Strategies for Guiding LLMs to Use Software Design Patterns: A Case of Singleton
Pith reviewed 2026-06-29 15:42 UTC · model grok-4.3
The pith
Iterative binary feedback best aligns LLM code generation with the Singleton design pattern while preserving functionality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
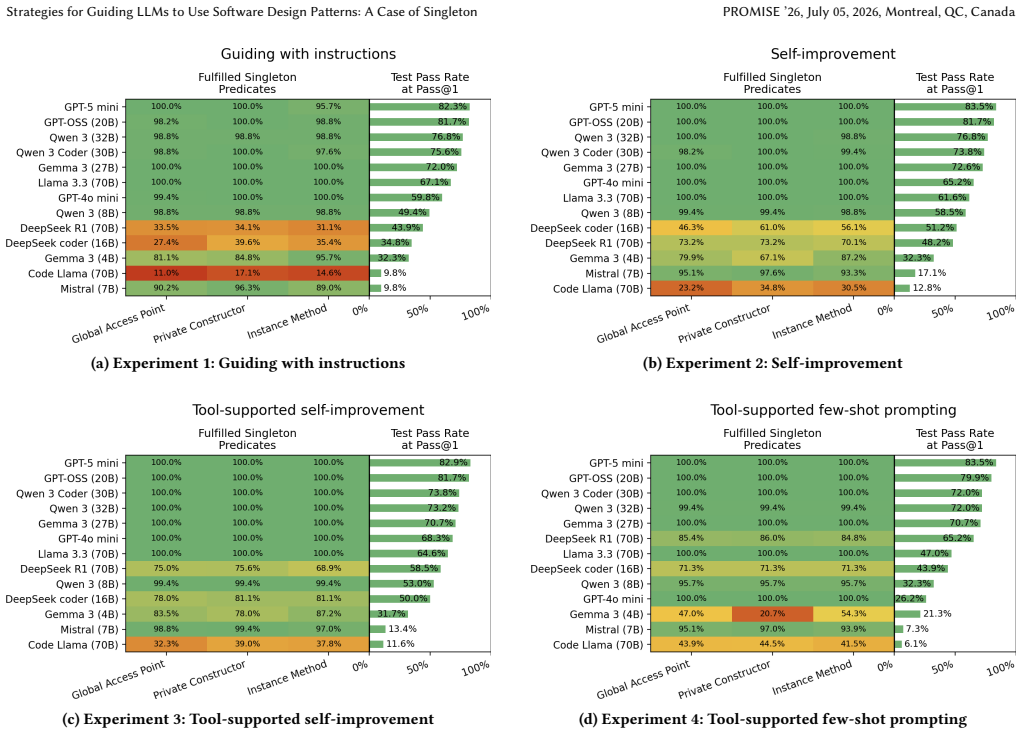
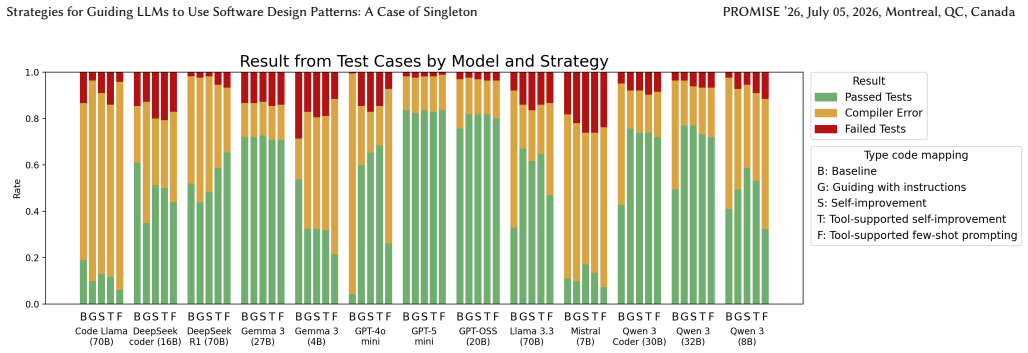
The central finding is that iterative binary automated feedback provides the best overall alignment with the Singleton pattern across models while preserving or improving code functionality, with model-specific optima such as instructions alone achieving 100% Singleton adherence and a 34.1 percentage point gain in tests passed for Llama 3.3, and binary feedback reaching 99.2% alignment plus 58.6% functionality for Qwen 3 (8B).
