DuoMem: Towards Capable On-Device Memory Agents via Dual-Space Distillation
Pith reviewed 2026-06-30 07:36 UTC · model grok-4.3
The pith
Dual-space distillation transfers procedural skills from large models to compact ones for on-device agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
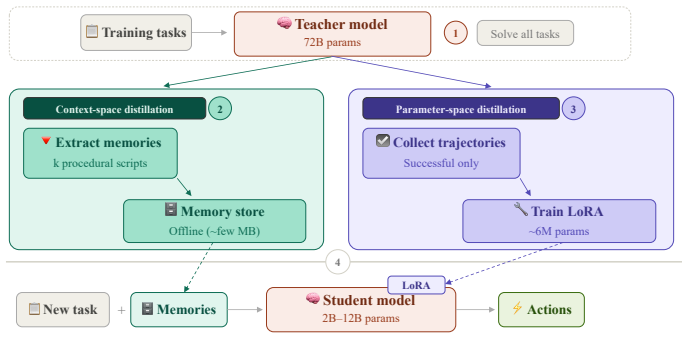
DuoMem transfers procedural problem-solving ability from a large teacher model to compact student models through dual-space distillation: context-space distillation replaces student-generated memories with higher-quality teacher-generated procedural memories prepended to the input, and parameter-space distillation fine-tunes lightweight LoRA adapters on successful teacher trajectories, enabling the student to reach performance close to the teacher on embodied decision-making tasks.
What carries the argument
Dual-space distillation framework that combines context-space memory replacement with parameter-space LoRA fine-tuning on teacher trajectories.
If this is right
- The 4B model completes tasks over three times faster than the 72B teacher in wall-clock time.
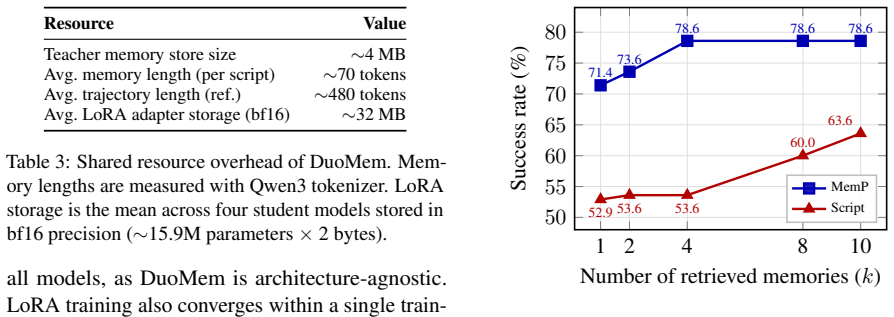
- Only a few megabytes of pre-computed teacher memories are required in addition to the adapters.
- Both distillation components contribute complementary gains, as shown by ablations on models from 2B to 72B parameters.
- The approach makes real-time edge deployment of memory-augmented agents feasible where the full teacher model would be impractical.
Where Pith is reading between the lines
- The same dual distillation could be tested on other multi-turn agent benchmarks to check whether the gains generalize beyond ALFWorld.
- Combining DuoMem with further compression techniques might allow even smaller base models to reach usable performance.
- The pre-computed memories could be updated incrementally on-device if new teacher trajectories become available.
Load-bearing premise
Teacher-generated memories and trajectories are of sufficiently higher quality that prepending them and fine-tuning LoRA on them transfers the procedural ability to the student model without major loss.
What would settle it
Testing the 4B model with DuoMem on ALFWorld and finding its success rate stays near the 4.3 percent baseline instead of rising toward 78 percent.
