SkelDPO: A Skeleton-Guided Direct Preference Optimization Framework for Efficient Code Generation
Pith reviewed 2026-06-27 21:39 UTC · model grok-4.3
The pith
SkelDPO aligns code models to efficiency skeletons by comparing efficient and inefficient implementations and applying a joint preference loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
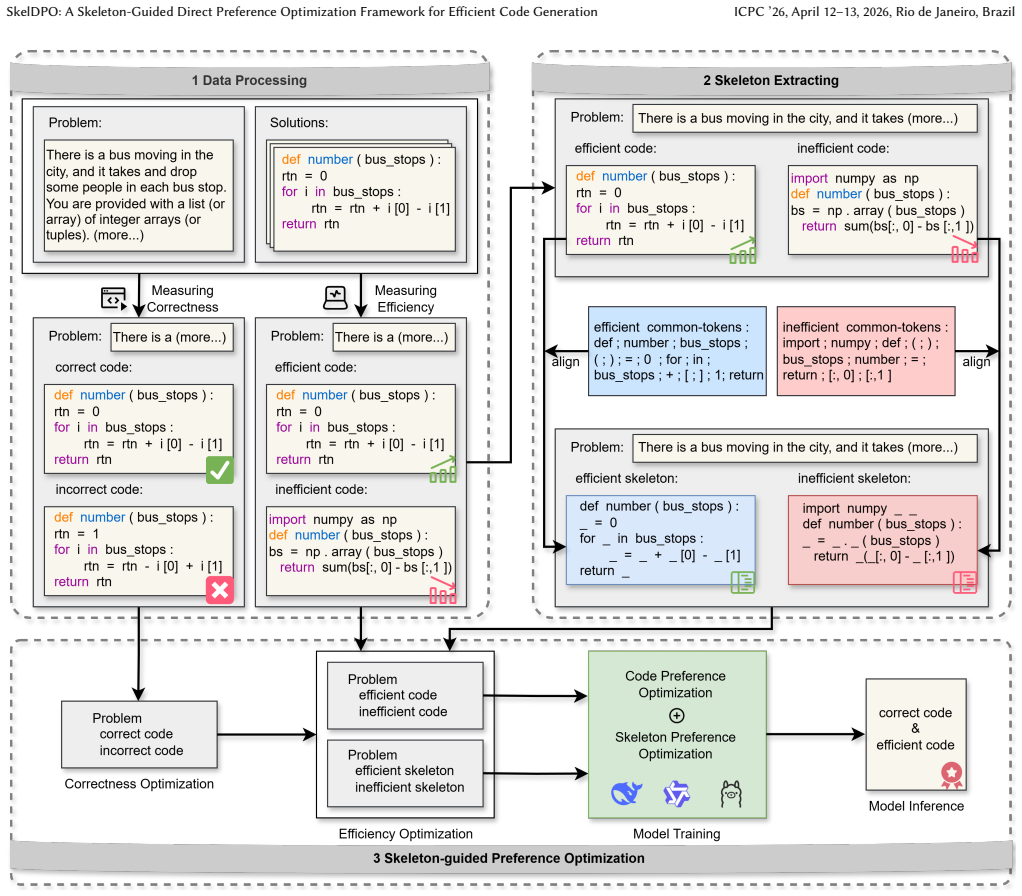
SkelDPO first identifies efficient and inefficient implementations from the code dataset and, through comparative analysis, locates their efficiency-prone and inefficiency-prone points, forming alignment signals between efficiency and inefficiency skeletons. During training, a joint code and skeleton preference loss is introduced, enabling the model to learn semantic correctness while reinforcing its understanding of efficiency-critical components in code.
What carries the argument
The joint code and skeleton preference loss that trains on alignment signals extracted from efficiency-prone and inefficiency-prone points identified by comparative analysis of code pairs.
Load-bearing premise
Comparing efficient and inefficient code versions can reliably identify the exact structural skeleton points that drive efficiency differences and supply usable training signals.
