Contrastive Regularization of Machine Learning Potentials
Pith reviewed 2026-07-01 02:59 UTC · model grok-4.3
The pith
Machine learning potentials trained only on pointwise errors produce wrong thermodynamic distributions even when energies are chemically accurate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
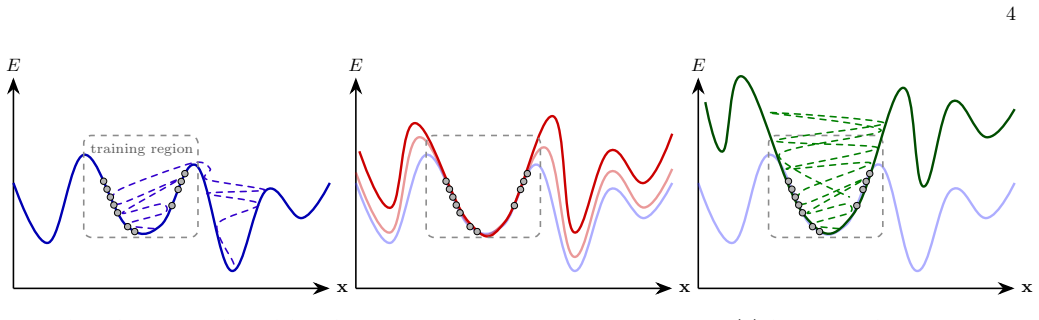
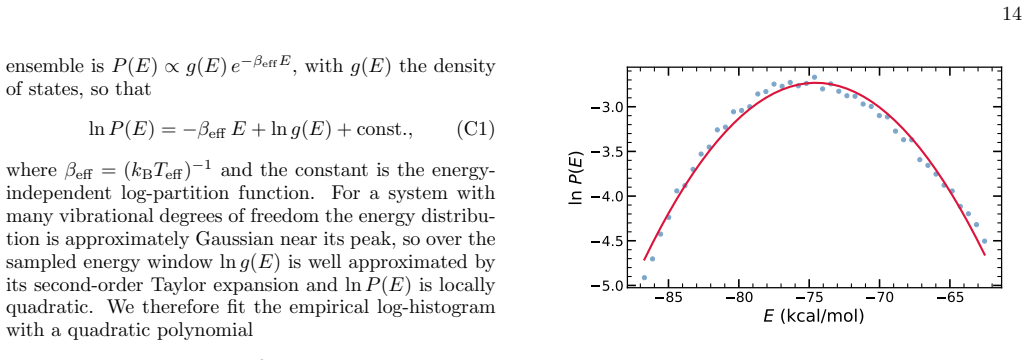
Potentials trained by MSE minimization on DFT data reach chemical accuracy on test points yet fail as samplers because their generated Boltzmann distribution differs from the target; augmenting the loss with a contrastive term derived from the Kullback-Leibler divergence, obtained by running persistent Langevin chains that expose the network's own spurious low-energy minima, confines trajectories to the physical basin and recovers the energy distribution, interatomic-distance distributions, and dihedral free-energy profiles to near-quantitative agreement with DFT while preserving force accuracy and remaining effective under reduced training data.
What carries the argument
Contrastive Regularized MSE (CRMSE), which augments pointwise MSE with a contrastive penalty from the KL divergence between the potential's implicit distribution and the target, using the trained network itself as an energy-based model whose persistent Langevin chains supply the negative samples.
If this is right
- Trajectories stay confined to physical basins rather than drifting into unphysical minima.
- Energy distributions, interatomic-distance histograms, and dihedral free-energy profiles match DFT to near-quantitative accuracy.
- Force accuracy on physical configurations is preserved and energy errors remain within chemical accuracy.
- The correction works even when the original training set is sharply reduced.
- Distribution-level matching is a distinct requirement separate from pointwise regression accuracy.
Where Pith is reading between the lines
- The same contrastive approach could be tested on other learned potentials used as generators in simulations beyond molecular systems.
- Benchmarks for ML potentials may need to add explicit sampling-quality tests in addition to pointwise error metrics.
- Self-generated negative samples via dynamics could reduce the required volume of expensive ab initio data for reliable models.
- The method implies that training objectives should be chosen to match the downstream use case of equilibrium sampling rather than isolated prediction accuracy.
Load-bearing premise
Persistent Langevin chains started from the trained potential will reliably expose the spurious low-energy minima responsible for sampling failure.
What would settle it
Apply CRMSE to another MD17 molecule or dataset and measure whether the resulting dihedral free-energy profiles still deviate from the DFT reference by more than chemical accuracy thresholds.
