Rehearsed Multi-Agent Live Product Demonstrations with Real-Time Voice Question Answering
Pith reviewed 2026-06-30 06:00 UTC · model grok-4.3
The pith
Rhetor is a multi-agent system that converts a running web application and its source code into a rehearsed live demonstration with synchronized narration and real-time voice question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
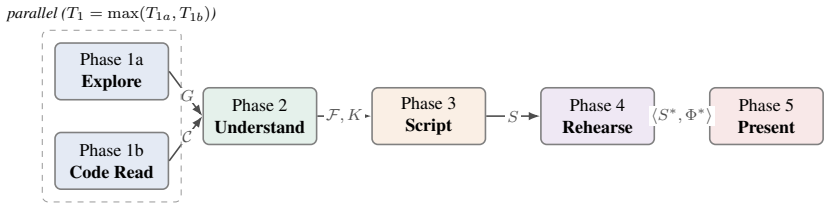
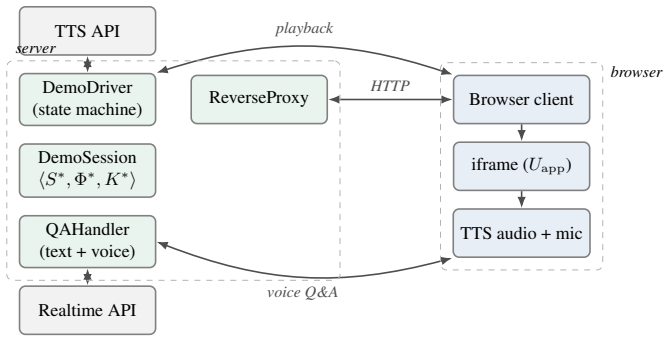
Rhetor takes a running web application and its source-code repository as input and produces a rehearsed live demonstration with segment-synchronized narration and real-time voice question answering, using a cross-modal feature representation, grounded scripter, pre-presentation rehearsal loop, and runtime synchronization invariant.
What carries the argument
The cross-modal feature representation that merges UI exploration with source-code analysis into features tagged with discrete focus tiers, which supports a grounded scripter and rehearsal loop for reliable script convergence.
If this is right
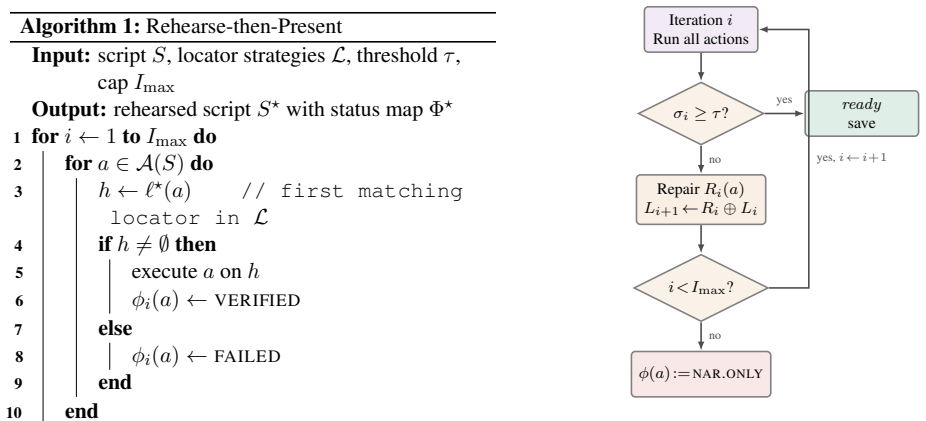
- The rehearsal loop with graceful degradation permits demos to continue even when some actions cannot be executed.
- The runtime synchronization invariant ensures each browser action aligns exactly with the end of its narration segment.
- Locator repair during rehearsal drives convergence to full success on applications like Excalidraw.
- A ten-metric benchmark protocol across six application categories can test whether each architectural choice improves outcomes.
Where Pith is reading between the lines
- Organizations could reduce presenter preparation time by running the system on updated codebases before each demo event.
- The same tiered feature approach might support automated testing scripts that remain stable across UI changes.
