REVIEW 2 major objections 54 references
DPText learns text representations that satisfy differential privacy, exclude private user attributes, and keep high utility for tasks such as sentiment analysis.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-25 01:24 UTC pith:DQFLXNEP
load-bearing objection DPText wants one text embedding to be formally differentially private, stripped of private attributes, and still useful for tasks, but the abstract gives no mechanism details or interaction analysis to support that all three hold at once. the 2 major comments →
I Am Not What I Write: Privacy Preserving Text Representation Learning
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DPText learns a textual representation that (1) is differentially private, (2) does not contain private information and (3) retains high utility for the given task.
What carries the argument
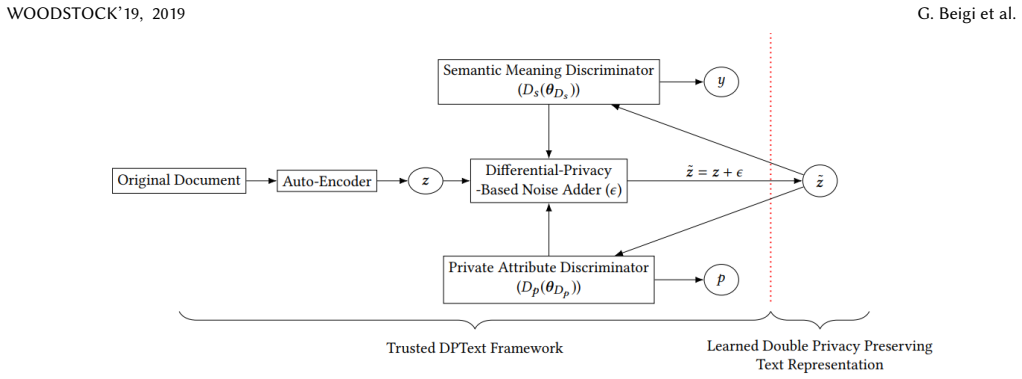
The DPText double privacy preserving framework that combines differential privacy with explicit removal of private attributes during representation learning.
Load-bearing premise
One learned representation can be made differentially private, stripped of all private attributes, and still keep high task utility without large trade-offs.
What would settle it
An adversary recovers a user's identity or infers a private attribute such as gender from the released DPText representations at a rate significantly above the claimed privacy bound, or task accuracy falls substantially below the non-private baseline.
If this is right
- User-generated text can be published with lower risk of re-identification.
- Sensitive attributes such as age or location become harder to infer from the released data.
- NLP models trained on the representations maintain competitive accuracy on sentiment and tagging tasks.
- Data publishers gain a concrete method to meet both privacy and utility requirements.
Where Pith is reading between the lines
- The same representation could be reused across multiple downstream tasks without additional privacy cost.
- Extending the approach to other data types such as images or graphs would require analogous double-protection layers.
- Long-term, the method might support public datasets that researchers can analyze without needing individual consent for each study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DPText, a double privacy-preserving text representation learning framework. It claims to learn a single textual representation that is (1) differentially private, (2) free of private attributes such as age, location, or gender, and (3) retains high utility for downstream tasks, with experimental support claimed on sentiment analysis and part-of-speech tagging.
Significance. If the joint satisfaction of formal DP, empirical attribute removal, and high task utility can be demonstrated without unacceptable trade-offs, the result would be significant for privacy-preserving NLP, as it targets the core tension between publishing user-generated text and protecting individual attributes while supporting standard tasks.
major comments (2)
- [Abstract] Abstract: The central claim that one learned representation simultaneously satisfies differential privacy, removes all private attributes, and preserves high utility is presented as the design goal and as experimentally supported, yet the abstract supplies no mechanism-interaction analysis, privacy-budget allocation between the DP and adversarial components, or quantitative trade-off results; this joint-compatibility premise is load-bearing for the three-property claim.
- [Abstract] Abstract: The evaluation is described only at the level of 'effectiveness ... in terms of preserving both privacy and utility' on two tasks; without reported metrics (e.g., privacy leakage rates, utility deltas relative to non-private baselines, or epsilon values), it is impossible to assess whether the three properties are achieved together rather than traded off.
Simulated Author's Rebuttal
We thank the referee for the feedback. The comments focus on the abstract's level of detail; we will revise the abstract to include concise references to mechanism interactions, budget allocation, and key quantitative results from the full paper while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that one learned representation simultaneously satisfies differential privacy, removes all private attributes, and preserves high utility is presented as the design goal and as experimentally supported, yet the abstract supplies no mechanism-interaction analysis, privacy-budget allocation between the DP and adversarial components, or quantitative trade-off results; this joint-compatibility premise is load-bearing for the three-property claim.
