Remember with Confidence: Uncertainty Quantification for Spatio-temporal Memory with Probabilistic Guarantees
Pith reviewed 2026-06-27 19:49 UTC · model grok-4.3
The pith
Object-level semantic uncertainty from caption scatter identifies unresolved objects and enables active refinement of robot memory with probabilistic guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
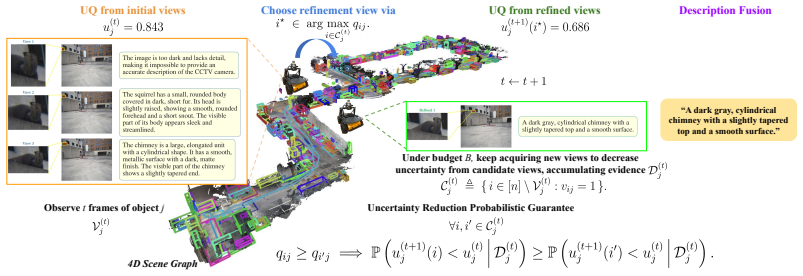
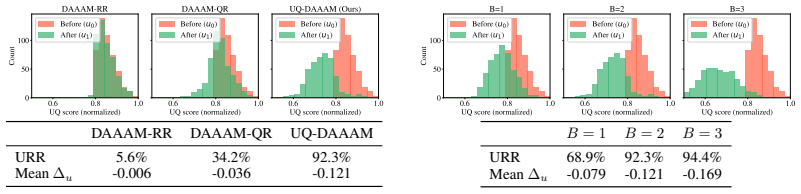
The paper claims that measuring object-centric cross-view semantic scatter of VLM captions produces a usable uncertainty score that flags unresolved objects; when this score drives view selection and caption fusion inside UQ-DAAAM, the resulting multi-view descriptions become more reliable, and higher-quality candidate views carry probabilistic guarantees of greater uncertainty reduction.
What carries the argument
The object-level semantic uncertainty score, defined as the cross-view semantic scatter of VLM captions attached to each persistent 3D entity.
If this is right
- UQ-DAAAM produces substantially larger uncertainty reduction than baselines on the OC-NaVQA benchmark.
- Spatio-temporal question answering performance improves when the uncertainty score guides view selection.
- Higher-quality candidate views selected by the score are probabilistically more likely to reduce uncertainty.
- Embodied 4D memory systems become both more reliable and more effective under a fixed query budget.
Where Pith is reading between the lines
- The same scatter-based score could be applied to other stored modalities such as depth or audio to flag multi-modal inconsistencies.
- Long-horizon planning modules could query the uncertainty score directly to decide when to revisit an object before committing to an action.
- The probabilistic guarantee might be used to allocate compute budgets dynamically across many objects rather than a fixed per-object budget.
Load-bearing premise
Cross-view semantic scatter of VLM captions is a valid proxy for identifying objects whose stored descriptions can be improved by selecting additional views.
What would settle it
A controlled test that checks whether objects scored high in uncertainty actually show larger gains in caption consistency or downstream task accuracy after the selected-view fusion step, relative to low-uncertainty objects.
Figures
read the original abstract
Long-horizon robot operation requires spatio-temporal memory to record the environment state and recall it for downstream reasoning. Scene graphs and retrieval-augmented systems ground VLM descriptions to persistent 3D entities with rich semantic descriptions. However, VLM captions are noisy and viewpoint-inconsistent, and existing systems treat them as an oracle with no mechanism to detect unreliable stored descriptions. We introduce object-level semantic uncertainty for multi-view VLM memory: a score that measures object-centric cross-view semantic scatter of captions and identifies semantically unresolved objects. Then, we include our uncertainty scores in an advanced spatial-semantic memory system, that we dub UQ-DAAAM. UQ-DAAAM uses this score to actively refine uncertain objects under a fixed query budget by selecting high-quality views and fusing the resulting multi-view captions into a single object description. We also derive probabilistic guarantees showing that higher-quality candidate views (as selected by our approach) are more likely to reduce uncertainty. Our experiments show that uncertainty quantification can make embodied 4D memory systems more reliable and more effective. In particular, on the OC-NaVQA benchmark, UQ-DAAAM achieves substantially larger uncertainty reduction and better spatio-temporal question answering performance than baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an object-level semantic uncertainty score based on cross-view semantic scatter of VLM captions to detect semantically unresolved objects in spatio-temporal memory systems. It integrates this score into the UQ-DAAAM system, which actively refines uncertain objects by selecting high-quality views under a fixed budget and fusing multi-view captions. The work derives probabilistic guarantees that higher-quality views reduce uncertainty and reports improved uncertainty reduction and spatio-temporal QA performance over baselines on the OC-NaVQA benchmark.