- Real-time voice Q&A could be extended by linking answers directly to the same cross-modal features used for narration.
Load-bearing premise
Merging UI exploration with source-code analysis into tiered features allows the scripter to produce scripts that converge reliably via the rehearsal loop.
What would settle it
If a new application yields a locator-firing rate below 0.5 after multiple rehearsal iterations, the claim of reliable convergence would be falsified.
Figures

read the original abstract
Live product demonstrations are a recurring, high-cost activity in software organizations: a human presenter must select features, dispatch the corresponding interactions on a running application, narrate them coherently, and answer questions in real time. Existing automation addresses only fragments -- generalist browser agents target instruction-conditioned task completion, and demo-video tools produce fixed MP4 artifacts that cannot be questioned and silently break under interface drift. We propose Rhetor, a multi-agent system that takes a running web application and its source-code repository as input and produces a rehearsed live demonstration with segment-synchronized narration and real-time voice question answering. The architectural contributions are a cross-modal feature representation that merges UI exploration with source-code analysis into features tagged with discrete focus tiers, a grounded scripter constrained to UI elements observed during exploration and dispatched through multi-strategy semantic locators, a pre-presentation rehearsal loop with explicit convergence and graceful degradation to narration-only segments, and a runtime synchronization invariant that ties each browser action to the audio-end event of its narration segment. Across six pipeline sessions on four deployed applications -- including the public-domain whiteboard application Excalidraw -- the rehearser's internal locator-firing rate (sigma-bar) spans 0.31-1.00 over 147 scripted actions; on the substantial workload (53 actions, full tier differentiation), sigma-bar is approximately 0.92, and on the public-domain reference point the locator-repair step drives convergence to sigma-bar = 1.00 at iteration 2. We additionally define a benchmark protocol of ten metrics across six application categories that would establish, beyond the case study, whether each design choice contributes positively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Rhetor, a multi-agent system that takes a running web application and its source-code repository as input and outputs a rehearsed live demonstration featuring segment-synchronized narration and real-time voice question answering. Architectural elements include a cross-modal feature representation merging UI exploration with source-code analysis via discrete focus tiers, a grounded scripter constrained to observed UI elements and using multi-strategy semantic locators, a pre-presentation rehearsal loop with explicit convergence criteria and graceful degradation, and a runtime synchronization invariant linking browser actions to narration audio-end events. Empirical results are reported from six pipeline sessions on four deployed applications (including Excalidraw), with internal locator-firing rates (sigma-bar) spanning 0.31-1.00 over 147 actions; on a 53-action workload sigma-bar is ~0.92 and on Excalidraw the repair step yields convergence to 1.00 at iteration 2. The paper also defines (but does not execute) a benchmark protocol of ten metrics across six application categories.
Significance. If the cross-modal representation and rehearsal loop reliably produce convergent scripts, the work could meaningfully reduce the recurring human cost of live product demonstrations in software organizations. The case-study metrics provide concrete evidence of feasibility on real deployed applications, including a public-domain reference, and the explicit definition of a benchmark protocol is a constructive contribution toward falsifiable evaluation. However, because the reported results are limited to six sessions without ablations, comparisons, or execution of the proposed benchmark, the demonstrated impact remains preliminary rather than conclusive.
major comments (2)
- [Abstract] Abstract: The central claim that the cross-modal feature representation (with discrete focus tiers) enables a grounded scripter whose scripts converge reliably via the rehearsal loop rests on sigma-bar values from six sessions on four applications. The manuscript itself states that the benchmark protocol of ten metrics across six categories 'would establish, beyond the case study, whether each design choice contributes positively,' indicating this protocol was not executed. This is load-bearing because the reliability claim cannot be assessed without systematic ablations or the defined benchmark.
