Aligned but Fragile: Enhancing LLM Safety Robustness via Zeroth-Order Optimization
Pith reviewed 2026-06-29 07:39 UTC · model grok-4.3
The pith
Zeroth-order refinement after standard alignment strengthens LLM safety against perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
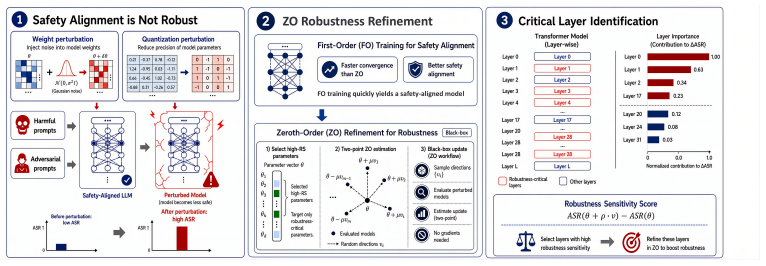
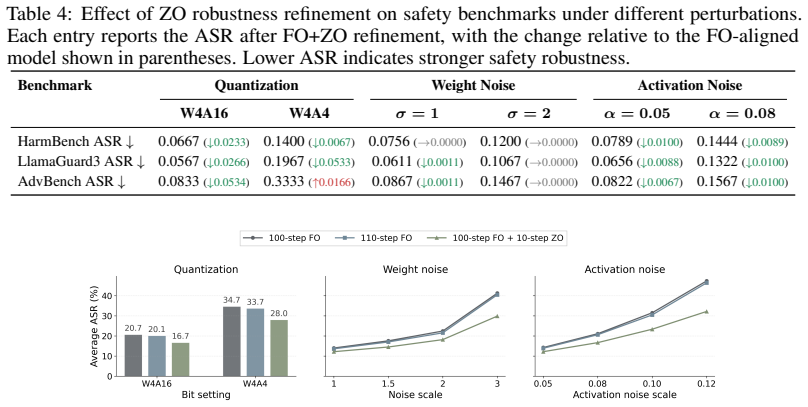
A hybrid procedure that performs standard first-order safety alignment followed by a small number of zeroth-order refinement steps produces models whose safety behavior resists degradation from parameter noise, activation noise, and quantization while preserving alignment quality.
What carries the argument
Zeroth-order optimization used as a post-alignment refinement stage that evaluates safety alignment directly under input and parameter perturbations to generate a robustness-oriented update signal.
If this is right
- Only a few zeroth-order steps suffice to increase robustness without additional data curation.
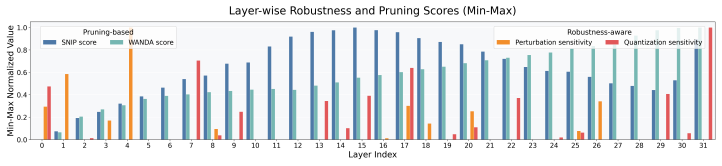
- Layer-wise sensitivity estimates derived from the same perturbations allow the refinement to focus on critical layers and keep compute cost modest.
- The resulting models retain general utility because the refinement stage is short and does not overwrite the first-order alignment.
- The approach applies after any existing first-order alignment method.
Where Pith is reading between the lines
- If the perturbation evaluations correlate with real-world attack surfaces, the same zeroth-order signal could be reused for ongoing robustness monitoring after deployment.
- The layer-selection mechanism might extend to other post-training objectives where robustness rather than accuracy is the primary goal.
Load-bearing premise
Evaluating safety alignment under perturbations gives a signal that improves robustness when used for refinement.
What would settle it
Run the hybrid procedure on a standard safety-aligned model and measure whether the rate of harmful responses under parameter or activation noise remains unchanged or increases.
