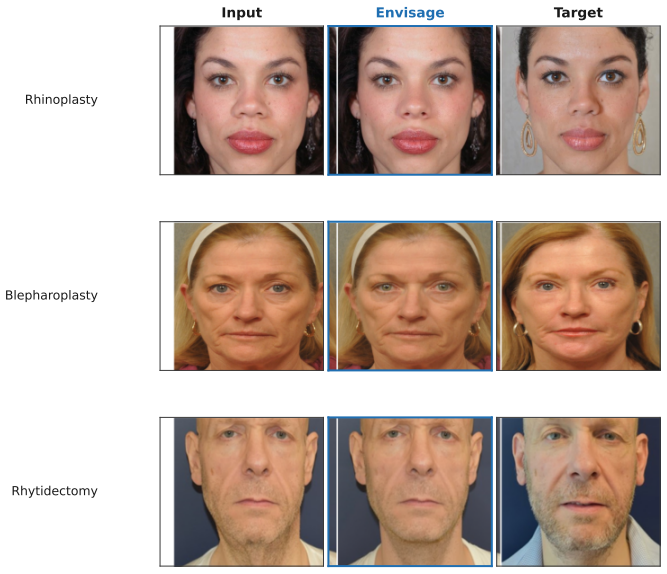
- The same preset and mask framework could be applied to the released blepharoplasty and rhytidectomy cases to test generalization across facial procedures.
- A learned ranker trained to pick the best seed from multiple generations could narrow more of the remaining gap to the oracle bound.
- If SurgicalScore is adopted, future diffusion backbones could be fine-tuned directly against its components rather than against general image quality objectives.
Load-bearing premise
The five components of SurgicalScore collectively capture clinical surgical accuracy and goal visualization quality without needing external clinical validation of the presets or the scoring weights.
What would settle it
A direct comparison of SurgicalScore rankings against independent ratings by board-certified plastic surgeons on the same 211 cases would show whether the metric aligns with clinical judgment.
Figures

read the original abstract
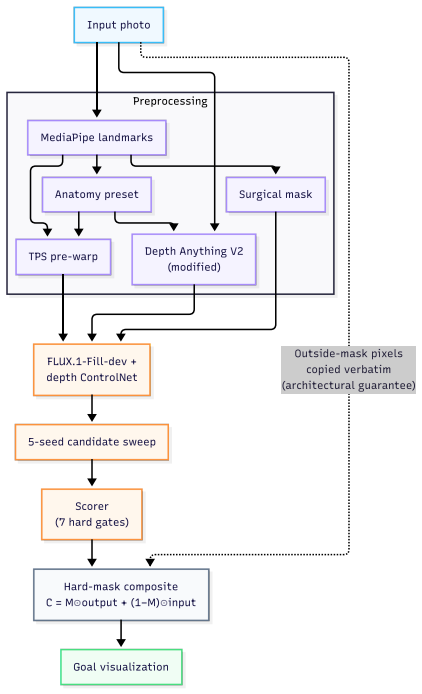
Localized generative editing needs localized evaluation: full-image identity metrics are structurally confounded under hard-composited edits. We present Envisage, a FLUX.1-Fill inpainting reference pipeline for rhinoplasty goal visualization from a single frontal photograph. The pipeline combines 8 rhinoplasty clinical presets (the released framework also includes 8 blepharoplasty and 8 rhytidectomy presets), MediaPipe masks, and hard-mask compositing. The composite preserves outside-mask pixels by construction, so full-face identity scores are dominated by copied pixels rather than by the diffusion backbone. Because full-face identity metrics cannot grade localized edits, we introduce SurgicalScore, a mask-decomposed 0-1 protocol scoring edit direction, edit magnitude, masked LPIPS, realism, and outside-mask preservation; SS_raw assigns 0.919 [0.918, 0.920] to a perfect-predictor control , anchoring the ceiling. On N=211, the paired ArcFace gain (output-to-GT minus input-to-GT) is negative for all methods (Envisage -0.048 smallest, vs. ICEdit -0.139, Kontext -0.242, InstructPix2Pix -0.294; p < 1e-4), with external validation on a 457-pair ASPS/PCA corpus showing a larger negative gap. With SurgicalScore, Envisage achieves the highest score (0.599 [0.579, 0.619]) and leads on both metrics, but the all-negative ArcFace gap shows that full-face identity is poorly aligned with localized surgical accuracy under hard compositing. A 5-seed GT-oracle (an upper bound, not a deployable result) reduces the residual ArcFace gap by 73% (-0.054 to -0.015), with positive output-to-GT gain on 33.9% of cases, indicating candidate-space headroom for a learned ranker. For localized edits, progress should be measured with edit-region fidelity rather than full-face identity metrics. We release Envisage, SurgicalScore, preset definitions, and matched split manifests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Envisage, a FLUX.1-Fill inpainting pipeline for rhinoplasty goal visualization from a single frontal photo using 8 clinical presets, MediaPipe masks, and hard-mask compositing. It argues that full-face identity metrics (e.g., ArcFace) are structurally confounded under localized edits, reports negative paired ArcFace gains for all methods on N=211 cases (Envisage least negative at -0.048), and introduces SurgicalScore—a mask-decomposed 0-1 metric on edit direction, magnitude, masked LPIPS, realism, and outside-mask preservation—where Envisage scores highest at 0.599. A perfect-predictor control reaches 0.919, external validation on a 457-pair ASPS/PCA corpus is shown, a 5-seed oracle reduces the ArcFace gap by 73%, and the framework, presets, and manifests are released.