Figures







read the original abstract
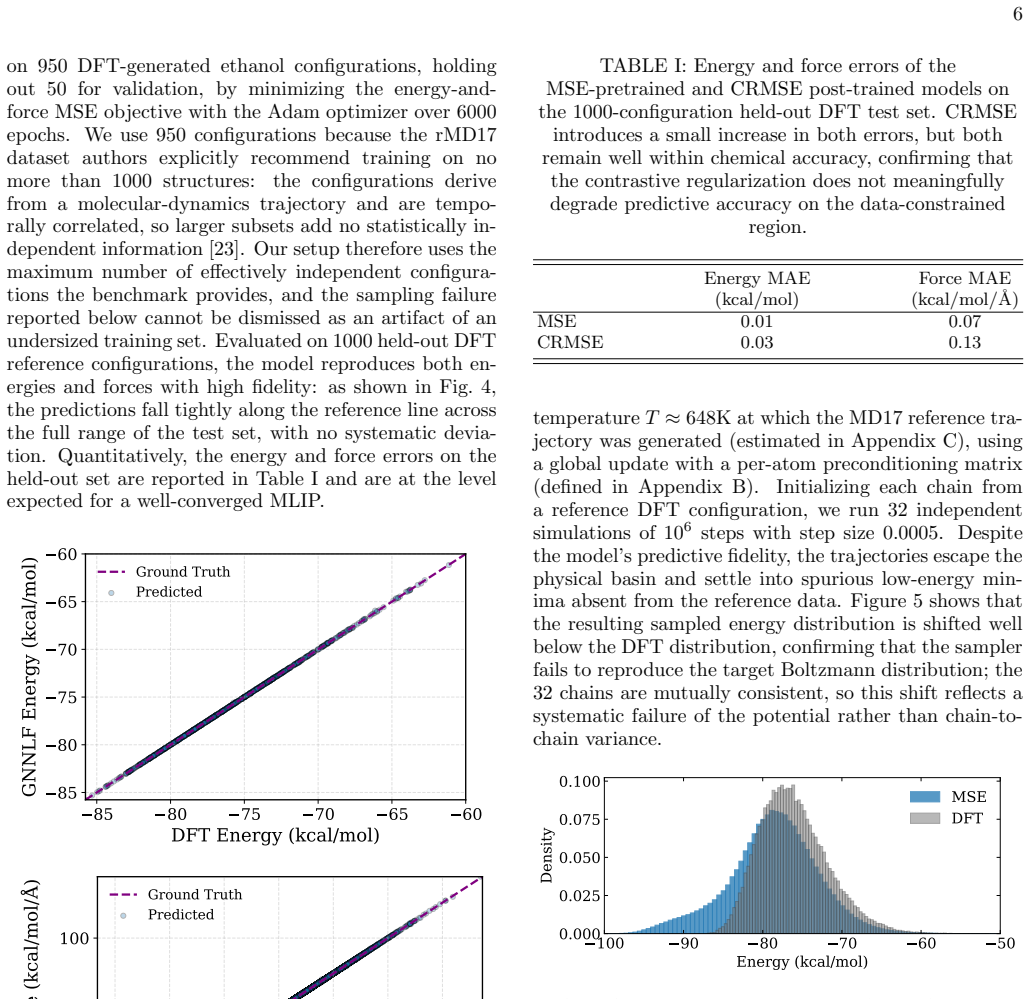
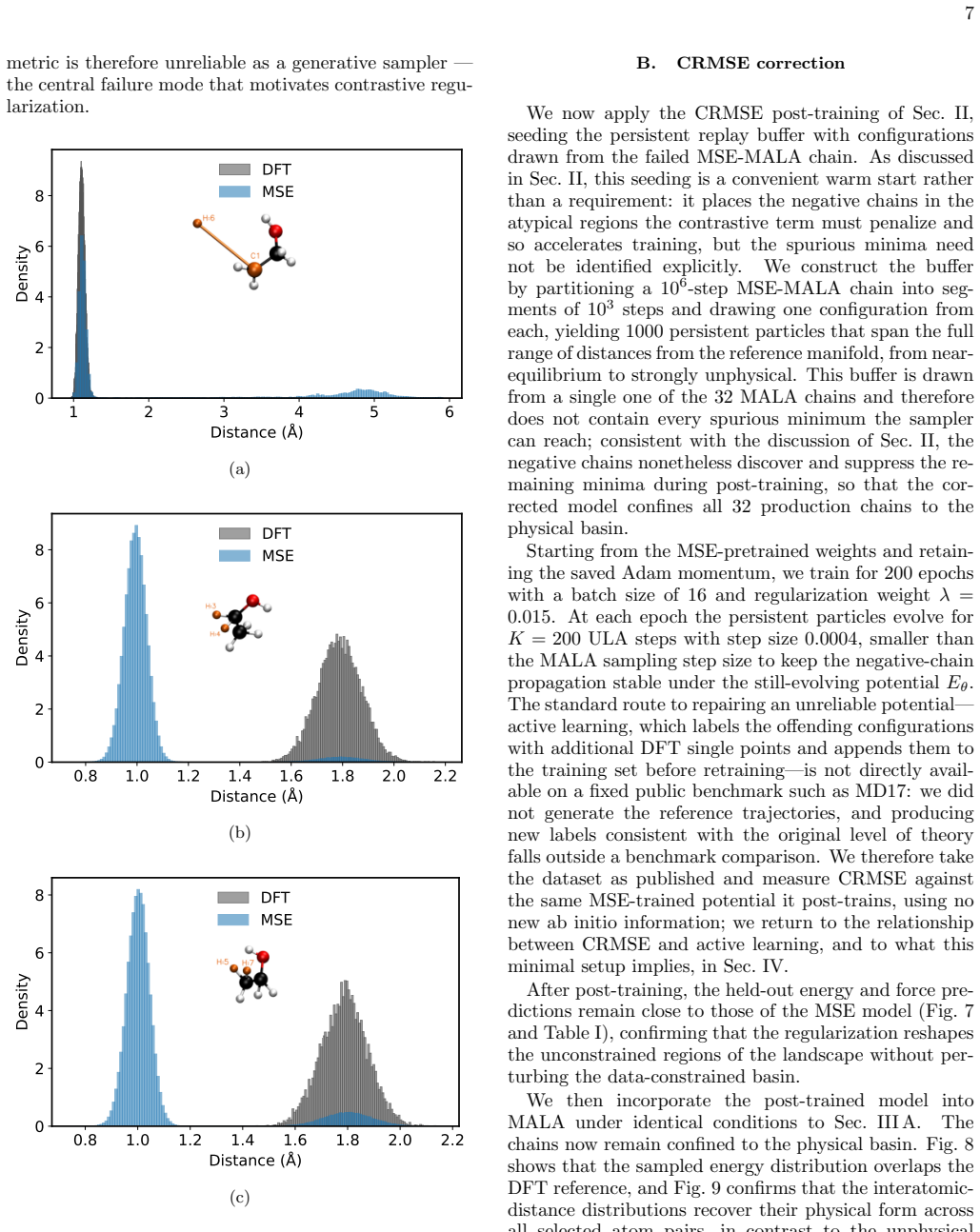
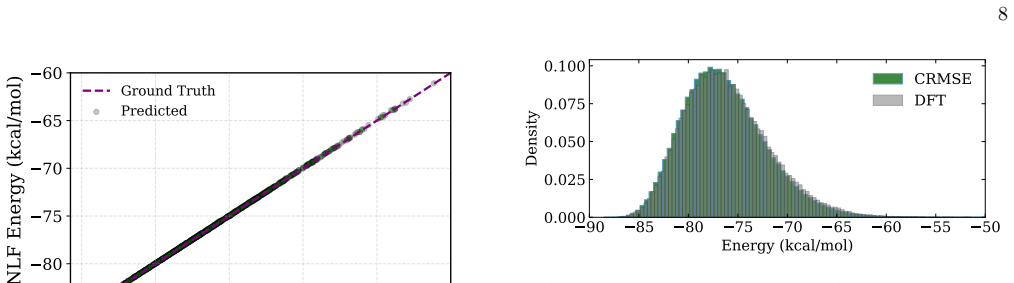
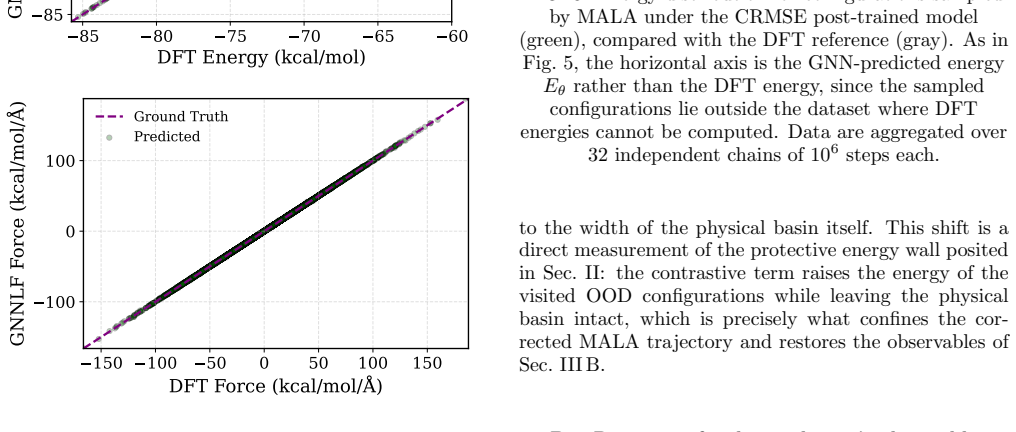
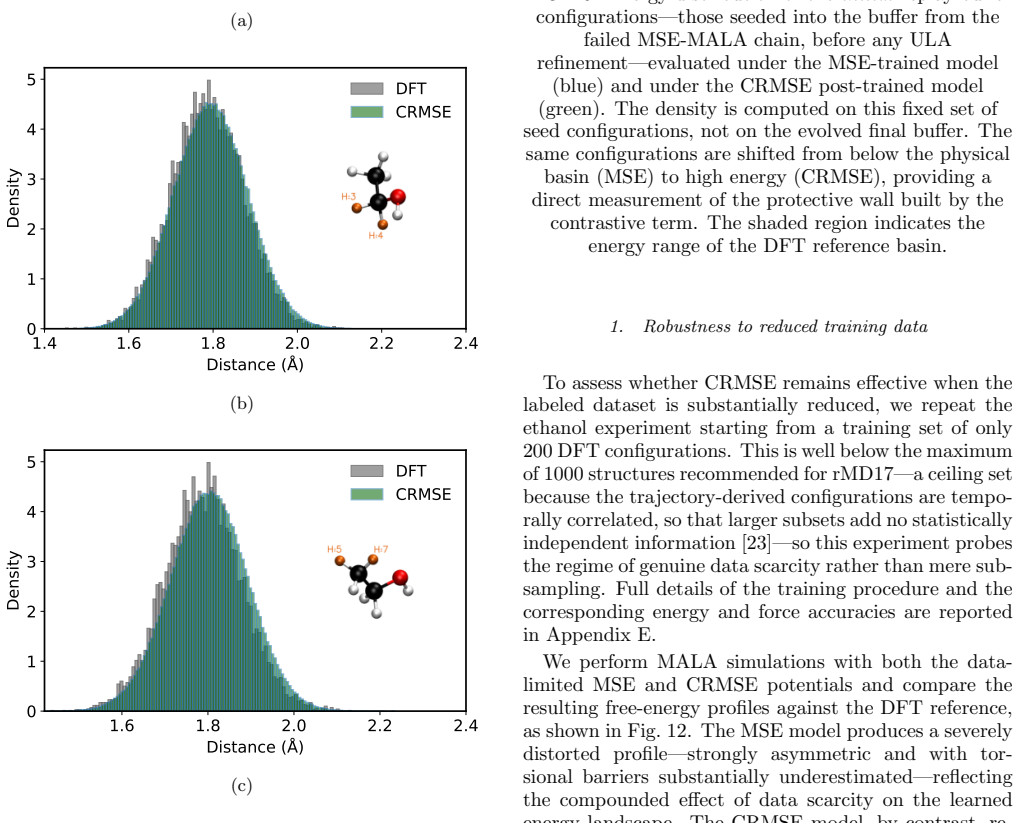
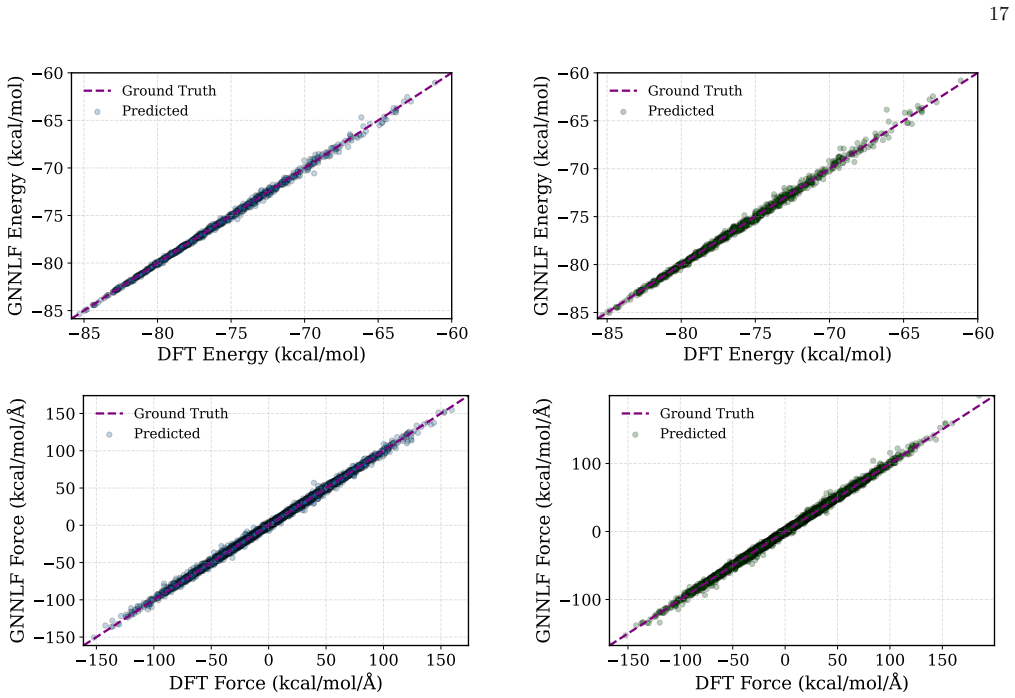
Machine learning interatomic potentials are trained to predict energies and forces but built to be sampled: their purpose is to drive molecular simulations whose observables average over the equilibrium distribution the potential defines. They exemplify a broader AI problem -- learned regressors deployed as generators -- where pointwise accuracy does not guarantee a correct distribution. We show that potentials trained by standard Mean Squared Error (MSE) minimization on Density Functional Theory (DFT) data can reach chemical accuracy on held-out data, yet still fail as samplers: their trajectories drift into spurious low-energy minima and return thermodynamic observables that depart sharply from the reference. To correct this, we introduce Contrastive Regularized MSE (CRMSE), a post-training step that augments the MSE with a contrastive term derived from the Kullback--Leibler divergence between the potential's implicit Boltzmann distribution and the target. The network serves as its own energy-based model: persistent Langevin chains expose the configurations it drifts into and raise their energy, adding no new ab initio data. On the ethanol and aspirin molecules of the MD17 dataset, CRMSE confines the sampler to the physical basin and recovers the energy distribution, interatomic-distance distributions, and dihedral free-energy profiles to near-quantitative agreement with DFT, while preserving force accuracy and keeping energy