TERMS-Bench: Diagnosing LLM Negotiation Agents Beyond Deal Rate
Pith reviewed 2026-05-15 02:51 UTC · model grok-4.3
The pith
A Bayesian-game testbed diagnoses LLM agents in price negotiation by measuring surplus extraction, cue use, and belief calibration rather than deal rate alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
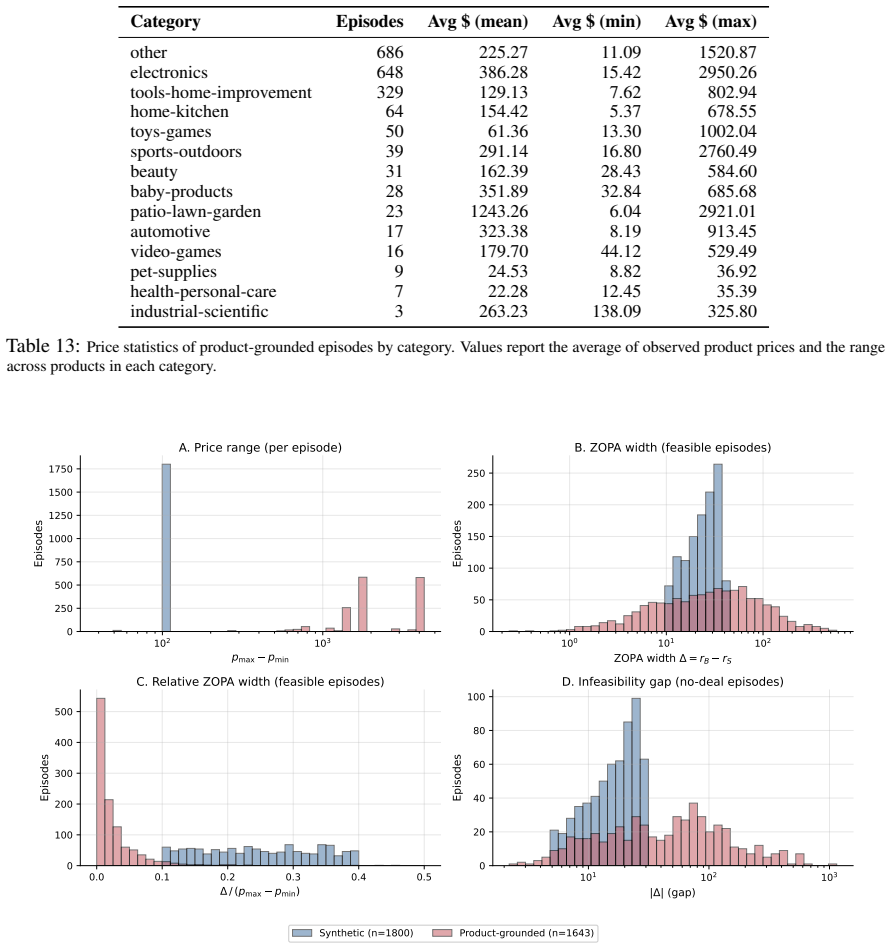
Terms-Bench instantiates a Bayesian-game verifier in bilateral price negotiation so that the counterpart's latent type, simulator policy, and payoff structure become observable diagnostics; this setup reveals that frontier LLMs saturate deal rate while diverging on surplus extraction, cue use, belief calibration, and compliance, exposing agent-specific bargaining bottlenecks that aggregate metrics conceal.
What carries the argument
The Bayesian-game framework in bilateral price negotiation, with the counterpart's private state and policy hidden from the agent but known to the evaluator, turning the opponent into an oracle reference for measuring optimality gaps.
If this is right
- Models can be compared by their distance to the oracle-optimal surplus given the known policy, rather than by deal rate.
- Failures in belief updating can be separated from failures in communication strategy or constraint compliance.
- Training interventions can target the specific measured gaps, such as cue interpretation or surplus-maximizing offers.
- The same verifier structure can be reused across different payoff matrices to test generalization of strategic reasoning.
