Sensitivity as a Double-Edged Sword: A Trade-off Between Discriminability and Adversarial Robustness
Pith reviewed 2026-06-28 15:45 UTC · model grok-4.3
The pith
Fully connected classifiers gain discriminability from high sensitivity to perturbations but lose adversarial robustness as a direct result, while a hybrid prototype mixer captures both properties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
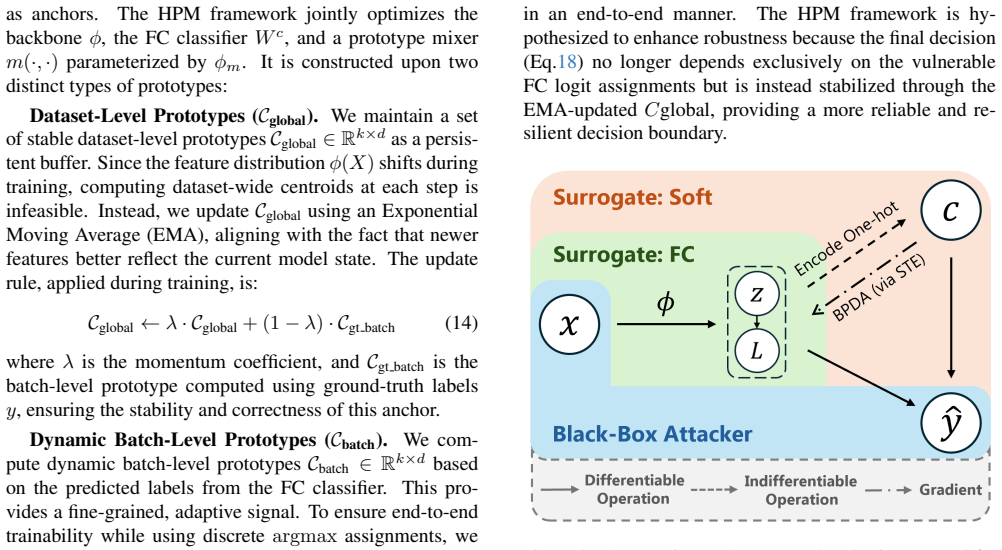
The authors establish that the high sensitivity of fully connected classifiers enables strong discriminability yet directly causes adversarial vulnerability, whereas l2 distance-based classifiers achieve robustness through insensitivity at the expense of accuracy; their Hybrid Prototype Mixing framework fuses stable dataset-level prototypes updated via EMA with dynamic batch-level prototypes generated from FC predictions through a straight-through estimator, yielding l2-distance predictions that retain discriminative power.
What carries the argument
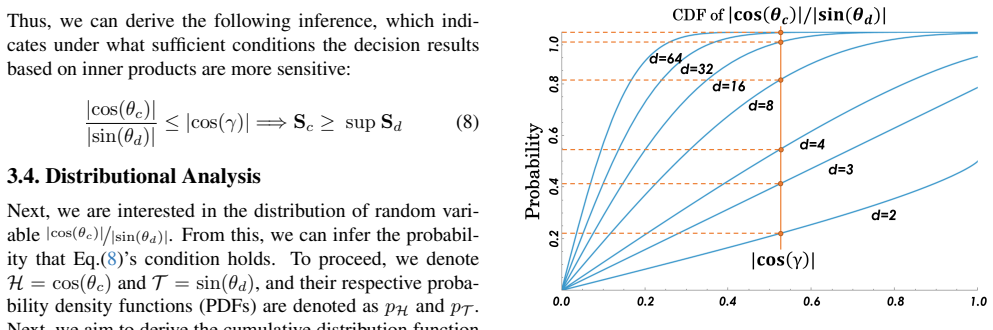
Hybrid Prototype Mixing (HPM) framework that fuses dataset-level EMA-updated prototypes with batch-level prototypes derived via straight-through estimator from the FC classifier output to produce l2-based predictions.
If this is right
- Existing state-of-the-art adversarially trained models receive measurable robustness gains from the plug-and-play module after minimal fine-tuning.
- The Mixed Surrogate Attack protocol enables reliable robustness assessment for architectures that include non-differentiable components such as the straight-through estimator.