errors within chemical accuracy; it remains effective when the training set is sharply reduced. That MSE training fails this way on MD17 -- one of the most widely used benchmarks -- while a minimal contrastive correction repairs it suggests that reliable sampling depends less on data volume than on training the model against the distribution it produces: distribution-level training is not a refinement of regression accuracy, but a distinct requirement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
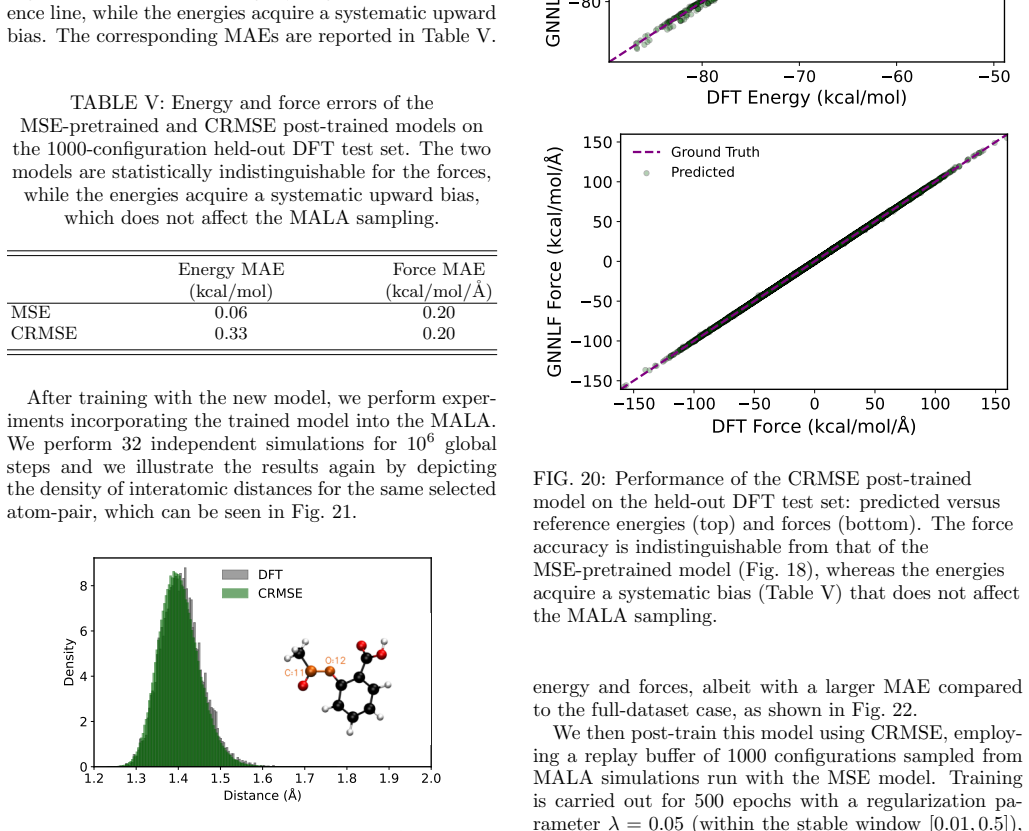
Summary. The paper claims that ML interatomic potentials trained by MSE on MD17 DFT data (ethanol, aspirin) reach chemical accuracy on held-out points yet fail as samplers, drifting into spurious low-energy minima and producing incorrect thermodynamic observables. It introduces CRMSE, a post-training step that augments MSE with a contrastive term derived from the KL divergence between the model's implicit Boltzmann distribution and the target DFT distribution; the network acts as its own energy-based model, with persistent Langevin chains generating negative samples whose energies are raised. On the cited molecules, CRMSE is reported to confine sampling to the physical basin, recover energy, interatomic-distance, and dihedral free-energy distributions to near-quantitative DFT agreement, preserve force accuracy within chemical error, and remain effective under reduced training sets.
Significance. If the central result holds, the work is significant because it isolates a concrete failure mode of pointwise regression when the model is used generatively and demonstrates that a minimal, data-free contrastive correction can restore distribution-level fidelity on a standard