Beyond Uniform Token-Level Trust Region in LLM Reinforcement Learning
Pith reviewed 2026-06-27 13:39 UTC · model grok-4.3
The pith
Position-weighted thresholds and cumulative prefix budgets align token updates with finite-horizon bounds in LLM RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
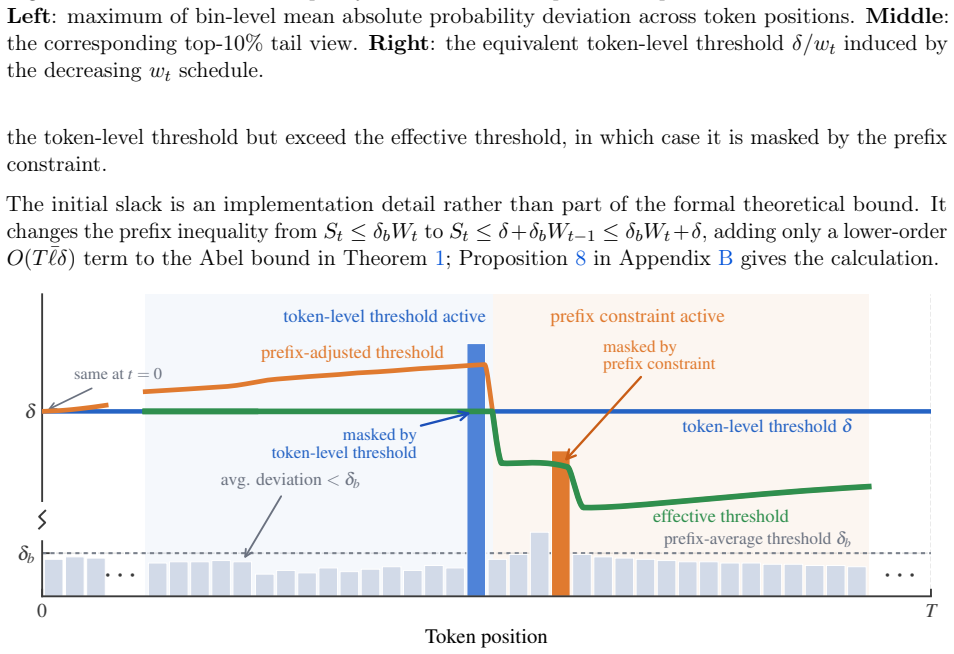
CPPO is a token-level masking rule that enforces a position-weighted threshold and a cumulative prefix budget so that every accepted update respects the finite-horizon policy-improvement bound; the first mechanism imposes stricter divergence limits on early tokens whose effects persist, while the second subtracts accumulated prefix drift from the remaining allowance before deciding whether a new token can be accepted.
What carries the argument
CPPO token-level masking rule that couples a position-weighted threshold with a cumulative prefix budget to enforce the finite-horizon policy-improvement bound.
If this is right
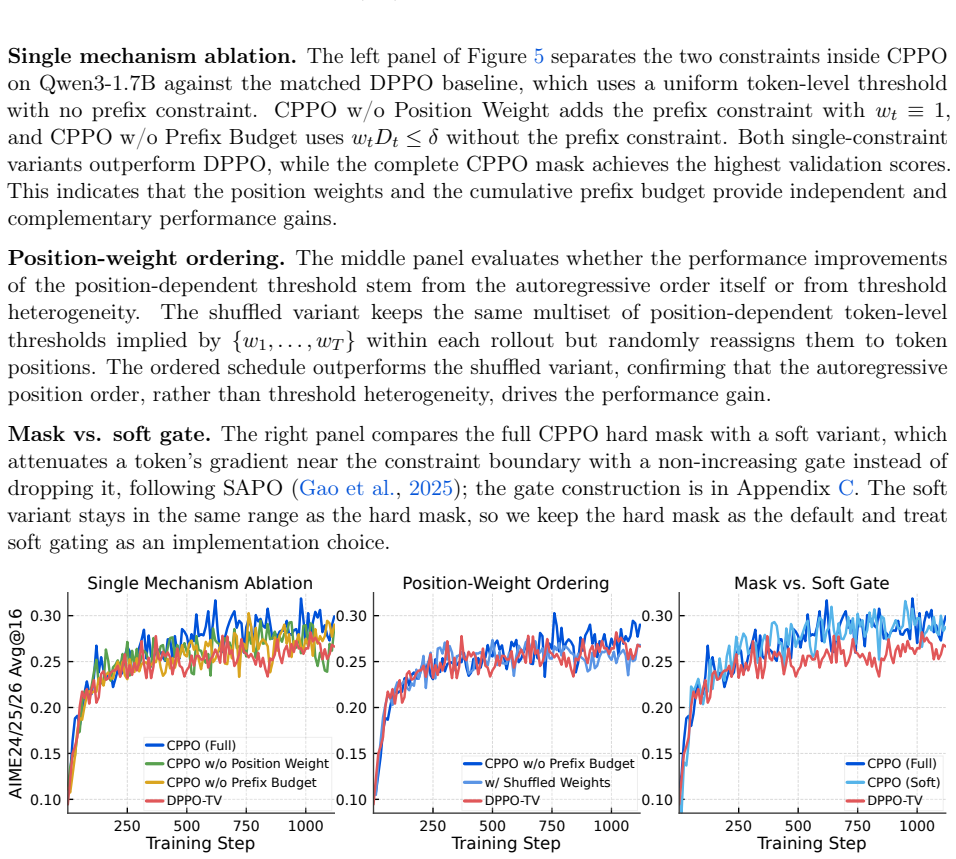
- Early-token updates receive tighter control while late-token updates receive more freedom.
