Unveiling the Black Box: A Multi-Layer Framework for Explaining Reinforcement Learning-Based Cyber Agents
Pith reviewed 2026-05-22 13:51 UTC · model grok-4.3
The pith
A multi-layer framework explains RL cyber agents by modeling their exploration dynamics and tracking Q-value shifts over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
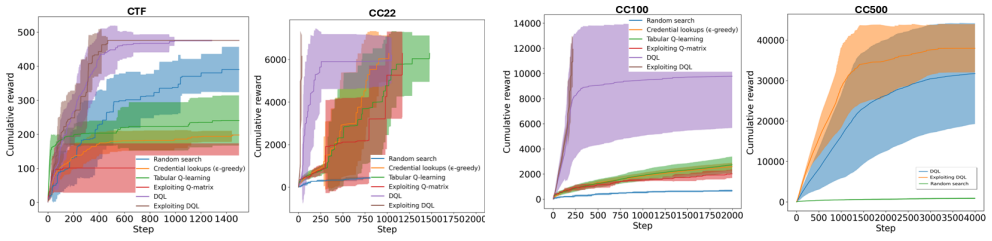
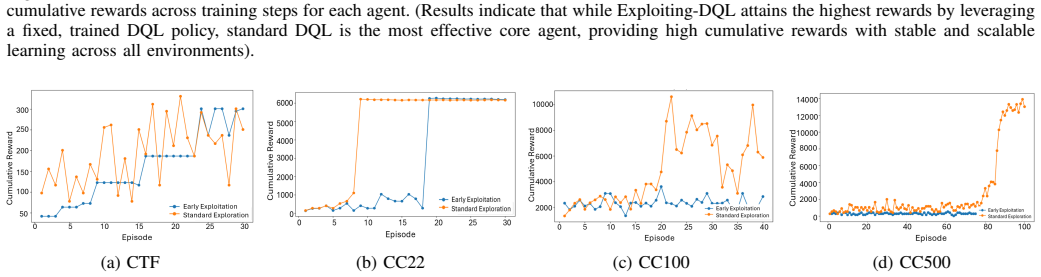
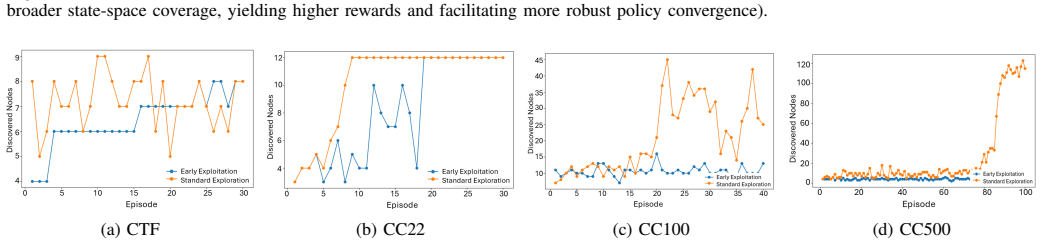
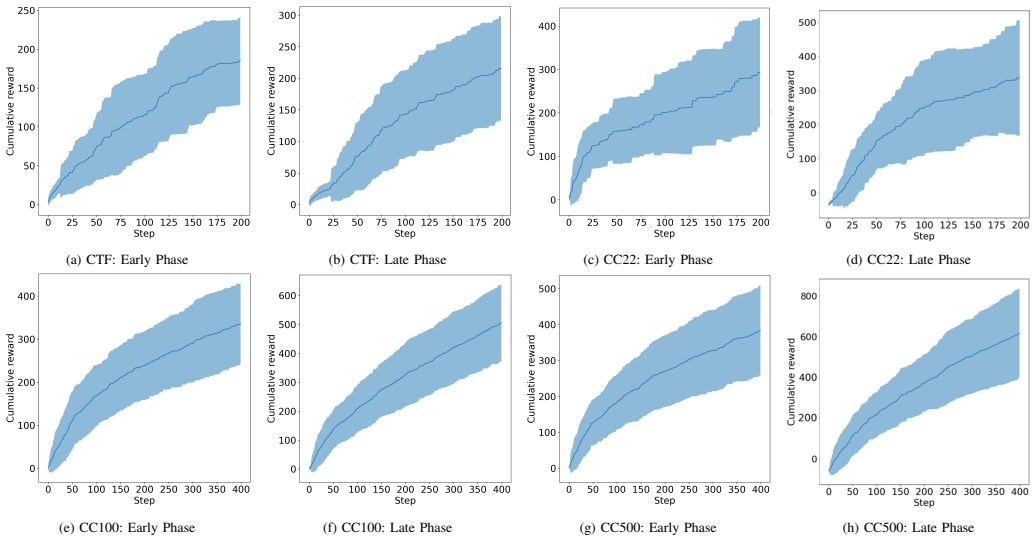
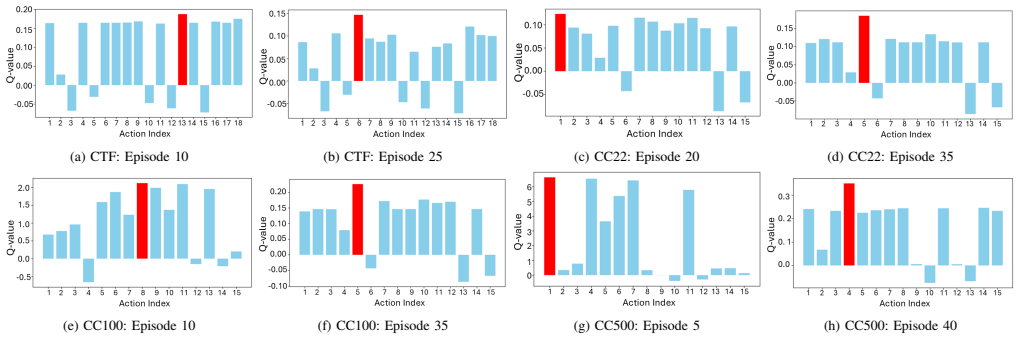
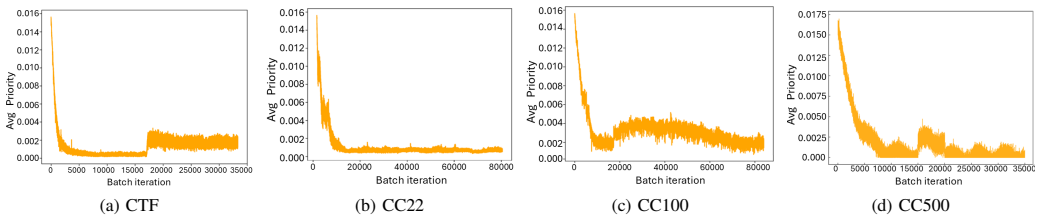
By treating cyberattacks as a POMDP, the framework exposes exploration-exploitation dynamics and phase-aware behavioural shifts; by tracking the temporal evolution of Q-values and applying prioritised experience replay, it surfaces critical learning transitions and evolving action preferences. When tested on CyberBattleSim environments of increasing complexity, these two layers together produce interpretable views of both strategic and tactical reasoning that previous explainable RL methods have not supplied at scale.
What carries the argument
The multi-layer explainability framework that operates at the MDP level via POMDP modeling of exploration-exploitation dynamics and at the policy level via temporal Q-value evolution combined with prioritised experience replay.
If this is right
- Red-team simulations gain visibility into how agents form and shift their attack strategies over time.
- RL policy debugging becomes possible by locating the exact learning transitions where action preferences change.
- Phase-aware threat modelling can incorporate the identified behavioural shifts rather than treating the agent as a static black box.
- Anticipatory defence planning can use the surfaced Q-value trajectories to predict likely next moves.
Where Pith is reading between the lines
- The same layered approach could be tested on RL agents in non-cyber domains such as robotic navigation to see whether POMDP and PER analysis transfers.
- If the insights prove actionable, trainers might deliberately insert monitoring points at the identified transition moments to improve sample efficiency.
- Defenders could feed the extracted phase information back into their own RL models to create more responsive countermeasures.
