From Question Answering to Task Completion: A Survey on Agent System and Harness Design
Pith reviewed 2026-06-27 04:38 UTC · model grok-4.3
The pith
Agent quality emerges from the interaction between model capability, runtime infrastructure, task structure, and evaluation design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
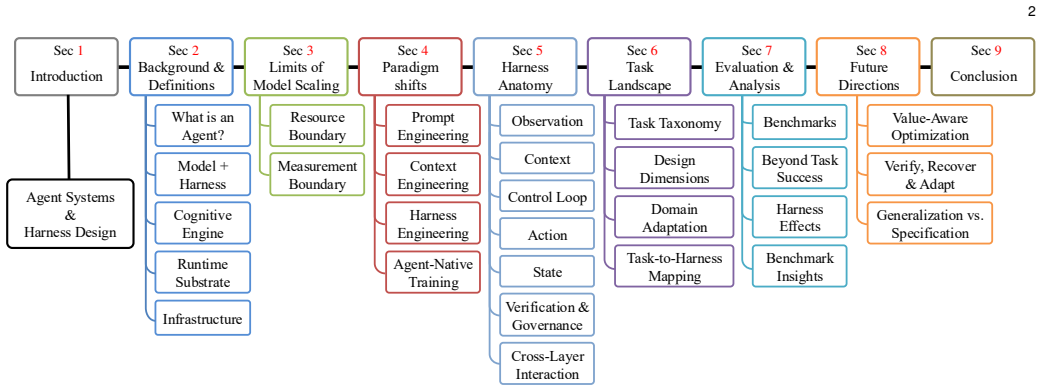
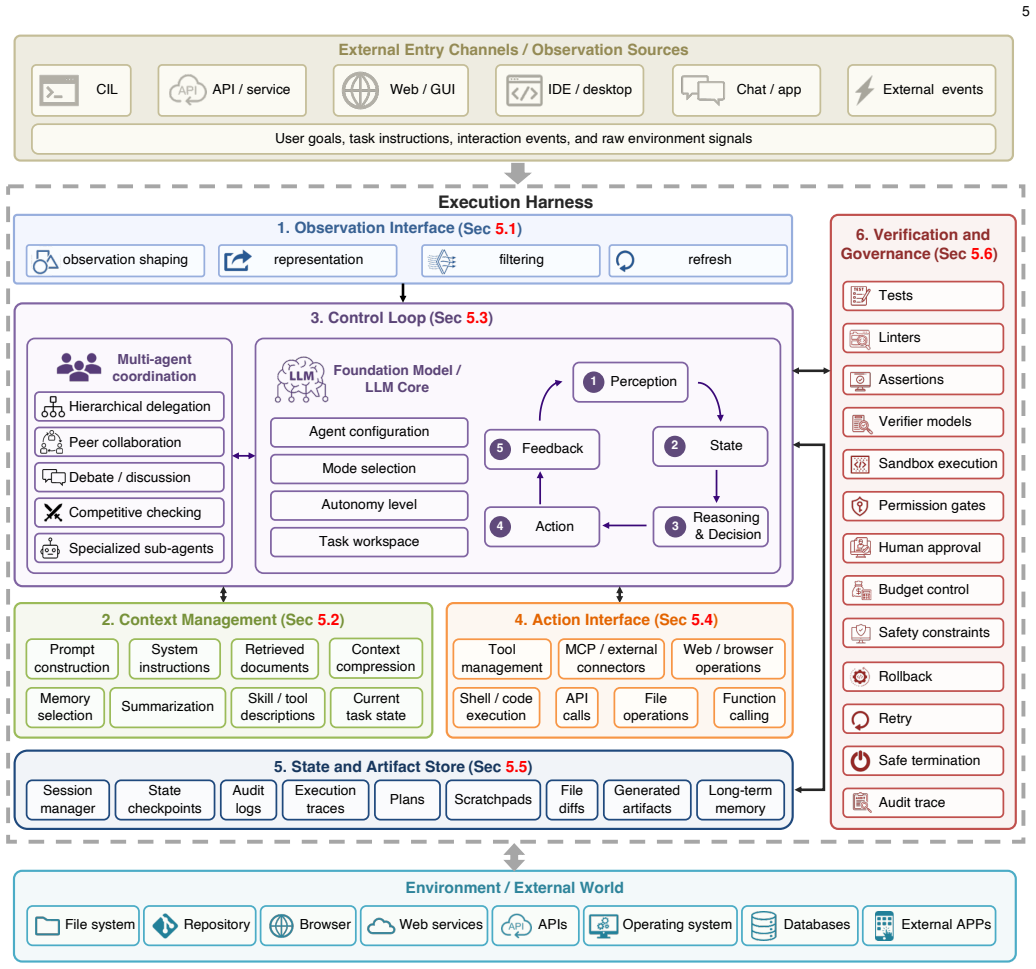
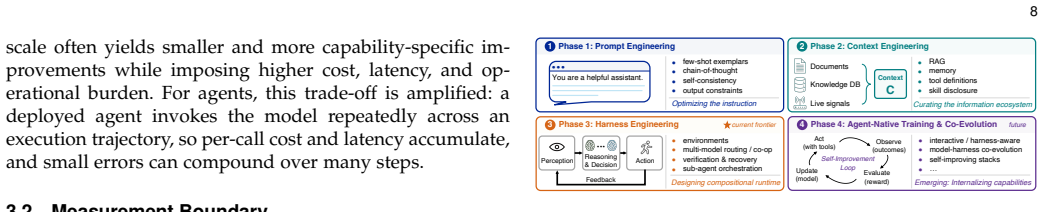
The paper establishes that agent quality—including success, efficiency, safety, and generalization—emerges from the interaction between model capability, runtime infrastructure, task structure, and evaluation design. It implements this claim by defining an LLM-based agent as a foundation model plus execution harness and by breaking the harness into the six coupled runtime responsibilities of observation, context, control, action, state, and verification. Using this lens the survey analyzes four paradigms of agent engineering, maps task and domain pressures onto harness configurations, reviews benchmark practices, and synthesizes evidence on how runtime choices affect long-horizon completion.
What carries the argument
The six coupled runtime responsibilities of the execution harness—observation, context, control, action, state, and verification—that interact with the foundation model to produce agent behavior over extended horizons.
If this is right
- Model-centric scaling reaches inherent limits without corresponding harness improvements.
- Task domains impose distinct pressures that require tailored harness configurations rather than one-size-fits-all designs.
- Evaluation practices must incorporate value-aware and safety metrics that go beyond simple task completion.
- Harness generalization across domains remains a central open engineering problem.
- Model-harness co-evolution offers a path to better reliability that isolated scaling cannot achieve.
Where Pith is reading between the lines
- The six-responsibility breakdown could be used to design new benchmarks that deliberately isolate one harness component while holding the others fixed.
- Safety failures may trace more often to weaknesses in verification or control than to the underlying model.
- The same model-harness lens might apply to non-LLM agent systems and reveal whether the six responsibilities remain a useful abstraction outside language models.
Load-bearing premise
The decomposition of the execution harness into exactly six coupled runtime responsibilities is both comprehensive and the right level of abstraction for diagnosing performance limits across domains.
What would settle it
An experiment in which varying harness configurations across the six responsibilities produces no measurable change in long-horizon success rates while model size alone accounts for all observed differences would falsify the claim that agent quality emerges from model-harness interaction.