Authors: The full manuscript (Sections 3.2-3.3 and 4) details the interaction: DP noise is added to the encoder output before the adversarial attribute-removal module, with the total privacy budget split such that epsilon_DP governs the noise scale and the adversarial loss is constrained to not violate the DP guarantee. Trade-off analysis appears in the experiments via Pareto curves of utility vs. leakage. We will add one sentence to the abstract summarizing this allocation and the observed compatibility (e.g., joint satisfaction at epsilon=2.0). revision: yes
-
Referee: [Abstract] Abstract: The evaluation is described only at the level of 'effectiveness ... in terms of preserving both privacy and utility' on two tasks; without reported metrics (e.g., privacy leakage rates, utility deltas relative to non-private baselines, or epsilon values), it is impossible to assess whether the three properties are achieved together rather than traded off.
Authors: The body reports concrete metrics: epsilon values (1.0-5.0), adversarial leakage rates (near-random for age/gender), and utility deltas (accuracy within 3-7% of non-private baselines on sentiment and POS). We will revise the abstract to include representative numbers (e.g., 'at epsilon=2.0, leakage <5% above random while retaining >92% of baseline utility') to make the joint achievement explicit. revision: yes
Circularity Check
No circularity; empirical framework claims rest on experiments, not self-referential definitions.
full rationale
The paper proposes DPText as a new double privacy-preserving representation learning method and asserts its three properties via experimental results on sentiment analysis and POS tagging. No equations, fitted parameters, or derivations are presented in the abstract or described structure that reduce to their own inputs by construction. The central claim is an empirical performance assertion rather than a mathematical result derived from self-citation chains or ansatzes smuggled via prior work. This is a standard self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
read the original abstract
Online users generate tremendous amounts of textual information by participating in different activities, such as writing reviews and sharing tweets. This textual data provides opportunities for researchers and business partners to study and understand individuals. However, this user-generated textual data not only can reveal the identity of the user but also may contain individual's private information (e.g., age, location, gender). Hence, "you are what you write" as the saying goes. Publishing the textual data thus compromises the privacy of individuals who provided it. The need arises for data publishers to protect people's privacy by anonymizing the data before publishing it. It is challenging to design effective anonymization techniques for textual information which minimizes the chances of re-identification and does not contain users' sensitive information (high privacy) while retaining the semantic meaning of the data for given tasks (high utility). In this paper, we study this problem and propose a novel double privacy preserving text representation learning framework, DPText, which learns a textual representation that (1) is differentially private, (2) does not contain private information and (3) retains high utility for the given task. Evaluating on two natural language processing tasks, i.e., sentiment analysis and part of speech tagging, we show the effectiveness of this approach in terms of preserving both privacy and utility.
Figures



Reference graph
Works this paper leans on
-
[1]
[n. d.]. How does Twitter make money? https://www.bbc.com/news/ business-24397472. Accessed: 2013-11-07
work page 2013
-
[2]
Hamidreza Alvari, Elham Shaabani, Soumajyoti Sarkar, Ghazaleh Beigi, and Paulo Shakarian. 2019. Less is More: Semi-Supervised Causal Inference for Detecting Pathogenic Users in Social Media. In Companion Proceedings of The 2019 World Wide Web Conference. ACM, 154–161
work page 2019
-
[3]
Hamidreza Alvari, Elham Shaabani, and Paulo Shakarian. 2018. Early Identifi- cation of Pathogenic Social Media Accounts. In IEEE Intelligence and Security Informatics (ISI). IEEE
work page 2018
-
[4]
Hamidreza Alvari and Paulo Shakarian. 2019. Hawkes Process for Understanding the Influence of Pathogenic Social Media Accounts. In 2019 2nd International Conference on Data Intelligence and Security (ICDIS) . IEEE
work page 2019