Figures

read the original abstract
Safety alignment for large language models (LLMs) aims to reduce harmful or unsafe behavior while preserving general utility. However, recent findings reveal that alignment effects can be fragile: lightweight post-alignment manipulations, such as parameter noise, activation noise, or quantization, can easily weaken the intended safety behavior. Prior efforts to improve robustness have primarily focused on data curation, modified alignment objectives, and safety-critical parameter identification, leaving the role of the optimizer itself largely unexplored. In this paper, we are the first to study the robustness of safety alignment from the perspective of the base optimizer. This optimizer-centric view naturally points to zeroth-order optimization, which provides a robustness-oriented signal by evaluating safety alignment under perturbations. Based on this insight, we propose a hybrid framework that first performs standard first-order safety alignment and then applies zeroth-order refinement to improve robustness. Both theoretically and empirically, we show that only a few zeroth-order refinement steps can enhance robustness while preserving safety alignment. We further improve the efficiency of zeroth-order refinement by exploiting its inherent perturbation-based evaluations to estimate layer-wise robustness sensitivity, enabling the refinement process to concentrate updates on robustness-critical layers with modest training overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety alignment in LLMs is fragile to lightweight post-alignment manipulations and proposes a hybrid framework: standard first-order (FO) safety alignment followed by a small number of zeroth-order (ZO) refinement steps. The ZO stage is justified as supplying a perturbation-based robustness signal; the authors assert both theoretical and empirical support that this improves robustness while preserving alignment, plus an efficiency technique that uses ZO evaluations to estimate layer-wise robustness sensitivity and focus updates on critical layers.
Significance. If the central claim holds with rigorous controls, this would be a meaningful contribution by shifting attention to the optimizer itself in alignment robustness—an underexplored direction. The hybrid FO-then-ZO approach and the sensitivity-based efficiency trick could offer a lightweight, practical post-processing step that does not require new data curation or objective redesign.
minor comments (2)
- [Abstract] Abstract states the approach and claims theoretical/empirical support but supplies no equations, data, error bars, or experimental details; the central claim therefore cannot be verified from the given text.
- The weakest assumption—that ZO evaluations supply a robustness-oriented signal by testing safety alignment under perturbations—is presented without a concrete counter-example or ablation showing that alternative perturbation sources would not suffice.
Simulated Author's Rebuttal
We thank the referee for their summary of our work and for noting the potential significance of an optimizer-centric approach to safety robustness. The 'uncertain' recommendation appears to stem from the need for rigorous controls on the central claims; the manuscript provides both theoretical justification (perturbation-based robustness signal from ZO) and empirical validation across multiple models and attack types. Since the report lists no specific major comments, we provide no point-by-point responses below.
Circularity Check
No significant circularity identified
full rationale
The paper's derivation chain, as presented in the abstract, introduces a hybrid first-order alignment followed by zeroth-order refinement without any equations, fitted parameters renamed as predictions, or self-citations that reduce the robustness claim to a definitional input. The statement that ZO supplies a perturbation-based signal is framed as an insight motivating the method rather than a self-referential loop, and the claim of being first to study the optimizer perspective does not invoke load-bearing prior self-work. The overall argument remains self-contained against external benchmarks with no exhibited reduction by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Qwen2 technical report,