Where Pith is reading between the lines
- Extending the benchmark to multi-issue or multi-party settings would expose whether current models handle increased dimensionality in hidden information.
- Agents that extract more surplus against fixed policies may perform better in real markets where counterpart types are drawn from similar distributions.
- The diagnostic lens suggests that future model releases should report calibration error and cue sensitivity alongside task success rates.
Load-bearing premise
The chosen simulator policy and payoff structure for bilateral price negotiation accurately reflect the strategic and informational features that matter in real negotiations.
What would settle it
Running the same negotiation protocol with human participants and observing whether their patterns of surplus extraction, cue use, and belief updates match or diverge from the LLM distributions would test whether the benchmark's agent-attributable gaps are real or artifacts of the simulator.
Figures





















read the original abstract
Negotiation is a central mechanism of economic exchange, shaping markets, procurement, labor agreements, and resource allocation. It is also a canonical testbed for agentic language models, requiring multi-turn interaction under hidden preferences, strategic communication, and binding constraints. These properties make negotiation hard to evaluate: unlike math or code, it has no intrinsic verifier. Existing LLM negotiation evaluations rely on LLM-vs.-LLM interaction or aggregate outcomes such as deal rate, leaving failures opaque. We introduce Terms-Bench, short for Testbed for Economic Reasoning in Multi-turn Strategy, a Bayesian-game framework that makes the environment itself the verifier by specifying the counterpart's latent type, policy, and payoff structure. We instantiate it in bilateral price negotiation, where the counterpart's private state and simulator policy are hidden from the agent but observable to the evaluator. This turns the counterpart from a black-box opponent into a diagnostic instrument, enabling agent-attributable failure analysis and oracle-reference optimality gaps. Evaluating 13 LLM agents spanning frontier systems from major providers, Terms-Bench turns negotiation evaluation from aggregate ranking into actionable diagnosis: where agents fail, why they fail, and what to strengthen. Empirically, frontier models saturate deal rate yet diverge in surplus extraction, cue use, belief calibration, and compliance, revealing agent-specific bargaining bottlenecks masked by prior benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Terms-Bench, a Bayesian-game testbed for LLM negotiation agents instantiated in bilateral price negotiation. By making the counterpart's latent type, policy, and payoff structure observable to the evaluator while hidden from the agent, it converts aggregate deal-rate metrics into diagnostics of surplus extraction, cue use, belief calibration, and compliance. Evaluation of 13 frontier and open-source LLMs shows saturation on deal rate but substantial divergence on the four diagnostic dimensions, which the authors attribute to agent-specific bargaining limitations.
Significance. If the simulator policy accurately captures relevant strategic and informational features of real negotiations, the framework offers a verifiable, agent-attributable alternative to opaque LLM-vs-LLM benchmarks and could guide targeted improvements in multi-turn strategic reasoning. The explicit use of an oracle-reference optimality gap is a methodological strength.
major comments (2)
- [§3] §3 (Framework definition): The simulator policy and payoff structure are load-bearing for the central claim that divergences are agent-attributable rather than environment-driven, yet no derivation from equilibrium concepts, human data, or validation of cue-generation and belief-update rules is provided; without this grounding, measured gaps on surplus extraction and belief calibration cannot be confidently attributed to the LLMs.
- [§4.3] §4.3 (Empirical results): The reported divergences across the 13 agents on surplus, cue use, and compliance lack statistical significance tests, confidence intervals, or controls for simulator stochasticity, so it is unclear whether the observed agent-specific bottlenecks are robust or could arise from environment variance.
minor comments (2)
- [§3.2] Notation for the Bayesian type space and belief updates could be clarified with an explicit table of symbols to aid reproducibility.
- [Abstract] The abstract and introduction would benefit from a one-sentence statement of the precise payoff structure used in the bilateral negotiation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address each major comment below and will make the corresponding changes to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Framework definition): The simulator policy and payoff structure are load-bearing for the central claim that divergences are agent-attributable rather than environment-driven, yet no derivation from equilibrium concepts, human data, or validation of cue-generation and belief-update rules is provided; without this grounding, measured gaps on surplus extraction and belief calibration cannot be confidently attributed to the LLMs.