Load-bearing premise
That breaking down POMDP exploration-exploitation patterns and Q-value changes through prioritised experience replay will deliver genuinely new and usable insights into the agent's choices rather than descriptions already available from ordinary RL logs.
What would settle it
Run the framework on an RL agent in a known CyberBattleSim scenario, then compare the insights it generates against a simple log of visited states, rewards, and actions to check whether any previously hidden reasoning steps are actually revealed.
Figures
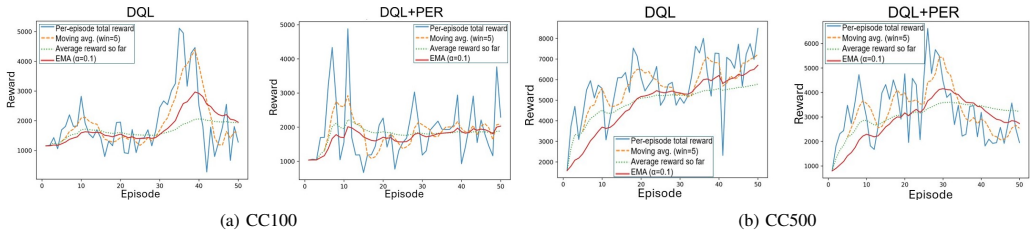

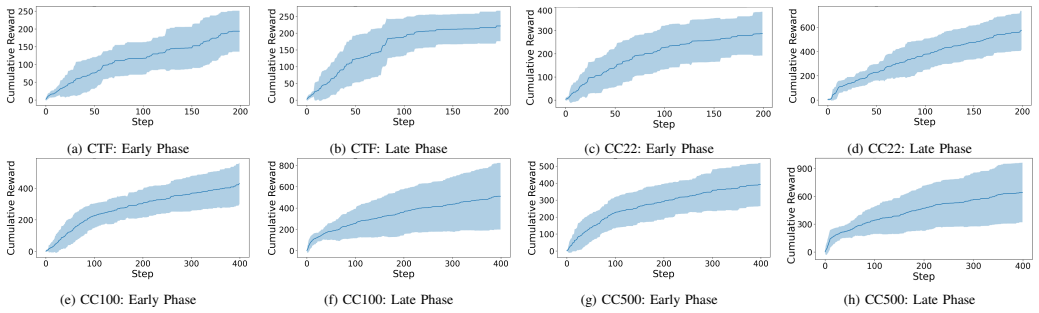
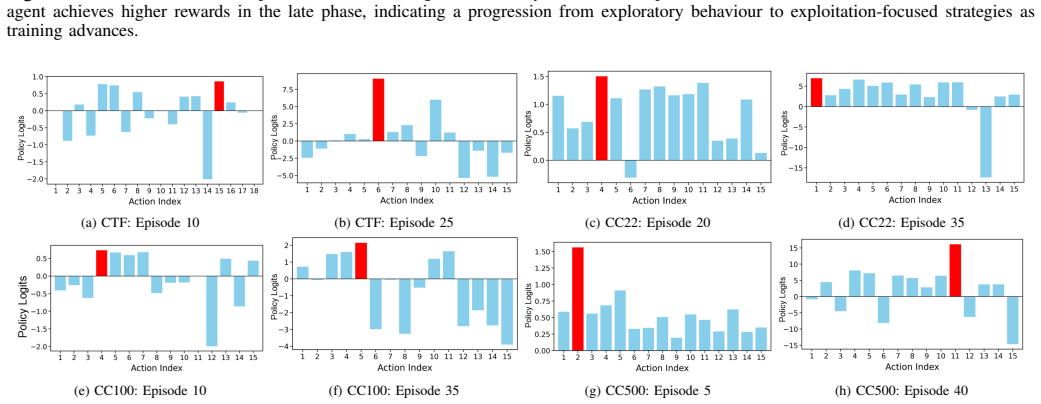
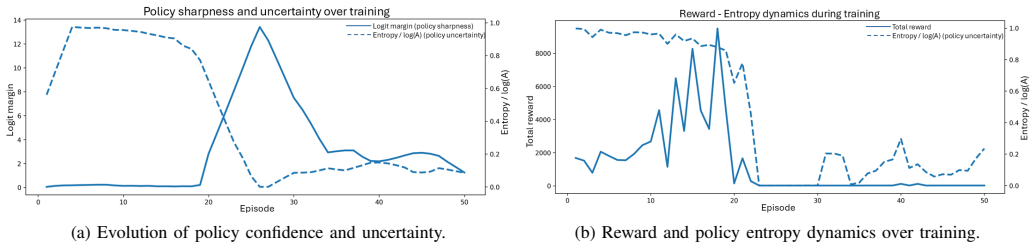
read the original abstract
Reinforcement Learning (RL) agents are increasingly used to simulate sophisticated cyberattacks, but their decision-making processes remain opaque, hindering trust, debugging, and defensive preparedness. In high-stakes cybersecurity contexts, explainability is essential for understanding how adversarial strategies are formed and evolve over time. In this paper, we propose a unified, multi-layer explainability framework for RL-based attacker agents that reveals both strategic (Markov Decision Process (MDP)-level) and tactical (policy-level) reasoning. At the MDP-level, we model cyberattacks as a Partially Observable Markov Decision Process (POMDP) to expose exploration-exploitation dynamics and phase-aware behavioural shifts. At the policy-level, we analyse the temporal evolution of Q-values and use Prioritised Experience Replay (PER) to surface critical learning transitions and evolving action preferences. Evaluated across CyberBattleSim environments of increasing complexity, our framework offers interpretable insights into agent behaviour at scale. Unlike previous explainable RL methods, which are {predominantly} post-hoc, domain-specific, or limited in depth, our approach is both agent- and environment-agnostic, {supporting use cases such as red-team simulation, RL policy debugging, phase-aware threat modelling and anticipatory defence planning.