Figures
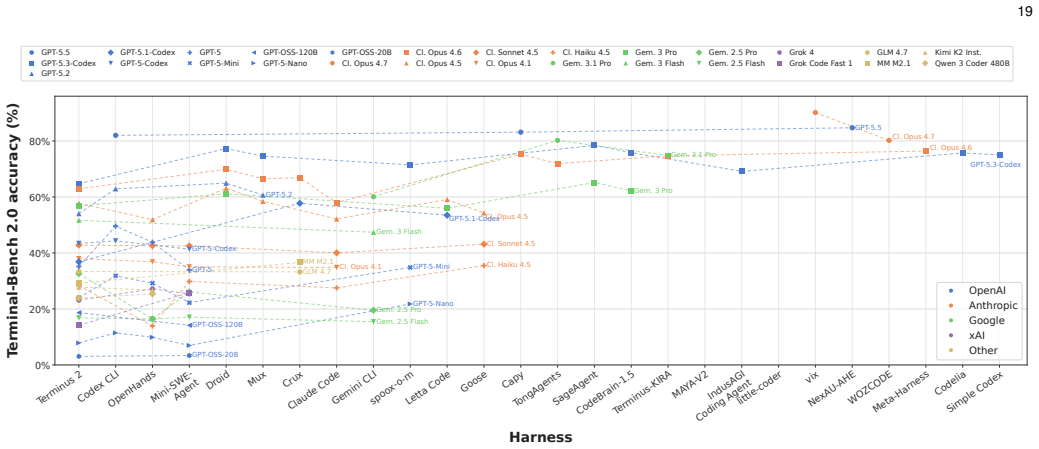
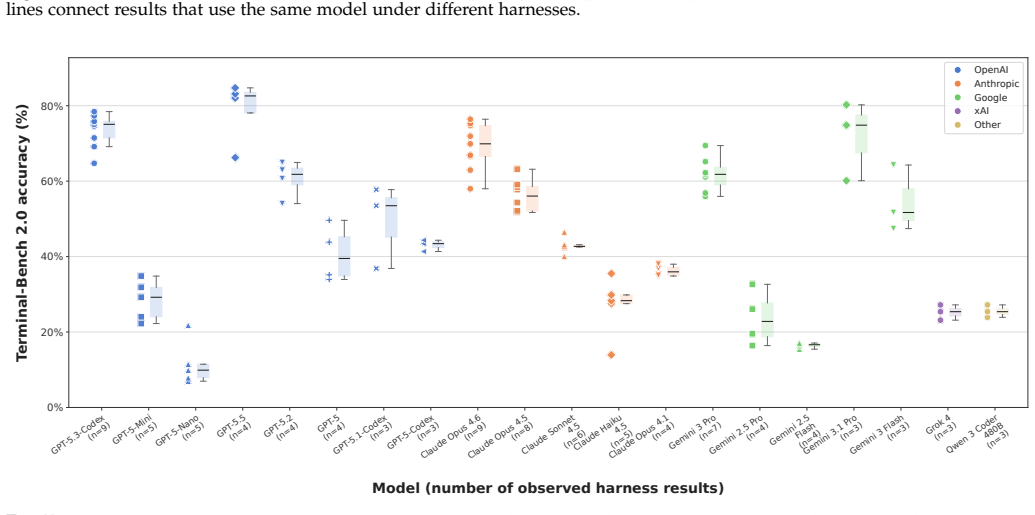
read the original abstract
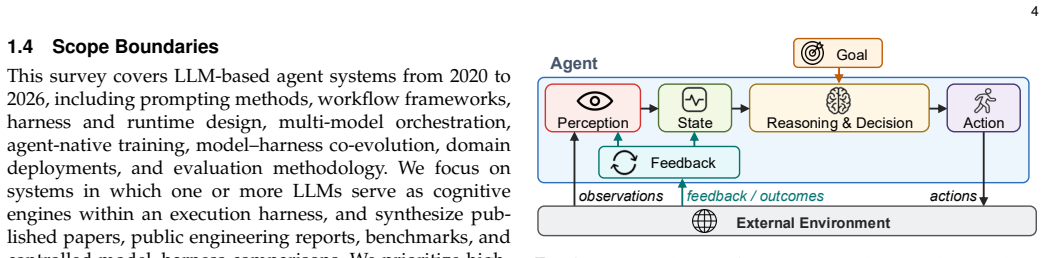
LLM-based agents mark a shift from passive question answering to active task completion: they perceive environments, invoke tools, maintain state, and act over extended horizons. As agent systems have evolved from prompt engineering to workflows and context engineering, harness engineering, and agent-native training with co-evolution, a central question has become increasingly important: where does the bottleneck in agent performance reside, in the foundation model, in the execution harness, or in the coupling between them? This survey examines LLM-based agents through a model-harness lens. We first clarify the functional definition of agents and the implementation view of an LLM-based agent as a foundation model coupled with an execution harness. We then analyze the limits of model-centric scaling, trace four paradigms of agent engineering, and decompose the execution harness into six coupled runtime responsibilities: observation, context, control, action, state, and verification. Using this decomposition, we map task properties and domain pressures to harness configurations, review benchmark and evaluation practices, and synthesize model-harness evidence on how runtime design affects long-horizon task completion, efficiency, and reliability. Finally, we identify open challenges in value-aware evaluation, safety, harness generalization, and model-harness co-evolution. Rather than treating agents as models with auxiliary tools, this survey argues that agent quality -- including success, efficiency, safety, and generalization -- emerges from the interaction between model capability, runtime infrastructure, task structure, and evaluation design. A collection of papers discussed in this survey is provided in