Gradient Smoothing: Coupling Layer-wise Updates for Improved Optimization
Pith reviewed 2026-07-01 06:34 UTC · model grok-4.3
The pith
Transforming optimizer updates along network depth via smoothing improves training and generalization in repeated-block architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
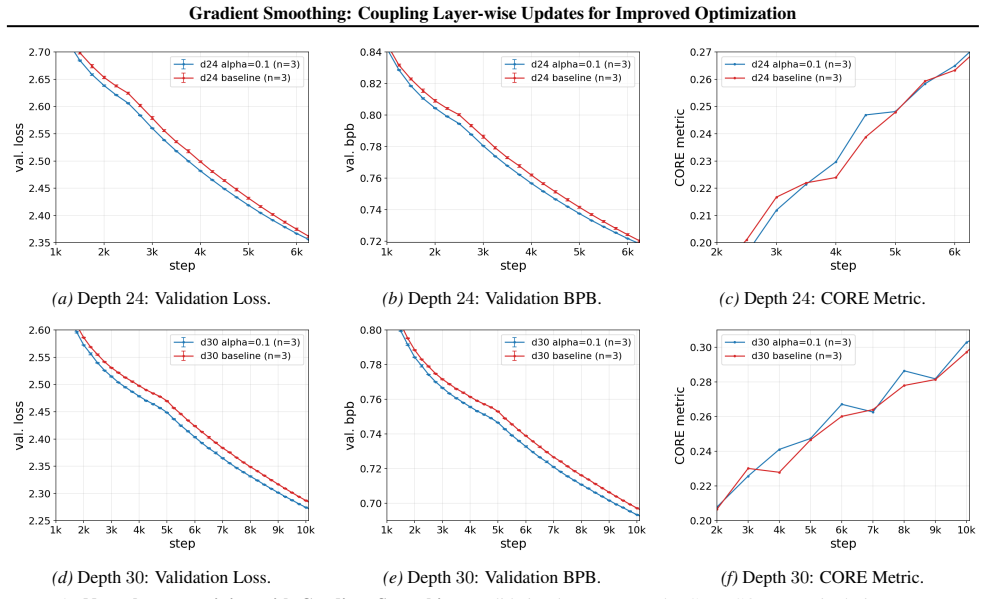
