FairBED: A Bayesian Experimental Design Approach to Gathering Fairer Data
Pith reviewed 2026-06-26 06:05 UTC · model grok-4.3
The pith
FairBED gathers data by maximizing information about the target while minimizing it about sensitive attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FairBED formulates fairness-aware BED objectives that maximize expected information gain about the target quantity while minimizing expected information gain about sensitive attributes, establishes a theoretical link between these objectives and demographic parity, and demonstrates that predictors trained on data acquired under FairBED exhibit improved fairness-accuracy trade-offs compared with data acquired randomly or under conventional BED.
What carries the argument
Fairness-aware BED objectives that maximize expected information gain on the target while minimizing it on sensitive attributes, using the premise that fair data is uninformative about those attributes.
If this is right
- Data acquisition itself becomes a lever for downstream model fairness.
- The same design can be applied to any supervised learning task that involves sensitive attributes.
- The demographic-parity link supplies a concrete way to audit the collected dataset before model training begins.
Where Pith is reading between the lines
- The method could be extended to sequential acquisition loops where fairness constraints are updated after each batch.
- In settings where sensitive attributes are only partially observed, the same information-gain trade-off might still apply by treating missing labels as additional uncertainty.
Load-bearing premise
Fair datasets should be uninformative about sensitive attributes.
What would settle it
A controlled data-acquisition experiment in which models trained on FairBED-selected data fail to show a better fairness-accuracy frontier than models trained on randomly selected data of the same size.
Figures
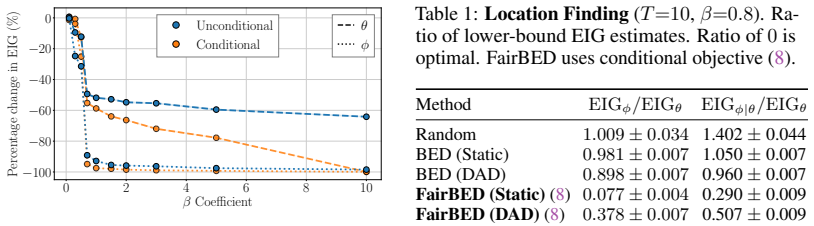

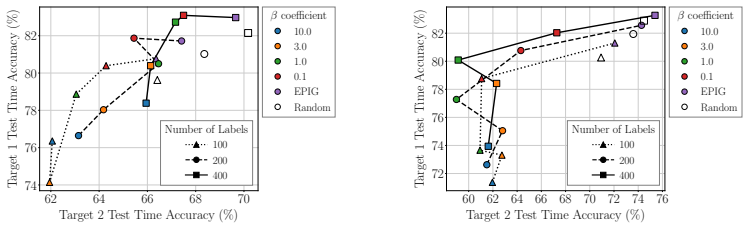

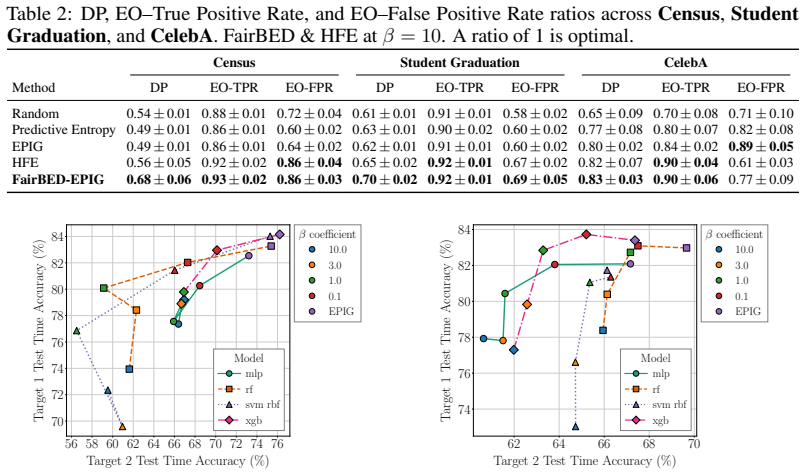
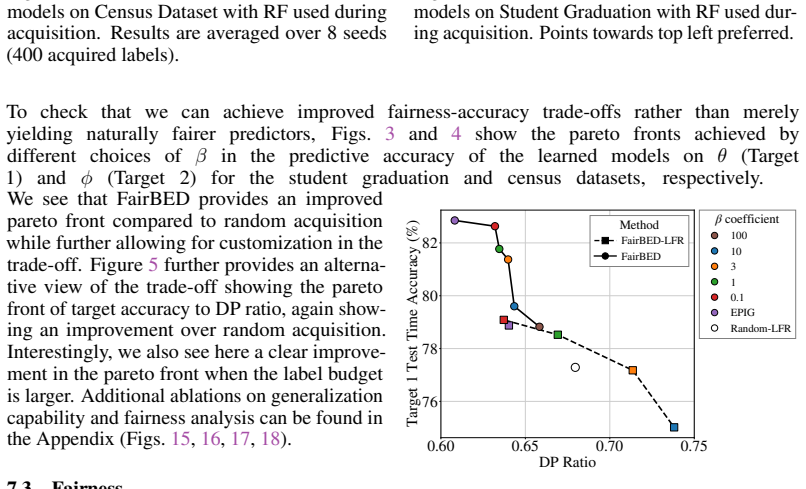
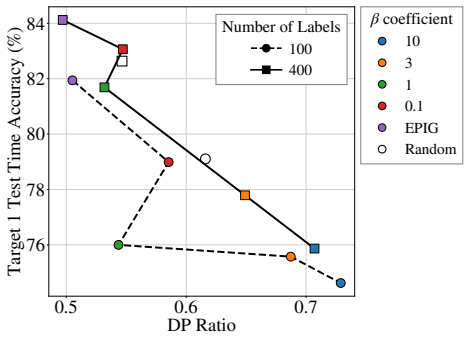
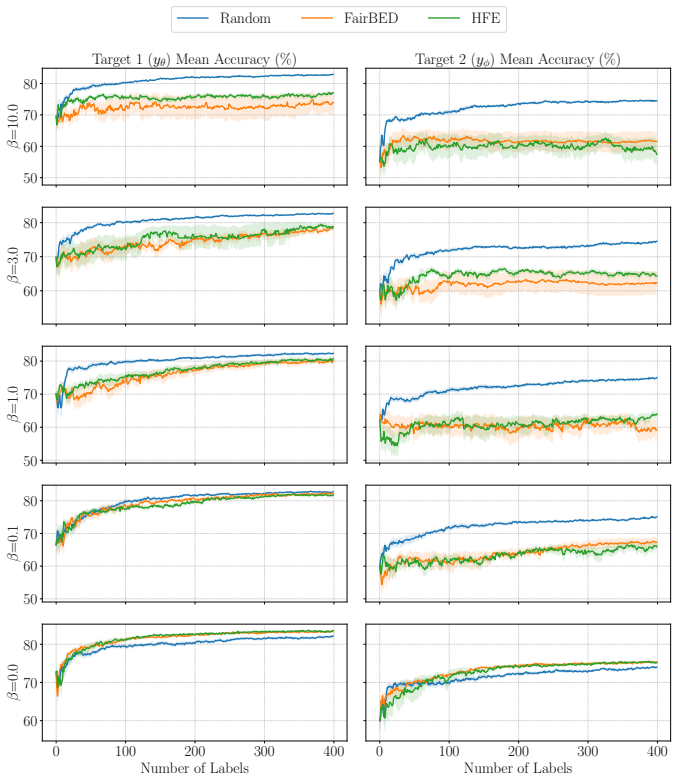
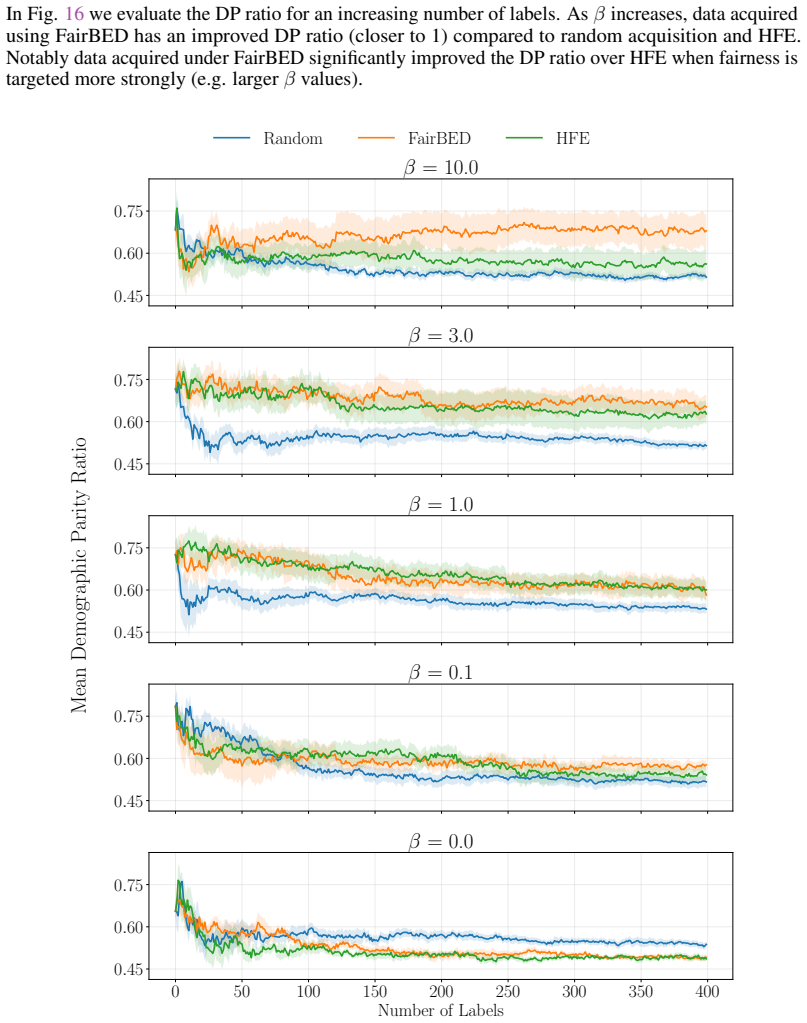
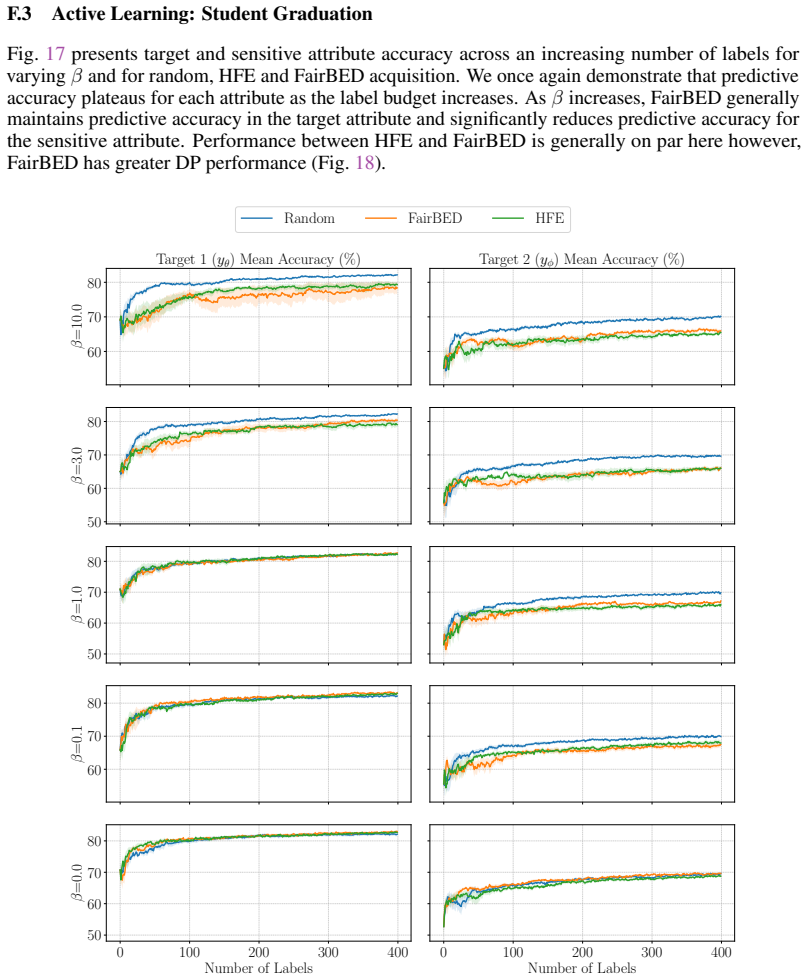
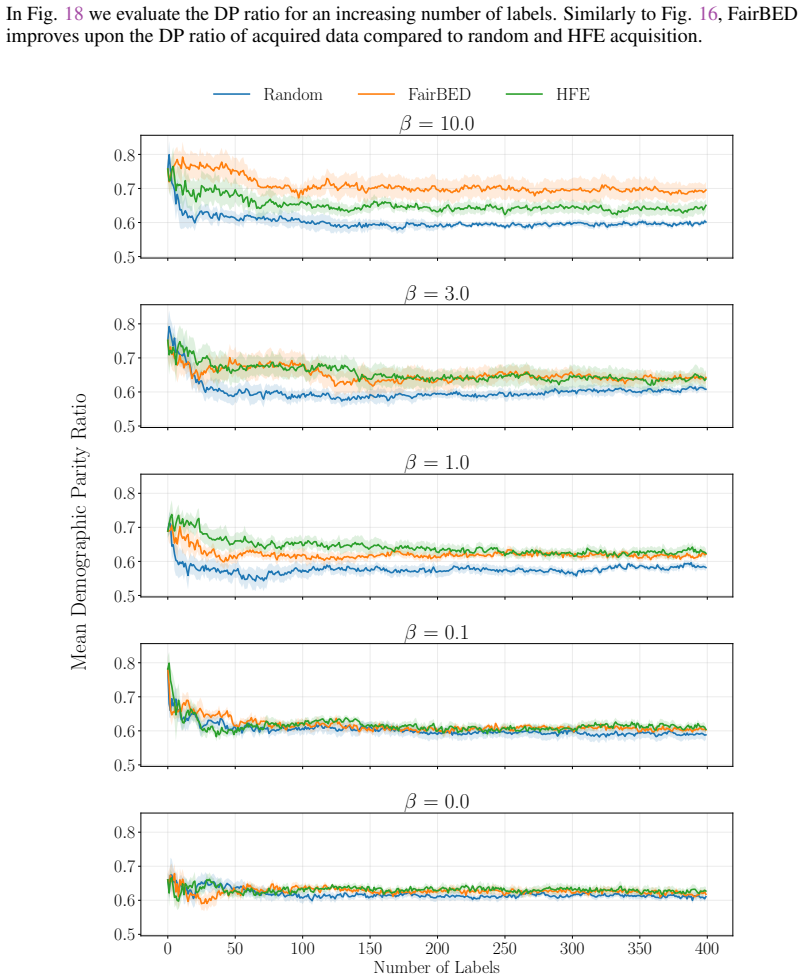
read the original abstract
Frameworks for ensuring fairness in machine learning typically focus on learning fair models from existing data. But this endeavor is often undermined by biases already present in that data. We therefore look to modify the data acquisition process itself to help gather fairer data that is inherently more suitable for training fair predictors. To this end, we introduce FairBED, which provides novel formulations for quantifying the fairness of datasets themselves based on the idea that fair datasets should be uninformative about sensitive attributes. We then use this to construct practical fairness-aware Bayesian experimental design (BED) objectives that maximize expected information gain about the target quantity of interest while minimizing expected information gain about sensitive attributes. We further derive a theoretical link between FairBED and demographic parity, and show empirically that models trained on data gathered using FairBED provide improved fairness-accuracy trade-offs compared to randomly acquired data and conventional BED.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FairBED, a Bayesian experimental design (BED) framework for acquiring fairer data. Fairness of a dataset is quantified via lack of information about sensitive attributes; this yields BED objectives that maximize expected information gain (EIG) on the target while minimizing EIG on the sensitive attribute. A theoretical connection to demographic parity is derived, and experiments claim that models trained on FairBED data achieve better fairness-accuracy trade-offs than those trained on randomly acquired data or data from conventional BED.