benchmark. The approach of self-generated negative samples via persistent dynamics is economical and directly targets the sampling pathology without requiring additional ab initio calculations. It underscores that reliable thermodynamic sampling imposes requirements distinct from regression accuracy, with potential implications for other learned energy-based models.
major comments (2)
- [Abstract / CRMSE description] Abstract and method description: the claim that persistent Langevin chains 'expose the configurations it drifts into' is load-bearing, yet no diagnostic is supplied showing that the generated configurations lie outside the DFT-supported physical basin, populate the spurious minima responsible for MSE sampling collapse, or differ systematically from training-data neighborhoods. Without such verification (e.g., overlap metrics or energy histograms of negative samples versus DFT), the observed recovery of distributions cannot be unambiguously attributed to the contrastive term rather than incidental effects.
- [Abstract] Abstract: quantitative recovery of energy, distance, and dihedral distributions is asserted without reported error bars, multiple independent chain runs, or robustness checks against contrastive strength, Langevin step size, or chain length. The absence of these controls leaves open whether the near-quantitative agreement is stable or sensitive to hyperparameter choices, undermining the claim that CRMSE 'remains effective when the training set is sharply reduced.'
minor comments (1)
- The notation and explicit functional form of the contrastive term (derived from KL) would benefit from an equation in the main text to clarify how the negative-sample energies enter the loss.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / CRMSE description] Abstract and method description: the claim that persistent Langevin chains 'expose the configurations it drifts into' is load-bearing, yet no diagnostic is supplied showing that the generated configurations lie outside the DFT-supported physical basin, populate the spurious minima responsible for MSE sampling collapse, or differ systematically from training-data neighborhoods. Without such verification (e.g., overlap metrics or energy histograms of negative samples versus DFT), the observed recovery of distributions cannot be unambiguously attributed to the contrastive term rather than incidental effects.
Authors: We agree that explicit verification of the negative samples would strengthen the attribution. In the revised manuscript we will add energy histograms of configurations sampled from the persistent Langevin chains versus the DFT reference, together with overlap metrics (e.g., Wasserstein distance on energies and RMSD distributions) relative to both the training set and the physical basin. These diagnostics will be shown for both ethanol and aspirin to confirm that the contrastive term targets the spurious minima responsible for sampling collapse. revision: yes
-
Referee: [Abstract] Abstract: quantitative recovery of energy, distance, and dihedral distributions is asserted without reported error bars, multiple independent chain runs, or robustness checks against contrastive strength, Langevin step size, or chain length. The absence of these controls leaves open whether the near-quantitative agreement is stable or sensitive to hyperparameter choices, undermining the claim that CRMSE 'remains effective when the training set is sharply reduced.'