https://github.com/ggjy/Awesome-Agent-Engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on LLM-based agents that shift from passive question answering to active task completion. It defines agents functionally as foundation models coupled to execution harnesses, analyzes the limits of model-centric scaling, traces four paradigms of agent engineering, decomposes the harness into six coupled runtime responsibilities (observation, context, control, action, state, verification), maps task properties and domain pressures onto harness configurations, reviews benchmark and evaluation practices, and identifies open challenges in value-aware evaluation, safety, harness generalization, and model-harness co-evolution. The central thesis is that agent quality (success, efficiency, safety, generalization) emerges from the interaction of model capability, runtime infrastructure, task structure, and evaluation design, with an accompanying GitHub collection of referenced papers.
Significance. If the mappings and decomposition are adequately supported by the reviewed literature, the survey supplies a coherent organizational lens for diagnosing performance bottlenecks in long-horizon agent systems and for guiding model-harness co-evolution research. The explicit provision of a curated paper collection is a concrete community resource. The framing moves the field beyond treating agents as models plus auxiliary tools toward a coupled-systems view.
minor comments (3)
- [Abstract] Abstract: the four paradigms of agent engineering are referenced but not enumerated; a parenthetical list or short clause naming them would improve immediate readability.
- [Harness decomposition section] The manuscript should state explicitly (in the harness-decomposition section) whether the six responsibilities are presented as an exhaustive partition or as one useful organizational cut derived from observed practices, to forestall misinterpretation of the framework's scope.