Figures





read the original abstract
Large Language Model (LLM)-based agents can solve complex procedural tasks by interacting with environments over multiple turns, but this ability typically depends on large models, long contexts, and repeated inference calls. This makes advanced memory-augmented agents difficult to deploy on resource-constrained devices. We introduce DuoMem, a dual-space distillation framework that transfers procedural problem-solving ability from a large teacher model to compact student models. DuoMem distils in two complementary spaces: (1)context-space distillation, which replaces student-generated memories with higher-quality teacher-generated procedural memories prepended to the student's input, and (2)parameter-space distillation, which fine-tunes lightweight LoRA adapters on successful teacher trajectories. Evaluated on ALFWorld, a challenging embodied decision-making benchmark, DuoMem boosts a 4B-parameter model from 4.3% to 77.9% task success rate, closing most of the gap to a 72B teacher model (87.1%), while adding fewer than 10M trainable parameters and only a few megabytes of pre-computed teacher memories. Moreover, the DuoMem-enhanced 4B model completes tasks over 3x faster than the 72B teacher in wall-clock time, making it viable for real-time edge deployment, which would be challenging for the teacher.Extensive ablations across eight models spanning 2B-72B parameters reveal that both distillation axes contribute complementary
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DuoMem, a dual-space distillation framework for transferring procedural problem-solving ability from large teacher LLMs to compact student models for on-device deployment. Context-space distillation replaces student-generated memories with prepended teacher-generated procedural memories; parameter-space distillation fine-tunes lightweight LoRA adapters (<10M parameters) on successful teacher trajectories. On ALFWorld, a 4B student improves from 4.3% to 77.9% task success (vs. 87.1% for 72B teacher), with only a few MB of pre-computed memories and 3x faster wall-clock time than the teacher. Ablations across 2B-72B models indicate both distillation axes contribute complementarily.
Significance. If the empirical results hold under rigorous controls, the work would be significant for enabling capable memory-augmented LLM agents on resource-constrained devices. It demonstrates a practical way to close most of the performance gap to much larger models while adding negligible overhead, with potential for real-time edge deployment. The dual-space approach and reported speedups are notable strengths if reproducible.
major comments (3)
- [Abstract] Abstract: the reported 4.3% → 77.9% gain on ALFWorld lacks any mention of baselines, error bars, data splits, ablation controls, or evaluation protocol. Without these, it is impossible to determine whether the central claim is supported or vulnerable to post-hoc selection.
- [Evaluation] The central claim depends on teacher-generated memories being higher-quality, procedural (not instance-specific), and directly usable by prepending to the student without format/alignment issues. The manuscript must provide explicit validation of this assumption (e.g., memory generation protocol, held-out task results, and comparison to student-generated memories) for the on-device claim to be load-bearing.
- [Ablation studies] The claim that both distillation axes contribute complementarily is stated but not quantified in the provided text. The ablations across eight models must include specific metrics (e.g., success rates per axis) and controls to show the contributions are additive rather than redundant.
minor comments (2)
- [Abstract] The abstract sentence is truncated mid-phrase ('both distillation axes contribute complementary').
- Exact memory sizes ('a few megabytes') and LoRA parameter counts should be reported with precise values and storage format in the main text or a table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying our evaluation protocol and ablation results. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 4.3% → 77.9% gain on ALFWorld lacks any mention of baselines, error bars, data splits, ablation controls, or evaluation protocol. Without these, it is impossible to determine whether the central claim is supported or vulnerable to post-hoc selection.
Authors: We agree the abstract should reference key evaluation details for context. The 4.3% is the unaugmented 4B baseline and 77.9% is the full DuoMem result on the standard ALFWorld test split (as described in Section 4). Error bars, data splits, and ablation controls are reported in the main text and tables. We will revise the abstract to explicitly note the evaluation protocol, baseline definition, and reference to ablations to address this concern. revision: yes
-
Referee: [Evaluation] The central claim depends on teacher-generated memories being higher-quality, procedural (not instance-specific), and directly usable by prepending to the student without format/alignment issues. The manuscript must provide explicit validation of this assumption (e.g., memory generation protocol, held-out task results, and comparison to student-generated memories) for the on-device claim to be load-bearing.
Authors: Section 3.2 details the memory generation protocol, where the teacher produces procedural memories on held-out tasks to promote generality over instance-specific content. Ablations in Section 5 compare teacher vs. student-generated memories, showing the quality gap. We will add an explicit subsection with held-out task validation and format compatibility checks to make this assumption more load-bearing. revision: yes
-
Referee: [Ablation studies] The claim that both distillation axes contribute complementarily is stated but not quantified in the provided text. The ablations across eight models must include specific metrics (e.g., success rates per axis) and controls to show the contributions are additive rather than redundant.
Authors: The manuscript states that both axes contribute complementarily based on ablations across 2B-72B models, but we acknowledge the need for more explicit per-axis quantification. We will expand the ablation tables and figures to report success rates for context-only, parameter-only, and combined settings, along with controls demonstrating additive gains rather than redundancy. revision: yes
Circularity Check
No circularity in empirical distillation framework
full rationale
The paper presents DuoMem as an empirical dual-space distillation approach that transfers procedural problem-solving from a teacher LLM to a student via prepending teacher memories and LoRA fine-tuning on teacher trajectories. Performance gains on ALFWorld (e.g., 4.3% to 77.9%) are reported as measured experimental outcomes of applying this method, with no equations, first-principles derivations, or predictions that reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided text; the framework is self-contained against external benchmarks via direct evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Teacher-generated procedural memories are of higher quality than those produced by the student model.