A. C. Qwen Team, “Qwen2 technical report,” https://qwen2.org/paper/, 2025
2025
-
[3]
Ethical and social risks of harm from Language Models
L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P.-S. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadehet al., “Ethical and social risks of harm from language models,”arXiv preprint arXiv:2112.04359, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Training language models to follow instructions with human feedback
L. Ouyanget al., “Training language models to follow instructions with human feedback,”arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
R. Rafailovet al., “Direct preference optimization: Your language model is secretly a reward model,”arXiv preprint arXiv:2305.18290, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
KTO: Model Alignment as Prospect Theoretic Optimization
K. Ethayarajh, W. Xu, N. Muennighoff, D. Jurafsky, and D. Kiela, “Kto: Model alignment as prospect theoretic optimization,”arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Deliberative alignment: Reasoning enables safer language models,
M. Y . Guan, M. Joglekar, E. Wallace, S. Jain, B. Barak, A. Helyar, R. Dias, A. Vallone, H. Ren, J. Weiet al., “Deliberative alignment: Reasoning enables safer language models,” SuperIntelligence-Robotics-Safety & Alignment, vol. 2, no. 3, 2025
2025
-
[8]
Realtoxicityprompts: Evaluating neural toxic degeneration in language models,
S. Gehman, S. Gururangan, M. Sap, Y . Choi, and N. A. Smith, “Realtoxicityprompts: Evaluating neural toxic degeneration in language models,” inFindings of the association for computational linguistics: EMNLP 2020, 2020, pp. 3356–3369
2020
-
[9]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Y . Liu, G. Deng, Z. Xu, Y . Li, Y . Zheng, Y . Zhang, L. Zhao, T. Zhang, K. Wang, and Y . Liu, “Jail- breaking chatgpt via prompt engineering: An empirical study,”arXiv preprint arXiv:2305.13860, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Sandbag detection through model impairment,
C. Tice, P. A. Kreer, N. Helm-Burger, P. S. Shahani, F. Ryzhenkov, T. van der Weij, F. Hofstätter, and J. Haimes, “Sandbag detection through model impairment,” inWorkshop on Socially Responsible Language Modelling Research, 2024
2024
-
[11]
Poser: Unmasking alignment faking llms by manipulating their internals,
J. Clymer, C. Juang, and S. Field, “Poser: Unmasking alignment faking llms by manipulating their internals,”arXiv preprint arXiv:2405.05466, 2024
-
[12]
Noise injection systemically degrades large language model safety guardrails,
P. S. Shahani, K. E. Miandoab, and M. Scheutz, “Noise injection systemically degrades large language model safety guardrails,”arXiv preprint arXiv:2505.13500, 2025
-
[13]
On jailbreaking quantized language models through fault injection attacks,
N. Zahran, A. Tahmasivand, I. Alouani, K. Khasawneh, and M. Fouda, “On jailbreaking quantized language models through fault injection attacks,” inProceedings of the Great Lakes Symposium on VLSI 2025, 2025, pp. 554–561. 10
2025
-
[14]
Robustifying safety-aligned large language models through clean data curation,
X. Liu, J. Liang, M. Ye, and Z. Xi, “Robustifying safety-aligned large language models through clean data curation,”arXiv preprint arXiv:2405.19358, 2024
-
[15]
Seal: Safety-enhanced aligned llm fine-tuning via bilevel data selection,
H. Shen, P.-Y . Chen, P. Das, and T. Chen, “Seal: Safety-enhanced aligned llm fine-tuning via bilevel data selection,” inInternational Conference on Learning Representations, 2025
2025
-
[16]
Safety alignment should be made more than just a few tokens deep,
X. Qi, A. Panda, K. Lyu, X. Ma, S. Roy, A. Beirami, P. Mittal, and P. Henderson, “Safety alignment should be made more than just a few tokens deep,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Improving llm safety alignment with dual-objective optimization,
X. Zhao, W. Cai, T. Shi, D. Huang, L. Lin, S. Mei, and D. Song, “Improving llm safety alignment with dual-objective optimization,” inForty-second International Conference on Machine Learning, 2025
2025
-
[18]
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack,
T. Huang, S. Hu, and L. Liu, “Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack,”Advances in Neural Information Processing Systems, vol. 37, pp. 74 058–74 088, 2024