What would settle it
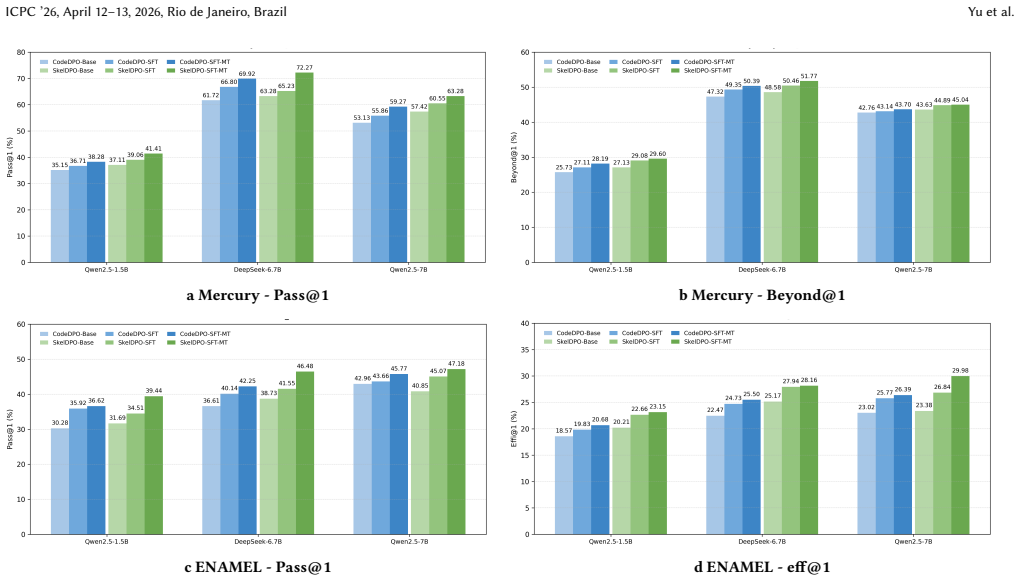
An ablation that removes the skeleton alignment signals from SkelDPO training and measures whether the reported 3-6% gains in Pass@1, Beyond@1, and Effi@1 still appear on the same evaluation tasks.
Figures


read the original abstract
With the remarkable progress of Code Large Language Models (Code LLMs) in achieving semantic correctness, execution efficiency has become an increasingly important dimension for evaluating their practical utility. However, existing approaches typically treat full programs as a single optimization target during training, without explicitly modeling the structural factors that influence efficiency. As a result, although these models can generate semantically correct code, they fail to learn, at a fine-grained level, the underlying skeleton features that lead to efficient implementations. To address this limitation, we propose SkelDPO (Skeleton-Guided Direct Preference Optimization), a skeleton-guided preference optimization framework that systematically enhances the efficiency of code generation. SkelDPO first identifies efficient and inefficient implementations from the code dataset and, through comparative analysis, locates their efficiency-prone and inefficiency-prone points, forming alignment signals between efficiency and inefficiency skeletons. During training, a joint code and skeleton preference loss is introduced, enabling the model to learn semantic correctness while reinforcing its understanding of efficiency-critical components in code. Results show that SkelDPO consistently surpasses existing methods: compared with SOTA method that relies solely on efficient and inefficient code preference optimization, it improves Pass@1, Beyond@1, and Effi@1 by 3-6%, 3-7%, and 2-5%, with greater improvements observed on complex tasks. Overall, SkelDPO provides a new perspective on skeleton-level efficiency alignment, breaking the limitation of conventional preference optimization that relies solely on correctness or efficiency pairs. All datasets and source code are publicly available at: https://github.com/icpcSkelDPO/SkelDPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkelDPO, a skeleton-guided direct preference optimization framework for Code LLMs that aims to improve execution efficiency. It identifies efficient/inefficient code pairs from datasets, uses comparative analysis to extract efficiency-prone and inefficiency-prone skeleton signals, and applies a joint code+skeleton preference loss during training. The central empirical claim is that SkelDPO outperforms SOTA efficiency-focused DPO baselines by 3-6% on Pass@1, 3-7% on Beyond@1, and 2-5% on Effi@1, with larger gains on complex tasks. Datasets and code are released publicly.
Significance. If the reported gains are robust, the work supplies a concrete extension of DPO that operates at the skeleton level rather than whole-program pairs, addressing a gap between semantic correctness and fine-grained efficiency in code generation. Public release of data and code is a clear reproducibility strength.
major comments (2)
- [Experimental results / §5 (or equivalent)] The abstract and method description supply no information on experimental design, baseline selection, skeleton extraction procedure, statistical tests, or potential confounds (e.g., dataset construction or prompt complexity). This absence makes it impossible to assess whether the claimed 3-6% Pass@1 gains are supported by the data; the central performance claim therefore cannot be evaluated from the provided material.