Significance. If the derivations and empirical results hold, the work would be significant for shifting fairness interventions upstream to the data-acquisition stage. The explicit link between information-theoretic fairness and demographic parity, together with the dual-objective BED formulation, could influence how practitioners design data-collection pipelines in domains where sensitive attributes are known at acquisition time.
major comments (2)
- [Abstract / §3 (formulation)] The central modeling choice—that a fair dataset must be uninformative about the sensitive attribute—directly determines both the fairness metric and the min-EIG objective. No section appears to provide a formal justification or sensitivity analysis showing that this choice is compatible with other standard fairness definitions (e.g., equalized odds or calibration) when the downstream task is classification.
- [Abstract / theoretical section] The claimed theoretical link to demographic parity is stated in the abstract but the derivation steps, the precise definition of demographic parity used, and the assumptions under which the link holds are not visible in the provided material. Without these, it is impossible to assess whether the link is an equivalence, an implication, or an approximation.
minor comments (2)
- [Abstract] The abstract refers to “practical fairness-aware BED objectives” but supplies neither the explicit functional form of the objectives nor the approximation method used to compute EIG.
- [Abstract] Empirical claims compare against “randomly acquired data and conventional BED,” yet the precise experimental protocol (feature spaces, acquisition budgets, sensitive-attribute distributions, fairness and accuracy metrics) is not summarized.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: [Abstract / §3 (formulation)] The central modeling choice—that a fair dataset must be uninformative about the sensitive attribute—directly determines both the fairness metric and the min-EIG objective. No section appears to provide a formal justification or sensitivity analysis showing that this choice is compatible with other standard fairness definitions (e.g., equalized odds or calibration) when the downstream task is classification.
Authors: Our framework centers on the information-theoretic definition of dataset fairness as lack of information about the sensitive attribute, which directly motivates the dual EIG objective in FairBED. This modeling choice is motivated by the goal of upstream intervention during data acquisition. We did not include a formal sensitivity analysis or explicit compatibility checks against equalized odds or calibration. In the revision we will add a new subsection discussing the rationale for this choice, its relation to demographic parity, and limitations with respect to other fairness notions for classification tasks. revision: yes
-
Referee: [Abstract / theoretical section] The claimed theoretical link to demographic parity is stated in the abstract but the derivation steps, the precise definition of demographic parity used, and the assumptions under which the link holds are not visible in the provided material. Without these, it is impossible to assess whether the link is an equivalence, an implication, or an approximation.
Authors: Section 4 derives the link, showing that under a linear model with Gaussian priors the min-EIG objective on the sensitive attribute implies demographic parity (defined as P(Ŷ=1|S=0)=P(Ŷ=1|S=1)) in expectation for the acquired data. We will expand this section to include all derivation steps, state the precise definition of demographic parity, list the assumptions explicitly, and clarify that the result is an implication under those conditions rather than an equivalence or general approximation. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract and described structure define fairness as lack of information about sensitive attributes, then construct BED objectives (max EIG target, min EIG sensitive) and claim a link to demographic parity. No quoted equations or steps reduce by construction to inputs, self-citations, or fitted parameters renamed as predictions. The central empirical claim is presented as an outcome of the method rather than forced by definition. This is the normal case of an independent construction against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
UCI Machine Learning Repository, 2000
Census-Income (KDD). UCI Machine Learning Repository, 2000. DOI: https://doi.org/10.24432/C5N30T. 8
-
[2]
Active sampling for min-max fairness.arXiv preprint arXiv:2006.06879, 2020
Abernethy, J., Awasthi, P., Kleindessner, M., Morgenstern, J., Russell, C., and Zhang, J. Active sampling for min-max fairness.arXiv preprint arXiv:2006.06879, 2020. 6
arXiv 2006
-
[3]
Abraham, S. S., Sundaram, S. S., et al. Fairness in clustering with multiple sensitive attributes. arXiv preprint arXiv:1910.05113, 2019. 7
arXiv 1910
-
[4]
A reductions approach to fair classification
Agarwal, A., Beygelzimer, A., Dudík, M., Langford, J., and Wallach, H. A reductions approach to fair classification. InInternational conference on machine learning, pp. 60–69. PMLR, 2018. 7
2018
-
[5]
Fair active learning.Expert Sys- tems with Applications, 199:116981, 2022
Anahideh, H., Asudeh, A., and Thirumuruganathan, S. Fair active learning.Expert Sys- tems with Applications, 199:116981, 2022. ISSN 0957-4174. doi: https://doi.org/10.1016/ j.eswa.2022.116981. URL https://www.sciencedirect.com/science/article/pii/ S0957417422004055. 7
arXiv 2022
-
[6]
and Li, J
Ao, Z. and Li, J. On estimating the gradient of the expected information gain in bayesian exper- imental design. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 20311–20319, 2024. 2
2024
-
[7]
T., Zhang, C., Krishnamurthy, A., Langford, J., and Agarwal, A
Ash, J. T., Zhang, C., Krishnamurthy, A., Langford, J., and Agarwal, A. Deep batch active learning by diverse, uncertain gradient lower bounds. InInternational Conference on Learning Representations, 2020. URLhttps://openreview.net/forum?id=ryghZJBKPS. 6
2020
-
[8]
Barlas, Y . Z. and Salako, K. Performance comparisons of reinforcement learning algorithms for sequential experimental design, 2025. URLhttps://arxiv.org/abs/2503.05905. 20
arXiv 2025
-
[9]
Bellamy, R. K. E., Dey, K., Hind, M., Hoffman, S. C., Houde, S., Kannan, K., Lohia, P., Martino, J., Mehta, S., Mojsilovic, A., Nagar, S., Ramamurthy, K. N., Richards, J., Saha, D., Sattigeri, P., Singh, M., Varshney, K. R., and Zhang, Y . AI Fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias, Octobe...