Authors: We acknowledge the lack of statistical controls and robustness tests in the current version. The revised manuscript will report results from multiple independent Langevin chains with error bars (standard deviation across runs) on all distribution metrics. We will also add sensitivity plots varying contrastive weight, Langevin step size, and chain length, and will repeat the reduced-training-set experiments under these controls to demonstrate that the recovery remains stable and effective. revision: yes
Circularity Check
No significant circularity; contrastive term from external KL and standard self-sampling technique
full rationale
The paper derives the contrastive regularization from the Kullback-Leibler divergence between the model's implicit Boltzmann distribution and the target DFT distribution, an external statistical principle applied post-training. Persistent Langevin chains on the network generate negative samples to raise energies of drifted configurations; this is a standard energy-based modeling approach and does not reduce the reported recovery of energy/distance/dihedral distributions to a fitted input or self-definition by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation. The central claim remains independently testable against MD17 DFT benchmarks and does not collapse to renaming or statistical forcing of the input MSE fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive regularization strength
axioms (1)
- domain assumption The trained network can serve as its own energy-based model whose Boltzmann distribution can be sampled via persistent Langevin dynamics
Reference graph
Works this paper leans on
-
[1]
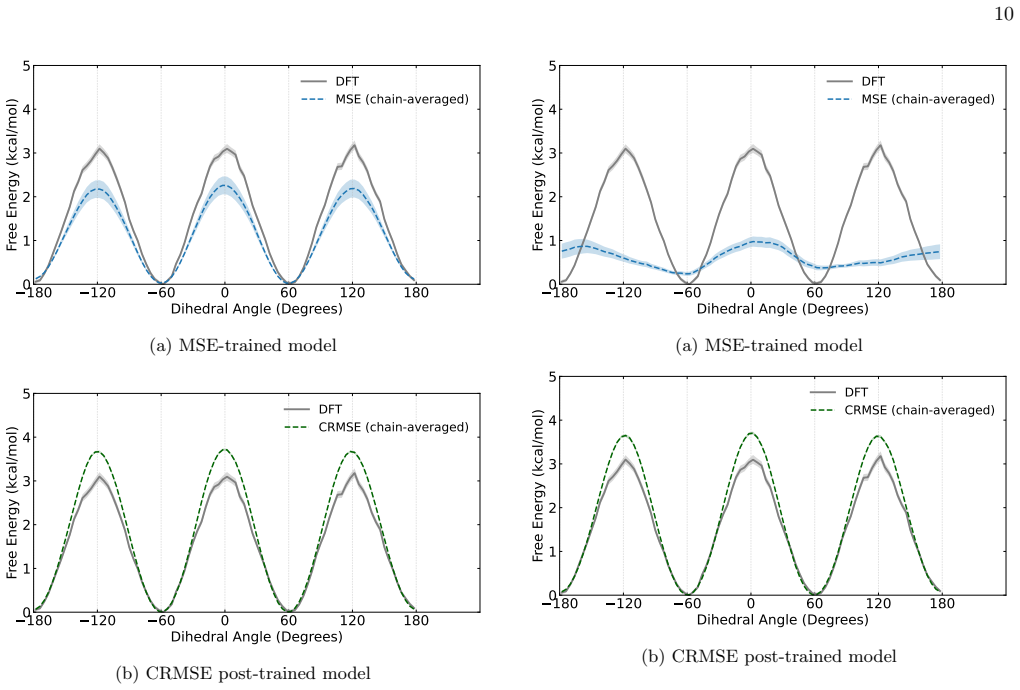
Robustness to reduced training data To assess whether CRMSE remains effective when the labeled dataset is substantially reduced, we repeat the ethanol experiment starting from a training set of only 200 DFT configurations. This is well below the maximum of 1000 structures recommended for rMD17—a ceiling set because the trajectory-derived configurations ar...