Significance. If SurgicalScore is shown to track clinical judgments, the work could usefully redirect evaluation of localized medical generative edits away from full-face identity metrics and supply a reproducible pipeline for rhinoplasty visualization. The explicit release of presets, code, and split manifests is a clear strength for reproducibility. The demonstration that identity metrics yield uniformly negative gains under hard compositing is a concrete observation, but the absence of external anchoring for SurgicalScore limits the strength of claims about clinical superiority.
major comments (3)
- [SurgicalScore protocol] SurgicalScore protocol: the five components (edit direction, edit magnitude, masked LPIPS, realism, outside-mask preservation) and their aggregation weights are defined internally with no reported correlation to board-certified surgeon ratings, no inter-rater agreement on the N=211 cases, and no sensitivity analysis on the weighting scheme; this is load-bearing for the claim that the 0.599 score demonstrates superior clinical goal visualization relative to ArcFace.
- [Results on N=211 cases] Results on N=211 cases: the assertion that the uniformly negative ArcFace gains (Envisage -0.048 vs. others more negative) show full-face identity is 'poorly aligned with localized surgical accuracy' is circular because it treats SurgicalScore as the reference without independent clinical validation of either the presets or the metric.
- [Clinical presets] Clinical presets: the 8 rhinoplasty presets (and the additional blepharoplasty/rhytidectomy sets) are asserted without external clinical derivation, surgeon review, or anchoring data, which underpins the pipeline's claimed relevance for goal visualization.
minor comments (2)
- The abstract and results report confidence intervals for SurgicalScore and the perfect-predictor control but do not state how they were computed (bootstrap, seeds, etc.); adding this detail would improve clarity.
- A table listing the exact weighting or scoring rules for each of the five SurgicalScore terms would make the metric definition more transparent and easier to reproduce.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for noting the reproducibility strengths of the released framework, presets, and manifests. We respond point-by-point to the major comments below, with clarifications on the scope of our claims and planned revisions where appropriate.
read point-by-point responses
-
Referee: [SurgicalScore protocol] SurgicalScore protocol: the five components (edit direction, edit magnitude, masked LPIPS, realism, outside-mask preservation) and their aggregation weights are defined internally with no reported correlation to board-certified surgeon ratings, no inter-rater agreement on the N=211 cases, and no sensitivity analysis on the weighting scheme; this is load-bearing for the claim that the 0.599 score demonstrates superior clinical goal visualization relative to ArcFace.
Authors: SurgicalScore is proposed as a mask-decomposed protocol specifically to address the structural confounding of full-face identity metrics under hard compositing, where the majority of pixels are copied from the input. The five components are selected to isolate edit-region properties (direction, magnitude, masked LPIPS), global realism, and outside-mask fidelity; the perfect-predictor control at 0.919 [0.918, 0.920] provides an empirical ceiling. We acknowledge that no correlation with board-certified surgeon ratings or inter-rater agreement on the N=211 cases is reported, and no sensitivity analysis on the aggregation weights was performed. These are genuine limitations. We will revise the manuscript to qualify the interpretation of the 0.599 score as relative performance on this protocol rather than absolute clinical superiority, and to add an explicit limitations paragraph on the absence of external clinical anchoring and sensitivity analysis. revision: partial
-
Referee: [Results on N=211 cases] Results on N=211 cases: the assertion that the uniformly negative ArcFace gains (Envisage -0.048 vs. others more negative) show full-face identity is 'poorly aligned with localized surgical accuracy' is circular because it treats SurgicalScore as the reference without independent clinical validation of either the presets or the metric.