Pith/arXiv arXiv 2018
-
[10]
Prediction- oriented bayesian active learning
Bickford Smith, F., Kirsch, A., Farquhar, S., Gal, Y ., Foster, A., and Rainforth, T. Prediction- oriented bayesian active learning. In Ruiz, F., Dy, J., and van de Meent, J.-W. (eds.),Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 of Proceedings of Machine Learning Research, pp. 7331–7348. PMLR, 25–...
2023
-
[11]
Making better use of unlabelled data in bayesian active learning.ArXiv, abs/2404.17249, 2024
Bickford-Smith, F., Foster, A., and Rainforth, T. Making better use of unlabelled data in bayesian active learning.ArXiv, abs/2404.17249, 2024. URL https://api.semanticscholar.org/ CorpusID:269430415. 6
arXiv 2024
-
[12]
V ., Chades, I., and Dezfouli, A
Blau, T., Bonilla, E. V ., Chades, I., and Dezfouli, A. Optimizing sequential experimental design with deep reinforcement learning. InInternational conference on machine learning, pp. 2107–2128. PMLR, 2022. 2, 20
2022
-
[13]
R., Intes, X., Bürkner, P.-C., and Radev, S
Bracher, N., Kühmichel, L., Ivanova, D. R., Intes, X., Bürkner, P.-C., and Radev, S. T. Jadai: Jointly amortizing adaptive design and bayesian inference, 2025. URL https://arxiv.org/ abs/2512.22999. 20
arXiv 2025
-
[14]
Adaptive sampling strategies to construct equitable training datasets
Cai, W., Encarnacion, R., Chern, B., Corbett-Davies, S., Bogen, M., Bergman, S., and Goel, S. Adaptive sampling strategies to construct equitable training datasets. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, pp. 1467–1478, New York, NY , USA, 2022. Association for Computing Machinery. ISBN 9781450393...
-
[15]
Adaptive sampling strategies to construct equitable training datasets
Cai, W., Encarnacion, R., Chern, B., Corbett-Davies, S., Bogen, M., Bergman, S., and Goel, S. Adaptive sampling strategies to construct equitable training datasets. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pp. 1467–1478, 2022. 7
2022
-
[16]
and Haas, C
Caton, S. and Haas, C. Fairness in machine learning: A survey.ACM Comput. Surv., 56(7), April
-
[17]
ISSN 0360-0300. doi: 10.1145/3616865. URL https://doi.org/10.1145/3616865. 1, 3
-
[18]
R., Myung, J
Cavagnaro, D. R., Myung, J. I., Pitt, M. A., and Kujala, J. V . Adaptive design optimization: A mutual information-based approach to model discrimination in cognitive science.Neural computation, 22(4):887–905, 2010. 2
2010
-
[19]
and Wang, X
Chai, J. and Wang, X. Fairness with adaptive weights. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (eds.),Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pp. 2853–
-
[20]
URL https://proceedings.mlr.press/v162/chai22a
PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/chai22a. html. 1, 3
2022
-
[21]
and Verdinelli, I
Chaloner, K. and Verdinelli, I. Bayesian experimental design: A review.Statistical Science, pp. 273–304, 1995. 1, 2
1995
-
[22]
Fair prediction with disparate impact: A study of bias in recidivism prediction instruments, 2017
Chouldechova, A. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments, 2017. URLhttps://arxiv.org/abs/1703.00056. 1, 3
Pith/arXiv arXiv 2017
-
[23]
Cruz, A. F. and Hardt, M. Unprocessing seven years of algorithmic fairness.arXiv preprint arXiv:2306.07261, 2023. 7
arXiv 2023
-
[24]
Review of mathematical frameworks for fairness in machine learning, 2020
del Barrio, E., Gordaliza, P., and Loubes, J.-M. Review of mathematical frameworks for fairness in machine learning, 2020. URLhttps://arxiv.org/abs/2005.13755. 2, 3, 30
arXiv 2020
-
[25]
Fairness through awareness,
Dwork, C., Hardt, M., Pitassi, T., Reingold, O., and Zemel, R. Fairness through awareness,
-
[26]
URLhttps://arxiv.org/abs/1104.3913. 3, 6
-
[27]
T., and Leiserson, M
Dwork, C., Immorlica, N., Kalai, A. T., and Leiserson, M. Decoupled classifiers for group-fair and efficient machine learning. InConference on fairness, accountability and transparency, pp. 119–133. PMLR, 2018. 6
2018
-
[28]
M., Saxena, A., Pei, Y ., and Pechenizkiy, M
Fajri, R. M., Saxena, A., Pei, Y ., and Pechenizkiy, M. Fal-cur: Fair active learning using uncertainty and representativeness on fair clustering.Expert Syst. Appl., 242(C), May 2024. ISSN 0957-4174. doi: 10.1016/j.eswa.2023.122842. URL https://doi.org/10.1016/j. eswa.2023.122842. 7
-
[29]
A., Moeller, J., Scheidegger, C., and Venkatasubramanian, S
Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., and Venkatasubramanian, S. Cer- tifying and removing disparate impact. InProceedings of the 21th ACM SIGKDD Interna- tional Conference on Knowledge Discovery and Data Mining, KDD ’15, pp. 259–268, New York, NY , USA, 2015. Association for Computing Machinery. ISBN 9781450336642. doi: 10.1145/2783...