- Predictions shift to an l2 distance basis while the original FC classifier's discriminative capability is retained through the dynamic prototype path.
- The method requires no full retraining and applies across multiple model architectures without altering the feature extractor.
Where Pith is reading between the lines
- Decoupling the classification head from the feature extractor may become a standard design pattern for improving security in other vision tasks.
- The same sensitivity-robustness tension could appear in classifier heads used outside image classification, suggesting the mixing approach might generalize.
- Further work could test whether the hybrid prototypes remain effective when the underlying feature extractor itself is replaced by a more robust backbone.
Load-bearing premise
The assumption that FC classifier sensitivity is the main driver of adversarial vulnerability and that the straight-through estimator fusion preserves accuracy while delivering true l2 robustness without introducing new unmeasured artifacts.
What would settle it
An experiment in which models equipped with the hybrid module still suffer attack success rates comparable to the original FC models when evaluated under the Mixed Surrogate Attack protocol using multiple surrogates and AutoAttack.
Figures
read the original abstract
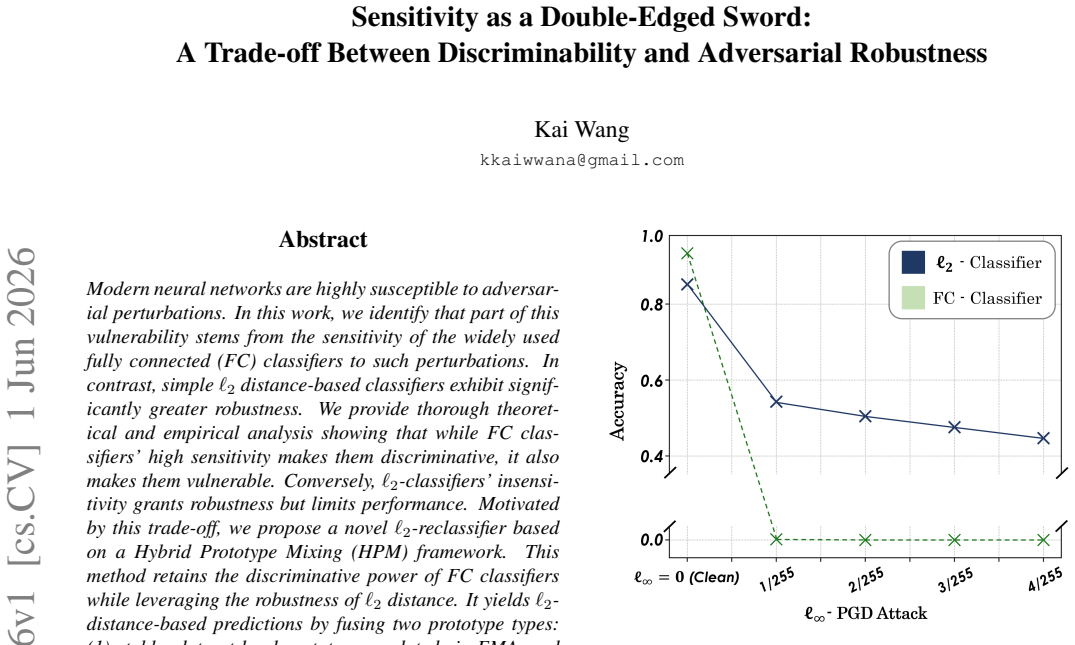
Modern neural networks are highly susceptible to adversarial perturbations. In this work, we identify that part of this vulnerability stems from the sensitivity of the widely used fully connected (FC) classifiers to such perturbations. In contrast, simple $\ell_2$ distance-based classifiers exhibit significantly greater robustness. We provide thorough theoretical and empirical analysis showing that while FC classifiers' high sensitivity makes them discriminative, it also makes them vulnerable. Conversely, $\ell_2$-classifiers' insensitivity grants robustness but limits performance. Motivated by this trade-off, we propose a novel $\ell_2$-reclassifier based on a Hybrid Prototype Mixing (HPM) framework. This method retains the discriminative power of FC classifiers while leveraging the robustness of $\ell_2$ distance. It yields $\ell_2$-distance-based predictions by fusing two prototype types: (1) stable, dataset-level prototypes updated via EMA, and (2) dynamic, batch-level prototypes generated from the FC classifier's predictions using a Straight-Through Estimator (STE). However, this dynamic, STE-based architecture introduces significant challenges for evaluation, such as gradient obfuscation and forward discontinuity. To address this, we propose a new, rigorous evaluation protocol, the Mixed Surrogate Attack (MSA), which uses multiple surrogates along with powerful AutoAttack to ensure a fair and robust assessment. Extensive experiments demonstrate that our lightweight, plug-and-play module, with minimal fine-tuning, effectively enhances the adversarial robustness of various existing SOTA adversarially trained models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that part of adversarial vulnerability in neural networks stems from the high sensitivity of fully connected (FC) classifiers, which aids discriminability but increases vulnerability, while simple ℓ2 distance-based