2024
-
[19]
Representation noising: A defence mechanism against harmful finetuning,
D. Rosati, J. Wehner, K. Williams, Ł. Bartoszcze, D. Atanasov, R. Gonzales, S. Majumdar, C. Maple, H. Sajjad, and F. Rudzicz, “Representation noising: A defence mechanism against harmful finetuning,”Advances in Neural Information Processing Systems, vol. 37, pp. 12 636– 12 676, 2024
2024
-
[20]
Safety layers in aligned large language models: The key to llm security,
S. Li, L. Yao, L. Zhang, and Y . Li, “Safety layers in aligned large language models: The key to llm security,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[21]
Random gradient-free minimization of convex functions,
Y . Nesterov and V . Spokoiny, “Random gradient-free minimization of convex functions,”Foun- dations of Computational Mathematics, 2017
2017
-
[22]
Fine-tuning language models with just forward passes,
S. Malladi, T. Gao, E. Nichani, A. Damian, J. D. Lee, D. Chen, and S. Arora, “Fine-tuning language models with just forward passes,”Advances in Neural Information Processing Systems, vol. 36, pp. 53 038–53 075, 2023
2023
-
[23]
Revisiting zeroth-order optimization for memory-efficient llm fine-tuning: A benchmark,
Y . Zhang, P. Li, J. Hong, J. Li, Y . Zhang, W. Zheng, P.-Y . Chen, J. D. Lee, W. Yin, M. Hong et al., “Revisiting zeroth-order optimization for memory-efficient llm fine-tuning: A benchmark,” arXiv preprint arXiv:2402.11592, 2024
-
[24]
Differentially private zeroth-order methods for scalable large language model fine-tuning,
Z. Liu, J. Lou, W. Bao, Y . Hu, W. Wang, Z. Qin, and K. Ren, “Differentially private zeroth-order methods for scalable large language model fine-tuning,”IEEE Transactions on Information Forensics and Security, 2026
2026
-
[25]
Towards memory-efficient and sustainable machine unlearning on edge using zeroth-order optimizer,
C. Zhang, C. Yang, Q. Tan, J. Liu, A. Li, Y . Wang, J. Lu, J. Wang, and G. Yuan, “Towards memory-efficient and sustainable machine unlearning on edge using zeroth-order optimizer,” in Proceedings of the Great Lakes Symposium on VLSI 2025, 2025, pp. 227–232
2025
-
[26]
Downgrade to upgrade: Optimizer sim- plification enhances robustness in llm unlearning,
Y . Lang, Y . Zhang, C. Fan, C. Wang, J. Jia, and S. Liu, “Downgrade to upgrade: Optimizer sim- plification enhances robustness in llm unlearning,”14th International Conference on Learning Representations, ICLR 2026, 2026
2026
-
[27]
A comprehensive survey in llm (-agent) full stack safety: Data, training and deployment,
K. Wang, G. Zhang, Z. Zhou, J. Wu, M. Yu, S. Zhao, C. Yin, J. Fu, Y . Yan, H. Luoet al., “A comprehensive survey in llm (-agent) full stack safety: Data, training and deployment,”arXiv preprint arXiv:2504.15585, 2025
-
[28]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference,
J. Ji, D. Hong, B. Zhang, B. Chen, J. Dai, B. Zheng, T. A. Qiu, J. Zhou, K. Wang, B. Li et al., “Pku-saferlhf: Towards multi-level safety alignment for llms with human preference,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 31 983–32 016
2025
-
[29]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirho- seini, C. McKinnonet al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Safe rlhf: Safe reinforce- ment learning from human feedback,
J. Dai, X. Pan, R. Sun, J. Ji, X. Xu, M. Liu, Y . Wang, and Y . Yang, “Safe rlhf: Safe reinforce- ment learning from human feedback,” inThe Twelfth International Conference on Learning Representations, 2024. 11
2024
-
[31]
Saro: Enhancing llm safety through reasoning-based alignment,
Y . Mou, Y . Luo, S. Zhang, and W. Ye, “Saro: Enhancing llm safety through reasoning-based alignment,”arXiv preprint arXiv:2504.09420, 2025
-
[32]
Jailbroken: How does llm safety training fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does llm safety training fail?” Advances in neural information processing systems, vol. 36, pp. 80 079–80 110, 2023
2023
-
[33]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and trans- ferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
" do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “" do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1671–1685
2024
-
[35]
Fine-tuning aligned language models compromises safety, even when users do not intend to!