- [Throughout] Minor terminology consistency: 'harness' and 'execution harness' appear interchangeably; a single preferred term or clear definition on first use would reduce potential ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed summary, positive assessment of significance, and recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No circularity: survey synthesizes external literature
full rationale
This is a survey paper that organizes existing agent literature under a model-harness interpretive lens. It presents the six-responsibility decomposition (observation, context, control, action, state, verification) explicitly as an organizational framework drawn from observed practices across domains, without any primary derivations, equations, fitted parameters, or uniqueness theorems. No load-bearing steps reduce to self-citation chains, self-definitional loops, or renamed empirical patterns; the central claim that agent quality emerges from model-harness-task-evaluation interactions is framed as a synthesizing perspective rather than a derived quantity. The paper is self-contained against external benchmarks as a literature review.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P . Dhari- wal, and et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, 2020
2020
-
[2]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwrightet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, 2022
2022
-
[3]
Large language model agent: A survey on methodology, appli- cations and challenges,
J. Luo, W. Zhang, Y. Yuan, Y. Zhao, J. Yang, Y. Gu, B. Wuet al., “Large language model agent: A survey on methodology, appli- cations and challenges,”arXiv preprint arXiv:2503.21460, 2025
Pith/arXiv arXiv 2025
-
[4]
The rise and potential of large language model based agents: A survey,
Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wanget al., “The rise and potential of large language model based agents: A survey,”Science China Information Sciences, 2025
2025
-
[5]
Introducing devin, the first AI software engi- neer,
Cognition Labs, “Introducing devin, the first AI software engi- neer,” https://www.cognition.ai/blog/introducing-devin, 2024
2024
-
[6]
How claude code works,
Anthropic, “How claude code works,” https://docs.claude.com/en/docs/claude-code/how-claude- code-works, 2025
2025
-
[7]
Harness engineering: Leveraging codex in an agent- first world,
OpenAI, “Harness engineering: Leveraging codex in an agent- first world,” https://openai.com/index/harness-engineering/, 2026
2026
-
[8]
From mind to machine: The rise of manus ai as a fully autonomous digital agent,
M. Shen, Y. Li, L. Chen, Z. Fan, Y. Li, and Q. Yang, “From mind to machine: The rise of manus ai as a fully autonomous digital agent,”arXiv preprint arXiv:2505.02024, 2025
arXiv 2025
-
[9]
AutoGPT,
T. B. Richards, “AutoGPT,” https://github.com/ Significant-Gravitas/AutoGPT, 2023
2023
-
[10]
Openhands: An open platform for ai software developers as generalist agents,
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singhet al., “Openhands: An open platform for ai software developers as generalist agents,” inInternational Conference on Learning Representations, 2025
2025
-
[11]
OpenClaw: Personal AI assistant,
OpenClaw Team, “OpenClaw: Personal AI assistant,” https:// github.com/openclaw/openclaw, 2025
2025
-
[12]
Measuring massive multitask language un- derstanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language un- derstanding,”arXiv preprint arXiv:2009.03300, 2020
Pith/arXiv arXiv 2009
-
[13]
Gpqa: A graduate-level google-proof q&a benchmark,
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani et al., “Gpqa: A graduate-level google-proof q&a benchmark,” in First conference on language modeling, 2024
2024
-
[14]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P . D. O. Pinto, J. Kaplan, H. Edwards, Y. Burdaet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[15]
L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhanget al., “Human- ity’s last exam,”arXiv preprint arXiv:2501.14249, 2025
Pith/arXiv arXiv 2025
-
[16]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” inInternational Conference on Learning Representations, 2024
2024
-
[17]
Webarena: A realistic web environ- ment for building autonomous agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Friedet al., “Webarena: A realistic web environ- ment for building autonomous agents,” inInternational Conference on Learning Representations, 2024