classifiers are more robust but less discriminative. It proposes a Hybrid Prototype Mixing (HPM) framework that fuses EMA-updated dataset-level prototypes with dynamic batch-level prototypes generated via Straight-Through Estimator (STE) from FC predictions to produce ℓ2-distance-based outputs. To handle evaluation issues like gradient obfuscation and forward discontinuity, it introduces the Mixed Surrogate Attack (MSA) protocol. Experiments show that this lightweight plug-and-play module, with minimal fine-tuning, improves adversarial robustness of various SOTA adversarially trained models.
Significance. If the central claims hold without the robustness gains being artifacts of the STE construction or MSA protocol, the work would provide both a practical method for enhancing robustness in existing models and theoretical insight into the sensitivity-discriminability-robustness trade-off. The lightweight nature and plug-and-play design could have broad applicability in computer vision if the insensitivity of the final ℓ2 predictions is rigorously established.
major comments (2)
- [HPM framework] HPM framework (method section): Batch-level prototypes are generated directly from the FC classifier's predictions using STE. This risks reintroducing sensitivity, as any perturbation that flips an FC prediction will shift the batch prototype and thus the fused ℓ2 distance. The manuscript must demonstrate that the overall forward-pass mapping remains insensitive (e.g., Lipschitz or equivalent to a fixed-prototype ℓ2 classifier) rather than relying on the FC component; without this, the claim that HPM resolves the trade-off by leveraging ℓ2 insensitivity does not hold. This is load-bearing for the robustness results.
- [MSA evaluation protocol] MSA evaluation protocol (experiments section): While MSA is presented as addressing gradient obfuscation and forward discontinuity, it is not shown that the protocol verifies the effective decision boundary is insensitive like a pure ℓ2 classifier. Additional analysis (e.g., measuring prototype stability or boundary properties under attack) is required to confirm the robustness is genuine rather than an evaluation artifact.
minor comments (2)
- Clarify notation for the two prototype types and the fusion operation to avoid ambiguity in how EMA and STE components interact during inference.
- Ensure theoretical analysis sections explicitly state assumptions about the FC classifier and how they translate to the hybrid model.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to strengthen the theoretical and empirical support for our claims.
read point-by-point responses
-
Referee: [HPM framework] HPM framework (method section): Batch-level prototypes are generated directly from the FC classifier's predictions using STE. This risks reintroducing sensitivity, as any perturbation that flips an FC prediction will shift the batch prototype and thus the fused ℓ2 distance. The manuscript must demonstrate that the overall forward-pass mapping remains insensitive (e.g., Lipschitz or equivalent to a fixed-prototype ℓ2 classifier) rather than relying on the FC component; without this, the claim that HPM resolves the trade-off by leveraging ℓ2 insensitivity does not hold. This is load-bearing for the robustness results.