} By transforming black-box learning into actionable behavioural intelligence, our framework enables both defenders and developers to better anticipate, analyse, and respond to autonomous cyber threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-layer explainability framework for RL-based cyber attacker agents. At the MDP level it models attacks as POMDPs to expose exploration-exploitation dynamics and phase-aware behavioural shifts; at the policy level it tracks temporal Q-value evolution and uses Prioritised Experience Replay (PER) to identify critical learning transitions. The framework is evaluated on CyberBattleSim environments of increasing complexity and is presented as agent- and environment-agnostic, yielding actionable behavioural intelligence for red-team simulation, policy debugging, phase-aware threat modelling and anticipatory defence.
Significance. If the claimed distinction from standard RL logging were demonstrated with quantitative metrics and baseline comparisons, the framework could meaningfully advance explainability in RL-driven cyber simulations, supporting practical uses in defensive preparedness. At present the absence of such evidence leaves the significance speculative.
major comments (2)
- [Abstract] Abstract: The central claim that the POMDP-level and PER-based analysis produces 'interpretable insights into agent behaviour at scale' and 'actionable behavioural intelligence' is unsupported by any reported quantitative metrics, interpretability scores, or comparisons against raw Q-tables, episode traces, or standard saliency methods.
- [Abstract] Abstract and Evaluation description: No baseline comparisons or actionability metrics are supplied to substantiate that the outputs differ from conventional RL instrumentation or that they enable previously unavailable use cases such as anticipatory defence planning.
minor comments (1)
- [Abstract] Abstract contains apparent LaTeX artifacts (curly braces around 'predominantly' and the long use-case sentence); these should be removed for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the quantitative support for our claims while preserving the framework's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the POMDP-level and PER-based analysis produces 'interpretable insights into agent behaviour at scale' and 'actionable behavioural intelligence' is unsupported by any reported quantitative metrics, interpretability scores, or comparisons against raw Q-tables, episode traces, or standard saliency methods.