- The running prefix budget automatically shrinks the allowed deviation once earlier tokens have already drifted.
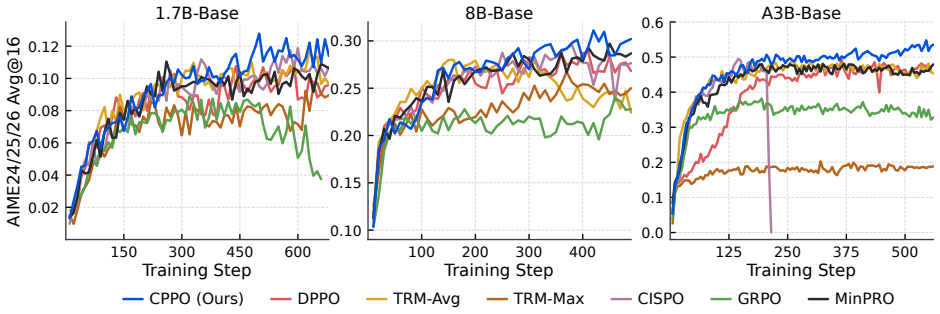
- Training curves become more stable and final reasoning accuracy rises across model scales.
- The method supplies a concrete way to keep PPO-style updates inside a finite-horizon improvement guarantee.
Where Pith is reading between the lines
- The same two mechanisms could be tested on non-reasoning tasks where sequence length varies widely.
- The prefix budget could be adapted to other autoregressive objectives such as code generation or long-form planning.
- If the bound holds, CPPO may allow larger per-token steps without increasing collapse risk.
Load-bearing premise
The reported stability and accuracy gains are produced by the position-weighted threshold and cumulative prefix budget rather than by other unstated implementation choices.
What would settle it
An ablation that disables either the position weighting or the prefix budget and shows the accuracy and stability gains disappear.