What carries the argument
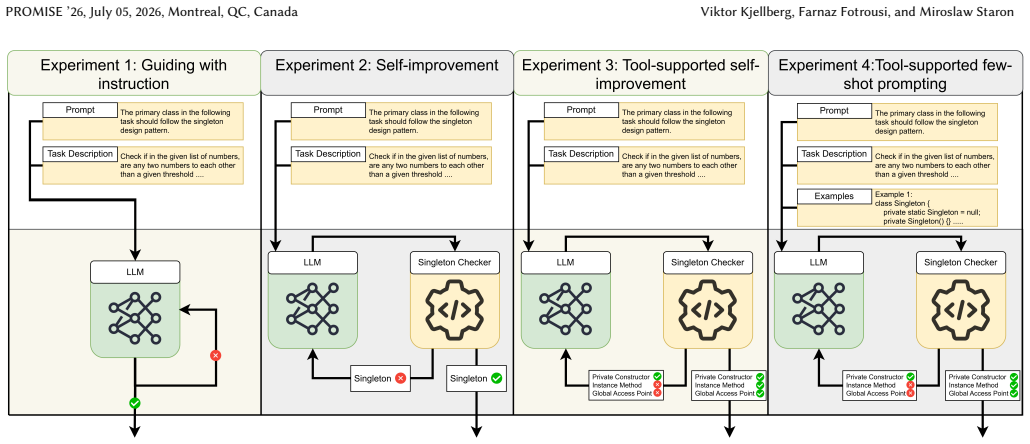
Four prompting strategies (plain instructions, binary automated feedback, extensive automated feedback, and extensive feedback with few-shot examples) applied iteratively to detect and enforce Singleton adherence in generated Java code.
If this is right
- Simple instructions alone can drive certain models like Llama 3.3 to 100% Singleton usage while also raising functional correctness.
- Binary feedback scales well for models like Qwen 3 (8B) to reach near-perfect pattern adherence without sacrificing test passage rates.
- Strategy choice must be tuned per model rather than applied uniformly.
- Even lightweight feedback loops suffice to steer LLMs toward established design patterns in code generation.
Where Pith is reading between the lines
- The approach may transfer to other creational or structural patterns if similar automated detectors can be built.
- Combining binary feedback with larger context windows could improve results on more complex multi-class designs.
- These techniques might reduce the need for post-generation refactoring in LLM-assisted development pipelines.
Load-bearing premise
The automated checker used to score whether generated code follows the Singleton pattern does so accurately and without systematic bias.
What would settle it
Running the same 164 tasks with an independent human review or alternative detector that finds substantially lower Singleton adherence under binary feedback than reported would falsify the effectiveness claim.
Figures

read the original abstract
Large Language Models (LLMs) can generate functional source code from natural-language prompts, but often fail to consistently follow higher-level architectural structures or design patterns. Since LLMs are increasingly used in software engineering, their ability to apply established design principles to generated code is crucial to the long-term success of software products. Therefore, the goal of this paper is to identify strategies for guiding LLMs to incorporate design patterns into the generated source code. We designed a computational experiment to evaluate the ability of 13 LLMs to generate code that follows the Singleton design pattern, using four prompting strategies: instructions, binary automated feedback, extensive automated feedback, and extensive feedback with few-shot prompts, in 164 Java coding challenges from HumanEval-X. Our results shows that the optimal strategy to guide LLMs to include design patterns depends heavily on the type of model. Still, overall, iterative binary feedback provides the best alignment with Singleton while preserving or improving the code's functionality. With guiding with instructions, Llama 3.3 generated Singleton classes in 100% of cases and improved code functionality, increasing the number of tests passed by 34.1 percentage points. It achieved a similar result with guidance through instructions and binary feedback. Qwen 3 (8B) increased the alignment with Singleton to 99.2% and the functionality to 58.6% using binary feedback. Our result suggests that even simple strategies can be used to guide LLMs to use design patterns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study evaluating the effectiveness of four prompting strategies—instructions, binary automated feedback, extensive automated feedback, and extensive feedback with few-shot prompts—in guiding 13 large language models to generate Java code adhering to the Singleton design pattern across 164 tasks from the HumanEval-X benchmark. The key finding is that iterative binary feedback generally provides the best balance of Singleton alignment and preserved or improved functionality, with examples including Llama 3.3 achieving 100% Singleton generation and a 34.1 percentage point increase in tests passed using instructions, and Qwen 3 (8B) reaching 99.2% alignment and 58.6% functionality with binary feedback.