Authors: We agree that the simulator policy is central to attributing divergences to the agents rather than the environment. The manuscript defines the policy via type-dependent reservation prices and myopic belief updates drawn from standard bilateral bargaining models, but does not include a formal derivation or validation. In revision we will add a dedicated subsection deriving the policy from Bayesian-game equilibrium concepts, include sensitivity checks across alternative cue-generation rules, and report results under perturbed simulator parameters to confirm attribution. revision: yes
-
Referee: [§4.3] §4.3 (Empirical results): The reported divergences across the 13 agents on surplus, cue use, and compliance lack statistical significance tests, confidence intervals, or controls for simulator stochasticity, so it is unclear whether the observed agent-specific bottlenecks are robust or could arise from environment variance.
Authors: We acknowledge the lack of statistical tests and controls for stochasticity in the reported results. Although metrics were averaged over repeated runs, no confidence intervals or significance tests were provided. In the revised version we will add bootstrap confidence intervals for all four diagnostic metrics, conduct paired statistical tests across agents while averaging over 200 simulator seeds, and include variance decomposition to isolate agent effects from environment noise. revision: yes
Circularity Check
No significant circularity; benchmark definitions and metrics are independent of fitted inputs or self-citation chains.
full rationale
The paper introduces Terms-Bench as a Bayesian-game framework for bilateral price negotiation, specifying counterpart latent type, policy, and payoff structure to enable diagnostic evaluation. No equations, fitted parameters, or self-citations are presented in the abstract or described derivation that reduce reported metrics (deal rate, surplus extraction, cue use, belief calibration, compliance) to quantities defined by the authors' own prior work. The central claim—that frontier models saturate deal rate but diverge on agent-specific diagnostics—rests on empirical evaluation within the explicitly constructed simulator, which is presented as a novel verifier rather than a tautological restatement of inputs. This satisfies the default expectation of a self-contained benchmark paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The negotiation environment can be faithfully modeled as a Bayesian game in which the evaluator observes the counterpart's latent type and policy while the agent does not.
invented entities (1)
-
Terms-Bench testbed
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TERMS-BENCH ... Bayesian-game framework ... counterpart’s latent type, policy, and payoff structure ... surplus efficiency SE+π ... belief error BEtype
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
surplus extraction, cue use, belief calibration, and compliance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The agent choosesAccept; the outcome is the counterpart’s last offered price
-
[2]
The agent choosesReject; the outcome is disagreement⊥
-
[3]
The counterpart accepts the agent’s offer; the outcome is the agent’s proposed price
-
[4]
The counterpart terminally rejects (walk-away); the outcome is disagreement⊥
-
[5]
The round limitKis reached without agreement; the outcome is disagreement⊥. Constraints.All Offer actions must satisfy: (i) price bounds pmin ≤p k ≤p max; (ii) monotonic concession: for buyer agents, pk ≥p k−1 where k, k−1 index the agent’s own offers; for seller agents,pk ≤p k−1; (iii) turn budget k≤K . Violations of (i) or of individual rationality (acc...
work page 2025
-
[6]
This family replaces the earlier Truthful family
Candid counterparts[type-instrumental economics, accurate cues]. This family replaces the earlier Truthful family. The counterpart’s economic behavior is low-noise and strongly type-conditioned: reservation value sets the feasible boundary, urgency changes acceptance and concession timing, and stance changes the payoff consequences of rigidity and concess...
-
[7]
Taciturn counterparts[type-instrumental economics, uninformative cues]. Economic behavior follows the same type-instrumental preset as Candid, but the cue channel is collapsed to neutral, noncommittal states. This isolates inference from economic behavior alone: an agent that degrades relative to Candid is relying heavily on linguistic or stylistic cues
-
[8]
The cue channel remains accurate, but economic behavior is more strongly history-reactive
Expressive counterparts[high-reactivity economics, accurate cues]. The cue channel remains accurate, but economic behavior is more strongly history-reactive. Counter-offers and acceptance probabilities respond more to the agent’s recent concession pattern and rigidity. This family tests whether agents can use reliable cues while avoiding confusion between...