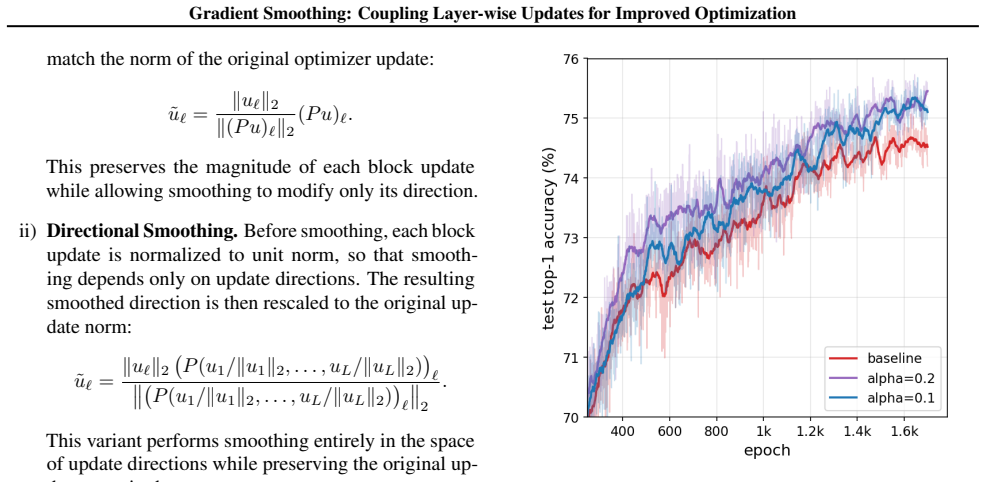
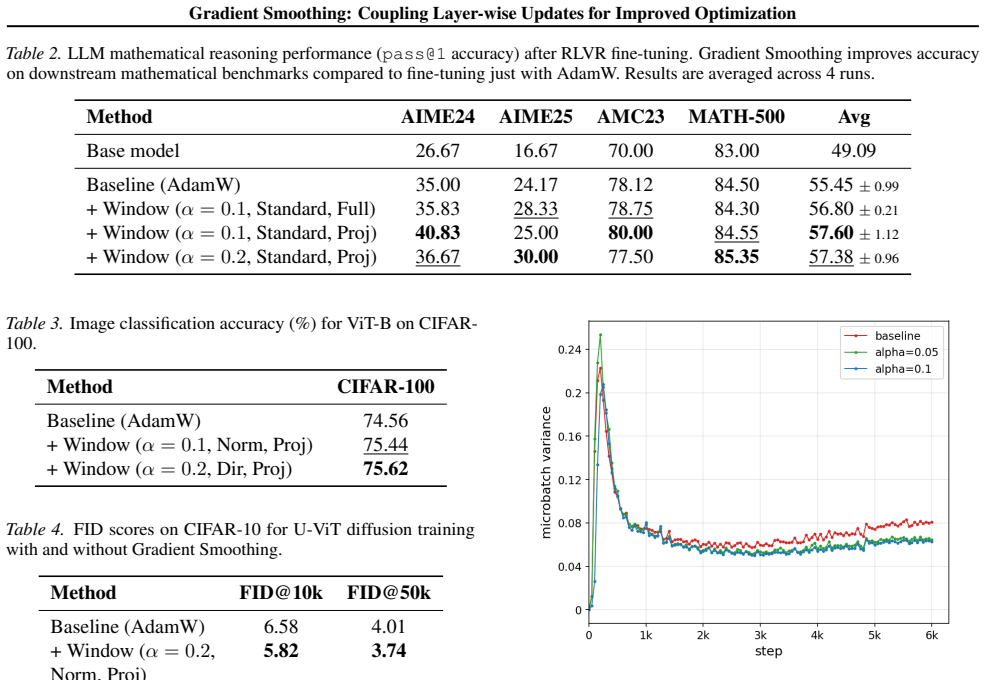
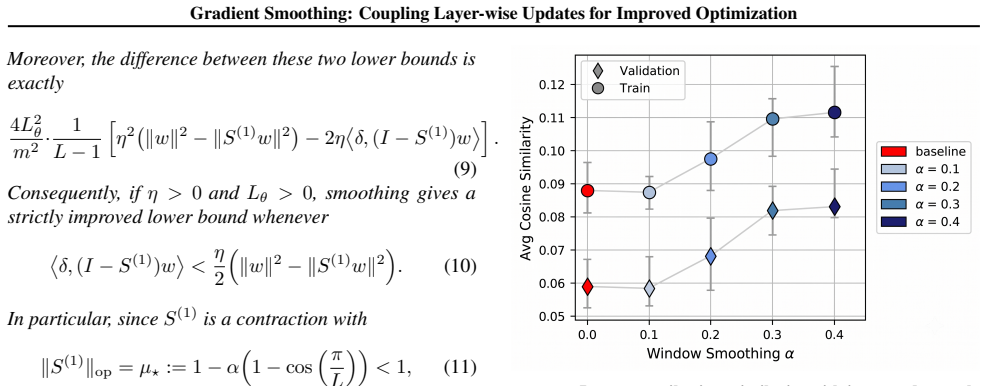
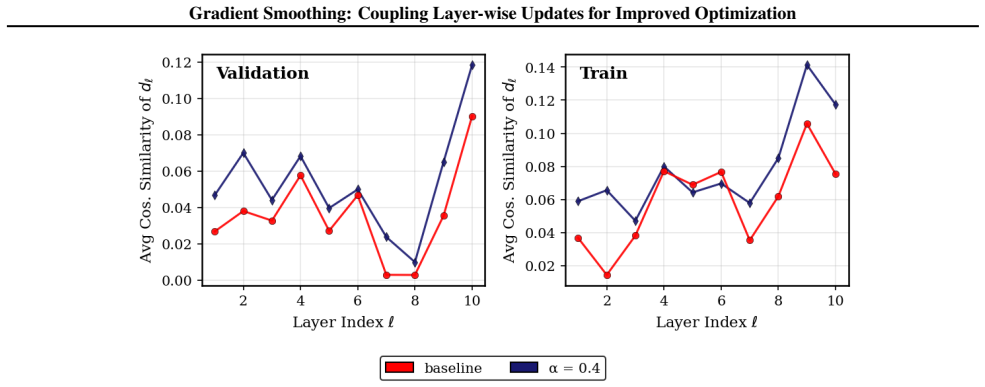
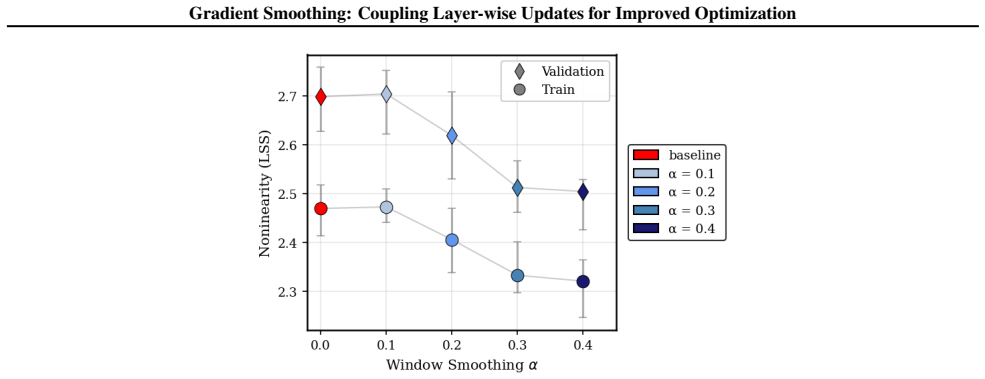
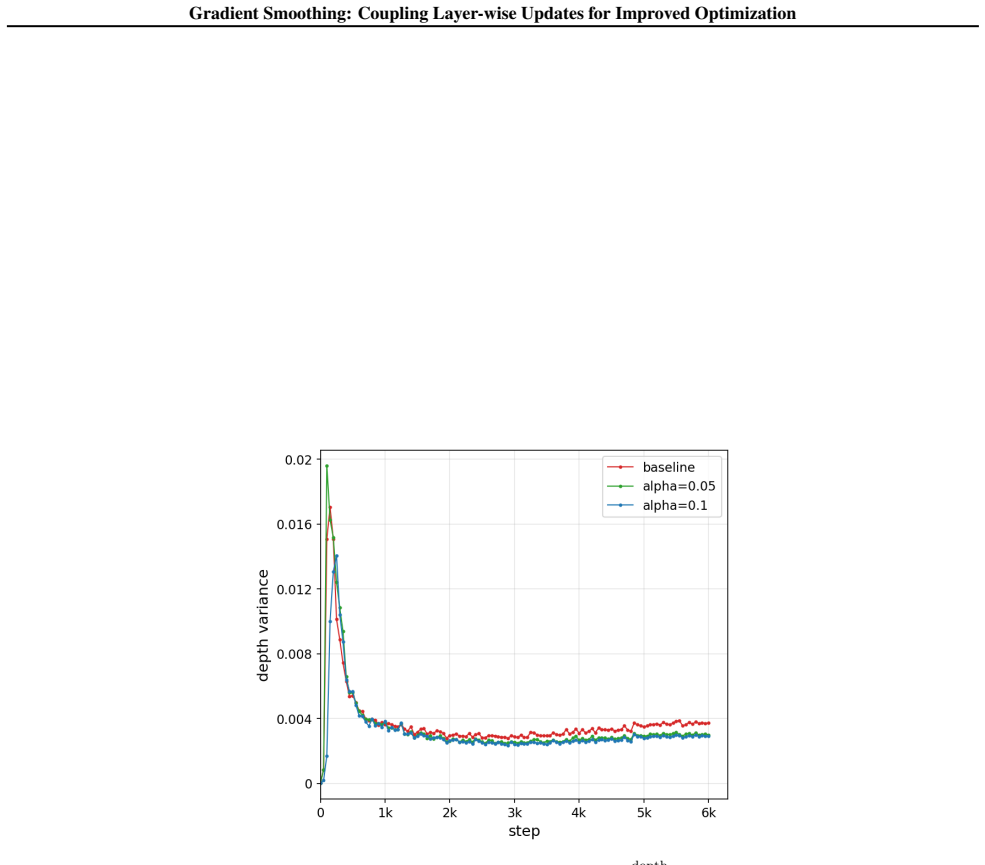
Depth-wise Gradient Augmentation obtains each layer's update by transforming the full collection of block-wise optimizer updates along the depth dimension. Gradient Smoothing instantiates this with a local Window Smoothing operator. The resulting updates act as structured depth-wise preconditioning, yielding better optimization trajectories and final performance than the base optimizer alone while preserving compatibility with existing pipelines.