Authors: We acknowledge that the current evaluation relies primarily on qualitative case studies across CyberBattleSim environments to illustrate phase-aware shifts and critical learning transitions. While these examples demonstrate distinctions from raw Q-tables and episode traces, we did not report formal interpretability scores or direct baseline comparisons. In the revised manuscript we will add a dedicated evaluation subsection that includes quantitative comparisons, such as the proportion of unique behavioral patterns surfaced by the multi-layer framework versus standard logging, and proxy metrics for insight density per episode. revision: yes
-
Referee: [Abstract] Abstract and Evaluation description: No baseline comparisons or actionability metrics are supplied to substantiate that the outputs differ from conventional RL instrumentation or that they enable previously unavailable use cases such as anticipatory defence planning.
Authors: The manuscript positions the framework as providing strategic (POMDP) and tactical (PER/Q-value) layers that conventional instrumentation does not combine. However, we agree that explicit substantiation through baselines and actionability metrics is needed to move beyond illustrative examples. We will revise the evaluation section to incorporate baseline comparisons against raw traces and saliency methods, along with discussion of how the identified phase shifts and transition points support anticipatory defence scenarios within the simulated environments. revision: yes
Circularity Check
No significant circularity; standard RL constructs applied to new domain
full rationale
The paper proposes a multi-layer framework that models cyberattacks as POMDPs to expose exploration-exploitation and phase shifts, then tracks temporal Q-value evolution via PER to surface learning transitions. These are established, externally defined RL techniques (POMDP formulation, Q-learning, prioritized replay) applied to CyberBattleSim environments. No derivation, equation, or central claim reduces by construction to a fitted parameter, self-referential definition, or self-citation chain. The claim of providing agent-agnostic, actionable insights is presented as an empirical outcome of the framework rather than a tautology. This is a self-contained proposal whose validity rests on external evaluation rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cyberattacks can be modeled as Partially Observable Markov Decision Processes to expose exploration-exploitation dynamics and phase-aware behavioural shifts.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
At the MDP-level, we model cyberattacks as a Partially Observable Markov Decision Process (POMDP) to expose exploration-exploitation dynamics and phase-aware behavioural shifts. At the policy-level, we analyse the temporal evolution of Q-values and use Prioritised Experience Replay (PER) to surface critical learning transitions