Significance. If the automated detection of Singleton adherence proves reliable, the work supplies concrete, model-specific guidance on prompting strategies for enforcing design patterns in LLM-generated code, a practically relevant contribution to software engineering given the growing use of LLMs for code synthesis. The scale (13 models, 164 tasks) and use of a public benchmark are strengths that support reproducibility and comparability.
major comments (1)
- [Abstract] Abstract: All reported metrics (e.g., 100% Singleton for Llama 3.3, 99.2% for Qwen 3, functionality deltas) depend on an unspecified automated detector for Singleton adherence in generated Java code. No description of the detection rules (static analysis, AST patterns, regex on private constructor + getInstance, or LLM judge), precision/recall, or human validation is provided. This is load-bearing for the central claim that binary feedback improves alignment while preserving functionality.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying the need for greater transparency around the automated detector, which is indeed central to our claims. We address the comment below and will make the requested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: All reported metrics (e.g., 100% Singleton for Llama 3.3, 99.2% for Qwen 3, functionality deltas) depend on an unspecified automated detector for Singleton adherence in generated Java code. No description of the detection rules (static analysis, AST patterns, regex on private constructor + getInstance, or LLM judge), precision/recall, or human validation is provided. This is load-bearing for the central claim that binary feedback improves alignment while preserving functionality.
Authors: We agree that the description of the automated detector is insufficient in the current manuscript and that this detail is load-bearing. The detector is implemented via static analysis (JavaParser AST traversal to confirm a private constructor and a public static getInstance() method returning the instance), but the manuscript provides only a high-level reference. In the revision we will add a dedicated subsection in Methods that specifies the exact rules, the library used, edge-case handling, and results of human validation on a random sample of 50 outputs (reporting precision, recall, and agreement rate). revision: yes
Circularity Check
No circularity: purely empirical measurement on public benchmark
full rationale
The paper conducts a computational experiment applying four prompting strategies to 13 LLMs across 164 HumanEval-X Java tasks and reports measured percentages of Singleton adherence and test-pass rates. No equations, fitted parameters, derivations, or predictions appear. No self-citations are invoked to justify core claims. The results stand or fall on the reported experimental outcomes against the external benchmark; the measurement procedure itself is not shown to reduce to a self-definition or prior self-citation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can generate functional source code from natural-language prompts
- domain assumption Following established design patterns improves long-term software quality
Reference graph
Works this paper leans on
-
[1]
Ziqian Bi, Keyu Chen, Chiung-Yi Tseng, Danyang Zhang, Tianyang Wang, Hongying Luo, Lu Chen, Junming Huang, Jibin Guan, Junfeng Hao, Xinyuan Song, and Junhao Song. 2025. Is GPT-OSS Good? A Comprehensive Eval- uation of OpenAI’s Latest Open Source Models. arXiv:2508.12461 [cs.CL] https://arxiv.org/abs/2508.12461
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
2020
-
[3]
2007.Pattern-oriented software architecture, on patterns and pattern languages
Frank Buschmann, Kevlin Henney, and Douglas C Schmidt. 2007.Pattern-oriented software architecture, on patterns and pattern languages. John wiley & sons
2007
-
[4]
Pinzhen Chen, Zhicheng Guo, Barry Haddow, and Kenneth Heafield. 2024. Itera- tive translation refinement with large language models. InProceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1). 181–190