-
[30]
W., Rainforth, T., and Goodman, N
Foster, A., Jankowiak, M., Bingham, E., Horsfall, P., Teh, Y . W., Rainforth, T., and Goodman, N. Variational Bayesian Optimal Experimental Design. InAdvances in Neural Information Processing Systems 32, pp. 14036–14047. Curran Associates, Inc., 2019. 2
2019
-
[31]
W., and Rainforth, T
Foster, A., Jankowiak, M., O’Meara, M., Teh, Y . W., and Rainforth, T. A unified stochastic gradient approach to designing bayesian-optimal experiments. InInternational Conference on Artificial Intelligence and Statistics, pp. 2959–2969. PMLR, 2020. 7, 18
2020
-
[32]
R., Malik, I., and Rainforth, T
Foster, A., Ivanova, D. R., Malik, I., and Rainforth, T. Deep adaptive design: Amortizing sequential bayesian experimental design.Proceedings of the 38th International Conference on Machine Learning (ICML), PMLR 139, 2021. 2, 7, 18, 20, 21, 22
2021
-
[33]
R., Thurston, H., Varghese, P., Hong, C., and Gronsbell, J
Gao, J., Chou, B., McCaw, Z. R., Thurston, H., Varghese, P., Hong, C., and Gronsbell, J. What is fair? defining fairness in machine learning for health.Statistics in Medicine, 44(20-22): e70234, 2025. 30
2025
-
[34]
Goda, T., Hironaka, T., and Kitade, W. Unbiased mlmc stochastic gradient-based optimization of bayesian experimental designs.arXiv preprint arXiv:2005.08414, 2020. 2
arXiv 2005
-
[35]
Equality of opportunity in super- vised learning
Hardt, M., Price, E., Price, E., and Srebro, N. Equality of opportunity in super- vised learning. In Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., and Garnett, R. (eds.),Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016. URL https://proceedings.neurips.cc/paper_files/paper/2016/file/ 9d2682367c3935defcb1f9e247a97...
2016
-
[36]
Equality of opportunity in supervised learning.Advances in neural information processing systems, 29, 2016
Hardt, M., Price, E., and Srebro, N. Equality of opportunity in supervised learning.Advances in neural information processing systems, 29, 2016. 6, 7
2016
-
[37]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
-
[38]
He, X. and Li, Y . Fairness in machine learning: A review for statisticians.Journal of the American Statistical Association, 120(552):2834–2851, 2025. doi: 10.1080/01621459.2025. 2579579. URLhttps://doi.org/10.1080/01621459.2025.2579579. 1, 3
-
[39]
R., Guan, C., and Rainforth, T
Hedman, M., Ivanova, D. R., Guan, C., and Rainforth, T. Step-DAD: Semi-amortized policy- based bayesian experimental design. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=JRg8P2bX8P. 2, 20
2025
-
[40]
Houlsby, N., Huszár, F., Ghahramani, Z., and Lengyel, M. Bayesian active learning for classification and preference learning.arXiv preprint arXiv:1112.5745, 2011. 6, 19
Pith/arXiv arXiv 2011
-
[41]
Pushing the limits of fairness impossibility: Who’s the fairest of them all?Advances in Neural Information Processing Systems, 35: 32749–32761, 2022
Hsu, B., Mazumder, R., Nandy, P., and Basu, K. Pushing the limits of fairness impossibility: Who’s the fairest of them all?Advances in Neural Information Processing Systems, 35: 32749–32761, 2022. 30
2022
-
[42]
Optimal experimental design: Formulations and computations.Acta Numerica, 33:715–840, 2024
Huan, X., Jagalur, J., and Marzouk, Y . Optimal experimental design: Formulations and computations.Acta Numerica, 33:715–840, 2024. 2
2024
-
[43]
Amortized bayesian experimental design for decision-making
Huang, D., Guo, Y ., Acerbi, L., and Kaski, S. Amortized bayesian experimental design for decision-making. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385. 20
2024
-
[44]
Huang, D., Wen, X., Bharti, A., Kaski, S., and Acerbi, L. Aline: Joint amortization for bayesian inference and active data acquisition.ArXiv, abs/2506.07259, 2025. URL https: //api.semanticscholar.org/CorpusID:279251169. 20
arXiv 2025
-
[45]
Bayesian experimental design via contrastive diffusions, 2025
Iollo, J., Heinkelé, C., Alliez, P., and Forbes, F. Bayesian experimental design via contrastive diffusions, 2025. URLhttps://arxiv.org/abs/2410.11826. 20
arXiv 2025
-
[46]
Nesting particle filters for experimental design in dynamical systems, 2024
Iqbal, S., Corenflos, A., Särkkä, S., and Abdulsamad, H. Nesting particle filters for experimental design in dynamical systems, 2024. URLhttps://arxiv.org/abs/2402.07868. 2 12
arXiv 2024
-
[47]
R., Foster, A., Kleinegesse, S., Gutmann, M., and Rainforth, T
Ivanova, D. R., Foster, A., Kleinegesse, S., Gutmann, M., and Rainforth, T. Implicit Deep Adaptive Design: Policy–Based Experimental Design without Likelihoods. InAd- vances in Neural Information Processing Systems, volume 34, pp. 25785–25798. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper/2021/file/ d811406316b669ad3d370d78b51b1d...