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Q(s, a)←Q(s, a) + α [r + γ max_a' Q(s', a') − Q(s, a)] ... δ_i = r_i + γ max_a' Q(s'_i, a') − Q(s_i, a_i)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Explainable Autonomous Cyber Defense using Adversarial Multi-Agent Reinforcement Learning
C-MADF learns a structural causal model to restrict response actions in an MDP and uses dual blue-red RL policies to achieve 1.8% false-positive rate and 0.979 F1 on the CICIoT2023 dataset.
Reference graph
Works this paper leans on
-
[1]
D. Goel, M. H. Ward-Graham, A. Neumann, F. Neumann, H. Nguyen, and M. Guo, “Defending active directory by combining neural network based dynamic program and evolutionary diversity optimisation,” in Proceedings of the Genetic and Evolutionary Computation Conference, ser. GECCO ’22, 2022, p. 1191–1199
work page 2022
-
[2]
Microsoft Defender Research Team, “Cyberbattlesim,” https://github.com/microsoft/cyberbattlesim, 2021, Created by Christian Seifert, Michael Betser, William Blum, James Bono, Kate Farris, Emily Goren, Justin Grana, Kristian Holsheimer, Brandon Marken, Joshua Neil, Nicole Nichols, Jugal Parikh, Haoran Wei
work page 2021
-
[3]
Cyber operations research gym,
“Cyber operations research gym,” https://github.com/cage- challenge/CybORG, 2022, created by Maxwell Standen, David Bowman, Son Hoang, Toby Richer, Martin Lucas, Richard Van Tassel, Phillip Vu, Mitchell Kiely, KC C., Natalie Konschnik, Joshua Collyer
work page 2022
-
[4]
Scalable and Generalizable RL Agents for Attack Path Discovery via Continuous Invariant Spaces,
F. Terranova, A. Lahmadi, and I. Chrisment, “Scalable and Generalizable RL Agents for Attack Path Discovery via Continuous Invariant Spaces,” in2025 28th International Symposium on Research in Attacks, Intrusions and Defenses (RAID), Gold Coast, Australia, Oct. 2025, p. 18. [Online]. Available: https://hal.science/hal-05182437
work page 2025
-
[5]
D. Goel, A. Neumann, F. Neumann, H. Nguyen, and M. Guo, “Evolving reinforcement learning environment to minimize learner’s achievable reward: An application on hardening active directory systems,” in Proceedings of the Genetic and Evolutionary Computation Conference, ser. GECCO ’23, 2023, p. 1348–1356
work page 2023
-
[6]
D. Goel, “Enhancing network resilience through machine learning- powered graph combinatorial optimization: Applications in cyber de- fense and information diffusion,”arXiv preprint arXiv:2310.10667, 2023
-
[7]
Non-stationary reinforcement learning without prior knowledge: An optimal black-box approach,
C.-Y . Wei and H. Luo, “Non-stationary reinforcement learning without prior knowledge: An optimal black-box approach,” inConference on learning theory. PMLR, 2021, pp. 4300–4354
work page 2021
-
[8]
Explainable ai (xai): Core ideas, techniques, and solutions,
R. Dwivedi, D. Dave, H. Naik, S. Singhal, R. Omer, P. Patel, B. Qian, Z. Wen, T. Shah, G. Morganet al., “Explainable ai (xai): Core ideas, techniques, and solutions,”ACM computing surveys, vol. 55, no. 9, pp. 1–33, 2023
work page 2023
-
[9]
Causal explanations for sequential decision-making in multi-agent systems,
