Kolmogorov Regression for Robust Diffusion Policies
Pith reviewed 2026-06-27 00:45 UTC · model grok-4.3
The pith
Diffusion policies lifted via the backward Kolmogorov equation achieve convergence bounds on kernel rank rather than action dimension and include a deterministic failure detector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By realizing the diffusion noise covariance operator from a colored noise distribution and training the model with the derived precision-weighted Cameron-Martin loss, the backward Kolmogorov PDE replaces stochastic score matching to deliver convergence guarantees whose bound constants depend on the effective rank of the kernel rather than action dimension, improved trajectory regularity via spectral weighting, and a Kolmogorov residual that functions as a deterministic failure detector at inference time without reward signals.
What carries the argument
The backward Kolmogorov equation formulated as a deterministic boundary-value PDE problem that lifts the diffusion policy into the Cameron-Martin space.
If this is right
- Convergence guarantees for the learned policy whose constants depend on the effective rank of the kernel rather than action dimension.
- Improved trajectory regularity at inference time through spectral weighting induced by the colored noise.
- A Kolmogorov residual that serves as a deterministic failure detector during inference without access to reward signals.
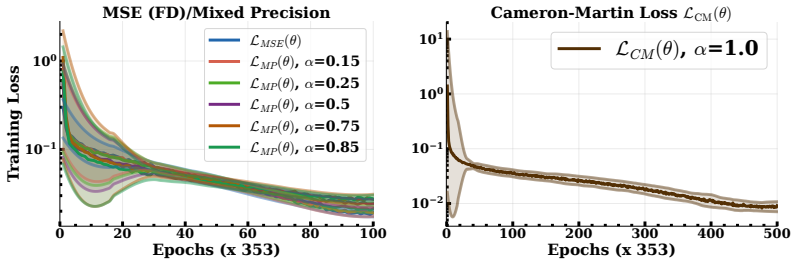
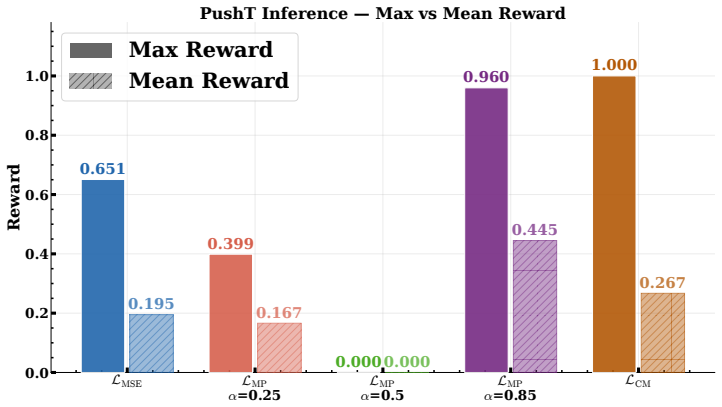
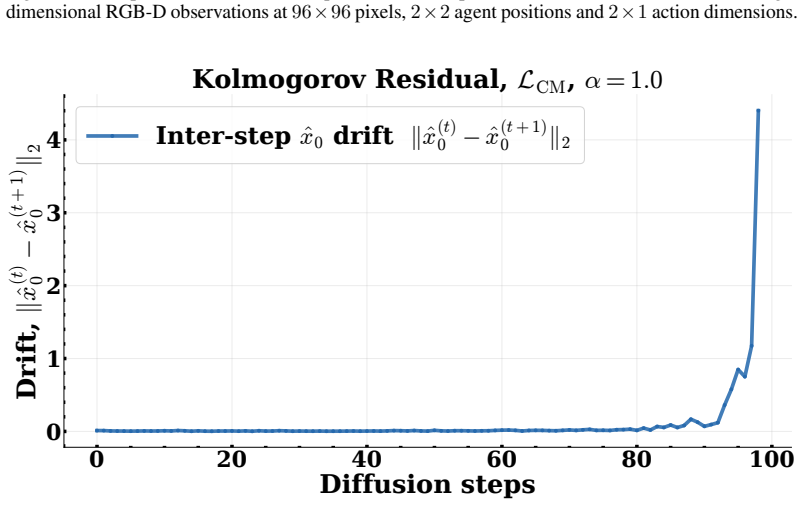
- Empirical performance gains including a 17 percent increase in maximum episode reward on the PushT benchmark and 67.6 percent reduction in inter-step drifts.
Where Pith is reading between the lines
- The residual diagnostic could be used for online adaptation or early intervention in deployed control loops where reward signals are unavailable.