X. Qi, Y . Zeng, T. Xie, P.-Y . Chen, R. Jia, P. Mittal, and P. Henderson, “Fine-tuning aligned language models compromises safety, even when users do not intend to!” inInternational Conference on Learning Representations, 2024
2024
-
[36]
X. Yang, X. Wang, Q. Zhang, L. Petzold, W. Y . Wang, X. Zhao, and D. Lin, “Shadow alignment: The ease of subverting safely-aligned language models,”arXiv preprint arXiv:2310.02949, 2023
-
[37]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDiarmid, T. Lanham, D. M. Ziegler, T. Maxwell, N. Chenget al., “Sleeper agents: Training deceptive llms that persist through safety training,”arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Refusal in language models is mediated by a single direction,
A. Arditi, O. Obeso, A. Syed, D. Paleka, N. Panickssery, W. Gurnee, and N. Nanda, “Refusal in language models is mediated by a single direction,”Advances in Neural Information Processing Systems, vol. 37, pp. 136 037–136 083, 2024
2024
-
[39]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
T. Dettmerset al., “Llm.int8(): 8-bit matrix multiplication for transformers at scale,”arXiv preprint arXiv:2208.07339, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Noise injection reveals hidden capabilities of sandbagging language models,
C. Tice, P. A. Kreer, N. Helm-Burger, P. S. Shahani, F. Ryzhenkov, F. Roger, C. Neo, J. Haimes, F. Hofstätter, and T. van der Weij, “Noise injection reveals hidden capabilities of sandbagging language models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[41]
Zeroth-order optimization finds flat minima,
L. Zhang, B. Li, K. K. Thekumparampil, S. Oh, M. Muehlebach, and N. He, “Zeroth-order optimization finds flat minima,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[42]
When flatness does (not) guarantee adversarial robustness,
N. P. Walter, L. Adilova, J. Vreeken, and M. Kamp, “When flatness does (not) guarantee adversarial robustness,”arXiv preprint arXiv:2510.14231, 2025
-
[43]
A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications,
S. Liu, P.-Y . Chen, B. Kailkhura, G. Zhang, A. O. Hero III, and P. K. Varshney, “A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications,”IEEE Signal Processing Magazine, vol. 37, no. 5, pp. 43–54, 2020
2020
-
[44]
Visualising policy-reward interplay to inform zeroth-order preference optimisation of large language models,
A. Galatolo, Z. Dai, K. Winkle, and M. Beloucif, “Visualising policy-reward interplay to inform zeroth-order preference optimisation of large language models,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 17 446–17 461
2025
-
[45]
Multivariate stochastic approximation using a simultaneous perturbation gradient approximation,
J. C. Spall, “Multivariate stochastic approximation using a simultaneous perturbation gradient approximation,”IEEE transactions on automatic control, vol. 37, no. 3, pp. 332–341, 1992
1992
-
[46]
Zeroth-order methods for constrained noncon- vex nonsmooth stochastic optimization,
Z. Liu, C. Chen, L. Luo, and B. K. H. Low, “Zeroth-order methods for constrained noncon- vex nonsmooth stochastic optimization,” inForty-first International Conference on Machine Learning, 2024
2024
-
[47]
Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition,
H. Karimi, J. Nutini, and M. Schmidt, “Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition,” inJoint European conference on machine learning and knowledge discovery in databases. Springer, 2016, pp. 795–811. 12
2016
-
[48]
Snip: Single-shot network pruning based on connection sensitivity,
N. Lee, T. Ajanthan, and P. Torr, “Snip: Single-shot network pruning based on connection sensitivity,” inInternational Conference on Learning Representations, 2019
2019
-
[49]
A simple and effective pruning approach for large language models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective pruning approach for large language models,” in12th International Conference on Learning Representations, ICLR 2024, 2024
2024
-
[50]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Improving alignment and robustness with circuit breakers,
A. Zou, L. Phan, J. Wang, D. Duenas, M. Lin, M. Andriushchenko, R. Wang, Z. Kolter, M. Fredrikson, and D. Hendrycks, “Improving alignment and robustness with circuit breakers,” Advances in Neural Information Processing Systems, vol. 37, pp. 83 345–83 373, 2024
2024
-
[52]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[53]
The language model evaluation harness, 07 2024.https://zenodo.org/records/12608602
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “The language model evaluation harness,” 07 2024. [Online]. Available: https://zenodo.org/re...
-
[54]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li et al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 35 181–35 224. A Hyperparameters and Hardware Configuration A.1 Training Hyperparameters The main hyp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.