2024
-
[5]
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2023. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
1995.Design patterns: elements of reusable object-oriented software
Erich Gamma. 1995.Design patterns: elements of reusable object-oriented software. Vol. 431. Addison-Wesley
1995
-
[7]
Shuzheng Gao, Xin-Cheng Wen, Cuiyun Gao, Wenxuan Wang, Hongyu Zhang, and Michael R. Lyu. 2023. What Makes Good In-Context Demonstrations for Code Intelligence Tasks with LLMs?. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). 761–773. doi:10.1109/ASE56229.2023. 00109
-
[8]
Jasmin Jahić and Ashkan Sami. 2024. State of Practice: LLMs in Software En- gineering and Software Architecture. In2024 IEEE 21st International Confer- ence on Software Architecture Companion (ICSA-C). 311–318. doi:10.1109/ICSA- C63560.2024.00059
-
[9]
Dae-Kyoo Kim. 2025. Comparative analysis of design pattern implementation validity in LLM-based code refactoring.Journal of Systems and Software230 (2025), 112519. doi:10.1016/j.jss.2025.112519
-
[10]
Geunwoo Kim, Pierre Baldi, and Stephen McAleer. 2023. Language Models can Solve Computer Tasks. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 39648–39677
2023
-
[11]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[12]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems36 (2023), 46534–46594
2023
-
[13]
Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika12, 2 (1947), 153–157
1947
-
[14]
Phu H Nguyen, Koen Yskout, Thomas Heyman, Jacques Klein, Riccardo Scan- dariato, and Yves Le Traon. 2015. Sospa: A system of security design patterns for systematically engineering secure systems. In2015 ACM/IEEE 18th International Conference on Model Driven Engineering Languages and Systems (MODELS). IEEE, 246–255
2015
-
[15]
Zhenyu Pan, Xuefeng Song, Yunkun Wang, Rongyu Cao, Binhua Li, Yongbin Li, and Han Liu. 2025. Do Code LLMs Understand Design Patterns?. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). 209–212. doi:10.1109/LLM4Code66737.2025.00031
-
[16]
Sushant Kumar Pandey, Miroslaw Staron, Jennifer Horkoff, Mirosław Ochodek, Nicholas Mucci, and Darko Durisic. 2023. TransDPR: Design Pattern Recog- nition Using Programming Language Models. In2023 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). 1–7. doi:10.1109/ESEM56168.2023.10304862
-
[17]
Yun Peng, Akhilesh Deepak Gotmare, Michael R Lyu, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. 2025. Perfcodegen: Improving performance of llm generated code with execution feedback. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE, 1–13
2025
-
[18]
Hassan Samo, Kashif Ali, Muniba Memon, Faheem Ahmed Abbasi, Muham- mad Yaqoob Koondhar, and Kamran Dahri. 2024. Fine-Tuning Mistral 7b Large Language Model For Python Query Response And Code Generation: A Parameter Efficient Approach.V A WKUM Transactions on Computer Sciences12, 1 (Jun. 2024), 205–217. doi:10.21015/vtcs.v12i1.1885
- [19]
-
[20]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learn- ing. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 8634–8652
2023
-
[21]
Miroslaw Staron and Silvia Abrahão. 2025. Exploring Generative AI in Automated Software Engineering.IEEE Software42, 3 (2025), 142–145. doi:10.1109/MS.2025. 3533754
-
[22]
Krzysztof Stencel and Patrycja Węgrzynowicz. 2008. Implementation Variants of the Singleton Design Pattern. InOn the Move to Meaningful Internet Systems: OTM 2008 Workshops, Robert Meersman, Zahir Tari, and Pilar Herrero (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 396–406
2008
-
[23]
Zhao Tian, Junjie Chen, and Xiangyu Zhang. 2025. Fixing Large Language Models’ Specification Misunderstanding for Better Code Generation. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 645–645
2025
-
[24]
Sizhe Wang, Zhengren Wang, Dongsheng Ma, Yongan Yu, Rui Ling, Zhiyu Li, Feiyu Xiong, and Wentao Zhang. 2026. CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation. arXiv:2504.21751 [cs.SE] https: //arxiv.org/abs/2504.21751
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.