Significance. If the modeling assumptions and derivations hold, the approach could meaningfully improve reliability of VLM-grounded memory for long-horizon robotics by providing a mechanism to detect and reduce description uncertainty with formal guarantees. The explicit derivation of probabilistic guarantees and the benchmark results are positive features that distinguish this from purely heuristic uncertainty methods.
major comments (2)
- [Abstract] Abstract: The uncertainty score and the probabilistic guarantees both rest on the premise that cross-view semantic scatter of VLM captions primarily indicates semantically unresolved objects whose descriptions can be improved by additional views. This premise is load-bearing for the central claims, yet the manuscript provides no analysis or evidence distinguishing scatter due to unresolved semantics from scatter due to legitimate viewpoint-dependent but accurate descriptions (e.g., different visible object parts). If the latter dominates, both the score and the claimed guarantees lose their intended meaning.
- [Abstract] The derivation of the probabilistic guarantees (abstract) is presented as showing that selected higher-quality views are more likely to reduce uncertainty. Without the explicit assumptions, lemmas, or conditions under which this holds (particularly regarding the scatter proxy), it is impossible to assess whether the guarantees are non-vacuous or robust to the viewpoint-variation concern.
minor comments (1)
- The abstract refers to 'substantially larger uncertainty reduction' on OC-NaVQA but does not quantify the effect sizes or report variance across runs; adding these details would strengthen the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the foundational assumptions and derivations require greater clarity and support. We respond to each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The uncertainty score and the probabilistic guarantees both rest on the premise that cross-view semantic scatter of VLM captions primarily indicates semantically unresolved objects whose descriptions can be improved by additional views. This premise is load-bearing for the central claims, yet the manuscript provides no analysis or evidence distinguishing scatter due to unresolved semantics from scatter due to legitimate viewpoint-dependent but accurate descriptions (e.g., different visible object parts). If the latter dominates, both the score and the claimed guarantees lose their intended meaning.
Authors: We agree this distinction is critical and that the manuscript would benefit from explicit support for the premise. The uncertainty score is motivated by the observation that semantically unresolved objects produce inconsistent VLM captions across views, while we expect consistent objects to yield stable descriptions even under viewpoint changes. In revision we will add a dedicated analysis subsection with qualitative examples from the OC-NaVQA data and a quantitative breakdown (e.g., per-object scatter histograms conditioned on human-annotated semantic stability) to illustrate when scatter is driven by unresolved semantics versus partial but accurate views. We will also note the limitation that extreme viewpoint variation can still inflate the score and discuss how the active selection step mitigates this. revision: partial
-
Referee: [Abstract] The derivation of the probabilistic guarantees (abstract) is presented as showing that selected higher-quality views are more likely to reduce uncertainty. Without the explicit assumptions, lemmas, or conditions under which this holds (particularly regarding the scatter proxy), it is impossible to assess whether the guarantees are non-vacuous or robust to the viewpoint-variation concern.