- [Method / §3.2 (skeleton signal formation)] The assumption that comparative analysis of efficient/inefficient pairs reliably isolates efficiency-prone skeleton points usable as alignment signals is stated but not validated or ablated. Without evidence that these signals are not artifacts of the pair selection process, the joint loss contribution to the reported gains remains unverified.
minor comments (2)
- [Method] Notation for the joint loss (code vs. skeleton terms) should be defined explicitly with equation numbers for clarity.
- [Evaluation metrics] The paper should clarify the precise definitions of Beyond@1 and Effi@1 metrics, including any thresholds or aggregation rules.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, providing clarifications from the full manuscript and indicating where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [Experimental results / §5 (or equivalent)] The abstract and method description supply no information on experimental design, baseline selection, skeleton extraction procedure, statistical tests, or potential confounds (e.g., dataset construction or prompt complexity). This absence makes it impossible to assess whether the claimed 3-6% Pass@1 gains are supported by the data; the central performance claim therefore cannot be evaluated from the provided material.
Authors: The full manuscript includes Section 4 (Experimental Setup) and Section 5 (Results) that detail the experimental design, including baseline selection (comparing against standard DPO and other efficiency-focused methods), datasets (publicly released), evaluation metrics (Pass@1, Beyond@1, Effi@1), and skeleton extraction in Section 3.2. We did not include statistical significance tests in the original submission, which is a limitation we acknowledge. We will revise the method section to explicitly describe the skeleton extraction procedure, dataset construction process, and potential confounds such as prompt complexity. This will make the support for the performance claims clearer. revision: yes
-
Referee: [Method / §3.2 (skeleton signal formation)] The assumption that comparative analysis of efficient/inefficient pairs reliably isolates efficiency-prone skeleton points usable as alignment signals is stated but not validated or ablated. Without evidence that these signals are not artifacts of the pair selection process, the joint loss contribution to the reported gains remains unverified.
Authors: Section 3.2 describes the comparative analysis process for identifying efficiency-prone and inefficiency-prone skeleton points. To address potential artifacts from pair selection, the manuscript includes ablation studies in Section 5.3 that isolate the contribution of the skeleton-guided loss, showing performance degradation when removed. This provides evidence that the signals contribute to the gains. We agree that additional validation, such as sensitivity analysis on pair selection, would strengthen the claim and will add this in the revised manuscript. revision: partial
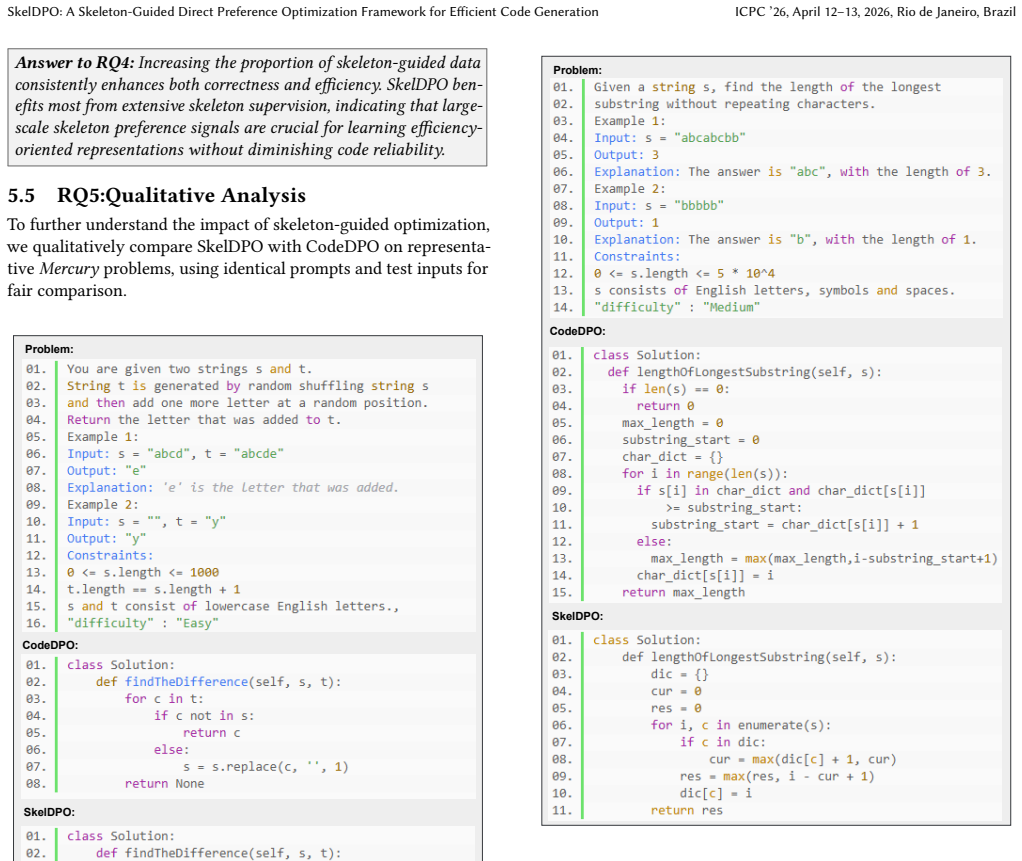
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes SkelDPO as a direct extension of standard DPO: it identifies efficient/inefficient code pairs from data, extracts skeleton signals via comparative analysis, and applies a joint code+skeleton preference loss. This pipeline is presented as a methodological addition without any equations or steps that reduce by construction to fitted parameters, self-citations, or renamed inputs. No load-bearing uniqueness theorems, ansatzes smuggled via prior work, or self-definitional loops are present. The reported gains (3-6% etc.) are empirical outcomes on held-out tasks, not predictions forced by the training procedure itself. The public code link further supports independent verification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Toufique Ahmed, Kunal Suresh Pai, Premkumar Devanbu, and Earl Barr. 2024. Automatic semantic augmentation of language model prompts (for code summa- rization). InProceedings of the IEEE/ACM 46th international conference on software engineering. 1–13