2024
-
[18]
Osworld: Benchmarking mul- timodal agents for open-ended tasks in real computer environ- ments,
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Leiet al., “Osworld: Benchmarking mul- timodal agents for open-ended tasks in real computer environ- ments,”Advances in Neural Information Processing Systems, 2024
2024
-
[19]
Theagent- company: benchmarking llm agents on consequential real world tasks,
F. F. Xu, Y. Song, B. Li, Y. Tang, K. Jain, M. Baoet al., “Theagent- company: benchmarking llm agents on consequential real world tasks,”Advances in Neural Information Processing Systems, 2026
2026
-
[20]
Terminal- bench: Benchmarking agents on hard, realistic tasks in command line interfaces,
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchananet al., “Terminal- bench: Benchmarking agents on hard, realistic tasks in command line interfaces,”arXiv preprint arXiv:2601.11868, 2026. 24
Pith/arXiv arXiv 2026
-
[21]
Swe-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,”Advances in Neural Information Processing Systems, 2024
2024
-
[22]
My AI adoption journey,
M. Hashimoto, “My AI adoption journey,” https://mitchellh. com/writing/my-ai-adoption-journey, 2026
2026
-
[23]
Natural-language agent harnesses,
L. Pan, L. Zou, S. Guo, J. Ni, and H.-T. Zheng, “Natural-language agent harnesses,”arXiv preprint arXiv:2603.25723, 2026
Pith/arXiv arXiv 2026
-
[24]
Meta-harness: End-to-end optimization of model harnesses,
Y. Lee, R. Nair, Q. Zhang, K. Lee, O. Khattab, and C. Finn, “Meta-harness: End-to-end optimization of model harnesses,” arXiv preprint arXiv:2603.28052, 2026
Pith/arXiv arXiv 2026
-
[25]
Opensquilla: Token-efficient ai agent with same budget, higher intelligence density,
OpenSquilla Team, “Opensquilla: Token-efficient ai agent with same budget, higher intelligence density,” https://github.com/ opensquilla/opensquilla, 2026, apache-2.0 License
2026
-
[26]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, 2022
2022
-
[27]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,”arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[28]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,”Advances in neural information pro- cessing systems, 2023
2023
-
[29]
Effective context engineering for AI agents,
Anthropic, “Effective context engineering for AI agents,” https://www.anthropic.com/engineering/ effective-context-engineering-for-ai-agents, 2025
2025
-
[30]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P . Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Ad- vances in neural information processing systems, 2020
2020
-
[31]
Memgpt: towards llms as operating systems
C. Packer, V . Fang, S. Patil, K. Lin, S. Wooders, and J. Gonzalez, “Memgpt: towards llms as operating systems.” 2023
2023
-
[32]
Tool- former: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Tool- former: Language models can teach themselves to use tools,” Advances in neural information processing systems, 2023
2023
-
[33]
Gorilla: Large language model connected with massive apis,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,”Advances in Neural Information Processing Systems, 2024
2024
-
[34]
Voyager: An open-ended embodied agent with large language models,
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar, “Voyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
Pith/arXiv arXiv 2023
-
[35]
Agent skills for large language models: Architecture, acquisition, security, and the path forward,
R. Xu and Y. Yan, “Agent skills for large language models: Architecture, acquisition, security, and the path forward,”arXiv preprint arXiv:2602.12430, 2026
Pith/arXiv arXiv 2026
-
[36]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
Pith/arXiv arXiv 2022
-
[37]
Magentic-one: A generalist multi-agent system for solving com- plex tasks,
A. Fourney, G. Bansal, H. Mozannar, C. Tan, E. Salinas, F. Niedt- ner, G. Proebsting, G. Bassman, J. Gerrits, J. Alberet al., “Magentic-one: A generalist multi-agent system for solving com- plex tasks,”arXiv preprint arXiv:2411.04468, 2024
Pith/arXiv arXiv 2024
-
[38]
Symphony: Synergistic multi-agent planning with heterogeneous language model assembly,
W. Zhu, Z. Tang, and K. Yue, “Symphony: Synergistic multi-agent planning with heterogeneous language model assembly,”arXiv preprint arXiv:2601.22623, 2026