B. Gyevnar, C. Wang, C. G. Lucas, S. B. Cohen, and S. V . Albrecht, “Causal explanations for sequential decision-making in multi-agent systems,”arXiv preprint arXiv:2302.10809, 2023
-
[10]
Codex: A cluster- based method for explainable reinforcement learning,
T. K. Mathes, J. Inman, A. Col ´on, and S. Khan, “Codex: A cluster- based method for explainable reinforcement learning,”arXiv preprint arXiv:2312.04216, 2023
-
[11]
Explainable reinforcement learning through a causal lens,
P. Madumal, T. Miller, L. Sonenberg, and F. Vetere, “Explainable reinforcement learning through a causal lens,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 03, 2020, pp. 2493–2500
work page 2020
-
[12]
Causal explanations for sequential decision making,
S. B. Nashed, S. Mahmud, C. V . Goldman, and S. Zilberstein, “Causal explanations for sequential decision making,”Journal of Artificial Intel- ligence Research, vol. 83, 2025
work page 2025
-
[13]
AIRS: Ex- planation for deep reinforcement learning-based security applications,
J. Yu, W. Guo, Q. Qin, G. Wang, T. Wang, and X. Xing, “AIRS: Ex- planation for deep reinforcement learning-based security applications,” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 7375–7392
work page 2023
-
[14]
Inroads into autonomous network defence using explained reinforcement learning,
M. Foley, M. Wang, C. Hicks, V . Mavroudiset al., “Inroads into autonomous network defence using explained reinforcement learning,” arXiv preprint arXiv:2306.09318, 2023
-
[15]
Experiential explanations for reinforcement learning,
A. Alabdulkarim, M. Singh, G. Mansi, K. Hall, and M. O. Riedl, “Experiential explanations for reinforcement learning,”arXiv preprint arXiv:2210.04723, 2022
-
[16]
Explainable artificial intelligence for cybersecurity,
D. K. Sharma, J. Mishra, A. Singh, R. Govil, G. Srivastava, and J. C.- W. Lin, “Explainable artificial intelligence for cybersecurity,”Computers and Electrical Engineering, vol. 103, p. 108356, 2022
work page 2022
-
[17]
Evaluation of explainable artificial intelligence: Shap, lime, and cam,
H. T. T. Nguyen, H. Q. Cao, K. V . T. Nguyen, and N. D. K. Pham, “Evaluation of explainable artificial intelligence: Shap, lime, and cam,” inProceedings of the FPT AI Conference, 2021, pp. 1–6
work page 2021
-
[18]
Explainability of cybersecurity threats data using shap,
R. Alenezi and S. A. Ludwig, “Explainability of cybersecurity threats data using shap,” in2021 IEEE symposium series on computational intelligence (SSCI). IEEE, 2021, pp. 01–10
work page 2021
-
[19]
Interpreting agent behaviors in reinforcement-learning-based cyber- battle simulation platforms,
J. Claypoole, S. Cheung, A. Gehani, V . Yegneswaran, and A. Ridley, “Interpreting agent behaviors in reinforcement-learning-based cyber- battle simulation platforms,”arXiv preprint arXiv:2506.08192, 2025
-
[20]
Nasim: Network attack simulator,
J. Schwartz and H. Kurniawatti, “Nasim: Network attack simulator,” https://networkattacksimulator.readthedocs.io/, 2019
work page 2019
-
[21]
Network defense is not a game,