Authors: We agree that rigorously demonstrating the insensitivity of the overall HPM forward-pass mapping is necessary to substantiate our central claims. Although the EMA-updated dataset-level prototypes provide stability and the fusion is designed to mitigate sensitivity, the manuscript currently relies primarily on empirical robustness gains. In the revised version, we will add a dedicated theoretical subsection deriving a bound on the Lipschitz constant of the fused mapping, showing that the EMA component ensures equivalence (in the limit) to a fixed-prototype ℓ2 classifier. We will also include new experiments quantifying prototype stability (e.g., variation under input perturbations) and comparing the effective sensitivity to both pure FC and pure ℓ2 baselines. These additions will be placed in the method and experiments sections. revision: yes
-
Referee: [MSA evaluation protocol] MSA evaluation protocol (experiments section): While MSA is presented as addressing gradient obfuscation and forward discontinuity, it is not shown that the protocol verifies the effective decision boundary is insensitive like a pure ℓ2 classifier. Additional analysis (e.g., measuring prototype stability or boundary properties under attack) is required to confirm the robustness is genuine rather than an evaluation artifact.
Authors: We acknowledge that further validation is required to confirm that MSA evaluates an effectively insensitive decision boundary rather than introducing artifacts. While MSA combines multiple surrogates with AutoAttack to mitigate gradient obfuscation and discontinuity, the current experiments do not explicitly compare boundary properties to fixed-prototype ℓ2 classifiers. In the revision, we will augment the evaluation protocol section with additional analyses: (i) measurements of batch-prototype stability (cosine similarity and norm variation) before and after attacks, and (ii) direct comparisons of decision boundaries (via boundary distance metrics) between HPM, FC, and fixed-prototype ℓ2 models under the same attack suite. These results will be reported to demonstrate that the observed robustness aligns with the properties of insensitive ℓ2 classifiers. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
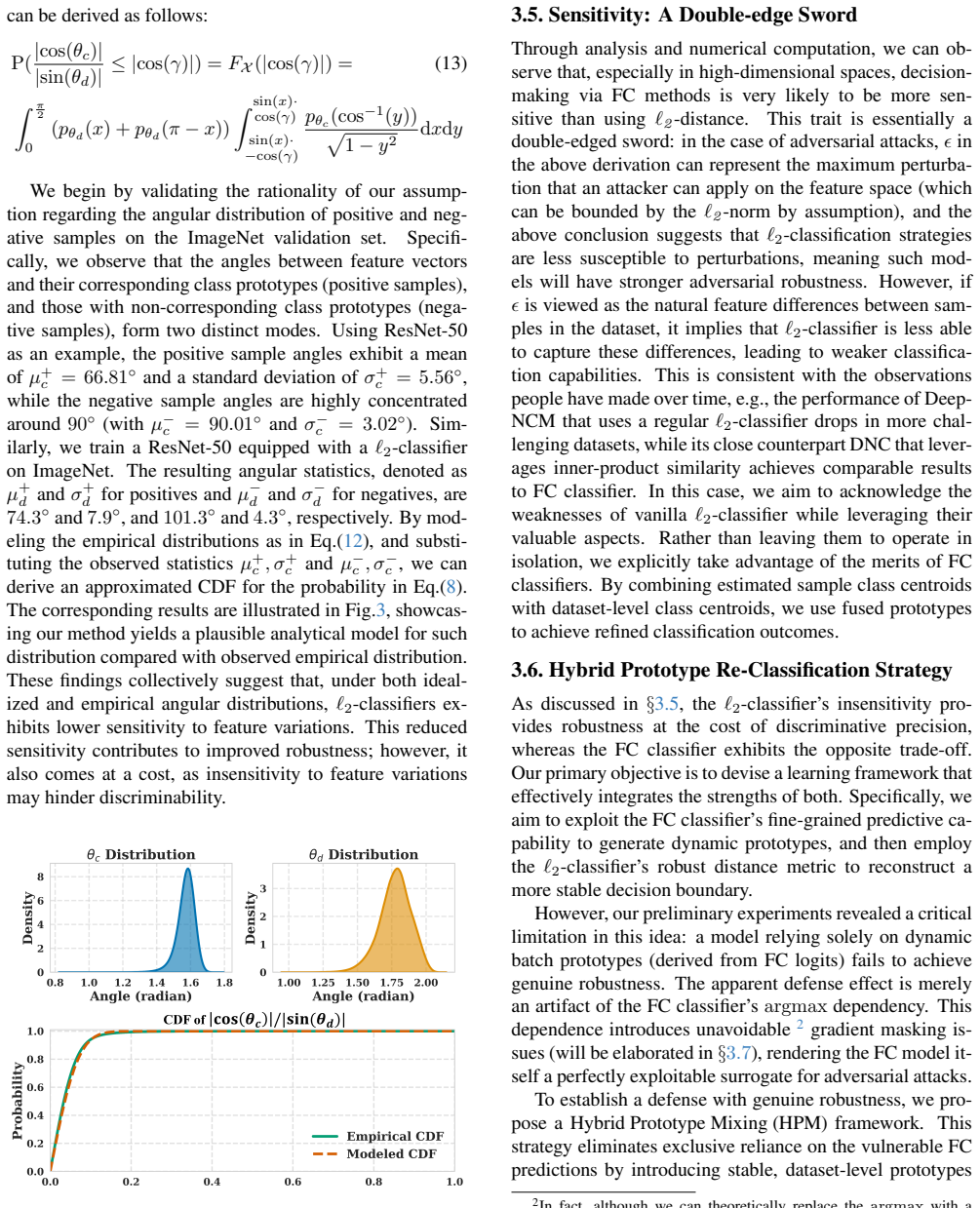
The paper presents a conceptual trade-off between FC classifier sensitivity and ℓ2 robustness, then introduces the HPM module as a hybrid construction using EMA and STE. No equations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. The central claims rest on theoretical/empirical analysis and a proposed evaluation protocol rather than reducing to inputs by construction. Self-citations are not mentioned as load-bearing. This is a standard non-finding for a methods paper without algebraic self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the surprising behavior of distance metrics in high dimensional space
Charu C Aggarwal, Alexander Hinneburg, and Daniel A Keim. On the surprising behavior of distance metrics in high dimensional space. InInternational conference on database theory, pages 420–434. Springer, 2001. 2
2001
-
[2]
Sajjad Amini, Mohammadreza Teymoorianfard, Shiqing Ma, and Amir Houmansadr. Meansparse: Post-training robust- ness enhancement through mean-centered feature sparsifica- tion.arXiv preprint arXiv:2406.05927, 2024. 8, 2
-
[3]
Square attack: a query-efficient black-box adversarial attack via random search