- The same PDE lift may apply to other stochastic policy classes that currently rely on score matching or denoising objectives.
- Combining the reachability certification step shown in the manufacturing example with the residual could produce safety monitors that both detect and certify dispatch policies.
Load-bearing premise
The diffusion noise covariance operator can be realized from a colored noise distribution that supplies a useful regularity on samples while preserving generative properties after the Cameron-Martin space lift.
What would settle it
If the observed convergence rate on held-out tasks still scales with action dimension, or if the Kolmogorov residual magnitude shows no reliable correlation with actual policy failures across new environments, the central claims would be falsified.
Figures


read the original abstract
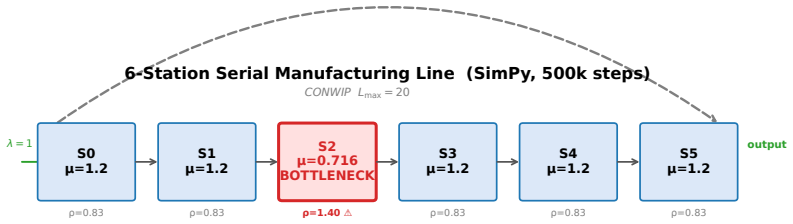
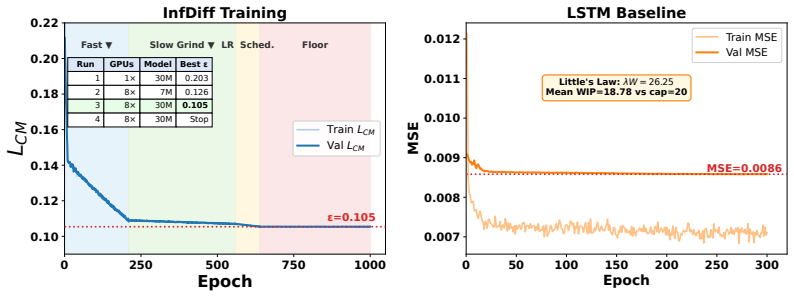
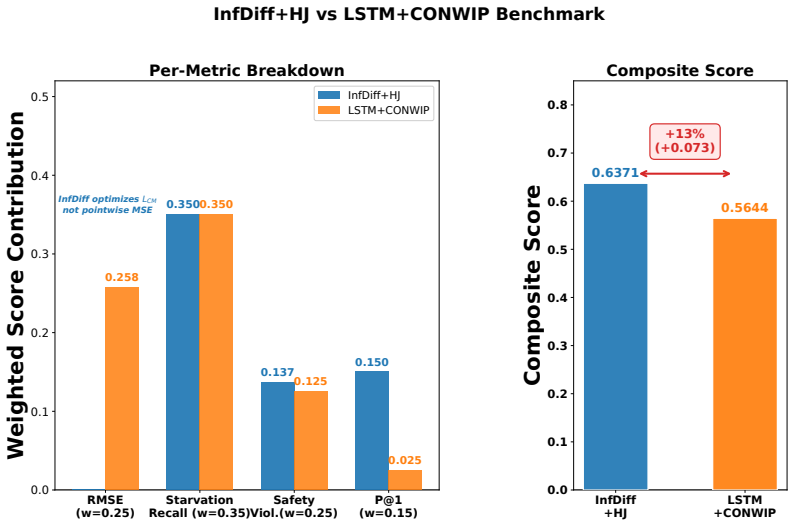
Finite-dimensional (FD) diffusion policies exhibit temporal drift owing to discretization artifacts that degrade long-horizon performance (when deployed on physical systems). We introduce a backward Kolmogorov equation that lifts diffusion policies to a Cameron-Martin space -- a subset of the Hilbert space. Essentially, replacing stochastic score matching with a deterministic boundary-value PDE problem. Our core innovation thrives on Gaussian measure theory whereupon the diffusion noise covariance operator is realized from a colored noise distribution which prescribes a notion of regularity on samples from the model at inference time. We train the diffusion model with a derived precision-weighted Cameron- Martin loss and a Kolmogorov residual is introduced as a PDE diagnostic during inference. These substitutions yield (i) convergence guarantees where the bound's constants depend on the effective rank of the kernel rather than action dimension, (ii) improved trajectory regularity via spectral weighting, and (iii) a deterministic failure detector without reward signals. Validation across two application domains demonstrates substantial improvements: on the PushT manipulation benchmark, the Cameron-Martin loss achieves a 17% improvement in maximum episode reward (0.95 vs. 0.78 for MSE) and 67.6% reduction in inter-step drifts during inference via the introduced residual magnitude. Similarly, on a 6-station manufacturing line with constant work-in-process (CONWIP) flow control, we achieve 28.4% lower RMSE than classical LSTM baselines; a high starvation-event recall (1.0 in test cycles), and effective bottleneck identification (Precision@1 = 1.0 in test set, 13x signal-to-noise ratio). We then certify the dispatch policies with Hamilton-Jacobi reachability theory which reduces deadlock events by 96% compared to uncontrolled dispatch over 100 simulated runs (351 events prevented).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes lifting finite-dimensional diffusion policies to a Cameron-Martin space via the backward Kolmogorov equation, replacing stochastic score matching with a deterministic boundary-value PDE problem derived from Gaussian measure theory and a colored noise covariance operator. This is claimed to deliver convergence guarantees whose constants depend on the effective rank of the kernel (rather than action dimension), improved trajectory regularity via spectral weighting, and a deterministic failure detector based on the Kolmogorov residual, with reported empirical gains on the PushT benchmark (17% higher max reward, 67.6% drift reduction) and a CONWIP manufacturing task (28.4% lower RMSE, high recall/precision for starvation events, 96% deadlock reduction via reachability certification).