-
[5]
Hamidreza Alvari, Paulo Shakarian, and JE Kelly Snyder. 2017. Semi-supervised learning for detecting human trafficking. Security Informatics 6, 1 (2017), 1
work page 2017
-
[6]
Balamurugan Anandan, Chris Clifton, Wei Jiang, Mummoorthy Murugesan, Pedro Pastrana-Camacho, and Luo Si. 2012. t-Plausibility: Generalizing Words to Desensitize Text. Transactions on Data Privacy 5, 3 (2012), 505–534
work page 2012
-
[7]
Michael Barbaro, Tom Zeller, and Saul Hansell. 2006. A face is exposed for AOL searcher no. 4417749. New York Times 9, 2008 (2006), 8
work page 2006
-
[8]
Ghazaleh Beigi, Ruocheng Guo, Alexander Nou, Yanchao Zhang, and Huan Liu
-
[9]
In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining
Protecting user privacy: An approach for untraceable web browsing history and unambiguous user profiles. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining . ACM, 213–221
-
[10]
Ghazaleh Beigi and Huan Liu. 2018. Privacy in social media: Identification, mitigation and applications. arXiv preprint arXiv:1808.02191 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Ghazaleh Beigi and Huan Liu. 2018. Similar but different: Exploiting usersâĂŹ congruity for recommendation systems. In International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Represen- tation in Modeling and Simulation . Springer, 129–140
work page 2018
-
[12]
Identifying Novel Privacy Issues of Online Users on Social Media Platforms
Ghazaleh Beigi and Huan Liu. 2019. "Identifying Novel Privacy Issues of Online Users on Social Media Platforms" by Ghazaleh Beigi and Huan Liu with Martin Vesely As Coordinator. SIGWEB Newsl. Winter, Article 4 (Feb. 2019), 7 pages
work page 2019
-
[13]
Ghazaleh Beigi, Suhas Ranganath, and Huan Liu. 2019. Signed Link Prediction with Sparse Data: The Role of Personality Information. InCompanion Proceedings of The 2019 World Wide Web Conference . ACM, 1270–1278
work page 2019
-
[14]
Ghazaleh Beigi, Kai Shu, Ruocheng Guo, Suhang Wang, and Huan Liu. 2019. Privacy Preserving Text Representation Learning. In Proceedings of the 30th on Hypertext and Social Media (HT ’19). ACM
work page 2019
-
[15]
Ghazaleh Beigi, Kai Shu, Yanchao Zhang, and Huan Liu. 2018. Securing social media user data: An adversarial approach. In Proceedings of the 29th on Hypertext and Social Media. ACM, 165–173
work page 2018
-
[16]
Valentina Beretta, Daniele Maccagnola, Timothy Cribbin, and Enza Messina
-
[17]
In Proceedings of the 26th ACM Conference on Hypertext & Social Media
An interactive method for inferring demographic attributes in Twitter. In Proceedings of the 26th ACM Conference on Hypertext & Social Media . ACM
-
[18]
Ann Bies, Justin Mott, Colin Warner, and Seth Kulick. 2012. English web treebank. Linguistic Data Consortium, Philadelphia, PA (2012)
work page 2012
-
[19]
Samuel R Bowman, Luke Vilnis, Oriol Vinyals, Andrew M Dai, Rafal Jozefowicz, and Samy Bengio. 2015. Generating sentences from a continuous space. arXiv preprint arXiv:1511.06349 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Stephen Boyd and Lieven Vandenberghe. 2004. Convex optimization. Cambridge university press
work page 2004
-
[21]
Thorsten Brants. 2000. TnT: a statistical part-of-speech tagger. In Proceedings of the sixth conference on Applied natural language processing . ACL, 224–231. Privacy Preserving Text Representation Learning WOODSTOCK’19, 2019
work page 2000
-
[22]
Kamalika Chaudhuri, Claire Monteleoni, and Anand D Sarwate. 2011. Differen- tially private empirical risk minimization. In JMLR, Vol. 12
work page 2011
-
[23]
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Cicero dos Santos and Maira Gatti. 2014. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of Computational Linguistics
work page 2014
-
[25]
Cynthia Dwork. 2008. Differential privacy: A survey of results. In International Conference on Theory and Applications of Models of Computation . Springer, 1–19
work page 2008
-
[26]
Cynthia Dwork, Aaron Roth, et al. 2014. The algorithmic foundations of differ- ential privacy. Foundations and Trends in Theoretical Computer Science (2014)
work page 2014
-
[27]
Benjamin CM Fung, K Wang, R Chen, and S Yu Philip. 2010. Privacy-preserving data publishing: A survey of recent developments. Comput. Surveys 42, 4 (2010)
work page 2010
-
[28]
Arthur Gervais, Reza Shokri, Adish Singla, Srdjan Capkun, and Vincent Lenders
-
[29]
In Proceedings of ACM SIGSAC on CCS
Quantifying web-search privacy. In Proceedings of ACM SIGSAC on CCS