Figures

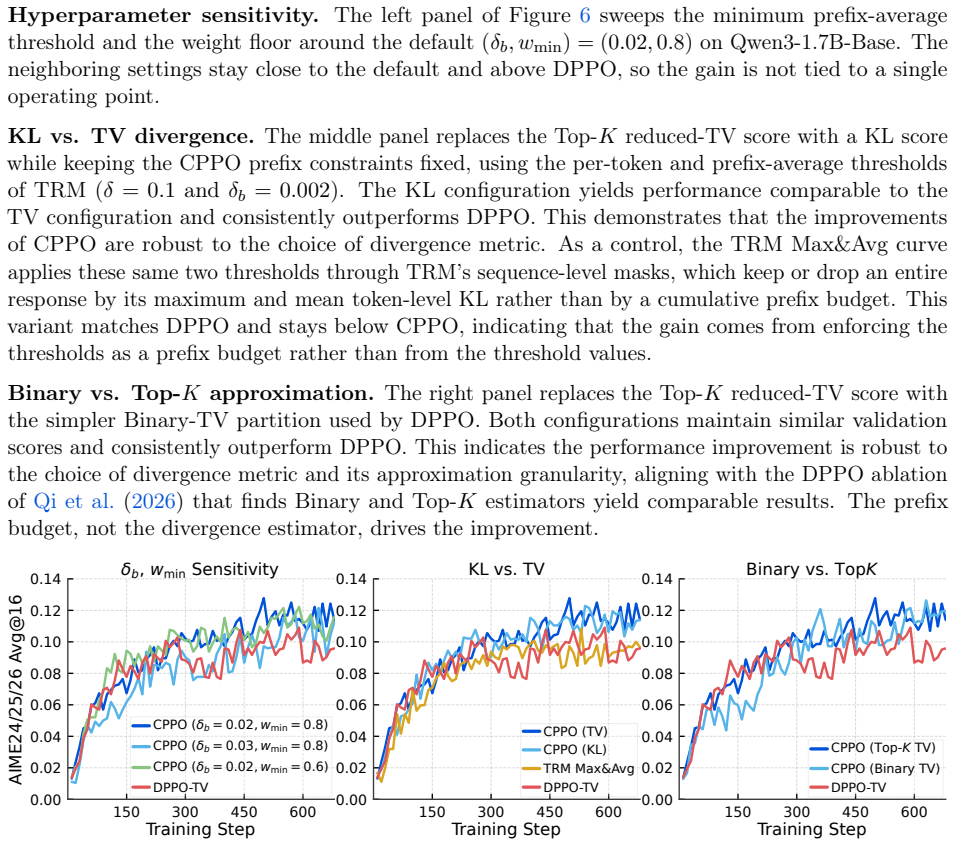
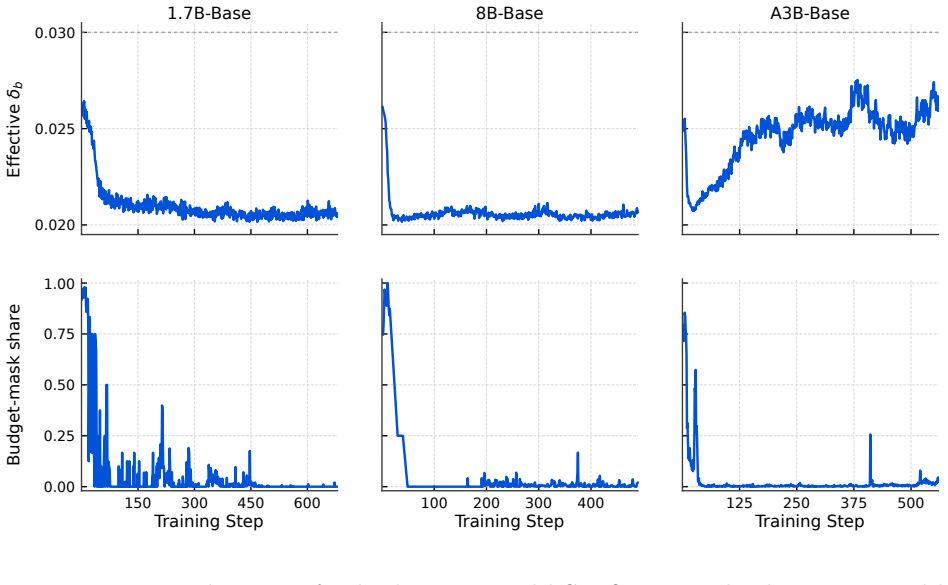
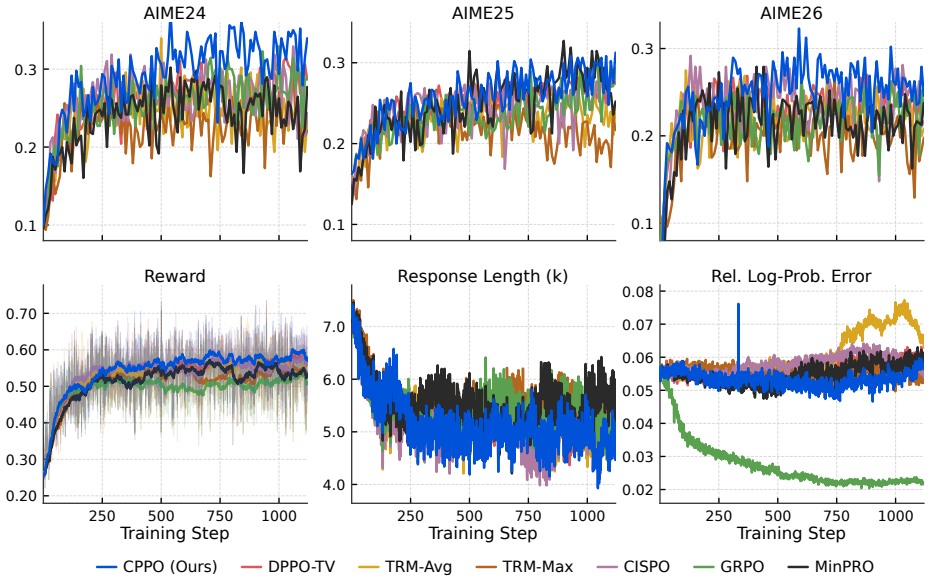
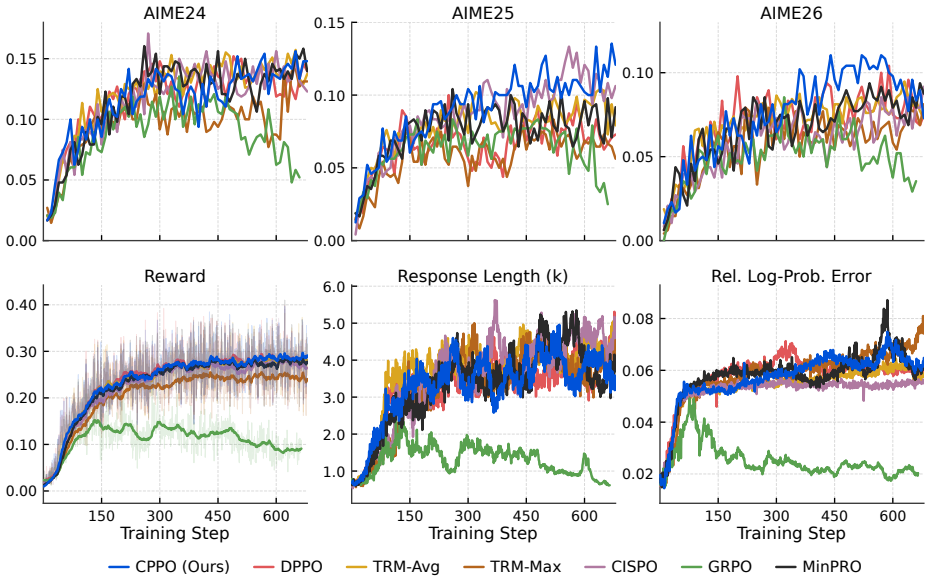
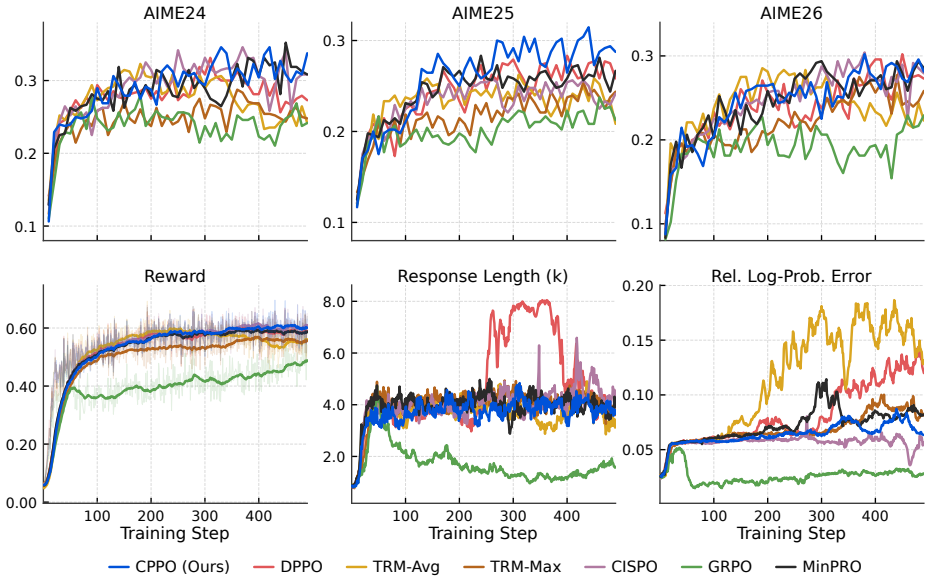
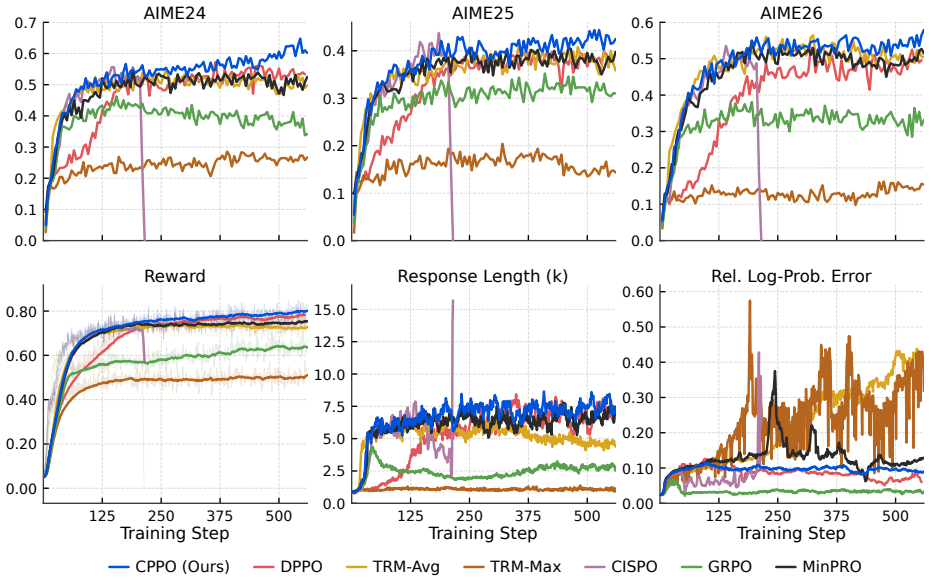
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become standard for improving LLM reasoning. However, existing PPO-style trust-region mechanisms remain position-agnostic by enforcing uniform thresholds across all tokens independently. This pointwise treatment conflicts with autoregressive generation in two critical ways. First, uniform thresholds ignore autoregressive asymmetry. Early-stage deviations produce compounding sequence-level drift, causing static thresholds to under-regulate early divergence and excessively constrain late-stage exploration. Second, evaluating token-level divergence in isolation overlooks cumulative prefix drift, granting the same divergence allowance regardless of how far the conditioning history has already deviated from the rollout policy. To