Authors: The guarantees rest on the modeling assumption that the cross-view scatter proxy correlates with semantic unresolvedness and that higher-quality views (ranked by our selection criteria) are more likely to produce captions that reduce this scatter. We will revise the manuscript to state all modeling assumptions explicitly, include the key lemmas and proof sketches in the main text or appendix, and add a short robustness discussion addressing viewpoint variation. These changes will make the scope and limitations of the guarantees transparent. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper explicitly defines the object-level semantic uncertainty score as the cross-view semantic scatter of VLM captions. Probabilistic guarantees are stated as separately derived results on the effect of view selection. No equations, self-citations, fitted parameters, or ansatzes are visible that reduce the guarantees or the refinement procedure to the definition by construction. The central claims retain independent content via the stated derivation and experimental evaluation on OC-NaVQA.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cross-view semantic scatter of VLM captions reliably indicates unresolved object descriptions
- domain assumption Probabilistic guarantees can be derived linking view quality to uncertainty reduction
invented entities (2)
-
object-level semantic uncertainty score
no independent evidence
-
UQ-DAAAM system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A.N. Angelopoulos and S. Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprint arXiv:2107.07511, 2021
Pith/arXiv arXiv 2021
-
[2]
Anwar, J
A. Anwar, J. Welsh, J. Biswas, S. Pouya, and Y . Chang. ReMEmbR: Building and reasoning over long- horizon spatio-temporal memory for robot navigation. InIEEE Intl. Conf. on Robotics and Automation (ICRA), 2025
2025
-
[3]
Armeni, Z
I. Armeni, Z. He, J. Gwak, A. Zamir, M. Fischer, J. Malik, and S. Savarese. 3D scene graph: A structure for unified semantics, 3D space, and camera. InIntl. Conf. on Computer Vision (ICCV), pp. 5664–5673, 2019
2019
-
[4]
Z. Bai, P. Wang, T. Xiao, T. He, Z. Han, Z. Zhang, and M.Z. Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
Pith/arXiv arXiv 2024
-
[5]
Barber, E.J
R.F. Barber, E.J. Candes, A. Ramdas, and R.J. Tibshirani. Conformal prediction beyond exchangeability. The Annals of Statistics, 51(2):816–845, 2023
2023
-
[6]
Chaloner and I
K. Chaloner and I. Verdinelli. Bayesian experimental design: A review.Statistical science, pp. 273–304, 1995
1995
-
[7]
C. Chen, K. Liu, Z. Chen, Y . Gu, Y . Wu, M. Tao, Z. Fu, and J. Ye. Inside: Llms’ internal states retain the power of hallucination detection.arXiv preprint arXiv:2402.03744, 2024
arXiv 2024
-
[8]
S-H. Chou, S. Chandhok, J. Little, and L. Sigal. Mm-r3: On (in-) consistency of vision-language models (vlms). InFindings of the Association for Computational Linguistics: ACL 2025, pp. 4762–4788, 2025
2025
-
[9]
Farquhar, J
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[10]
Gal and Z
Y . Gal and Z. Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InIntl. Conf. on Machine Learning (ICML), pp. 1050–1059. PMLR, 2016
2016
-
[11]
Ginting, D-K
M.F. Ginting, D-K. Kim, X. Meng, A.M. Reinke, B.J. Krishna, N. Kayhani, O. Peltzer, D. Fan, A. Shaban, S-K. Kim, M. Kochenderfer, A. Agha-mohammadi, and S. Omidshafiei. Enter the mind palace: Reason- ing and planning for long-term active embodied question answering. InConference on Robot Learning (CoRL), 2025
2025
-
[12]
Gorlo, L
N. Gorlo, L. Schmid, and L. Carlone. Describe anything anywhere at any moment. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[13]
Goyal, T
Y . Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 6904–6913, 2017
2017
-
[14]
Q. Gu, A. Kuwajerwala, S. Morin, K.M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, C. Gan, C.M. de Melo, J.B. Tenenbaum, A. Torralba, F. Shkurti, and L. Paull. Concept- graphs: Open-vocabulary 3d scene graphs for perception and planning. InIEEE Intl. Conf. on Robotics and Automation (ICRA), May 2024
2024
-
[15]
C. Guo, G. Pleiss, Y . Sun, and K.Q. Weinberger. On calibration of modern neural networks. InIntl. Conf. on Machine Learning (ICML), pp. 1321–1330, 2017
2017
-
[16]
P. He, X. Liu, J. Gao, and W. Chen. Deberta: Decoding-enhanced bert with disentangled attention.arXiv preprint arXiv:2006.03654, 2020