arXiv 2026
-
[39]
Openai agents sdk,
OpenAI, “Openai agents sdk,” https://github.com/openai/ openai-agents-python, 2025
2025
-
[40]
Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses,
J. Lin, S. Liu, C. Pan, L. Lin, S. Dou, X. Huang, H. Yan, Z. Han, and T. Gui, “Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses,”arXiv preprint arXiv:2604.25850, 2026
Pith/arXiv arXiv 2026
-
[41]
Webrl: Training llm web agents via self- evolving online curriculum reinforcement learning,
Z. Qi, X. Liu, I. L. Iong, H. Lai, X. Sun, J. Sun, X. Yang, Y. Yang, S. Yao, W. Xuet al., “Webrl: Training llm web agents via self- evolving online curriculum reinforcement learning,” inInterna- tional Conference on Learning Representations, vol. 2025, 2025
2025
-
[42]
Computerrl: Scaling end-to-end online reinforcement learning for computer use agents,
H. Lai, X. Liu, Y. Zhao, H. Xu, H. Zhang, B. Jing, Y. Ren, S. Yao, Y. Dong, and J. Tang, “Computerrl: Scaling end-to-end online reinforcement learning for computer use agents,”arXiv preprint arXiv:2508.14040, 2025
arXiv 2025
-
[43]
Deepseek-r1: Incentivizing reasoning capability in llms via re- inforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P . Wang, Q. Zhuet al., “Deepseek-r1: Incentivizing reasoning capability in llms via re- inforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[44]
Evolver: Self-evolving llm agents through an experience-driven lifecycle,
R. Wu, X. Wang, J. Mei, P . Cai, D. Fuet al., “Evolver: Self-evolving llm agents through an experience-driven lifecycle,”arXiv preprint arXiv:2510.16079, 2025
Pith/arXiv arXiv 2025
-
[45]
Agentevolver: Towards efficient self- evolving agent system,
Y. Zhai, S. Tao, C. Chen, A. Zou, Z. Chen, Q. Fu, S. Mai, L. Yu, J. Deng, Z. Caoet al., “Agentevolver: Towards efficient self- evolving agent system,”arXiv preprint arXiv:2511.10395, 2025
arXiv 2025
-
[46]
Darwin godel machine: Open-ended evolution of self-improving agents,
J. Zhang, S. Hu, C. Lu, R. Lange, and J. Clune, “Darwin godel machine: Open-ended evolution of self-improving agents,”arXiv preprint arXiv:2505.22954, 2025
Pith/arXiv arXiv 2025
-
[47]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, 2024
2024
-
[48]
Large language model based multi- agents: A survey of progress and challenges,
T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi- agents: A survey of progress and challenges,”arXiv preprint arXiv:2402.01680, 2024
Pith/arXiv arXiv 2024
-
[49]
A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y. Wu, and Y. Yang, “A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges,”Vicinagearth, 2024
2024
-
[50]
Multi-agent collaboration mechanisms: A survey of llms,
K.-T. Tran, D. Dao, M.-D. Nguyen, Q.-V . Pham, B. O’Sullivan, and H. D. Nguyen, “Multi-agent collaboration mechanisms: A survey of llms,”arXiv preprint arXiv:2501.06322, 2025
Pith/arXiv arXiv 2025
-
[51]
Survey on evaluation of llm-based agents,
A. Yehudai, L. Eden, A. Li, G. Uziel, Y. Zhao, R. Bar-Haim, A. Cohan, and M. Shmueli-Scheuer, “Survey on evaluation of llm-based agents,”arXiv preprint arXiv:2503.16416, 2025
Pith/arXiv arXiv 2025
-
[52]
Gui agents: A survey,
D. Nguyen, J. Chen, Y. Wang, G. Wu, N. Park, Z. Hu, H. Lyu, J. Wu, R. Aponte, Y. Xiaet al., “Gui agents: A survey,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[53]
A survey on vision–language–action models for embodied ai,
Y. Ma, Z. Song, Y. Zhuang, J. Hao, and I. King, “A survey on vision–language–action models for embodied ai,”IEEE Transac- tions on Neural Networks and Learning Systems, 2026
2026
-
[54]
A survey on trustworthy llm agents: Threats and countermeasures,
M. Yu, F. Meng, X. Zhou, S. Wang, J. Mao, L. Pan, T. Chen, K. Wanget al., “A survey on trustworthy llm agents: Threats and countermeasures,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025
2025
-
[55]
Agent harness for large language model agents: A survey,
Q. Meng, Y. Wang, L. Chen, Q. Wang, C. Lu, W. Wu, Y. Gao, Y. Wu, and Y. Hu, “Agent harness for large language model agents: A survey,” 2026
2026
-
[56]
Agent harness engineering: A survey,
J. Li, X. Xiao, Y. Zhang, C. Liu, L. Zhao, X. Liao, Y. Ji, J. Wang, J. Gu, Y. Geet al., “Agent harness engineering: A survey,” OpenReview preprint, 2026
2026
-
[57]
X. Ning, K. Tieu, D. Fu, T. Wei, Z. Li, Y. Bei, J. Zou, M. Ai, Z. Liu, T.-W. Liet al., “Code as agent harness,”arXiv preprint arXiv:2605.18747, 2026