address this limitation, we propose CPPO (Cumulative Prefix-divergence Policy Optimization), a token-level masking rule that aligns updates with a finite-horizon policy-improvement bound via two coupled mechanisms. First, a position-weighted threshold imposes stricter limits at early positions whose effects persist longer, relaxing constraints for late-stage tokens. Second, a cumulative prefix budget tracks historical deviations, dynamically restricting further token-level deviation to prevent compounding errors along the prefix. Empirically, CPPO enhances training stability and significantly improves reasoning accuracy across various model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CPPO (Cumulative Prefix-divergence Policy Optimization) as an improvement over standard PPO-style trust regions for RLVR in LLMs. It identifies two limitations of uniform token-level thresholds—failure to account for autoregressive compounding from early positions and cumulative prefix drift—and introduces a position-weighted threshold (stricter early, relaxed late) plus a cumulative prefix budget to enforce a finite-horizon policy-improvement bound. The method is claimed to yield more stable training and higher reasoning accuracy across model scales.
Significance. A mechanism that rigorously ties token-level masking to a finite-horizon improvement guarantee could address a genuine mismatch between pointwise trust regions and sequential generation; if the bound is shown to hold and the gains are isolated to the proposed components, the approach would be a useful refinement for autoregressive RL.
major comments (2)
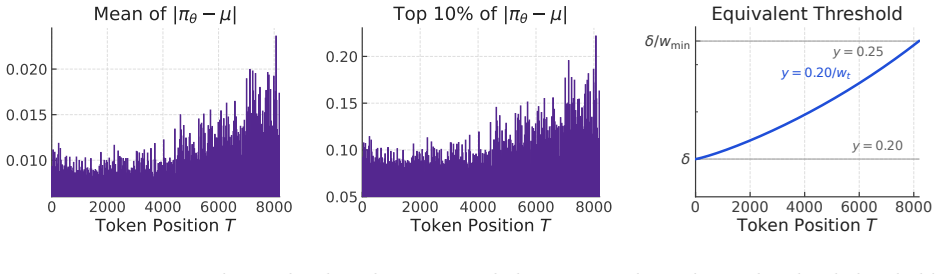
- [Abstract] Abstract and introduction: the central claim that the position-weighted threshold together with the cumulative prefix budget 'aligns updates with a finite-horizon policy-improvement bound' is asserted without any statement of the bound, derivation, or proof that the masking rule respects it. No equation or section supplies the total-variation or KL constraint that the two mechanisms are said to enforce.