What carries the argument
The Window Smoothing operator inside the Depth-wise Gradient Augmentation framework, which couples block-wise updates by local smoothing along the depth dimension.
If this is right
- The method works on top of arbitrary base optimizers such as SGD, Adam, or Muon.
- Performance gains appear in language-model pretraining, RL post-training for reasoning, diffusion modeling, and ViT image classification.
- Representation evolution across depth becomes more structured.
- No changes to model architecture or training objective are required.
Where Pith is reading between the lines
- The same depth-wise coupling idea could be tested on architectures that develop repeated-block structure only late in training.
- Fixed window smoothing might be replaced by a learned operator that adapts to observed layer correlations.
- Depth could be treated as an explicit dimension for preconditioning in the same way width or batch size already are.
- The approach may combine naturally with existing techniques such as gradient clipping or adaptive learning-rate schedules.
Load-bearing premise
Deep neural networks with repeated architectural blocks exhibit structured relationships across layers that emerge during training and can be usefully exploited by transforming the collection of block-wise optimizer updates along the depth dimension.
What would settle it
Running a standard transformer language-model pretraining experiment with Gradient Smoothing applied on top of Adam or SGD and finding no improvement or a degradation in training loss or downstream metrics relative to the unsmoothed baseline.
Figures

read the original abstract
Deep neural networks with repeated architectural blocks, such as transformers, often exhibit structured relationships across layers that emerge during training. Motivated by this observation, we introduce \emph{Depth-wise Gradient Augmentation}, a general optimization paradigm in which the update applied to each layer is obtained by transforming the collection of block-wise optimizer updates along the depth dimension. Within this framework, we study \emph{Gradient Smoothing}, a family of depth-wise smoothing methods, and instantiate it with a simple local \emph{Window Smoothing} operator. The resulting method operates directly on block-wise updates produced by arbitrary base optimizers (e.g., SGD, Adam, Muon), incurs minimal computational overhead, and is compatible with existing optimization pipelines. We evaluate Gradient Smoothing across a diverse set of architectures and training regimes, including language model pretraining, RL post-training of LLMs for reasoning, diffusion modeling, and image classification with Vision Transformers. Across these settings, Gradient Smoothing consistently improves optimization and generalization performance without modifying model architectures or training objectives. We further show that it promotes more structured representation evolution across depth, consistent with its interpretation as a structured depth-wise preconditioning method. Together, these results establish Depth-wise Gradient Augmentation as a promising framework for exploiting cross-depth structure in optimization and demonstrate Gradient Smoothing as a simple and broadly applicable instantiation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Depth-wise Gradient Augmentation as a general paradigm for obtaining layer updates by transforming collections of block-wise optimizer outputs along the depth dimension. It focuses on the Gradient Smoothing family, instantiated via a local Window Smoothing operator, and claims this yields consistent gains in optimization and generalization on language-model pretraining, RL post-training of LLMs, diffusion modeling, and ViT image classification. The method is presented as modular, compatible with arbitrary base optimizers (SGD, Adam, Muon), incurring minimal overhead, and additionally promoting more structured representation evolution across depth.