2021
-
[48]
Decision theory for discrimination-aware classification
Kamiran, F., Karim, A., and Zhang, X. Decision theory for discrimination-aware classification. In2012 IEEE 12th international conference on data mining, pp. 924–929. IEEE, 2012. 7, 10, 31
2012
-
[49]
A., and Rainforth, T
Kerrigan, G., Naesseth, C. A., and Rainforth, T. A geometric approach to optimal experimental design. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026. URLhttps://openreview.net/forum?id=u0aepMHQ5p. 20
2026
-
[50]
Kleinegesse, S., Drovandi, C., and Gutmann, M. U. Sequential Bayesian Experimental Design for Implicit Models via Mutual Information.Bayesian Analysis, pp. 1 – 30, 2021. doi: 10.1214/20-BA1225. 20
-
[51]
Adaptive sensitive reweighting to mitigate bias in fairness-aware classification
Krasanakis, E., Spyromitros-Xioufis, E., Papadopoulos, S., and Kompatsiaris, Y . Adaptive sensitive reweighting to mitigate bias in fairness-aware classification. InProceedings of the 2018 World Wide Web Conference, WWW ’18, pp. 853–862, Republic and Canton of Geneva, CHE,
2018
-
[52]
International World Wide Web Conferences Steering Committee. ISBN 9781450356398. doi: 10.1145/3178876.3186133. URL https://doi.org/10.1145/3178876.3186133. 1, 3
-
[53]
Adaptive sensitive reweighting to mitigate bias in fairness-aware classification
Krasanakis, E., Spyromitros-Xioufis, E., Papadopoulos, S., and Kompatsiaris, Y . Adaptive sensitive reweighting to mitigate bias in fairness-aware classification. InProceedings of the 2018 world wide web conference, pp. 853–862, 2018. 6
2018
-
[54]
Lim, V ., Novoseller, E., Ichnowski, J., Huang, H., and Goldberg, K. Policy-based bayesian experimental design for non-differentiable implicit models.arXiv preprint arXiv:2203.04272,
-
[55]
Lindley, D. V . On a measure of the information provided by an experiment.The Annals of Mathematical Statistics, pp. 986–1005, 1956. 1, 2, 20
1956
-
[56]
V .Bayesian statistics, a review, volume 2
Lindley, D. V .Bayesian statistics, a review, volume 2. SIAM, 1972. 1, 2
1972
-
[57]
Z., Haghgoo, B., Chen, A
Liu, E. Z., Haghgoo, B., Chen, A. S., Raghunathan, A., Koh, P. W., Sagawa, S., Liang, P., and Finn, C. Just train twice: Improving group robustness without training group information. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pp. 6781–6792....
2021
-
[58]
Deep learning face attributes in the wild.2015 IEEE International Conference on Computer Vision (ICCV), pp
Liu, Z., Luo, P., Wang, X., and Tang, X. Deep learning face attributes in the wild.2015 IEEE International Conference on Computer Vision (ICCV), pp. 3730–3738, 2014. URL https://api.semanticscholar.org/CorpusID:459456. 8, 29
2015
-
[59]
On the fairness of disentangled representations
Locatello, F., Abbati, G., Rainforth, T., Bauer, S., Scholkopf, B., and Bachem, O. On the fairness of disentangled representations. InNeural Information Processing Systems, 2019. URL https://api.semanticscholar.org/CorpusID:173187920. 6
2019
-
[60]
MacKay, D. J. Information-based objective functions for active data selection.Neural computa- tion, 4(4):590–604, 1992. 2, 6
1992
-
[61]
Minimax pareto fairness: A multi objective perspective
Martinez, N., Bertran, M., and Sapiro, G. Minimax pareto fairness: A multi objective perspective. InInternational conference on machine learning, pp. 6755–6764. PMLR, 2020. 7
2020
-
[62]
Algorithmic fairness: Choices, assumptions, and definitions.Annual Review of Statistics and Its Application, 2021
Mitchell, S., Potash, E., Barocas, S., D’Amour, A., and Lum, K. Algorithmic fairness: Choices, assumptions, and definitions.Annual Review of Statistics and Its Application, 2021. URL https://api.semanticscholar.org/CorpusID:228893833. 3, 6
2021
-
[63]
I., Cavagnaro, D
Myung, J. I., Cavagnaro, D. R., and Pitt, M. A. A tutorial on adaptive design optimization. Journal of mathematical psychology, 57(3-4):53–67, 2013. 20 13
2013
-
[64]
Fairness without harm: An influence- guided active sampling approach.Advances in Neural Information Processing Systems, 37: 61513–61548, 2024
Pang, J., Wang, J., Zhu, Z., Yao, Y ., Qian, C., and Liu, Y . Fairness without harm: An influence- guided active sampling approach.Advances in Neural Information Processing Systems, 37: 61513–61548, 2024. 7
2024
-
[65]
Pytorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. Pytorch: An imperative style, high-performance deep learning library. InAdvances in Neural Informa...