- [Empirical results] Empirical evaluation (implied results section): no ablation isolating the two mechanisms from other implementation choices (clipping schedule, reward scaling, learning-rate schedule) is described, nor are error bars, number of seeds, or quantitative deltas provided; therefore the reported stability and accuracy gains cannot be attributed to the claimed alignment rather than incidental factors.
minor comments (2)
- Notation for the position-weighted threshold and prefix budget is introduced only descriptively; explicit formulas would clarify how the dynamic restriction is computed at each step.
- [Abstract] The abstract states improvements 'across various model scales' but supplies neither the scales nor the base models used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. We agree that both the theoretical claim and the empirical presentation require strengthening and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central claim that the position-weighted threshold together with the cumulative prefix budget 'aligns updates with a finite-horizon policy-improvement bound' is asserted without any statement of the bound, derivation, or proof that the masking rule respects it. No equation or section supplies the total-variation or KL constraint that the two mechanisms are said to enforce.
Authors: We agree that the abstract and introduction assert the alignment without an explicit statement of the bound. In the revision we will insert the finite-horizon policy-improvement bound (a token-wise adaptation of the standard total-variation or KL-constrained improvement guarantee) together with a short derivation showing how the position-weighted threshold and cumulative prefix budget jointly enforce the constraint. The equation and proof sketch will appear in Section 3. revision: yes
-
Referee: [Empirical results] Empirical evaluation (implied results section): no ablation isolating the two mechanisms from other implementation choices (clipping schedule, reward scaling, learning-rate schedule) is described, nor are error bars, number of seeds, or quantitative deltas provided; therefore the reported stability and accuracy gains cannot be attributed to the claimed alignment rather than incidental factors.
Authors: We acknowledge that the current results do not isolate the two proposed mechanisms via dedicated ablations and lack reported error bars or seed counts. In the revised manuscript we will add an ablation table that turns each component on and off while holding other hyperparameters fixed, report means and standard deviations over at least three seeds, and include quantitative deltas with respect to the PPO baseline. These additions will appear in the main results section and appendix. revision: yes
Circularity Check
No circularity: abstract asserts alignment with bound but supplies no equations or self-referential reductions
full rationale
The provided abstract and context contain no equations, fitted parameters, or derivations. The claim that the two mechanisms align updates with a finite-horizon policy-improvement bound is stated without showing the bound, the step-by-step argument, or any reduction to inputs. No self-citations, ansatzes, or renamings appear. This is the common case of an empirical proposal whose grounding (or lack thereof) lies outside the visible text; absence of a derivation does not create circularity. The derivation chain cannot be walked because none is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[3]
Proceedings of the nineteenth international conference on machine learning , pages=
Approximately optimal approximate reinforcement learning , author=. Proceedings of the nineteenth international conference on machine learning , pages=
-
[4]
International conference on machine learning , pages=
Constrained policy optimization , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Relative entropy policy search , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[6]
Riedmiller , title=
Abbas Abdolmaleki and Jost Tobias Springenberg and Yuval Tassa and Rémi Munos and Nicolas Heess and Martin A. Riedmiller , title=. CoRR , volume=. 2018 , cdate=
2018
-
[7]
Francis Song and Abbas Abdolmaleki and Jost Tobias Springenberg and Aidan Clark and Hubert Soyer and Jack W
H. Francis Song and Abbas Abdolmaleki and Jost Tobias Springenberg and Aidan Clark and Hubert Soyer and Jack W. Rae and Seb Noury and Arun Ahuja and Siqi Liu and Dhruva Tirumala and Nicolas Heess and Dan Belov and Martin A. Riedmiller and Matthew M. Botvinick , title=. CoRR , volume=. 2019 , cdate=
2019
-
[8]
CoRR , volume=
Yuhui Wang and Hao He and Xiaoyang Tan and Yaozhong Gan , title=. CoRR , volume=. 2019 , cdate=
2019
-
[9]
2019 , cdate=
Yuhui Wang and Hao He and Xiaoyang Tan , title=. 2019 , cdate=
2019
-
[10]
International Conference on Learning Representations , year=
Implementation Matters in Deep RL: A Case Study on PPO and TRPO , author=. International Conference on Learning Representations , year=
-
[11]
International Conference on Learning Representations , year=
What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study , author=. International Conference on Learning Representations , year=
-
[12]
The annals of mathematical statistics , volume=
On information and sufficiency , author=. The annals of mathematical statistics , volume=. 1951 , publisher=
1951
-
[13]
Long Ouyang and Jeff Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , title=. CoR...
