TACO: Task-Aware Column Description Generation Using LLMs
Pith reviewed 2026-06-26 14:11 UTC · model grok-4.3
The pith
TACO generates column descriptions via abbreviation expansion, initial LLM output, and revision against simulated downstream tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
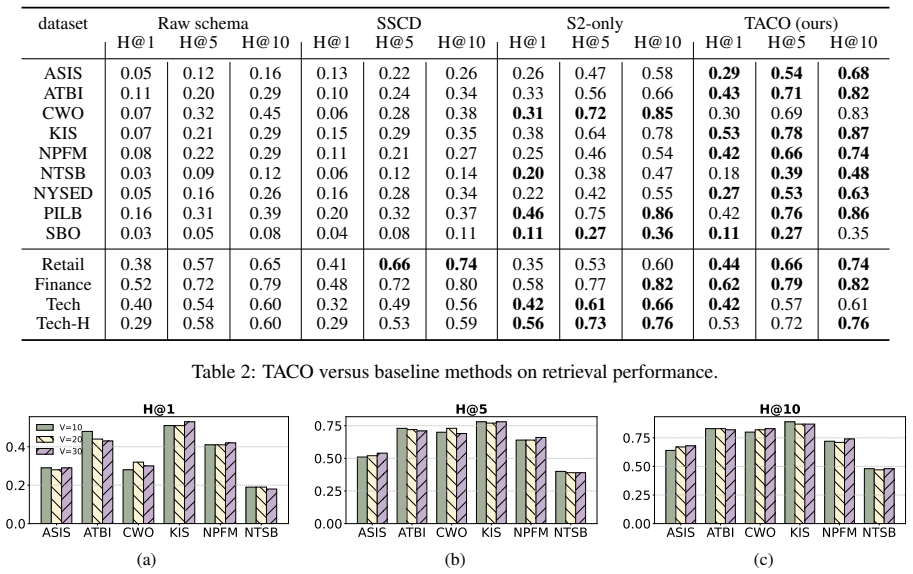
TACO is a task-aware framework that produces more accurate column descriptions than single-prompt LLMs by chaining abbreviation expansion, enriched description generation, and revision that incorporates feedback from simulated downstream tasks, yielding measurable gains on NL2SQL, table question answering, and entity linking across both public and enterprise tabular datasets.
What carries the argument
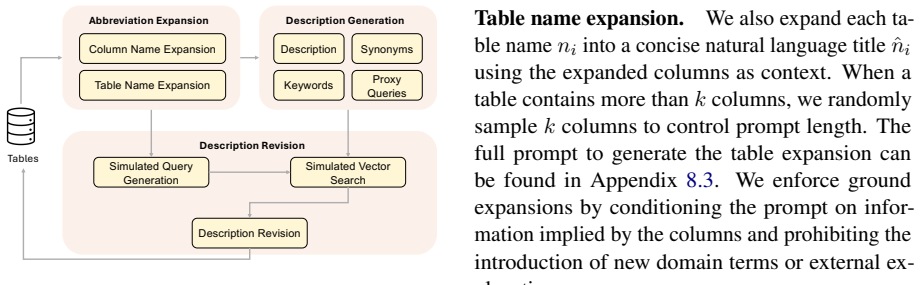
The three-step pipeline of abbreviation expansion to standardize names, description generation enriched with synonyms and search keywords, and description revision driven by simulated downstream tasks.
Load-bearing premise
Refinements produced by simulating downstream tasks in the revision step will generalize to real user tasks without introducing simulation-specific bias or overfitting.
What would settle it
Run TACO-generated descriptions on a new real-world task whose structure was never used in any simulation step and measure whether the reported performance lift disappears or reverses.