- [Abstract] Abstract: The reported performance figures (sigma-bar of 0.92 on the 53-action workload; convergence to 1.00 at iteration 2 on Excalidraw) are presented without error bars, statistical tests, or a full experimental protocol. This weakens the empirical grounding for the claim that the rehearsal loop drives reliable convergence across the 147 scripted actions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The manuscript presents the reported results explicitly as a case study on four deployed applications while defining (but not executing) a benchmark protocol for stronger claims. We address each major comment below and propose targeted revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the cross-modal feature representation (with discrete focus tiers) enables a grounded scripter whose scripts converge reliably via the rehearsal loop rests on sigma-bar values from six sessions on four applications. The manuscript itself states that the benchmark protocol of ten metrics across six categories 'would establish, beyond the case study, whether each design choice contributes positively,' indicating this protocol was not executed. This is load-bearing because the reliability claim cannot be assessed without systematic ablations or the defined benchmark.
Authors: We agree that the benchmark protocol was defined but not executed, as the manuscript already states. The central claim is scoped to the observed behavior in the six pipeline sessions: the cross-modal features, grounded scripter, and rehearsal loop produced sigma-bar values of 0.31-1.00 (with 0.92 on the 53-action workload and convergence to 1.00 at iteration 2 on Excalidraw). These are internal, per-session metrics of locator success during rehearsal, not a general reliability guarantee. We will revise the abstract to more explicitly frame the contribution as a feasibility case study on real applications (including a public-domain reference) and to note that the defined benchmark remains future work for systematic ablations. revision: partial
-
Referee: [Abstract] Abstract: The reported performance figures (sigma-bar of 0.92 on the 53-action workload; convergence to 1.00 at iteration 2 on Excalidraw) are presented without error bars, statistical tests, or a full experimental protocol. This weakens the empirical grounding for the claim that the rehearsal loop drives reliable convergence across the 147 scripted actions.
Authors: The figures are descriptive metrics computed directly from the six individual pipeline sessions on specific applications and workloads (147 actions total). Because each session constitutes a complete run rather than a sample from a larger population, standard error bars or inferential statistical tests are not applicable. We will add a clarifying sentence in the abstract and results section stating that these values are case-study observations of the rehearsal process rather than aggregated experimental statistics. revision: yes
Circularity Check
No circularity; case-study metrics are direct observations, not self-defined
full rationale
The paper describes an architectural system (cross-modal features, grounded scripter, rehearsal loop) and reports sigma-bar locator-firing rates as direct measurements from six sessions on four applications. No equations, fitted parameters, or predictions appear that reduce by construction to inputs. The text explicitly distinguishes the presented case studies from an unexecuted benchmark protocol of ten metrics, so the reliability claims rest on observed runs rather than tautological re-labeling. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation chain is therefore self-contained engineering description plus empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Deng, Y . Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y . Su. Mind2Web: Towards a generalist agent for the web. InNeurIPS Datasets and Benchmarks,
-
[2]
WebArena: A Realistic Web Environment for Building Autonomous Agents
S. Zhou et al. WebArena: A realistic web environment for building autonomous agents. arXiv:2307.13854, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
J. Y . Koh et al. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. arXiv:2401.13649, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
H. He et al. WebV oyager: Building an end-to-end web agent with large multimodal models. arXiv:2401.13919, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
An illusion of progress? assessing the current state of web agents.arXiv preprint arXiv:2504.01382,
T. Xue et al. An illusion of progress? Assessing the current state of web agents. arXiv:2504.01382, 2025
-
[6]
MolmoWeb: An open agent for automating web tasks
Allen Institute for AI. MolmoWeb: An open agent for automating web tasks. Technical report, 2026
2026
- [7]
-
[8]
R. Khedar et al. State-grounded multi-agent syn- thetic data generation for tool-augmented LLMs. arXiv:2606.16307, 2026
-
[9]
Realtime API: speech-to-speech over Web- Socket
OpenAI. Realtime API: speech-to-speech over Web- Socket. Technical documentation, 2024
2024
-
[10]
Y . Madkour. DemoPilot: autonomous demo video agent. GitHub, 2026
2026
-
[11]
N. Holas. LooK: one-command product demo videos. GitHub, 2026
2026
-
[12]
GitHub, 2026
NeuraScreen: JSON-driven demo video generator. GitHub, 2026
2026
-
[13]
F. Mathieu. DemoDSL. GitHub, 2026. 14
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.