Pith/arXiv arXiv 2026
-
[58]
Intelligent agents: Theory and practice,
M. Wooldridge and N. R. Jennings, “Intelligent agents: Theory and practice,”The knowledge engineering review, 1995
1995
-
[59]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P . Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th annual acm symposium on user interface software and technology, 2023
2023
-
[60]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst conference on language modeling, 2024
2024
-
[61]
Metagpt: Meta program- ming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y. Cheng, J. Wang, C. Zhang, S. Yau, Z. Lin, L. Zhouet al., “Metagpt: Meta program- ming for a multi-agent collaborative framework,” inInternational Conference on Learning Representations, 2024
2024
-
[62]
Large language model guided tree-of-thought,
J. Long, “Large language model guided tree-of-thought,”arXiv preprint arXiv:2305.08291, 2023
arXiv 2023
-
[63]
Reflexion: Language agents with verbal reinforcement learn- ing,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learn- ing,”Advances in neural information processing systems, 2023
2023
-
[64]
Effective harnesses for long-running agents,
Anthropic, “Effective harnesses for long-running agents,” https://www.anthropic.com/engineering/effective-harnesses- for-long-running-agents, 2025
2025
-
[65]
Model context protocol,
Anthropic, “Model context protocol,” https:// modelcontextprotocol.io/introduction, 2025
2025
-
[66]
Agent2agent (a2a,
G. Cloud, “Agent2agent (a2a,” https://github.com/a2aproject/ A2A, 2025
2025
-
[67]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[68]
Training compute-optimal large language models,
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskayaet al., “Training compute-optimal large language models,”arXiv preprint arXiv:2203.15556, 2022. 25
Pith/arXiv arXiv 2022
-
[69]
Palm: Scaling language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P . Barhamet al., “Palm: Scaling language modeling with pathways,”Journal of machine learning research, 2023
2023
-
[70]
Codegen: An open large language model for code with multi-turn program synthesis,
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with multi-turn program synthesis,”arXiv preprint arXiv:2203.13474, 2022
Pith/arXiv arXiv 2022
-
[71]
Competition- level code generation with alphacode,
Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lagoet al., “Competition- level code generation with alphacode,”Science, 2022
2022
-
[72]
Solving quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag et al., “Solving quantitative reasoning problems with language models,”Advances in neural information processing systems, 2022
2022
-
[73]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P . Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[74]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P . Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynoldset al., “Flamingo: a visual language model for few-shot learning,”Advances in neural information processing systems, 2022
2022
-
[75]
On scaling up a multilingual vision and language model,
X. Chen, J. Djolonga, P . Padlewski, B. Mustafa, S. Changpinyo, J. Wu, C. R. Ruiz, S. Goodmanet al., “On scaling up a multilingual vision and language model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[76]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandeyet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[77]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y. Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,”Advances in neural information pro- cessing systems, vol. 36, pp. 21 558–21 572, 2023
2023
-
[78]
Train- ing verifiers to solve math word problems,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Train- ing verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[79]
Measuring mathematical problem solving with the math dataset,
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset,”arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[80]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark,
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandraet al., “Mmlu-pro: A more robust and challenging multi-task language understanding benchmark,”Advances in Neural Information Processing Systems, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.