Figures









read the original abstract
Generating accurate and informative column descriptions (e.g. "membership status of customers" for the column name "cust_mem") is essential for a wide range of downstream NLP tasks on tabular data, including NL2SQL, table question answering, and entity linking. This problem arises in enterprises, domain sciences, government data portals, and so on. Despite its importance, most real-world datasets suffer from missing or cryptic documentation, often due to abbreviated column names or domain-specific jargon. Existing approaches largely rely on single-prompt large language models (LLMs), which struggle with three key issues: (i) inconsistent or incorrect handling of abbreviations, (ii) hallucinated or incomplete descriptions, and (iii) redundancy or vagueness that hinders downstream performance. We present TACO, a task-aware framework for automatic column description generation using LLMs. TACO introduces a three-step pipeline: (1) abbreviation expansion, which standardizes column names; (2) description generation, which produces initial semantic descriptions enriched with synonyms and search-oriented keywords; and (3) description revision, which refines these outputs using simulated downstream tasks. In addition, we investigate human-in-the-loop extensions and release new evaluation datasets for entity linking and schema enrichment. Extensive experiments across public and proprietary datasets show that TACO consistently outperforms existing methods, improving downstream task performance by up to 32%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TACO, a three-step LLM pipeline for generating column descriptions from cryptic names: (1) abbreviation expansion, (2) initial semantic description generation enriched with synonyms and keywords, and (3) revision via simulated downstream tasks. It claims consistent outperformance over prior methods on public and proprietary datasets for tasks including NL2SQL, table QA, and entity linking, with downstream gains up to 32%, while also releasing new evaluation datasets and exploring human-in-the-loop variants.
Significance. If the empirical gains are robust and the simulated revision generalizes without distribution shift, the work could meaningfully improve automated handling of poorly documented tabular data across enterprise, scientific, and government settings. The release of new datasets is a concrete positive contribution.
major comments (2)
- [Description revision step (Section 3)] Description revision step (Section 3): The headline claim of up to 32% downstream improvement rests on step (3) producing refinements that transfer to real NL2SQL/table-QA/entity-linking evaluations. No held-out validation or explicit distributional comparison between the simulated tasks and the actual evaluation tasks is described; if the simulation objective is narrow or overlaps with test distributions, measured gains could be artifacts rather than genuine description quality.
- [Experimental results and evaluation (Section 4 / Tables 2-4)] Experimental results and evaluation (Section 4 / Tables 2-4): The abstract states 'extensive experiments' and a 32% figure, yet the provided description supplies no information on baseline selection, exact metrics, how the 32% was computed (absolute vs. relative, on which task), statistical significance, or controls for prompt variability and dataset splits. This prevents verification that the outperformance claim is supported.
minor comments (2)
- [Abstract] Abstract: The claim of 'consistently outperforms' would be clearer if the abstract briefly named the main baselines and the primary downstream metric on which the 32% gain was observed.
- [Method overview] Notation: The distinction between 'search-oriented keywords' in step (2) and the simulated-task objective in step (3) is not sharply delineated, making it hard to isolate the contribution of each component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Description revision step (Section 3)] Description revision step (Section 3): The headline claim of up to 32% downstream improvement rests on step (3) producing refinements that transfer to real NL2SQL/table-QA/entity-linking evaluations. No held-out validation or explicit distributional comparison between the simulated tasks and the actual evaluation tasks is described; if the simulation objective is narrow or overlaps with test distributions, measured gains could be artifacts rather than genuine description quality.
Authors: The simulated tasks used in the revision step are constructed directly from the same task definitions as the downstream evaluations (e.g., SQL query simulation for NL2SQL and answer generation for table QA). While the current manuscript does not provide an explicit held-out validation set or quantitative distributional comparison (such as embedding distances), the observed gains are consistent across independent public and proprietary datasets, which supports generalization. We will add a dedicated paragraph in Section 3 detailing the simulation construction process with examples and a qualitative alignment analysis to the evaluation tasks, plus a limitations subsection discussing potential distribution shift. revision: yes
-
Referee: [Experimental results and evaluation (Section 4 / Tables 2-4)] Experimental results and evaluation (Section 4 / Tables 2-4): The abstract states 'extensive experiments' and a 32% figure, yet the provided description supplies no information on baseline selection, exact metrics, how the 32% was computed (absolute vs. relative, on which task), statistical significance, or controls for prompt variability and dataset splits. This prevents verification that the outperformance claim is supported.
Authors: We agree that the experimental section requires additional detail for full verifiability. The 32% figure is the maximum relative improvement in task-specific metrics (e.g., execution accuracy or F1) versus the strongest baseline on one dataset-task pair. Baselines comprise prior column-description methods and vanilla LLM prompting; metrics follow standard definitions per task; experiments use fixed splits with multiple prompt runs. We will revise Section 4 and the associated tables to explicitly list all baselines with selection rationale, report both absolute and relative scores, include statistical significance results (e.g., paired tests), describe prompt-variability controls, and specify dataset splits. These changes will directly address the verification concern. revision: yes
Circularity Check
No significant circularity; empirical framework self-contained
full rationale
The paper describes an empirical three-step LLM pipeline for column description generation (abbreviation expansion, initial generation, revision via simulated tasks) and supports its claims via performance comparisons on public and proprietary datasets. No equations, fitted parameters, or derivations appear in the provided text. The central result (up to 32% downstream gains) rests on external benchmark evaluations rather than any self-referential reduction, self-citation chain, or input-renamed-as-prediction. This matches the default case of a non-circular empirical method paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be prompted to expand abbreviations and generate descriptions without hallucination when given structured steps.