Significance. If the empirical claims are substantiated with rigorous, reproducible experiments, the contribution would be significant: a simple, architecture-agnostic operator that exploits emergent cross-layer structure in repeated-block networks and can be dropped into existing pipelines. The framing as structured depth-wise preconditioning and the breadth of evaluated domains (pretraining, RL, diffusion, classification) would position it as a broadly applicable optimization technique.
major comments (2)
- [Abstract] Abstract: the central claim that 'Gradient Smoothing consistently improves optimization and generalization performance' is asserted without any reported metrics, baselines, effect sizes, number of runs, or statistical tests. This absence is load-bearing for an empirical paper whose primary contribution is performance improvement.
- [Abstract / method description] The description of the Window Smoothing operator and its interaction with base-optimizer outputs (e.g., how the depth-wise transformation is exactly defined and whether it preserves unbiasedness or introduces new hyperparameters) is not accompanied by any equation or pseudocode in the provided text, preventing verification that the method is indeed 'parameter-free' or minimal-overhead as stated.
minor comments (1)
- [Abstract] The abstract mentions compatibility with Muon but provides no citation or brief description of this optimizer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Gradient Smoothing consistently improves optimization and generalization performance' is asserted without any reported metrics, baselines, effect sizes, number of runs, or statistical tests. This absence is load-bearing for an empirical paper whose primary contribution is performance improvement.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revised version, we will incorporate key results such as average relative improvements across tasks (with specific effect sizes), the number of independent runs, and mention of statistical significance where applicable, while preserving brevity. revision: yes
-
Referee: [Abstract / method description] The description of the Window Smoothing operator and its interaction with base-optimizer outputs (e.g., how the depth-wise transformation is exactly defined and whether it preserves unbiasedness or introduces new hyperparameters) is not accompanied by any equation or pseudocode in the provided text, preventing verification that the method is indeed 'parameter-free' or minimal-overhead as stated.
Authors: The Window Smoothing operator is formally defined in Section 3 with the exact depth-wise transformation (a local convex combination of block-wise updates) and pseudocode in Algorithm 1. It preserves unbiasedness as a linear operator with weights summing to one and introduces no new hyperparameters (window size is fixed at a default value with no tuning required). Overhead is strictly O(L) for L layers. We will revise the abstract to include a brief reference to these properties or a short equation for improved self-containment. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper introduces Depth-wise Gradient Augmentation and Gradient Smoothing as a modular operator applied to block-wise updates from arbitrary base optimizers. The abstract and description contain no equations, fitted parameters, or derivation steps that reduce to self-definition or input data by construction. Claims rest on empirical evaluation across domains rather than any mathematical reduction or self-citation chain. No load-bearing premises invoke prior author work as a uniqueness theorem or ansatz. The method is presented as compatible with existing pipelines without architecture changes, making the central contribution self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deep neural networks with repeated architectural blocks exhibit structured relationships across layers that emerge during training.
Reference graph
Works this paper leans on
-
[1]
Bao, F., Nie, S., Xue, K., Cao, Y ., Li, C., Su, H., and Zhu, J
URL https://arxiv.org/ abs/2407.07810. Bao, F., Nie, S., Xue, K., Cao, Y ., Li, C., Su, H., and Zhu, J. All are worth words: A vit backbone for diffusion mod- els,
-
[2]
URL https://arxiv.org/abs/2209. 12152. Ben-Shaul, I. and Dekel, S. Nearest class-center simplifica- tion through intermediate layers. In Cloninger, A., Doster, T., Emerson, T., Kaul, M., Ktena, I., Kvinge, H., Mi- olane, N., Rieck, B., Tymochko, S., and Wolf, G. (eds.), Proceedings of Topological, Algebraic, and Geometric Learning Workshops 2022, volume 1...
2022
-
[3]
URLhttps://arxiv.org/abs/2503.16219. Eschenhagen, R., Immer, A., Turner, R. E., Schneider, F., and Hennig, P. Kronecker-factored approximate curvature for modern neural network architectures,
-
[4]
Fisher, Q., Meng, H., and Papyan, V
URL https://arxiv.org/abs/2311.00636. Fisher, Q., Meng, H., and Papyan, V . Pushing bound- aries: Mixup’s influence on neural collapse,
- [5]
-
[6]
Deep Residual Networks Learn the Geodesic Curve in the Wasserstein Space
URL https://arxiv.org/abs/ 2102.09235. Garrod, C. and Keating, J. P. Unifying low dimensional observations in deep learning through the deep linear unconstrained feature model,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., and Roberts, D
URL https: //arxiv.org/abs/1806.03884. Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., and Roberts, D. A. The unreasonable ineffectiveness of the deeper layers,
-
[8]
URL https://arxiv.org/ abs/2403.17887. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao...