Pith/arXiv arXiv 2006
-
[17]
Honerkamp, M
D. Honerkamp, M. B ¨uchner, F. Despinoy, T. Welschehold, and A. Valada. Language-grounded dynamic scene graphs for interactive object search with mobile manipulation.IEEE Robotics and Automation Letters (RA-L), 2024. 10
2024
-
[18]
Hughes, Y
N. Hughes, Y . Chang, and L. Carlone. Hydra: a real-time spatial perception engine for 3D scene graph construction and optimization. InRobotics: Science and Systems (RSS), 2022
2022
-
[19]
Hughes, Y
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone. Foundations of spatial perception for robotics: Hierarchical representations and real-time systems.Intl. J. of Robotics Research, 2024
2024
-
[20]
H ¨ullermeier and W
E. H ¨ullermeier and W. Waegeman. Aleatoric and epistemic uncertainty in machine learning: An intro- duction to concepts and methods.Machine learning, 110(3):457–506, 2021
2021
-
[21]
Jatavallabhula, A
K.M. Jatavallabhula, A. Kuwajerwala, Q. Gu, M. Omama, T. Chen, S. Li, G. Iyer, S. Saryazdi, N. Keetha, A. Tewari, J.B. Tenenbaum, C.M. de Melo, M. Krishna, L. Paull, F. Shkurti, and A. Torralba. Conceptfu- sion: Open-set multimodal 3d mapping. InRobotics: Science and Systems (RSS), 2023
2023
-
[22]
Khan and Y
Z. Khan and Y . Fu. Consistency and uncertainty: Identifying unreliable responses from black-box vision- language models for selective visual question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10854–10863, 2024
2024
-
[23]
S. Koch, N. Vaskevicius, M. Colosi, P. Hermosilla, and T. Ropinski. Open3DSG: Open-vocabulary 3D scene graphs from point clouds with queryable objects and open-set relationships. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[24]
L. Kuhn, Y . Gal, and S. Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664, 2023
Pith/arXiv arXiv 2023
-
[25]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
2017
-
[26]
G.K.R. Lau, H. Dao, N.K.H. Lin, and B.K.H. Low. Uncertainty quantification for mllms. InICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025
2025
-
[27]
L. Li, J. Lei, Z. Gan, and J. Liu. Adversarial vqa: A new benchmark for evaluating the robustness of vqa models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2042–2051, 2021
2042
-
[28]
L. Lian, Y . Ding, Y . Ge, S. Liu, H. Mao, B. Li, M. Pavone, M-Y . Liu, T. Darrell, A. Yala, and Y . Cui. Describe anything: Detailed localized image and video captioning. InIntl. Conf. on Computer Vision (ICCV), 2025
2025
-
[29]
F. Liu, K. Lin, L. Li, J. Wang, Y . Yacoob, and L. Wang. Aligning large multi-modal model with robust instruction tuning.CoRR, 2023
2023
-
[30]
H. Liu, C. Li, Q. Wu, and Y .J. Lee. Visual instruction tuning. InConf. on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[31]
X. Liu, A. Prabhu, F. Cladera, I.D. Miller, L. Zhou, C.J. Taylor, and V . Kumar. Active metric-semantic mapping by multiple aerial robots. In2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 3282–3288. IEEE, 2023
2023
-
[32]
Maggio, Y
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone. Clio: Real-time task-driven open-set 3D scene graphs.IEEE Robotics and Automation Letters (RA-L), 9(10):8921–8928, 2024
2024
-
[33]
A. Malinin and M. Gales. Uncertainty estimation in autoregressive structured prediction.arXiv preprint arXiv:2002.07650, 2020
arXiv 2002
-
[34]
P. Manakul, A. Liusie, and M.J.F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models.arXiv preprint arXiv:2303.08896, 2023
Pith/arXiv arXiv 2023
-
[35]
Marino, M
K. Marino, M. Rastegari, A. Farhadi, and R. Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pp. 3195–3204, 2019
2019
-
[36]
J. Ni, G.H. Abrego, N. Constant, J. Ma, K. Hall, D. Cer, and Y . Yang. Sentence-t5: Scalable sentence en- coders from pre-trained text-to-text models. InFindings of the association for computational linguistics: ACL 2022, pp. 1864–1874, 2022
2022
-
[37]
Nikitin, J
A. Nikitin, J. Kossen, Y . Gal, and P. Marttinen. Kernel language entropy: Fine-grained uncertainty quan- tification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37: 8901–8929, 2024. 11
2024
- [38]
-
[39]
Radford, J.W
A. Radford, J.W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language super- vision. In Marina Meila and Tong Zhang (eds.),Intl. Conf. on Machine Learning (ICML), volume 139 of Proceedings of Machine Learning Research, pp. 8748–87...