-
[2]
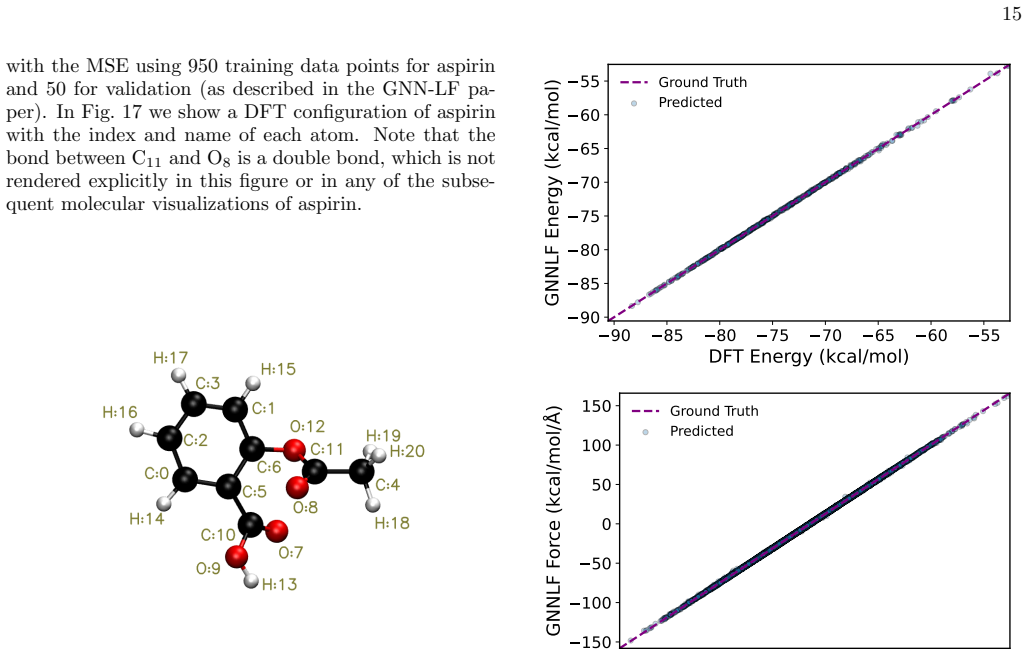
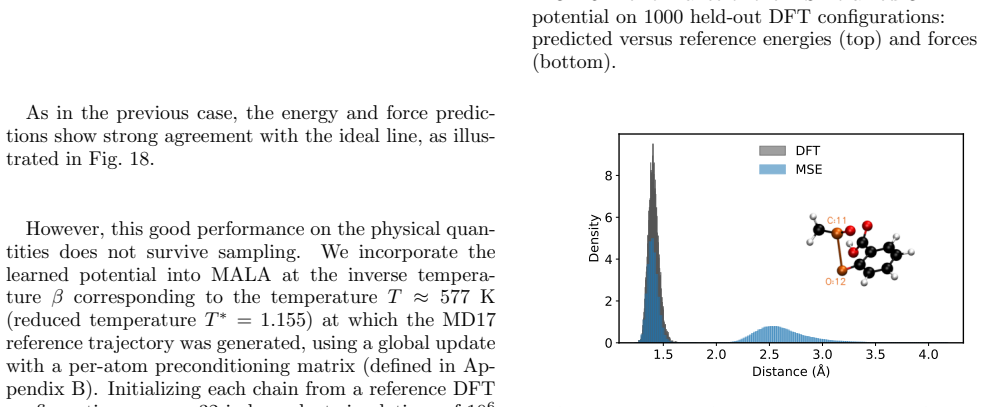
Generalization to aspirin Having established the validity of CRMSE on ethanol, we now examine whether the same correction generalises to a more complex molecule. As for ethanol, the surro- gate is trained on 950 aspirin configurations—the maxi- mum recommended for rMD17, whose trajectory-derived structures are temporally correlated so that larger sub- set...
-
[3]
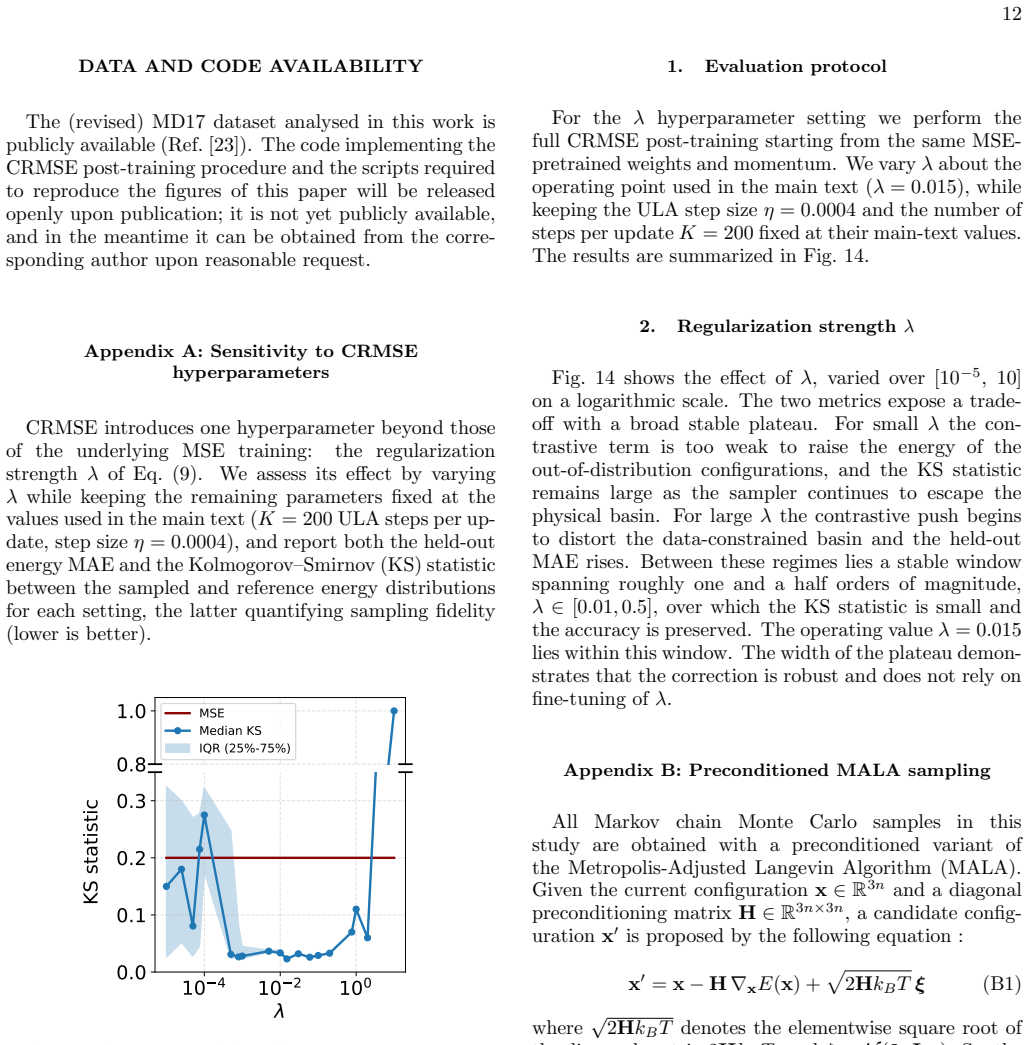
Evaluation protocol For theλhyperparameter setting we perform the full CRMSE post-training starting from the same MSE- pretrained weights and momentum. We varyλabout the operating point used in the main text (λ= 0.015), while keeping the ULA step sizeη= 0.0004 and the number of steps per updateK= 200 fixed at their main-text values. The results are summar...