2024
-
[3]
2025.Welcome to Claude 4: Your Partner in AI Innovation
Anthropic. 2025.Welcome to Claude 4: Your Partner in AI Innovation. https: //claude4.org/
2025
-
[4]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [5]
- [6]
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Tristan Coignion, Clément Quinton, and Romain Rouvoy. 2024. A performance study of llm-generated code on leetcode. InProceedings of the 28th international conference on evaluation and assessment in software engineering. 79–89
2024
-
[9]
Mingzhe Du, Anh Tuan Luu, Bin Ji, Qian Liu, and See-Kiong Ng. 2024. Mercury: A code efficiency benchmark for code large language models.Advances in Neural Information Processing Systems37 (2024), 16601–16622
2024
- [10]
-
[11]
Xiaoning Feng, Xiaohong Han, Simin Chen, and Wei Yang. 2024. Llmeffichecker: Understanding and testing efficiency degradation of large language models.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 1–38
2024
-
[12]
Shuzheng Gao, Cuiyun Gao, Wenchao Gu, and Michael Lyu. 2024. Search-based llms for code optimization. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 254–266
2024
- [13]
-
[14]
Qiuhan Gu. 2023. Llm-based code generation method for golang compiler testing. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2201–2203
2023
-
[15]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence.arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Mea- suring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Dong Huang, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao Qing, Heming Cui, Zhijiang Guo, and Jie Zhang. 2024. Effilearner: Enhancing efficiency of generated code via self-optimization.Advances in Neural Information Processing Systems37 (2024), 84482–84522
2024
-
[19]
Dong Huang, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao Qing, Jie M Zhang, Heming Cui, and Zhijiang Guo. 2024. SOAP: enhancing efficiency of generated code via self-optimization.arXiv e-prints(2024), arXiv–2405
2024
-
[20]
Dong Huang, Guangtao Zeng, Jianbo Dai, Meng Luo, Han Weng, Yuhao QING, Heming Cui, Zhijiang Guo, and Jie Zhang. 2025. EffiCoder: Enhancing Code Generation in Large Language Models through Efficiency-Aware Fine-tuning. In Forty-second International Conference on Machine Learning
2025
-
[21]
Tao Huang, Zhihong Sun, Zhi Jin, Ge Li, and Chen Lyu. 2024. Knowledge-aware code generation with large language models. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 52–63
2024
-
[22]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, et al. 2024. Qwen2.5-Coder Technical Report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. GPT-4o System Card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation.arXiv preprint arXiv:2406.00515(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [27]
-
[28]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy- Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
-
[30]
Changan Niu, Ting Zhang, Chuanyi Li, Bin Luo, and Vincent Ng. 2024. On evaluating the efficiency of source code generated by llms. InProceedings of the 2024 IEEE/ACM First International Conference on AI Foundation Models and Software Engineering. 103–107