2022
-
[14]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[15]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title=. CoRR , volume=. 2024 , cdate=
2024
-
[16]
Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Peiyi Wang and Qihao Zhu and Runxin Xu and Ruoyu Zhang and Shirong Ma and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Chengda Lu and Chen...
2025
-
[17]
2026 , url=
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
2026
-
[18]
Laminar: A scalable asynchronous RL post-training framework
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , title =. 2025 , isbn =. doi:10.1145/3689031.3696075 , booktitle =
-
[19]
CoRR , volume=
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
2025
-
[20]
CoRR , volume=
Aili Chen and Aonian Li and Bangwei Gong and Binyang Jiang and Bo Fei and Bo Yang and Boji Shan and Changqing Yu and Chao Wang and Cheng Zhu and Chengjun Xiao and Chengyu Du and Chi Zhang and Chu Qiao and Chunhao Zhang and Chunhui Du and Congchao Guo and Da Chen and Deming Ding and Dianjun Sun and Dong Li and Enwei Jiao and Haigang Zhou and Haimo Zhang an...
2025
-
[21]
Soft Adaptive Policy Optimization
Soft adaptive policy optimization , author=. arXiv preprint arXiv:2511.20347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2601.22718 , year=
A Step Back: Prefix Importance Ratio Stabilizes Policy Optimization , author=. arXiv preprint arXiv:2601.22718 , year=
-
[23]
CoRR , volume=
Xiangxiang Chu and Hailang Huang and Xiao Zhang and Fei Wei and Yong Wang , title=. CoRR , volume=. 2025 , month=
2025
-
[24]
Second Conference on Language Modeling , year=
Understanding R1-Zero-Like Training: A Critical Perspective , author=. Second Conference on Language Modeling , year=
-
[25]
2025 , url=
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models , author=. 2025 , url=
2025
-
[26]
CoRR , volume=
Shenzhi Wang and Le Yu and Chang Gao and Chujie Zheng and Shixuan Liu and Rui Lu and Kai Dang and Xionghui Chen and Jianxin Yang and Zhenru Zhang and Yuqiong Liu and An Yang and Andrew Zhao and Yang Yue and Shiji Song and Bowen Yu and Gao Huang and Junyang Lin , title=. CoRR , volume=. 2025 , month=
2025
-
[27]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization , author=. arXiv preprint arXiv:2501.03262 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
CoRR , volume=
Chujie Zheng and Shixuan Liu and Mingze Li and Xiong-Hui Chen and Bowen Yu and Chang Gao and Kai Dang and Yuqiong Liu and Rui Men and An Yang and Jingren Zhou and Junyang Lin , title=. CoRR , volume=. 2025 , month=
2025
-
[29]
Rethinking the Trust Region in LLM Reinforcement Learning
Rethinking the Trust Region in LLM Reinforcement Learning , author=. arXiv preprint arXiv:2602.04879 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Multi-Step Likelihood-Ratio Correction for Reinforcement Learning with Verifiable Rewards
Multi-Step Likelihood-Ratio Correction for Reinforcement Learning with Verifiable Rewards , author=. arXiv preprint arXiv:2605.20865 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
arXiv preprint arXiv:2603.19835 , year=
Fipo: Eliciting deep reasoning with future-kl influenced policy optimization , author=. arXiv preprint arXiv:2603.19835 , year=
-
[32]
Trust Region Masking for Long-Horizon LLM Reinforcement Learning
Trust Region Masking for Long-Horizon LLM Reinforcement Learning , author=. arXiv preprint arXiv:2512.23075 , year=
work page internal anchor Pith review arXiv
-
[33]
The Fourteenth International Conference on Learning Representations , year=
Geometric-Mean Policy Optimization , author=. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.