-
[9]
Economic behavior is strongly history-reactive, and the cue channel is uninformative
Strategic counterparts[high-reactivity economics, uninformative cues]. Economic behavior is strongly history-reactive, and the cue channel is uninformative. The counterpart is linguistically guarded while adapting tactically through price and acceptance behavior. This is the hardest core family for opponent modeling because both the economic and language ...
-
[10]
This family is an explicit stress test rather than part of the core factorial
Adversarial counterparts[hardball economics, pressuring cues]. This family is an explicit stress test rather than part of the core factorial. The stance prior is skewed toward aggressive counterparts, economic reactivity is high, concessionary behavior is strongly exploited, and rigidity is punished for aggressive types. The cue channel is biased toward n...
-
[11]
Stochastic counterparts[moderate-reactivity economics, noisy/weak cues]. This family degrades both the price and cue channels through noise rather than through deliberate strategic concealment. Economic behavior uses a moderate reactivity preset, but price noise is high, so offer trajectories are less diagnostic of the underlying concession rule. The cue ...
-
[12]
Opener role χ∈ {AgentOpens,CounterpartOpens} , assigned at episode start and constant across rounds
-
[13]
History-reactive features ϕk := (ConcedeSpeed k,Rigidity k,ConcedeMagnitude k), which are deterministic functions of the agent’s past offer sequence (Appendix C.3) and parameterize the counter- part’s acceptance probability, walk-away hazard, and concession rate
-
[14]
Offer-history summary hB k := (p B k , p B k−1), which records the counterpart’s current and previous offers. These are needed to evaluate acceptance utility uA(pB k ), to compute the price-likelihood mean (28), to derive the counterpart’s concession magnitudeC B k used in the strategic-cue model, and to specify the role-dependent monotone feasible interv...
-
[15]
Projection onto BB = [a0, b0] produces a mixed distribution with point masses at the two endpoints: fopen(pB 1 |t B, d0,e) = Φ a0 −µ 0(tB, d0,e) σ0 , p B 1 =a 0, 1 σ0 ϕ pB 1 −µ 0(tB, d0,e) σ0 , a 0 < p B 1 < b0, 1−Φ b0 −µ 0(tB, d0,e) σ0 , p B 1 =b 0, (39) with (a0, b0) = (rB, pmax) for a seller counterpart and (pmin, rB) for a buyer. I...
-
[16]
Base agent.The evaluated LLM observes the standard benchmark interface and must infer tB from prices, actions, and messages
-
[17]
This removes posterior-formation error while preserving uncertainty overt B
Oracle-posterior agent.The evaluated LLM observes the standard interface plus zpost k at each round. This removes posterior-formation error while preserving uncertainty overt B
-
[18]
This removes both posterior-formation error and residual latent-state uncertainty
Revealed-type agent.The evaluated LLM is given the true latent type tB directly. This removes both posterior-formation error and residual latent-state uncertainty
-
[19]
Model-based oracle.The dynamic-programming policy π⋆ acts from the oracle belief state and the known simulator model. This removes LLM planning, execution, and prompt-following errors. These conditions form an intervention ladder. Moving from the base agent to the oracle-posterior agent tests whether correcting the agent’s posterior improves utility. Movi...
work page 2026
-
[20]
Near-universal seller advantage on closing surplus.12 of 13 LLMs extract more closing surplus as seller than as buyer (median ∆σπ = +0.037 ; sign-test p= 0.0017 , exact paired Wilcoxon p= 0.0061 ); GPT-4o-mini is the lone exception, with ∆σπ =−0.063 . Among the 12 positive agents the magnitudes are highly model-dependent, from +0.014 (Grok 4.20 ) to +0.13...
-
[21]
Compensating agreement-rate dip.In the opposite direction, sellers close fewer deals: median ∆AGR+ π =−0.010 , with 0/13 models showing seller > buyer (paired Wilcoxon p= 0.0005 ). The dip is most pronounced for the strongest anchor-and-hold agents— GLM 5.1 reaches feasible AGR+ π = 1.000 as buyer but 0.902 as seller, and Claude Opus 4.7 drops from 0.998 ...