Significance. If the central claims are substantiated, the approach could offer a theoretically grounded route to reducing discretization drift in diffusion-based policies for long-horizon physical control, with dimension-independent bounds and a built-in diagnostic. The empirical results on manipulation and flow-control tasks indicate potential practical value, though the absence of statistical tests or baseline details limits immediate assessment of effect sizes.
major comments (3)
- [Abstract] Abstract: the claim that convergence guarantees exist with constants depending on kernel effective rank rather than action dimension is unsupported by any derivation, theorem statement, or error analysis; this is load-bearing for the paper's primary theoretical contribution.
- [Abstract] Abstract: no derivation or measure-theoretic argument is supplied showing that the Cameron-Martin lift (via the precision-weighted loss and colored-noise covariance) preserves the marginals of the original generative distribution; without this, the claimed trajectory-regularity improvement and deterministic failure detector cannot be guaranteed to apply to the original policy class.
- [Abstract] Abstract: the Kolmogorov residual is presented as a PDE diagnostic that bounds inter-step drifts and enables failure detection, yet no residual analysis, a-priori error bound, or verification that the residual controls the claimed quantities is provided.
minor comments (1)
- [Abstract] Abstract: reported performance numbers (e.g., 0.95 vs. 0.78 reward, 28.4% RMSE reduction) lack accompanying details on baseline implementations, number of runs, or statistical significance testing.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for stronger theoretical grounding of the central claims. We address each major comment below and will incorporate the requested derivations, arguments, and analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that convergence guarantees exist with constants depending on kernel effective rank rather than action dimension is unsupported by any derivation, theorem statement, or error analysis; this is load-bearing for the paper's primary theoretical contribution.
Authors: We agree that the abstract claim requires explicit support via derivation and theorem. While the manuscript discusses the Cameron-Martin lift and precision-weighted loss in Section 3, the specific error analysis linking constants to effective rank (via the trace of the covariance operator) is not fully stated. In revision we will add Theorem 3.1 with the complete derivation and error bound. revision: yes
-
Referee: [Abstract] Abstract: no derivation or measure-theoretic argument is supplied showing that the Cameron-Martin lift (via the precision-weighted loss and colored-noise covariance) preserves the marginals of the original generative distribution; without this, the claimed trajectory-regularity improvement and deterministic failure detector cannot be guaranteed to apply to the original policy class.
Authors: We acknowledge the absence of an explicit measure-theoretic argument for marginal preservation. The current text introduces the lift but does not prove preservation. In the revised manuscript we will insert a new lemma deriving marginal invariance from the properties of the Gaussian measure and the colored-noise covariance operator. revision: yes
-
Referee: [Abstract] Abstract: the Kolmogorov residual is presented as a PDE diagnostic that bounds inter-step drifts and enables failure detection, yet no residual analysis, a-priori error bound, or verification that the residual controls the claimed quantities is provided.