2019
-
[66]
On nesting monte carlo estimators
Rainforth, T., Cornish, R., Yang, H., Warrington, A., and Wood, F. On nesting monte carlo estimators. InInternational Conference on Machine Learning, pp. 4267–4276. PMLR, 2018. 2, 20
2018
-
[67]
R., and Bickford Smith, F
Rainforth, T., Foster, A., Ivanova, D. R., and Bickford Smith, F. Modern bayesian experimental design.Statistical Science, 39(1):100–114, 2024. 1, 2, 20
2024
-
[68]
M., Machado, J., and Baptista, L
Realinho, V ., Vieira, M. M., Machado, J., and Baptista, L. Predict Students’ Dropout and Academic Success. UCI Machine Learning Repository, 2021. DOI: https://doi.org/10.24432/C5MC89. 8
-
[69]
C., and Fei-Fei, L
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. Imagenet large scale visual recognition challenge.International Journal of Computer Vision (IJCV), 115(3):211–252, 2015. 29
2015
-
[70]
Ryan, E. G., Drovandi, C. C., Thompson, M. H., and Pettitt, A. N. Towards bayesian experimental design for nonlinear models that require a large number of sampling times. Computational Statistics & Data Analysis, 70:45–60, 2014. ISSN 0167-9473. doi: https: //doi.org/10.1016/j.csda.2013.08.017. 20
-
[71]
G., Drovandi, C
Ryan, E. G., Drovandi, C. C., McGree, J. M., and Pettitt, A. N. A review of modern computa- tional algorithms for bayesian optimal design.International Statistical Review, 84(1):128–154,
-
[72]
Active learning literature survey
Settles, B. Active learning literature survey. Technical report, University of Wisconsin— Madison, 2009. 6
2009
-
[73]
Promoting fairness in learned models by learning to active learn under parity constraints
Sharaf, A., Daume III, H., and Ni, R. Promoting fairness in learned models by learning to active learn under parity constraints. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pp. 2149–2156, 2022. 1, 7
2022
-
[74]
Adaptive sampling for minimax fair classification.Advances in Neural Information Processing Systems, 34:24535–24544, 2021
Shekhar, S., Fields, G., Ghavamzadeh, M., and Javidi, T. Adaptive sampling for minimax fair classification.Advances in Neural Information Processing Systems, 34:24535–24544, 2021. 6
2021
-
[75]
Metric-fair active learning
Shen, J., Cui, N., and Wang, J. Metric-fair active learning. InInternational conference on machine learning, pp. 19809–19826. PMLR, 2022. 1, 6, 7
2022
-
[76]
Discrimination in online ad delivery.Commun
Sweeney, L. Discrimination in online ad delivery.Commun. ACM, 56(5):44–54, May 2013. ISSN 0001-0782. doi: 10.1145/2447976.2447990. URL https://doi.org/10.1145/ 2447976.2447990. 1
-
[77]
H., Zhang, H., Park, J., Rong, K., and Whang, S
Tae, K. H., Zhang, H., Park, J., Rong, K., and Whang, S. E. Falcon: Fair active learning using multi-armed bandits, 2024. URLhttps://arxiv.org/abs/2401.12722. 7
arXiv 2024
-
[78]
Vincent, B. T. and Rainforth, T. The DARC toolbox: automated, flexible, and efficient delayed and risky choice experiments using bayesian adaptive design.PsyArXiv preprint, 2017. 20
2017
-
[79]
Williams, D. R. . M. S. A. Discrimination and racial disparities in health: evidence and needed research.Journal of behavioral medicine, 32(1), 20–47., 2009. URL https://doi.org/10. 1007/s10865-008-9185-0. 1 14
2009
-
[80]
2405.20674,https://arxiv.org/abs/2405.20674
Xia, Y ., Mukherjee, S., Xie, Z., Wu, J., Li, X., Aponte, R., Lyu, H., Barrow, J., Chen, H., Dernoncourt, F., Kveton, B., Yu, T., Zhang, R., Gu, J., Ahmed, N. K., Wang, Y ., Chen, X., Deilamsalehy, H., Kim, S., Hu, Z., Zhao, Y ., Lipka, N., Yoon, S., Huang, T. K., Wang, Z., Mathur, P., Pal, S., Mukherjee, K., Zhang, Z., Park, N., Nguyen, T. H., Luo, J., R...
work page internal anchor Pith review doi:10.48550/arxiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.