Reference graph
Works this paper leans on
-
[1]
Ting Cai, Stephen Sheen, and AnHai Doan
Under review. Ting Cai, Stephen Sheen, and AnHai Doan. 2025. Columbo: Expanding abbreviated column names for tabular data using large language models.Preprint, arXiv:2508.09403. Zhoujun Cheng, Haoyu Dong, Zhiruo Wang, Ran Jia, Jiaqi Guo, Yan Gao, Shi Han, Jian-Guang Lou, and Dongmei Zhang. 2022. Hitab: A hierarchical table dataset for question answering a...
arXiv 2025
-
[2]
arXiv preprint arXiv:2402.17944
Large language models (llms) on tabular data: Prediction, generation, and understanding–a survey. arXiv preprint arXiv:2402.17944. Benjamin Feuer, Yurong Liu, Chinmay Hegde, and Ju- liana Freire. 2024. Archetype: A novel framework for open-source column type annotation using large language models.Proc. VLDB Endow., 17(9):2279– 2292. Juliana Freire, Grace ...
arXiv 2024
-
[3]
Table-to-text generation with effective hier- archical encoder on three dimensions (row, column and time). InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natu- ral Language Processing (EMNLP-IJCNLP), pages 3143–3152, Hong Kong, China. Association for Com- putational Li...
2019
-
[4]
InProceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 4320–4333, Online
TaPas: Weakly supervised table parsing via pre-training. InProceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 4320–4333, Online. Association for Computa- tional Linguistics. Madelon Hulsebos, Paul Groth, and Çagatay Demiralp
-
[5]
Madelon Hulsebos, Kevin Zeng Hu, Michiel A
Adatyper: Adaptive semantic column type detection. Madelon Hulsebos, Kevin Zeng Hu, Michiel A. Bakker, Emanuel Zgraggen, Arvind Satyanarayan, Tim Kraska, Çagatay Demiralp, and César A. Hidalgo
-
[6]
Sherlock: A deep learning approach to seman- tic data type detection. InProceedings of the 25th ACM SIGKDD International Conference on Knowl- edge Discovery & Data Mining, KDD 2019, pages 1500–1508. ACM. Erin Illman and Paul Temple. 2019. California con- sumer privacy act.The Business Lawyer, 75(1):1637– 1646. Zdenˇek Kasner, Ekaterina Garanina, Ondrej Pl...
arXiv 2019
-
[7]
Annotating columns with pre-trained language models.CoRR, abs/2104.01785. Yuan Tian, Jonathan K. Kummerfeld, Toby Jia-Jun Li, and Tianyi Zhang. 2024. Sqlucid: Grounding nat- ural language database queries with interactive ex- planations. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technol- ogy, UIST ’24, New York, NY , US...
arXiv 2024
-
[8]
Text-to-sql domain adaptation via human-llm collaborative data annotation. InProceedings of the 30th International Conference on Intelligent User In- terfaces, IUI ’25, page 1398–1425, New York, NY , USA. Association for Computing Machinery. Yuan Tian, Zheng Zhang, Zheng Ning, Toby Jia-Jun Li, Jonathan K. Kummerfeld, and Tianyi Zhang. 2023. Interactive te...
arXiv 2023
-
[9]
InELLIS workshop on Representation Learning and Generative Models for Structured Data
Matching table metadata to knowledge graphs: A data augmentation perspective. InELLIS workshop on Representation Learning and Generative Models for Structured Data. 10 Jingfeng Yang, Aditya Gupta, Shyam Upadhyay, Luheng He, Rahul Goel, and Shachi Paul. 2022. TableFormer: Robust transformer modeling for table- text encoding. InProceedings of the 60th Annua...