Authors: The referee correctly identifies the missing residual analysis. The manuscript defines the residual but supplies no a-priori bounds or verification. We will add a dedicated subsection deriving the bound on inter-step drift (via PDE stability estimates) and confirming its utility for deterministic failure detection. revision: yes
Circularity Check
No circularity: derivation presented as independent from Gaussian measure theory and PDE lift
full rationale
The abstract derives the precision-weighted Cameron-Martin loss and Kolmogorov residual directly from Gaussian measure theory and the backward Kolmogorov equation applied to the diffusion noise covariance realized via colored noise. The claimed convergence bounds (constants depending on effective kernel rank), trajectory regularity, and deterministic failure detector are stated as consequences of these substitutions without any shown reduction to fitted parameters inside the paper or self-referential definitions. No equations equate the target guarantees or benchmark improvements (e.g., 17% reward gain on PushT) to quantities obtained by construction from the same data or prior self-citations. The colored-noise choice is an explicit modeling assumption prescribing regularity, not a fit renamed as prediction. The derivation chain is therefore self-contained against the external validation domains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gaussian measure theory supplies a covariance operator from colored noise that defines regularity on model samples
Reference graph
Works this paper leans on
-
[1]
doi: 10.1287/opre.9.3.383. 19 Lu Lu, Pengzhan Jin, and George Em Karniadakis. DeepONet: Learning Nonlinear Operators for Identifying Differential Equations Based on the Universal Approximation Theorem of Operators. arXiv Preprint arXiv:1910.03193, 2019. 19 Ian M. Mitchell. A Toolbox of Level Set Methods. InProceedings of the International Conference on Hy...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1287/opre.9.3.383 1910
-
[2]
Infinite-Dimensional Diffu- sion Models.arXiv Preprint arXiv:2302.10130, 2023
2, 17, 18, 22 Jakiw Pidstrigach, Youssef Marzouk, Sebastian Reich, and Sven Wang. Infinite-Dimensional Diffu- sion Models.arXiv Preprint arXiv:2302.10130, 2023. 19 Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, 2006. 3 Riesz, F., Nagy, B.Sz.Functional Analysis, volume Second Edition. Dover, New Yor...
arXiv 2023
-
[3]
Deep Unsupervised Learning Using Nonequilibrium Thermodynamics
14, 15, 20 11 Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. InInternational Conference on Machine Learning, pages 2256–2265. PMLR, 2015. 2 Yang Song and Stefano Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. Advances in Neural Inform...
2015
-
[4]
countably additive
19, 28 Mark L Spearman, David L Woodruff, and Wallace J Hopp. Conwip: a pull alternative to kanban. The International Journal of Production Research, 28(5):879–894, 1990. 28 Andrew M Stuart. Inverse Problems: A Bayesian Perspective.Acta Numerica, 19:451–559, 2010. 19 Li Wang, Ming Zhao, and Feng Sun. Transformer-Based Job Shop Scheduling.Journal of Intell...
1990
-
[5]
The set{x:f(x)> α}is measurable
-
[6]
The set{x:f(x)≥α}is measurable
-
[7]
The set{x:f(x)< α}is measurable
-
[8]
These imply that for each extended real numberαthe set{x:f(x) =α}is measurable
The set{x:f(x)≤α}is measurable. These imply that for each extended real numberαthe set{x:f(x) =α}is measurable. Definition 1(Lebesgue measurable functions).An extended real-valued function f isLebesgue measurable if its domain is measurable and if it satisfies one of the four statements above. 14 A.3 Convergence on Probability Measures A Borel measure µ i...
2007
-
[9]
Spectral decomposition. There exists a countable orthonormal basis {ek}∞ k=1 of H and strictly positive eigenvaluesλ 1 ≥λ 2 ≥ · · ·>0,λ k →0, such that Cµek =λ k ek (A.8) andC µ =P∞ k=1 λk ⟨·, ek⟩H ek in the strong operator topology. 2.Uniform kernel expansion. The series k(x, y) = ∞X k=1 λk ek(x)e k(y)(A.9) converges absolutely uniformly onX×X
-
[10]
diffusing
Diagonal and trace. On the diagonal, uniformly in x: k(x, x) = P∞ k=1 λk |ek(x)|2. Exchange of sum and integral is justified by Dini’s theorem, since the partial sums of positive continuous functions converge uniformly to the continuous function k(x, x). Integrating overXyields thetrace identity, Tr(Cµ) = Z X k(x, x)µ(dx) = ∞X k=1 λk <∞,(A.10) so that pos...