-
[4]
14 shows the effect ofλ, varied over [10 −5, 10] on a logarithmic scale
Regularization strengthλ Fig. 14 shows the effect ofλ, varied over [10 −5, 10] on a logarithmic scale. The two metrics expose a trade- off with a broad stable plateau. For smallλthe con- trastive term is too weak to raise the energy of the out-of-distribution configurations, and the KS statistic remains large as the sampler continues to escape the physica...
-
[5]
Hohenberg and W
P. Hohenberg and W. Kohn, Phys. Rev.136, B864 (1964)
1964
-
[6]
Kohn and L
W. Kohn and L. J. Sham, Phys. Rev.140, A1133 (1965)
1965
-
[7]
Behler and M
J. Behler and M. Parrinello, Phys. Rev. Lett.98, 146401 (2007)
2007
-
[8]
K. T. Sch¨ utt, H. E. Sauceda, P.-J. Kindermans, A. Tkatchenko, and K.-R. M¨ uller, The Journal of Chem- ical Physics148, 241722 (2018)
2018
-
[9]
G. Wang, C. Wang, X. Zhang, Z. Li, J. Zhou, and Z. Sun, iScience27, 109673 (2024)
2024
-
[10]
Wang and M
X. Wang and M. Zhang, inProceedings of the First Learning on Graphs Conference, Proceedings of Machine Learning Research, Vol. 198, edited by B. Rieck and R. Pascanu (PMLR, 2022) pp. 19:1–19:30
2022
-
[11]
Ocampo, D
D. Ocampo, D. Posso, R. Namakian, and W. Gao, Com- putational Materials Science244, 113155 (2024)
2024
-
[12]
O. T. Unke, S. Chmiela, H. E. Sauceda, M. Gastegger, I. Poltavsky, K. T. Sch¨ utt, A. Tkatchenko, and K.-R. M¨ uller, Chemical Reviews121, 10142 (2021)
2021
-
[13]
D. Wu, L. Wang, and P. Zhang, Phys. Rev. Lett.122, 080602 (2019)
2019
-
[14]
Huembeli, J
P. Huembeli, J. M. Arrazola, N. Killoran, M. Mohseni, and P. Wittek, Quantum Machine Intelligence4, 1 (2022)
2022
-
[15]
Du and I
Y. Du and I. Mordatch, inNeural Information Processing Systems(2019)
2019
-
[16]
L. Gagnon and G. Lajoie, Clarifying MCMC-based train- ing of modern EBMs : Contrastive Divergence versus Maximum Likelihood (2022), arXiv:2202.12176 [cs.LG]
-
[17]
Tieleman, inProceedings of the 25th International Conference on Machine Learning (ICML)(2008) pp
T. Tieleman, inProceedings of the 25th International Conference on Machine Learning (ICML)(2008) pp. 1064–1071
2008
- [18]
-
[19]
No´ e, S
F. No´ e, S. Olsson, J. K¨ ohler, and H. Wu, Science365, eaaw1147 (2019)
2019
-
[20]
M. S. Shell, The Journal of Chemical Physics129, 144108 (2008)
2008
-
[21]
W. G. Noid, J.-W. Chu, G. S. Ayton, V. Krishna, S. Izvekov, G. A. Voth, A. Das, and H. C. Andersen, The Journal of Chemical Physics128, 244114 (2008)
2008
-
[22]
Thaler and J
S. Thaler and J. Zavadlav, Nature Communications12, 6884 (2021)
2021
-
[23]
Focassio, L
B. Focassio, L. P. M. Freitas, and G. R. Schleder, ACS Applied Materials & Interfaces17, 13111 (2025)
2025
-
[24]
Vandermause, S
J. Vandermause, S. B. Torrisi, S. Batzner, Y. Xie, L. Sun, A. M. Kolpak, and B. Kozinsky, npj Computational Ma- terials6, 20 (2020)
2020
-
[25]
Schran, K
C. Schran, K. Brezina, and O. Marsalek, The Journal of Chemical Physics153, 104105 (2020)
2020
-
[26]
Z. Yan, Z. Fan, and Y. Zhu, Journal of Chemical Infor- mation and Modeling66, 1406 (2026), pMID: 41610402
2026
-
[27]
A. S. Christensen and A. von Lilienfeld, Revised MD17 dataset (rMD17), Figshare dataset (2020), figshare
2020
-
[28]
P. J. Rossky, J. D. Doll, and H. L. Friedman, The Journal of Chemical Physics69, 4628 (1978)
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.