-
[9]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URL http://dx. doi.org/10.1038/s41586-025-09422-z. Gupta, V ., Koren, T., and Singer, Y . Shampoo: Precon- ditioned stochastic tensor optimization,
-
[10]
Shampoo: Preconditioned Stochastic Tensor Optimization
URL https://arxiv.org/abs/1802.09568. He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URL https:// arxiv.org/abs/1512.03385. Hoyt, C. R. and Owen, A. B. Probing neural networks with t-sne, class-specific projections and a guided tour,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
On layer-wise repre- sentation similarity: Application for multi-exit models with a single classifier
Jiang, J., Zhou, J., and Zhu, Z. On layer-wise repre- sentation similarity: Application for multi-exit models with a single classifier. InNeurIPS 2024 Workshop 11 Gradient Smoothing: Coupling Layer-wise Updates for Improved Optimization on Symmetry and Geometry in Neural Representations, 2025a. URL https://openreview.net/forum? id=YanMgtZhfY. Jiang, J., Z...
2024
-
[13]
URLhttps://arxiv.org/abs/2512.08819. Karpathy, A. nanochat: The best chatgpt that $100 can buy,
-
[14]
Adam: A Method for Stochastic Optimization
URL https://arxiv.org/abs/ 1412.6980. Krause, F., Phan, T., Gui, M., Baumann, S. A., Hu, V . T., and Ommer, B. Tread: Token routing for efficient architecture-agnostic diffusion training,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://arxiv.org/abs/2501.04765. Lad, V ., Lee, J. H., Gurnee, W., and Tegmark, M. The remarkable robustness of llms: Stages of inference?,
- [16]
-
[17]
Li, Z., Liu, L., Liang, C., Chen, W., and Zhao, T
URL https: //arxiv.org/abs/2401.09018. Li, Z., Liu, L., Liang, C., Chen, W., and Zhao, T. Normuon: Making muon more efficient and scalable,
-
[18]
Lin, W., Dangel, F., Eschenhagen, R., Neklyudov, K., Kristiadi, A., Turner, R
URL https://arxiv.org/abs/2510.05491. Lin, W., Dangel, F., Eschenhagen, R., Neklyudov, K., Kristiadi, A., Turner, R. E., and Makhzani, A. Struc- tured inverse-free natural gradient: Memory-efficient & numerically-stable kfac,
-
[19]
URL https://arxiv. org/abs/2312.05705. Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization,
-
[20]
Decoupled Weight Decay Regularization
URL https://arxiv.org/abs/ 1711.05101. Martens, J. and Grosse, R. Optimizing neural networks with kronecker-factored approximate curvature,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Men, X., Xu, M., Zhang, Q., Wang, B., Lin, H., Lu, Y ., Han, X., and Chen, W
URL https://arxiv.org/abs/1503.05671. Men, X., Xu, M., Zhang, Q., Wang, B., Lin, H., Lu, Y ., Han, X., and Chen, W. Shortgpt: Layers in large language models are more redundant than you expect,
-
[22]
Xiang Meng, Kayhan Behdin, Haoyue Wang, and Rahul Mazumder
URL https://arxiv.org/abs/2403.03853. Nagwekar, A. Towards guided descent: Optimization algo- rithms for training neural networks at scale,
- [23]
-
[24]
URL https://www.pnas.org/ doi/abs/10.1073/pnas.2015509117
doi: 10.1073/ pnas.2015509117. URL https://www.pnas.org/ doi/abs/10.1073/pnas.2015509117. Parker, L., Onal, E., Stengel, A., and Intrater, J. Neural collapse in the intermediate hidden layers of classification neural networks,
-
[25]
URL https:// arxiv.org/abs/2502.01954. Sarfati, R., Liu, T. J. B., Boull´e, N., and Earls, C. J. Lines of thought in large language models,
- [26]
-
[27]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y
URL https: //arxiv.org/abs/2405.15943. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models,