2021
-
[40]
A.Z. Ren, A. Dixit, A. Bodrova, S. Singh, S. Tu, N. Brown, P. Xu, L. Takayama, F. Xia, J. Varley, Z. Xu, D. Sadigh, A. Zeng, and A. Majumdar. Robots that ask for help: Uncertainty alignment for large language model planners. InConference on Robot Learning (CoRL), 2023
2023
-
[41]
A.Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh. Explore until confident: Efficient exploration for embodied question answering. InRobotics: Science and Systems (RSS), 2024
2024
-
[42]
Rosinol, A
A. Rosinol, A. Gupta, M. Abate, J. Shi, and L. Carlone. 3D dynamic scene graphs: Actionable spatial per- ception with places, objects, and humans. InRobotics: Science and Systems (RSS), 2020. doi: 10.15607/ RSS.2020.XVI.079. URLhttp://news.mit.edu/2020/robots-spatial-perception-0715
2020
-
[43]
Saxena, B
S. Saxena, B. Buchanan, C. Paxton, P. Liu, B. Chen, N. Vaskevicius, L. Palmieri, J. Francis, and O. Kroe- mer. Grapheqa: Using 3d semantic scene graphs for real-time embodied question answering. InConfer- ence on Robot Learning (CoRL), 2025
2025
-
[44]
Schmid, M
L. Schmid, M. Abate, Y . Chang, and L. Carlone. Khronos: A unified approach for spatio-temporal metric- semantic SLAM in dynamic environments. InRobotics: Science and Systems (RSS), 2024
2024
-
[45]
J. Su, J. Luo, H. Wang, and L. Cheng. Api is enough: Conformal prediction for large language models without logit-access.arXiv preprint arXiv:2403.01216, 2024
arXiv 2024
-
[46]
S. Tong, Z. Liu, Y . Zhai, Y . Ma, Y . LeCun, and S. Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 9568–9578, 2024
2024
-
[47]
D. Tran, J. Liu, M.W. Dusenberry, D. Phan, M. Collier, J. Ren, K. Han, Z. Wang, Z. Mariet, H. Hu, et al. Plex: Towards reliability using pretrained large model extensions.arXiv preprint arXiv:2207.07411, 2022
arXiv 2022
-
[48]
Upadhyay, S
U. Upadhyay, S. Karthik, M. Mancini, and Z. Akata. Probvlm: Probabilistic adapter for frozen vison- language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1899–1910, 2023
1910
-
[49]
A. Venkataramanan, P. Bodesheim, and J. Denzler. Probabilistic embeddings for frozen vision-language models: Uncertainty quantification with gaussian process latent variable models.arXiv preprint arXiv:2505.05163, 2025
arXiv 2025
-
[50]
Werby, C
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard. Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation.Robotics: Science and Systems (RSS), 2024
2024
- [51]
-
[52]
Y . Yang, H. Yang, J. Zhou, P. Chen, H. Zhang, Y . Du, and C. Gan. 3d-mem: 3d scene memory for embodied exploration and reasoning. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 17294–17303, 2025
2025
-
[53]
Q. Yu, J. Li, L. Wei, L. Pang, W. Ye, B. Qin, S. Tang, Q. Tian, and Y . Zhuang. Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12944–12953, 2024
2024
-
[54]
B. Zhai, S. Yang, C. Xu, S. Shen, K. Keutzer, and M. Li. Halle-switch: Controlling object hallucination in large vision language models.arXiv preprint arXiv:2310.01779, 2023
arXiv 2023
-
[55]
Zhang, C
A. Zhang, C. Eranki, C. Zhang, J-H. Park, R. Hong, P. Kalyani, L. Kalyanaraman, A. Gamare, A. Bagad, M. Esteva, et al. Toward robust robot 3-d perception in urban environments: The ut campus object dataset. IEEE Trans. Robotics, 40:3322–3340, 2024
2024
-
[56]
Zhang and L
H. Zhang and L. Carlone. Fuse: Quantifying uncertainty in multimodal llms by bayesian fusing epistemic and aleatoric uncertainty.Work in progress, 2026. 12
2026
-
[57]
Zhang, P
Y . Zhang, P. Sun, Y . Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang. Bytetrack: Multi-object tracking by associating every detection box. InEuropean Conf. on Computer Vision (ECCV), pp. 1–21. Springer, 2022
2022
- [58]
-
[59]
(Z (t) j )⊤ z⊤ ij #h Z (t) j zij i =
X. Zhao, W. Ding, Y . An, Y . Du, T. Yu, M. Li, M. Tang, and J. Wang. Fast segment anything, 2023. 13 Supplementary Material A Object-level Uncertainty Matters in DAAAM DAAAM is designed to build grounded semantic memory from a sparse set of representative views. However, not all objects are equally easy to describe from a limited number of views. Some ob...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.