Maksym Andriushchenko, Francesco Croce, Nicolas Flam- marion, and Matthias Hein. Square attack: a query-efficient black-box adversarial attack via random search. InEuropean conference on computer vision, pages 484–501. Springer,
-
[4]
Obfus- cated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfus- cated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational confer- ence on machine learning, pages 274–283. PMLR, 2018. 6
2018
-
[5]
Jimmy Lei Ba. Layer normalization.arXiv preprint arXiv:1607.06450, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Tao Bai, Jinqi Luo, Jun Zhao, Bihan Wen, and Qian Wang. Recent advances in adversarial training for adversarial ro- bustness.arXiv preprint arXiv:2102.01356, 2021. 2
-
[7]
Brian R Bartoldson, James Diffenderfer, Konstantinos Parasyris, and Bhavya Kailkhura. Adversarial robustness limits via scaling-law and human-alignment studies.arXiv preprint arXiv:2404.09349, 2024. 8, 1, 2, 3
-
[8]
Analysis of representations for domain adapta- tion.Advances in neural information processing systems, 19, 2006
Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adapta- tion.Advances in neural information processing systems, 19, 2006. 2
2006
-
[9]
nearest neighbor
Kevin Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft. When is “nearest neighbor” meaningful? InDatabase Theory—ICDT’99: 7th International Confer- ence Jerusalem, Israel, January 10–12, 1999 Proceedings 7, pages 217–235. Springer, 1999. 2
1999
-
[10]
Adversarial attack vulnerability of medical image analysis systems: Unexplored factors.Medi- cal Image Analysis, 73:102141, 2021
Gerda Bortsova, Cristina Gonz ´alez-Gonzalo, Suzanne C Wetstein, Florian Dubost, Ioannis Katramados, Laurens Hogeweg, Bart Liefers, Bram van Ginneken, Josien PW Pluim, Mitko Veta, et al. Adversarial attack vulnerability of medical image analysis systems: Unexplored factors.Medi- cal Image Analysis, 73:102141, 2021. 2
2021
-
[11]
Distributions of angles in random packing on spheres.The Journal of Ma- chine Learning Research, 14(1):1837–1864, 2013
Tony Cai, Jianqing Fan, and Tiefeng Jiang. Distributions of angles in random packing on spheres.The Journal of Ma- chine Learning Research, 14(1):1837–1864, 2013. 4, 2
2013
-
[12]
Zoo: Zeroth order optimization based black- box attacks to deep neural networks without training substi- tute models
Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black- box attacks to deep neural networks without training substi- tute models. InProceedings of the 10th ACM workshop on artificial intelligence and security, pages 15–26, 2017. 2
2017
-
[13]
Nearest neighbor pattern clas- sification.IEEE transactions on information theory, 13(1): 21–27, 1967
Thomas Cover and Peter Hart. Nearest neighbor pattern clas- sification.IEEE transactions on information theory, 13(1): 21–27, 1967. 2
1967
-
[14]
Reliable evalua- tion of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evalua- tion of adversarial robustness with an ensemble of diverse parameter-free attacks. InICML, 2020. 1
2020
-
[15]
Minimally distorted adversarial examples with a fast adaptive boundary attack
Francesco Croce and Matthias Hein. Minimally distorted adversarial examples with a fast adaptive boundary attack. InInternational Conference on Machine Learning, pages 2196–2205. PMLR, 2020. 1
2020
-
[16]
Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670, 2020
Francesco Croce, Maksym Andriushchenko, Vikash Se- hwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670, 2020. 2, 7, 1
-
[17]