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://arxiv.org/abs/2402.03300. Skean, O., Arefin, M. R., LeCun, Y ., and Shwartz-Ziv, R. Does representation matter? exploring intermedi- ate layers in large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
URL https: //arxiv.org/abs/2412.09563. Skean, O., Arefin, M. R., Zhao, D., Patel, N., Naghiyev, J., LeCun, Y ., and Shwartz-Ziv, R. Layer by layer: Uncov- ering hidden representations in language models,
-
[30]
Layer by Layer: Uncovering Hidden Representations in Language Models
URLhttps://arxiv.org/abs/2502.02013. 12 Gradient Smoothing: Coupling Layer-wise Updates for Improved Optimization Song, Z.-Y ., Li, Z., Cao, Q.-H., xing Luo, M., and Zhu, H. X. Bridging the dimensional chasm: Uncover layer- wise dimensional reduction in transformers through token correlation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
S´uken´ık, P., Mondelli, M., and Lampert, C
URL https://arxiv.org/abs/ 2503.22547. S´uken´ık, P., Mondelli, M., and Lampert, C. Deep neural collapse is provably optimal for the deep unconstrained features model,
-
[32]
URL https://arxiv.org/abs/2012.12877. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need,
-
[33]
URL https://arxiv.org/ abs/1706.03762. Vyas, N., Morwani, D., Zhao, R., Kwun, M., Shapira, I., Brandfonbrener, D., Janson, L., and Kakade, S. Soap: Improving and stabilizing shampoo using adam,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
SOAP: Improving and Stabilizing Shampoo using Adam
URLhttps://arxiv.org/abs/2409.11321. Wang, J., Fan, L., Zhang, D., Jing, W., Di, D., Song, Y ., Liu, S., and Cong, C. Visual prompt-agnostic evolution,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Wang, P., Li, X., Yaras, C., Zhu, Z., Balzano, L., Hu, W., and Qu, Q
URLhttps://arxiv.org/abs/2601.20232. Wang, P., Li, X., Yaras, C., Zhu, Z., Balzano, L., Hu, W., and Qu, Q. Understanding deep representation learning via layerwise feature compression and discrimination, 2024a. Wang, S., Gai, K., and Zhang, S. Progressive feedforward collapse of resnet training, 2024b. Wolfram, C. and Schein, A. Layers at similar depths g...
- [36]
-
[37]
URL https: //arxiv.org/abs/2405.17767. Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Yang, J., Tu, J., Zhang, J., Ma, J., Yang, J., Xu, J., Zhou, J., Bai, J., He, J., Lin, J., Dang, K., Lu, K., Chen, K., Yang, K., Li, M., Xue, M., Ni, N., Zhang, P., Wang, P., P...
-
[38]
URL https://arxiv.org/abs/2407.10671. Zangrando, E., Deidda, P., Brugiapaglia, S., Guglielmi, N., and Tudisco, F. Provable emergence of deep neu- ral collapse and low-rank bias in l2-regularized nonlinear networks,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Zarka, J., Guth, F., and Mallat, S
URL https://arxiv.org/abs/ 2402.03991. Zarka, J., Guth, F., and Mallat, S. Separation and concentra- tion in deep networks,
-
[40]
URL https://arxiv. org/abs/2012.10424. Zhou, N., Chen, J., and Huang, D. Sharing task-relevant information in visual prompt tuning by cross-layer dy- namic connection.IEEE Transactions on Image Pro- cessing, 34:4527–4540,
-
[41]
ISSN 1941-0042. doi: 10.1109/tip.2025.3587587. URL http://dx.doi. org/10.1109/tip.2025.3587587. 13 Gradient Smoothing: Coupling Layer-wise Updates for Improved Optimization A. Appendix A.1. Specialization of Smoothing to Adam, AdamW, and Muon In our experiments, the base optimizer U (t) is typically Adam (Kingma & Ba, 2017), AdamW (Loshchilov & Hutter, 20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.