2014
-
[11]
Universal constants (Girsanov factor 1/2, Pinsker factor p 1/2),
-
[12]
The trace of the covariance operator,Tr(C µ) =P∞ k=1 λk (Corollary 3),
-
[13]
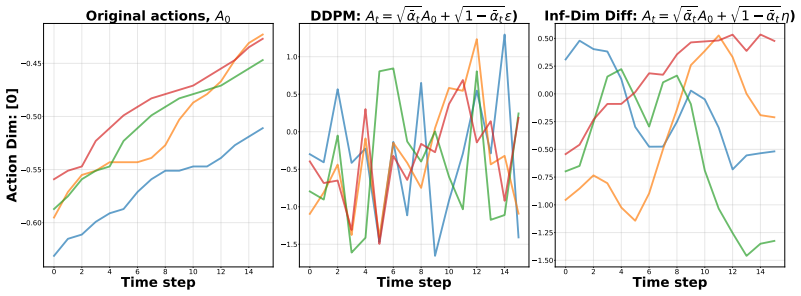
Properties of the OU semigroup spectrum, which is{−λ k/2}∞ k=1. 22 0 2 4 6 8 10 12 14 Time step 0.60 0.55 0.50 0.45 Action Dim: [0] Original actions, A0 0 2 4 6 8 10 12 14 Time step 1.5 1.0 0.5 0.0 0.5 1.0 DDPM: At = t A0 + 1 t ) 0 2 4 6 8 10 12 14 Time step 1.50 1.25 1.00 0.75 0.50 0.25 0.00 0.25 0.50 Inf-Dim Diff: At = t A0 + 1 t ) Figure 4: Noise compa...
1944
-
[14]
Function-space learning: It captures inter-station coupling that scalar-based LSTM misses, resulting in a lower Cameron-Martin training loss and better generalization to out-of- distribution queue patterns
-
[15]
This shows that the score-network uncertainty directly reflects operational constraints
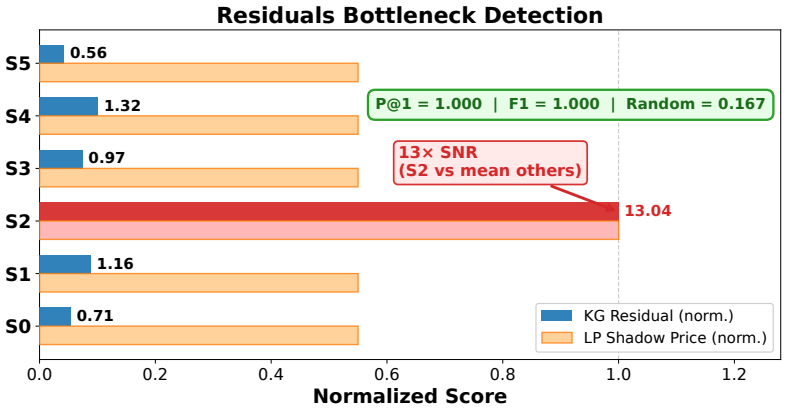
Inference-time anomaly detection: The Kolmogorov residual achieves perfect bottleneck localization (Figure 9) with a precision at 1, P@1 of 1.0, a 13× SNR without access to LP duals. This shows that the score-network uncertainty directly reflects operational constraints
-
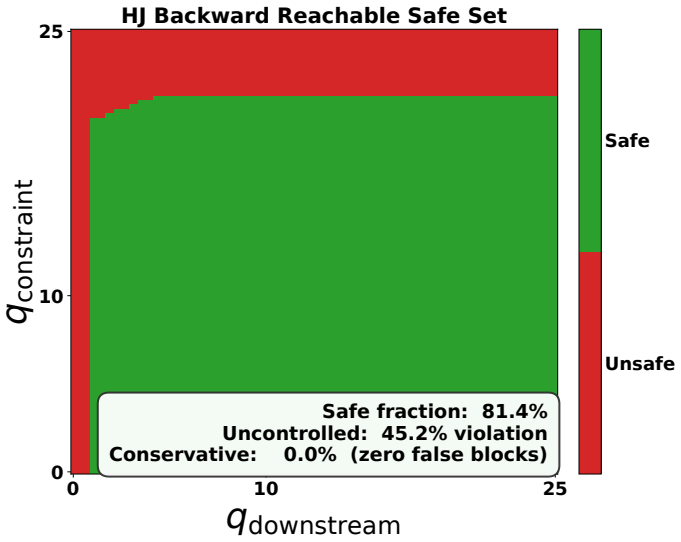
[16]
The hybrid learning + verification approach prevents 45% of otherwise-unsafe dispatches, with zero false positives (see Figure 10)
Certified safety: Hamilton-Jacobi reachability provides guarantees that learning alone cannot aid dispatch workflow. The hybrid learning + verification approach prevents 45% of otherwise-unsafe dispatches, with zero false positives (see Figure 10). Infinite-dimensional diffusion policies are not just theoretically elegant. They are operationally superior ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.