-
[22]
Net effect on SE + π remains positive for 12 of 13.The seller-side σπ gain dominates the agreement- rate drop in SE + π terms for the same 12 of 13 agents (median ∆SE + π = +0.032, paired Wilcoxon p= 0.0100 ); the lone exception is GPT-4o-mini (−0.065). Among the 12 agents that do show a seller advantage, the heterogeneity in magnitude tracks opening-pric...
-
[23]
I believe 88 is a fair starting point
The typology is preserved across role.Despite the universal σπ asymmetry, no agent crosses a typology boundary by role: every agent’s qualitative profile (anchor-and-hold, mid/balanced, anchor- 64 Claude Opus 4.6Claude Opus 4.7Gemini 3.1 ProGemma 4 31B GLM 5.1 DeepSeek-V4-Pro Grok 4.20Kimi K2.6 Qwen 3.6 Plus GPT-5.4GPT-5.5 Doubao 2.0 Pro 0.0 0.1 0.2 0.3 0...
work page 2000
-
[24]
Open inside the public price range and at least 20% away from your r e s e r v a t i o n price toward your f a v o r a b l e extreme
-
[25]
Concede in small , d e c r e a s i n g i n c r e m e n t s -- never more than 30% of the di st an ce to the counterpart ’ s most recent offer
-
[26]
If the counterpart ’ s price has not crossed your r e s e r v a t i o n by round K -1 , prefer Reject over a negative - utility Accept . 72 Listing 2: Final GEPA-optimisedstrategy_patch. SYSTEM I N S T R U C T I O N S FOR TERMS - Bench B I L A T E R A L N E G O T I A T I O N AGENT = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = =...
-
[27]
I n d i v i d u a l R a t i o n a l i t y ( IR ) : Never Accept a price worse than r e s e r v a t i o n
-
[28]
Bounds : Every Offer must be within [ p_min , p_max ]
-
[29]
M o n o t o n i c i t y : S u c c e s s i v e offers must move toward the c o u n t e r p a r t ( buyer non - decreasing , seller non - i n c r e a s i n g )
-
[30]
Budget : Never exceed r e s e r v a t i o n in an offer you ’ d accept
-
[31]
ST RA TE GY G UI DA NC E = = = = = = = = = = = = = = = = = ### Opening ( when you open first )
Valid Actions : Always output exactly one of Offer X / Accept / Reject . ST RA TE GY G UI DA NC E = = = = = = = = = = = = = = = = = ### Opening ( when you open first )
-
[32]
Start at a p p r o x i m a t e l y 20 -30% of the range from your f a v o r a b l e extreme
Open a g g r e s s i v e l y but within [ p_min , p_max ]. Start at a p p r o x i m a t e l y 20 -30% of the range from your f a v o r a b l e extreme . - BUYER : ~ p_min + 0.2 * ( p_max - p_min ) . - SELLER : ~ p_max - 0.2 * ( p_max - p_min )
-
[33]
### R e s p o n d i n g to the counterpart ’ s first offer
If r e s e r v a t i o n is extreme ( very high as buyer / very low as seller ) , open further from r e s e r v a t i o n to m ax imi se p o t e n t i a l utility . ### R e s p o n d i n g to the counterpart ’ s first offer
-
[34]
Accept i m m e d i a t e l y if the offer already gives you very good utility ( >50% of max ) . This avoids wa lk aw ay risk
-
[35]
### C o n c e s s i o n pattern
Counter - offer if utility is < ~35 -40% of max OR you believe you can extract more given r e m a i n i n g rounds . ### C o n c e s s i o n pattern
-
[36]
Never concede more than 30% of the di st anc e between your last offer and the counterpart ’ s
Concede in small , d e c r e a s i n g i n c r e m e n t s . Never concede more than 30% of the di st anc e between your last offer and the counterpart ’ s
-
[37]
In later rounds , make token c o n c e s s i o n s (0.5 -2% of range ) to signal f ir mn ess
Slow c o n c e s s i o n s as you ap pr oa ch r e s e r v a t i o n . In later rounds , make token c o n c e s s i o n s (0.5 -2% of range ) to signal f ir mn ess
- [38]
-
[39]