-
[30]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Advances in neural information processing systems . 2672–2680
work page 2014
-
[31]
Michaela Gotz, Ashwin Machanavajjhala, Guozhang Wang, Xiaokui Xiao, and Johannes Gehrke. 2012. Publishing search logs a comparative study of privacy guarantees. IEEE Transactions on Knowledge and Data Engineering 24, 3 (2012)
work page 2012
-
[32]
Dilek Hakkini-Tur, GËĘkhan Tur, et al. 2006. Sanitization and anonymization of document repositories. In Web and information security. IGI Global, 133–148
work page 2006
-
[33]
Briland Hitaj, Giuseppe Ateniese, and Fernando Perez-Cruz. 2017. Deep models under the GAN: information leakage from collaborative deep learning. In Pro- ceedings of ACM SIGSAC Conference on Computer and Communications Security
work page 2017
-
[34]
Dirk Hovy, Anders Johannsen, and Anders Søgaard. 2015. User review sites as a resource for large-scale sociolinguistic studies. In Proceedings of WWW
work page 2015
-
[35]
Dirk Hovy and Anders Søgaard. 2015. Tagging performance correlates with author age. In Proceedings of ACL
work page 2015
-
[36]
Daniel C Howe and Helen Nissenbaum. 2009. TrackMeNot: Resisting surveillance in web search. Lessons from the Identity trail: Anonymity, privacy, and identity in a networked society 23 (2009), 417–436
work page 2009
-
[37]
Anna Jørgensen, Dirk Hovy, and Anders Søgaard. 2016. Learning a POS tagger for AAVE-like language. In Proceedings of ACL: Human Language Technologies
work page 2016
-
[38]
Daniel Kifer and Ashwin Machanavajjhala. 2011. No free lunch in data privacy. In Proceedings of ACM SIGMOD International Conference on Management of data
work page 2011
-
[39]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[40]
Aleksandra Korolova, Krishnaram Kenthapadi, Nina Mishra, and Alexandros Ntoulas. 2009. Releasing search queries and clicks privately. In WWW
work page 2009
-
[41]
Quoc Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. In International Conference on Machine Learning . 1188–1196
work page 2014
-
[42]
Yitong Li, Timothy Baldwin, and Trevor Cohn. 2018. Towards Robust and Privacy- preserving Text Representations. (2018)
work page 2018
-
[43]
Marco Lui and Timothy Baldwin. 2012. langid. py: An off-the-shelf language identification tool. In Proceedings of the ACL 2012 system demonstrations
work page 2012
-
[44]
Frank McSherry and Ilya Mironov. 2009. Differentially private recommender systems: building privacy into the net. In Proceedings of the 15th ACM SIGKDD
work page 2009
-
[45]
Xuying Meng, Suhang Wang, Kai Shu, Jundong Li, Bo Chen, Huan Liu, and Yujun Zhang. 2018. Personalized privacy-preserving social recommendation. In Proceedings of Thirty-Second AAAI Conference on Artificial Intelligence
work page 2018
-
[46]
Arjun Mukherjee and Bing Liu. 2010. Improving gender classification of blog authors. In Proceedings of the 2010 conference on ACL EMNLP
work page 2010
-
[47]
Arvind Narayanan and Vitaly Shmatikov. 2008. Robust de-anonymization of large sparse datasets. In IEEE Symposium on Security and Privacy
work page 2008
-
[48]
Slav Petrov, Dipanjan Das, and Ryan McDonald. 2012. A Universal Part-of-Speech Tagset. In Proceedings of Language Resources and Evaluation (LREC)
work page 2012
-
[49]
Martin Potthast, Francisco Rangel, Michael Tschuggnall, Efstathios Stamatatos, Paolo Rosso, and Benno Stein. 2017. Overview of PAN’17. InInternational Con- ference of the Cross-Language Evaluation Forum for European Languages
work page 2017
-
[50]
Lifeng Shang, Zhengdong Lu, and Hang Li. 2015. Neural responding machine for short-text conversation. arXiv preprint arXiv:1503.02364 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
Svitlana Volkova, Yoram Bachrach, Michael Armstrong, and Vijay Sharma. 2015. Inferring Latent User Properties from Texts Published in Social Media.. In Pro- ceedings of Twenty-Ninth AAAI Conference on Artificial Intelligence
work page 2015
-
[52]
Qian Xiao, Rui Chen, and Kian-Lee Tan. 2014. Differentially private network data release via structural inference. In Proceedings of the 20th ACM SIGKDD
work page 2014
-
[53]
Jinxue Zhang, Jingchao Sun, Rui Zhang, and Yanchao Zhang. 2018. Privacy- Preserving Social Media Data Outsourcing. In Proceedings of IEEE INFOCOM
work page 2018
-
[54]
Sicong Zhang, Hui Yang, and Lisa Singh. 2016. Anonymizing query logs by differential privacy. In Proceedings of ACM SIGIR
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.