2024
-
[31]
Indraneil Paul, Haoyi Yang, Goran Glavaš, Kristian Kersting, and Iryna Gurevych
- [32]
-
[33]
Huiyun Peng, Arjun Gupte, Nicholas John Eliopoulos, Chien Chou Ho, Rishi Mantri, Leo Deng, Wenxin Jiang, Yung-Hsiang Lu, Konstantin Läufer, George K Thiruvathukal, et al. 2024. Large Language Models for Energy-Efficient Code: Emerging Results and Future Directions.arXiv preprint arXiv:2410.09241(2024)
-
[34]
Yun Peng, Jun Wan, Yichen Li, and Xiaoxue Ren. 2025. Coffe: A code efficiency benchmark for code generation.Proceedings of the ACM on Software Engineering 2, FSE (2025), 242–265
2025
- [35]
-
[36]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Jieke Shi, Zhou Yang, and David Lo. 2024. Efficient and green large language models for software engineering: Vision and the road ahead.ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[38]
Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, and Amir Yazdanbakhsh. 2024. Learning Performance-Improving Code Edits. InProceedings of the 12th International Conference on Learning Representations (ICLR)
2024
-
[39]
Zhihong Sun, Chen Lyu, Bolun Li, Yao Wan, Hongyu Zhang, Ge Li, and Zhi Jin
-
[40]
InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)
Enhancing Code Generation Performance of Smaller Models by Distilling the Reasoning Ability of LLMs. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 5878–5895
2024
-
[41]
Zhihong Sun, Yao Wan, Jia Li, Hongyu Zhang, Zhi Jin, Ge Li, and Chen Lyu
-
[42]
InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering
Sifting through the chaff: On utilizing execution feedback for ranking the generated code candidates. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 229–241
-
[43]
Siddhant Waghjale, Vishruth Veerendranath, Zhiruo Wang, and Daniel Fried
-
[44]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
ECCO: Can We Improve Model-Generated Code Efficiency Without Sacri- ficing Functional Correctness?. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 15362–15376
2024
-
[45]
Chong Wang, Jian Zhang, Yebo Feng, Tianlin Li, Weisong Sun, Yang Liu, and Xin Peng. 2025. Teaching code llms to use autocompletion tools in repository-level code generation.ACM Transactions on Software Engineering and Methodology34, 7 (2025), 1–27
2025
-
[46]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Under- standing and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 8696–8708. ICPC ’26, April 12–13, 2026, Rio de Janeiro, Brazil Yu et al
2021
- [47]
-
[48]
Man Fai Wong and Chee Wei Tan. 2024. Aligning crowd-sourced human feedback for reinforcement learning on code generation by large language models.IEEE Transactions on Big Data(2024)
2024
- [49]
-
[50]
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, and Ge Li. 2024. Exploring and unleashing the power of large language models in automated code translation.Proceedings of the ACM on Software Engineering1, FSE (2024), 1585–1608
2024
-
[51]
Tong Ye, Yangkai Du, Tengfei Ma, Lingfei Wu, Xuhong Zhang, Shouling Ji, and Wenhai Wang. 2025. Uncovering llm-generated code: A zero-shot synthetic code detector via code rewriting. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 968–976
2025
- [52]
- [53]
- [54]
-
[55]
Lei Zhang, Yunshui Li, Jiaming Li, Xiaobo Xia, Jiaxi Yang, Run Luo, Minzheng Wang, Longze Chen, Junhao Liu, Qiang Qu, et al . 2025. Hierarchical context pruning: Optimizing real-world code completion with repository-level pretrained code llms. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25886–25894
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.