Authors: The uniformly negative paired ArcFace gains are an independent empirical observation obtained directly from the N=211 cases (Envisage -0.048, others more negative; p < 1e-4) and replicated on the external 457-pair ASPS/PCA corpus. This result follows from the hard-mask compositing construction, which preserves the large majority of pixels outside the edit region; identity metrics therefore reflect input similarity more than edit quality. The statement that full-face identity is poorly aligned with localized surgical accuracy is grounded in this consistent negative direction across all methods, not in SurgicalScore. We will revise the relevant paragraph to separate the empirical ArcFace finding from the introduction of SurgicalScore and to avoid any phrasing that could be read as circular. revision: yes
-
Referee: [Clinical presets] Clinical presets: the 8 rhinoplasty presets (and the additional blepharoplasty/rhytidectomy sets) are asserted without external clinical derivation, surgeon review, or anchoring data, which underpins the pipeline's claimed relevance for goal visualization.
Authors: The eight rhinoplasty presets encode standard clinical goals (dorsal hump reduction, tip refinement and rotation, alar base adjustment, etc.) drawn from established rhinoplasty planning descriptions. The released code and manifests contain the exact parameter values for each preset to support reproducibility. We did not conduct a dedicated surgeon derivation study or review for this manuscript. We will revise the methods section to include citations to clinical literature supporting these visualization targets and to clarify that the presets represent representative goal visualizations rather than patient-specific surgical plans. revision: partial
- Absence of correlation between SurgicalScore and board-certified surgeon ratings
- Absence of inter-rater agreement on the N=211 cases
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines SurgicalScore independently as a mask-decomposed 0-1 protocol with five explicit components (edit direction, edit magnitude, masked LPIPS, realism, outside-mask preservation) and anchors it with a perfect-predictor control reaching 0.919. The headline result (Envisage highest at 0.599 on N=211) is reported against this metric while simultaneously showing negative ArcFace gains for all methods on both internal and external ASPS/PCA corpora. No equations reduce a prediction to a fitted input by construction, no self-citation chains justify uniqueness or ansatzes, and the claim that full-face metrics are confounded follows directly from the observed negative gains rather than from internal redefinition. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Masked LPIPS and the other four SurgicalScore components together measure clinical edit quality
- standard math Hard-mask compositing preserves outside-mask pixels exactly
invented entities (1)
-
SurgicalScore
no independent evidence
Reference graph
Works this paper leans on
-
[1]
American Society of Plastic Surgeons
GitHub reposi- tory. American Society of Plastic Surgeons. Photo gallery of patient results submitted by member sur- geons. https://www.plasticsurgery.org/photo-gallery, 2024a. Accessed: 2026-04-20. American Society of Plastic Surgeons. Plastic surgery statistics report
2026
-
[2]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
ASPS National Clear- inghouse, 2024b. https://www.plasticsurgery.org/documents/news/statistics/ 2024/plastic-surgery-statistics-report-2024.pdf . S. Batifol, A. Blattmann, F. Boesel, and others (Black Forest Labs). FLUX.1 Kontext: Flow matching for in-context image generation and editing in latent space. arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
doi: 10.3390/app152312376. Black Forest Labs. Announcing Black Forest Labs (FLUX.1 model release). Blog post,
-
[4]
Accessed 2026-04-20
URL https://bfl.ai/announcing-black-forest-labs/ . Accessed 2026-04-20. F. L. Bookstein. Principal warps: thin-plate splines and the decomposition of deformations. IEEE Transactions on Pattern Analysis and Machine Intelligence , 11(6):567–585,
2026
- [5]
-
[6]
doi: 10.1007/s00266-022-02883-x. R. Gal, O. Patashnik, H. Maron, A. H. Bermano, G. Chechik, and D. Cohen-Or. StyleGAN- NADA: CLIP-guided domain adaptation of image generators. ACM Transactions on Graphics (SIGGRAPH), 41(4),
- [7]
-
[8]
doi: 10.3389/fcell.2024.1459336. T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. In ICLR,
-
[9]
arXiv:1710.10196; CelebA-HQ released here. T. Karras, S. Laine, and T. Aila. A style-based generator architecture for generative adversarial networks. In CVPR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv:1812.04948; FFHQ released here. Y . Kartynnik, A. Ablavatski, I. Grishchenko, and M. Grundmann. Real-time facial surface geometry from monocular video on mobile GPUs. arXiv:1907.06724,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[11]
doi: 10.1038/s41467-025-57669-x. S. Knoedler, M. Alfertshofer, S. Simon, A. C. Panayi, R. Saadoun, A. Palackic, F. Falkner, G. Hunde- shagen, M. Kauke-Navarro, F. H. V ollbach, A. K. Bigdeli, and L. Knoedler. Turn your vision into reality: AI-powered pre-operative outcome simulation in rhinoplasty surgery. Aesthetic Plastic Surgery, 48(23):4833–4838,
-
[12]
doi: 10.1007/s00266-024-04043-9. 13 Jonathan Javier Loor-Duque, Rosaura Y okasta Bravo-Pita, Ariana Deyaneira Jiménez-Narváez, Freddy Raúl Guzmán-Suárez, and Manuel Eugenio Morocho-Cayamcela. Analysis of diffusion models for the prediction of the septorhinoplasty surgeries results. In Applied Engineering and Innovative Technologies (AENIT 2023), volume 11...