Decoupled kullback-leibler divergence loss.Advances in Neural Information Processing Systems, 37:74461–74486, 2024
Jiequan Cui, Zhuotao Tian, Zhisheng Zhong, Xiaojuan Qi, Bei Yu, and Hanwang Zhang. Decoupled kullback-leibler divergence loss.Advances in Neural Information Processing Systems, 37:74461–74486, 2024. 8, 1, 2
2024
-
[18]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2, 7
2009
-
[19]
PyTorch Lightning, 2019
William Falcon and The PyTorch Lightning team. PyTorch Lightning, 2019. 1
2019
-
[20]
Hy- brid attention-based prototypical networks for noisy few- shot relation classification
Tianyu Gao, Xu Han, Zhiyuan Liu, and Maosong Sun. Hy- brid attention-based prototypical networks for noisy few- shot relation classification. InProceedings of the AAAI con- ference on artificial intelligence, pages 6407–6414, 2019. 2
2019
-
[21]
Adaptive prototypical networks.arXiv preprint arXiv:2211.12479, 2022
Manas Gogoi, Sambhavi Tiwari, and Shekhar Verma. Adaptive prototypical networks.arXiv preprint arXiv:2211.12479, 2022. 2
-
[22]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow. Explaining and harnessing adversarial ex- amples.arXiv preprint arXiv:1412.6572, 2014. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Deepncm: Deep nearest class mean classifiers
Samantha Guerriero, Barbara Caputo, and Thomas Mensink. Deepncm: Deep nearest class mean classifiers. 2018. 2, 3
2018
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 1, 2
2016
-
[25]
Reducing the computational require- ments of the minimum-distance classifier.Remote sensing of environment, 25(1):117–128, 1988
Michael E Hodgson. Reducing the computational require- ments of the minimum-distance classifier.Remote sensing of environment, 25(1):117–128, 1988. 2
1988
-
[26]
Deep metric learning using triplet network
Elad Hoffer and Nir Ailon. Deep metric learning using triplet network. InInternational workshop on similarity-based pat- tern recognition, pages 84–92. Springer, 2015. 3
2015
-
[27]
Adversar- ial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Adversar- ial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019. 1
2019
-
[28]
Improved prototypical networks for few- shot learning.Pattern Recognition Letters, 140:81–87, 2020
Zhong Ji, Xingliang Chai, Yunlong Yu, Yanwei Pang, and Zhongfei Zhang. Improved prototypical networks for few- shot learning.Pattern Recognition Letters, 140:81–87, 2020. 2
2020
-
[29]
Las-at: adversarial training with learn- able attack strategy
Xiaojun Jia, Yong Zhang, Baoyuan Wu, Ke Ma, Jue Wang, and Xiaochun Cao. Las-at: adversarial training with learn- able attack strategy. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13398–13408, 2022. 8, 2
2022
-
[30]
Deep metric learning: A survey.Symmetry, 11(9):1066, 2019
Mahmut Kaya and Hasan S ¸akir Bilge. Deep metric learning: A survey.Symmetry, 11(9):1066, 2019. 3
2019
-
[31]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014. 1
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Cifar-10 and cifar-100 datasets.URl: https://www.cs.toronto.edu/ kriz/cifar.html, 6(1):1, 2009
Alex Krizhevsky, Vinod Nair, and Geoffrey Hin- ton. Cifar-10 and cifar-100 datasets.URl: https://www.cs.toronto.edu/ kriz/cifar.html, 6(1):1, 2009. 1, 2, 7
2009
-
[33]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry. Towards deep learning models resis- tant to adversarial attacks.arXiv preprint arXiv:1706.06083,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Supervised contrastive replay: Revisiting the nearest class mean classifier in online class-incremental continual learning