At round K -1 / K , if the c o u n t e r p a r t has not crossed your reservation , Reject rather than accept a negative - utility deal
-
[40]
Re pe at ed offers at r e s e r v a t i o n signal your limit
At your reservation , hold firm . Re pe at ed offers at r e s e r v a t i o n signal your limit
-
[41]
### D e t e c t i n g no - deal s c e n a r i o s
If the c o u n t e r p a r t is barely moving and offers do not con ve rg e to a f eas ib le zone , prepare for no a g r e e m e n t ; c o r r e c t l y i d e n t i f y i n g a no - deal s ce na ri o scores 1.0. ### D e t e c t i n g no - deal s c e n a r i o s
-
[42]
If c o u n t e r p a r t offers stay far from your r e s e r v a t i o n with minimal movement , the s cen ar io likely has no ZOPA . Co nt in ue n e g o t i a t i n g n orm al ly ; Reject c o n f i d e n t l y if their final offer is u n a c c e p t a b l e . ### A c c e p t i n g
-
[43]
Accept when the offer gives p os it iv e utility AND further n e g o t i a t i o n is u nl ik el y to yield m e a n i n g f u l l y better results
-
[44]
Be more willing to accept early at high utility ( >60% of max ) -- this locks in gains and avoids wa lk awa y risk
-
[45]
Be ca ut iou s about a c c e p t i n g too quickly at m ed io cr e utility ( <40%) -- 73 you may leave s i g n i f i c a n t value on the table . ### Message st ra te gy
-
[46]
Keep m es sa ges concise , professional , s t r a t e g i c : - R e f e r e n c e market comps , budget constraints , demand , a l t e r n a t i v e s . - Ask about their c o n s t r a i n t s to gather i n f o r m a t i o n . - Signal urgency / w i l l i n g n e s s to close when c o n c e d i n g . - Late rounds : signal fir mn es s (" near my limit " ,...
-
[47]
Your opening offer matters e n o r m o u s l y ; many n e g o t i a t i o n s co nc lu de in 1 -2 rounds . Open too close to mid po in t -> i m m e d i a t e accept at m edi oc re score ; open too a g g r e s s i v e l y -> wa lk aw ay risk . - When the c o u n t e r p a r t opens f a v o r a b l y ( below r e s e r v a t i o n as buyer , above as seller ...
-
[48]
avg, low, and high are historical market statistics drawn from the AmazonHistoryPrice corpus (Appendix H.2.1). They calibrate the plausible valuation scale for the item and serve as a public prior for both buyer and seller
-
[49]
The counterpart’s true reservation valuerB, urgencyκ B, and stanceη B remain private and unobserved
-
[50]
The agent’s ownreservation_price is sampled from a role-conditioned wedge around the product reference price (see §H.2.1) and is delivered through the same private_context channel as in synthetic runs. Constraints introduced by the block The category-level public price bounds [pmin, pmax] in constraints.price_bounds are derived from the product category r...
-
[51]
Never change the actiond k ∈ {OFFER,ACCEPT,REJECT}or the pricep k
-
[52]
Never introduce new numbers, constraints, deadlines, or factual claims
-
[53]
Never reveal hidden information (reservation values, urgency, stance, internal policy)
-
[54]
Never reference internal variables (types, simulator, cues,κ,η)
-
[55]
Shape tone usingsentiment(positive, neutral, negative) andstrategy_cue(Concede, Hold, Pressure)
-
[56]
Keep the message realistic and concise (1–3 sentences)
-
[57]
Ifis_opening_turn = No, briefly respond to the agent’s last message in a way consistent with the cues; ifYes, initiate naturally. Action-specific requirements: Offer→ state the provided price string verbatim with no rounding or paraphrase; Accept→ confirm agreement and make clear that the negotiation has concluded with a deal;Reject→firmly close the negot...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.