-
[13]
doi: 10.1007/978-3-031-70760-5_36. L. Ma, D. Kim, C. Lian, D. Xiao, T. Kuang, Q. Liu, Y . Lang, H. H. Deng, J. Gateno, Y . Wu, E. Y ang, M. A. K. Liebschner, J. J. Xia, and P .-T. Y ap. Deep simulation of facial appearance changes following craniomaxillofacial bony movements in orthognathic surgical planning. In Medical Image Computing and Computer Assist...
-
[14]
doi: 10.1007/978-3-030-87202-1_44. E. P . Monk. The monk skin tone scale,
-
[15]
doi: 10.1177/1090820X12469221. A. Newman, A. R. Caudill, E. Ball, and S. P . Davison. Revision rates in cosmetic plastic surgery with and without resident involvement. Plastic and Reconstructive Surgery – Global Open , 12(3): e5678,
-
[16]
doi: 10.1097/GOX.0000000000005678. M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P . Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P .-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jégou, J. Mairal, P . Labatut, A. Joulin, and P . Bojanowski. DINOv2: ...
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
URL https://openreview.net/forum? id=a68SUt6zFt. arXiv:2304.07193. D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. In ICLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv:2307.01952; SDXL inpainting checkpoint via diffusers/stable-diffusion-xl-1.0-inpainting- 0.1. C. Rathgeb, D. Dogan, F. Stockhardt, M. De Marsico, and C. Busch. Plastic surgery: An obstacle for deep face recognition? In CVPR Workshops, pages 806–807,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
automated assessment of aesthetic outcomes in facial plastic surgery
arXiv:2003.09373. P . V arghaei, K. Abraham-Aggarwal, M. T. Abraham, and A. Ross. Automated assessment of aes- thetic outcomes in facial plastic surgery, 2025a. URL https://arxiv.org/abs/2508.13363. arXiv preprint arXiv:2508.13363. P . V arghaei, K. Abraham-Aggarwal, M. T. Abraham, and A. Ross. SurFace1259 dataset, described in “automated assessment of ae...
-
[20]
arXiv:2504.20690. A Deployable K = 5 Ranker Probe The K = 5 best-of-5 oracle assumes GT access at scoring time. To assess whether a deployable (no-GT) ranker can recover the oracle gain, we evaluated six GT-free per-seed signals as candidate rankers on the five-seed-complete subset ( N =207): random selection, single fixed seed (K = 1 headline), max ArcFace...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
K= 5 oracle on N =207 (Envisage five-seed-complete cases)
Table 4: Naive no-GT rankers vs. K= 5 oracle on N =207 (Envisage five-seed-complete cases). Per- case oracle selection by true SurgicalScore raises the mean from 0.609 (K= 1 ) to 0.743 (+0.134). Deployable rankers based on identity preservation ( arccos(O, I)), realism (D), outside-mask SSIM (E), or combinations all score below the single-seed headline; th...
2024
-
[22]
younger upper eyelids with reduced skin excess, defined supratarsal crease
where all four methods produce outputs on the same filtered case set. F Blepharoplasty and Rhytidectomy Preset Definitions The Envisage framework includes 8 blepharoplasty and 8 rhytidectomy sub-procedure presets fol- lowing the same architecture as the rhinoplasty presets (Section 3.5). Each preset specifies (a) a landmark detection threshold derived from p...
2000
-
[23]
rhinoplasty post-op nose
into a numerical bound: for an inside-mask edit with L2 norm below ∼ 104 pixel-units, the full-face ArcFace cosine shift is upper-bounded by Lp95 · 104 ≈ 0.12. The bound is loose because pixel-L2 is a coarse upper bound on identity-space displacement, but it is informative: full-face metric drift under hard-mask compositing is demonstrably small whenever ...
2000
-
[24]
Source: released code and data
and the GT-paste-no-composite calibration anchor ( 0.703). Source: released code and data. Strategy N Mean SS 95% CI Single seed 42 (headline) 207 0.609 [0 .584, 0.634] Mean over 5 seeds (ensemble) 207 0.594 [0 .576, 0.612] Best of 5 (oracle) 207 0.743 [0.725, 0.762] GT-paste no-composite (calibration anchor) 211 0.703 [0 .649, 0.756] R Backbone Substitut...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.