Zheda Mai, Ruiwen Li, Hyunwoo Kim, and Scott San- ner. Supervised contrastive replay: Revisiting the nearest class mean classifier in online class-incremental continual learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3589–3599,
-
[35]
Metric learning for adversarial robust- ness.Advances in neural information processing systems, 32, 2019
Chengzhi Mao, Ziyuan Zhong, Junfeng Yang, Carl V ondrick, and Baishakhi Ray. Metric learning for adversarial robust- ness.Advances in neural information processing systems, 32, 2019. 3
2019
-
[36]
Distance-based image classification: Gen- eralizing to new classes at near-zero cost.IEEE transactions on pattern analysis and machine intelligence, 35(11):2624– 2637, 2013
Thomas Mensink, Jakob Verbeek, Florent Perronnin, and Gabriela Csurka. Distance-based image classification: Gen- eralizing to new classes at near-zero cost.IEEE transactions on pattern analysis and machine intelligence, 35(11):2624– 2637, 2013. 3
2013
-
[37]
Hyper- spherical prototype networks.Advances in neural informa- tion processing systems, 32, 2019
Pascal Mettes, Elise Van der Pol, and Cees Snoek. Hyper- spherical prototype networks.Advances in neural informa- tion processing systems, 32, 2019. 2
2019
-
[38]
A sur- vey on the vulnerability of deep neural networks against ad- versarial attacks.Progress in Artificial Intelligence, 11(2): 131–141, 2022
Andy Michel, Sumit Kumar Jha, and Rickard Ewetz. A sur- vey on the vulnerability of deep neural networks against ad- versarial attacks.Progress in Artificial Intelligence, 11(2): 131–141, 2022. 2
2022
-
[39]
When adversarial training meets vision trans- formers: Recipes from training to architecture.Advances in Neural Information Processing Systems, 35:18599–18611,
Yichuan Mo, Dongxian Wu, Yifei Wang, Yiwen Guo, and Yisen Wang. When adversarial training meets vision trans- formers: Recipes from training to architecture.Advances in Neural Information Processing Systems, 35:18599–18611,
-
[40]
A met- ric learning reality check
Kevin Musgrave, Serge Belongie, and Ser-Nam Lim. A met- ric learning reality check. InEuropean Conference on Com- puter Vision, pages 681–699. Springer, 2020. 3
2020
-
[41]
Transferrable prototypical networks for unsupervised domain adaptation
Yingwei Pan, Ting Yao, Yehao Li, Yu Wang, Chong-Wah Ngo, and Tao Mei. Transferrable prototypical networks for unsupervised domain adaptation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2239–2247, 2019. 2
2019
-
[42]
High-dimensional probability: An introduction with applications in data science, 2020
Omiros Papaspiliopoulos. High-dimensional probability: An introduction with applications in data science, 2020. 4
2020
-
[43]
Practi- cal black-box attacks against machine learning
Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. Practi- cal black-box attacks against machine learning. InProceed- ings of the 2017 ACM on Asia conference on computer and communications security, pages 506–519, 2017. 2
2017
-
[44]
Continual lifelong learning with neural networks: A review.Neural networks, 113:54–71,
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural networks, 113:54–71,
-
[45]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zem- ing Lin, Natalia Gimelshein, Luca Antiga, Alban Desmai- son, Andreas Kopf, Edward Yang, Zachary DeVito, Mar- tin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high...