A. Molina-Markham, R. K. Winder, and A. Ridley, “Network defense is not a game,”arXiv preprint arXiv:2104.10262, 2021
-
[22]
Entity-based reinforcement learning for autonomous cyber defence,
I. S. Thompson, A. Caron, C. Hicks, and V . Mavroudis, “Entity-based reinforcement learning for autonomous cyber defence,” inProceedings of the Workshop on Autonomous Cybersecurity, 2024, pp. 56–67
work page 2024
-
[23]
Optimizing cyber defense in dynamic active directories through rein- forcement learning,
D. Goel, K. Moore, M. Guo, D. Wang, M. Kim, and S. Camtepe, “Optimizing cyber defense in dynamic active directories through rein- forcement learning,” inEuropean Symposium on Research in Computer Security. Springer, 2024, pp. 332–352
work page 2024
-
[24]
Learning cyber defence tactics from scratch with multi-agent reinforcement learning,
J. Wiebe, R. A. Mallah, and L. Li, “Learning cyber defence tactics from scratch with multi-agent reinforcement learning,”arXiv preprint arXiv:2310.05939, 2023
-
[25]
Autonomous network cyber offence strategy through deep reinforcement learning,
M. Sultana, A. Taylor, and L. Li, “Autonomous network cyber offence strategy through deep reinforcement learning,” inArtificial Intelligence and Machine Learning for Multi-Domain Operations Applications III, vol. 11746. SPIE, 2021, pp. 490–502
work page 2021
-
[26]
Developing opti- mal causal cyber-defence agents via cyber security simulation,
A. Andrew, S. Spillard, J. Collyer, and N. Dhir, “Developing opti- mal causal cyber-defence agents via cyber security simulation,”arXiv preprint arXiv:2207.12355, 2022
-
[27]
Autonomous cyber warfare agents: dynamic rein- forcement learning for defensive cyber operations,
D. A. Bierbrauer, R. M. Schabinger, C. Carlin, J. Mullin, J. A. Pavlik, and N. D. Bastian, “Autonomous cyber warfare agents: dynamic rein- forcement learning for defensive cyber operations,” inArtificial Intelli- gence and Machine Learning for Multi-Domain Operations Applications V, vol. 12538. SPIE, 2023, pp. 42–56
work page 2023
-
[28]
Adaptiveϵ-greedy exploration in reinforcement learning,
M. Tokic, “Adaptiveϵ-greedy exploration in reinforcement learning,” inProceedings of the 22nd International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2010, pp. 243–250
work page 2010
-
[29]
C. J. C. H. Watkins and P. Dayan, “Q-learning,”Machine Learning, vol. 8, no. 3-4, pp. 279–292, 1992
work page 1992
-
[30]
R. E. Bellman,Dynamic Programming. Princeton, NJ: Princeton University Press, 1957
work page 1957
-
[31]
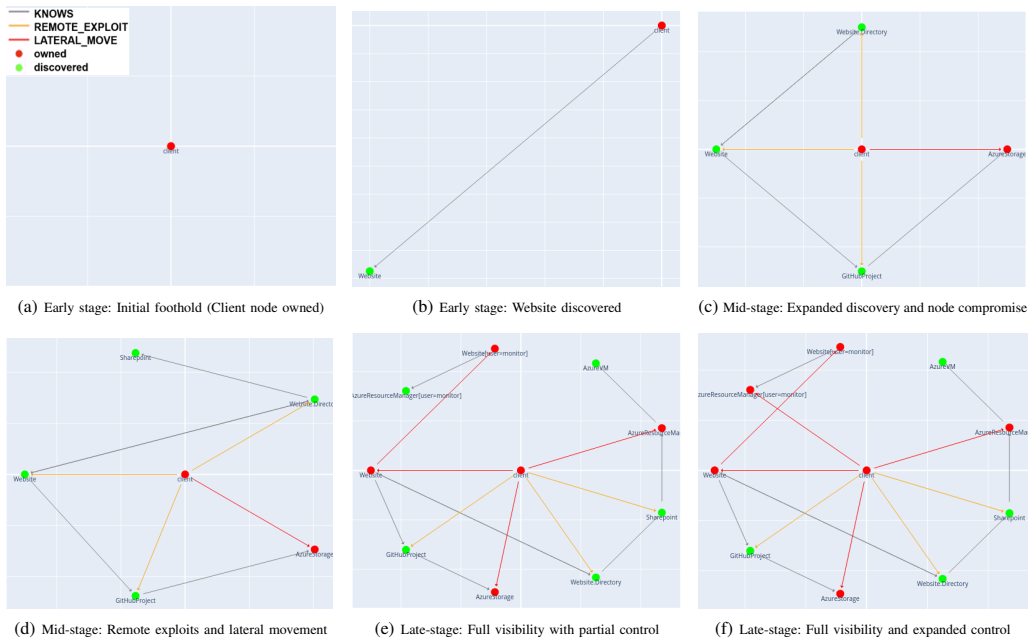
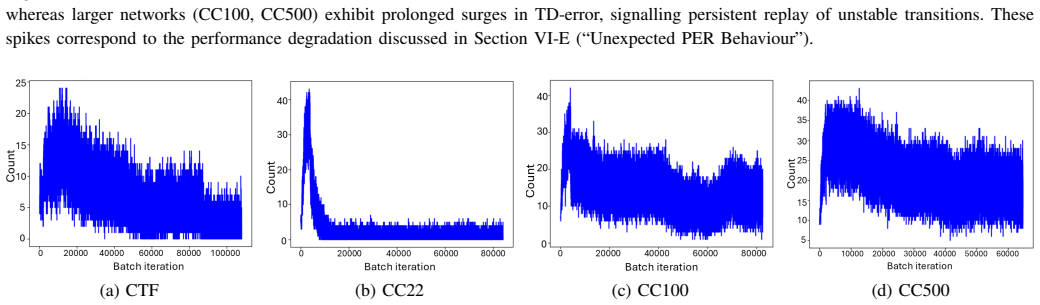
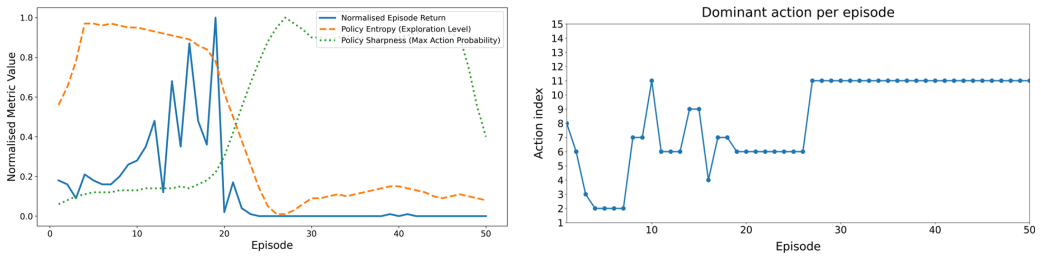
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” inProceedings of the 4th International Conference on Learning Representations (ICLR), 2016, arXiv:1511.05952. [Online]. Available: https://arxiv.org/abs/1511.05952 Appendix Intermediate Exploration Trajectory of the RL Attacker Under Partial Observability To illustrate the ...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.