2022
-
[10]
Sato: Contextual semantic type detection in tables.Proc. VLDB Endow., 13(11):1835–1848. Haoxiang Zhang, Yurong Liu, Aécio Santos, Juliana Freire, and 1 others. 2025a. Autoddg: Automated dataset description generation using large language models.arXiv preprint arXiv:2502.01050. Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srini- vasan, Shen Wang, Huzefa Ra...
arXiv 2023
-
[11]
do not add any extra information or explanation in your final expansion
-
[12]
Do not mutate the numbers appear in the attribute names
-
[13]
Keep the original orders of the attribute names
-
[14]
First anaylze the context of the table and explain your expansion of the table name
If a token is already in full form, its expansion should be itself and do not paraphrase it. First anaylze the context of the table and explain your expansion of the table name. At last, output your answer in a JSON format where the key is the original table name and the value is the expanded table name. Figure 6: Prompt for Table Name Expansion You are a...
-
[15]
Moreover, you should also ensure that you do not directly paraphrase the original description nor simply explain the attribute
-
[16]
You should try to describe the attribute name to make it more easily to be searched
-
[17]
You should describe the attribute name in a whole and not just describe a single part
-
[18]
Apart from the description, you should also try to generate the following information helpful for downstream search engines:
Do not hallucinate or make up any ifnormation that is not in the attribute name, altdisplay, original_desc or expansion. Apart from the description, you should also try to generate the following information helpful for downstream search engines:
-
[19]
a list of keywords that are relevant to the attribute, separated by commas
-
[20]
a list of synonyms that are relevant to the attribute, separated by commas
-
[21]
When you generate the keywords, synonyms and search queries, make sure
a list of potential search queries that are relevant to the attribute, separated by commas. When you generate the keywords, synonyms and search queries, make sure
-
[22]
they are relevant to the attribute and the domain
-
[23]
don't generate vague or generic keywords, synonyms or search queries
-
[24]
make it very specific to the attribute and the domain. The attribute information is as follows: attribute_name: {column_name} Can you generate the description, keywords, synonyms and search queries for each of the attribute ? Please return the result in a JSON format. Also can you do a self revision:
-
[25]
first explain your understanding of the attribute and the task
-
[26]
then generate the description, keywords, synonyms and search queries
-
[27]
finally, pinpoint the drawbacks of your generated description, keywords, synonyms and search queries and revise them if necessary
-
[28]
placeholder_attribute_name
return the final result in a JSON format where the key is the column name (make sure it is in the exact format of the input column names), the value is a dictionary with keys being descriptions, keywords, synonyms, and search queries. Figure 7: Prompt for column description generation 12 Given the examples below (each attribute is in table_name.column_nam...
-
[29]
Can you explain in detail why the correct column is not rank the first in the returned results compared to other column's descriptions?
-
[30]
Return the revised enrichment as the same JSON format
Can you focus on how to revise the description (together with the synonyms, keywords, search_queries) for the column'{answer}'so that its cosine similairty between the query increases and the vector search result is better? Provide the 3 most relevant synonyms, keywords and user queries. Return the revised enrichment as the same JSON format. Figure 9: Pro...
-
[31]
Figure 11 shows the prompt to re-generate the column expansions based on human input. 14 Given the following information about a table in the {domain} area: Table Name: {table_name} Table Expansion {generated by LLM, may be wrong): {table_expansion} Column Name and Column Expansion {expansions are generated by LLM, may be wrong): {column_name}: {column_ex...
-
[32]
1: Likely incorrect; probably wrong, very little matches
Assign a confidence score from O to 5 indicating how likely you think the provided expansion is correct, based on your knowledge and the information given: 0: Very likely incorrect; almost certainly wrong. 1: Likely incorrect; probably wrong, very little matches. 2: Possibly incorrect; some clues, but mostly doubtful. 3: Uncertain; about equally likely to...
-
[33]
Output the result in a JSON format, where the keys are the table name and the column names (keep them in the original format) and the value is a dictionary with the following keys
Briefly explain your reasoning for the assigned score. Output the result in a JSON format, where the keys are the table name and the column names (keep them in the original format) and the value is a dictionary with the following keys
-
[34]
expansion: the provided expansion,
-
[35]
score: the ambiguity score,
-
[36]
reason: a short reason for the score Figure 10: Prompt for LLM-as-a-judge for the column expansions Given the following information about a table in the {domain} area: Table Name: {table_name} Table Expansion (generated by LLM, may be wrong): {table_expansion} Column Name and Column Expansion (expansions are generated by LLM, may be wrong): {column_name}:...
-
[37]
user expansion from the same table: {user_feedback_from_the_same_table}
-
[38]
user expansion from other tables: {user_feedback_from_the_other_table} Please revise the table expansion and column expansions based on the user feedback. Return the revised table expansion and column expansions in the JSON format, where the keys are the original table name and column names (do not add table name in front of the column names in the keys) ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.