2019
-
[46]
An embarrass- ingly simple approach to zero-shot learning
Bernardino Romera-Paredes and Philip Torr. An embarrass- ingly simple approach to zero-shot learning. InInternational conference on machine learning, pages 2152–2161. PMLR,
-
[47]
Facenet: A unified embedding for face recognition and clus- tering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clus- tering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015. 3
2015
-
[48]
Revisiting adversarial training for imagenet: Architectures, training and generalization across threat models.Advances in Neural Information Processing Systems, 36:13931–13955,
Naman Deep Singh, Francesco Croce, and Matthias Hein. Revisiting adversarial training for imagenet: Architectures, training and generalization across threat models.Advances in Neural Information Processing Systems, 36:13931–13955,
-
[49]
Prototypical networks for few-shot learning.Advances in neural informa- tion processing systems, 30, 2017
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning.Advances in neural informa- tion processing systems, 30, 2017. 2
2017
-
[50]
Intriguing properties of neural networks
C Szegedy. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013. 2
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[51]
Robustness may be at odds with accuracy
Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy. InInternational Conference on Learning Representations, number 2019, 2019. 1
2019
-
[52]
Matching networks for one shot learning.Ad- vances in neural information processing systems, 29, 2016
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning.Ad- vances in neural information processing systems, 29, 2016. 2
2016
-
[53]
Visual recognition with deep nearest centroids.arXiv preprint arXiv:2209.07383, 2022
Wenguan Wang, Cheng Han, Tianfei Zhou, and Dongfang Liu. Visual recognition with deep nearest centroids.arXiv preprint arXiv:2209.07383, 2022. 2, 3
-
[54]
Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (csur), 53(3):1–34, 2020
Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (csur), 53(3):1–34, 2020. 2
2020
-
[55]
Better diffusion models further improve adversarial training
Zekai Wang, Tianyu Pang, Chao Du, Min Lin, Weiwei Liu, and Shuicheng Yan. Better diffusion models further improve adversarial training. InInternational Conference on Machine Learning, pages 36246–36263. PMLR, 2023. 8, 2
2023
-
[56]
John Wiley & Sons, 2003
Andrew R Webb.Statistical pattern recognition. John Wiley & Sons, 2003. 2
2003
-
[57]
Distance met- ric learning for large margin nearest neighbor classification
Kilian Q Weinberger and Lawrence K Saul. Distance met- ric learning for large margin nearest neighbor classification. Journal of machine learning research, 10(2), 2009. 3
2009
-
[58]
arXiv preprint arXiv:2312.04960 , year=
Xiaoyun Xu, Shujian Yu, Zhuoran Liu, and Stjepan Picek. Mimir: Masked image modeling for mutual information-based adversarial robustness.arXiv preprint arXiv:2312.04960, 2023. 8, 2 Sensitivity as a Double-Edged Sword: A Trade-off Between Discriminability and Adversarial Robustness Supplementary Material
-
[59]
Implementation Details 6.1. Environments Our project is implemented entirely in Python using PyTorch [45] and PyTorch-Lightning [19], with all experiments con- ducted on a Linux server equipped with a single GPU. The versions and models of key software and hardware are summarized in Tab. 4. Component Version / Model SystemUbuntu 22.04 LTS Python3.12.2 PyT...
-
[60]
1 and Eq
Proof of Classifier Sensitivity We define the sensitivity of FC and DB classifiers in Eq. 1 and Eq. 2 of our main paper, reflecting how significantly the model’s predictions change in response to variations in the input feature representations. We first derive the supremum ofSd in Eq. 5 of the main paper. The proof of this result is simply as follows: Sd ...
-
[61]
First, we evaluate our model by fine-tuning pretrained models from existing works
Limitations and Future Work There are still several limitations in this work. First, we evaluate our model by fine-tuning pretrained models from existing works. However, since the fine-tuning setup may differ significantly from the original training configurations (e.g., train- ing objectives, data augmentations), extensive fine-tuning could lead to overf...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.