- domain assumption Fine-tuning LoRA adapters on teacher trajectories transfers procedural ability to the student model.
Reference graph
Works this paper leans on
-
[1]
Shridhar, Mohit and Yuan, Xingdi and Cote, Marc-Alexandre and Bisk, Yonatan and Trischler, Adam and Hausknecht, Matthew , booktitle=
-
[2]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Shafran, Izhak and Narasimhan, Karthik R and Cao, Yuan , booktitle=
-
[3]
Hu, Edward J and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , booktitle=
-
[4]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
Scaling data-constrained language models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , journal=
-
[8]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S , booktitle=
-
[9]
Zhang, Ceyao and Yang, Kaijie and Hu, Siyi and Wang, Zihao and Li, Guanghe and Sun, Yihang and Zhang, Cheng and Zhang, Zhaowei and Liu, Anji and Zhu, Song-Chun and others , booktitle=
-
[10]
Transactions on Machine Learning Research , year=
Cognitive architectures for language agents , author=. Transactions on Machine Learning Research , year=
-
[11]
Majumder, Bodhisattwa Prasad and Mishra, Bhavana Dalvi and Jansen, Peter and Tafjord, Oyvind and Tandon, Niket and Zhang, Li and Callison-Burch, Chris and Clark, Peter , booktitle=
-
[12]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[13]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , journal=
-
[15]
A Survey on Knowledge Distillation of Large Language Models
A survey on knowledge distillation of large language models , author=. arXiv preprint arXiv:2402.13116 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Distilling step-by-step!
Hsieh, Cheng-Yu and Li, Chun-Liang and Yeh, Chih-Kuan and Nakhost, Hootan and Fujii, Yasuhisa and Ratner, Alex and Krishna, Ranjay and Lee, Chen-Yu and Pfister, Tomas , booktitle=. Distilling step-by-step!
-
[17]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal=
-
[18]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Gemma 3 Technical Report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
, howpublished =
Gemma 4 is a family of open models, purpose-built for advanced reasoning and agentic workflows. , howpublished =
-
[21]
Advances in Neural Information Processing Systems , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Trial and error:
Song, Yifan and Yin, Da and Yue, Xiang and Huang, Jie and Li, Sujian and Lin, Bill Yuchen , booktitle=. Trial and error:
-
[23]
Selective self-rehearsal:
Gupta, Sonam and Nandwani, Yatin and Yehudai, Asaf and Mishra, Mayank and Pandey, Gaurav and Raghu, Dinesh and Joshi, Sachindra , journal=. Selective self-rehearsal:
-
[24]
Reflexion:
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , journal=. Reflexion:
-
[25]
Zhu, Yuqi and Qiao, Shuofei and Ou, Yixin and Deng, Shumin and Lyu, Shiwei and Shen, Yue and Liang, Lei and Gu, Jinjie and Chen, Huajun and Zhang, Ningyu , booktitle=
-
[26]
Kagaya, Tomoyuki and Yuan, Thong Jing and Lou, Yuxuan and Karlekar, Jayashree and Pranata, Sugiri and Kinose, Akira and Oguri, Koki and Wick, Felix and You, Yang , booktitle=
-
[27]
Li, Junkai and Lai, Yunghwei and Li, Weitao and Ren, Jingyi and Zhang, Meng and Kang, Xinhui and Wang, Siyu and Li, Peng and Zhang, Ya-Qin and Ma, Weizhi and others , journal=
-
[28]
International Conference on Machine Learning , pages=
Specializing smaller language models towards multi-step reasoning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[29]
Shridhar, Mohit and Thomason, Jesse and Gordon, Daniel and Bisk, Yonatan and Han, Winson and Mottaghi, Roozbeh and Zettlemoyer, Luke and Fox, Dieter , booktitle=. Alfred:
-
[30]
Fang, Runnan and Liang, Yuan and Wang, Xiaobin and Wu, Jialong and Qiao, Shuofei and Xie, Pengjun and Huang, Fei and Chen, Huajun and Zhang, Ningyu , journal=
-
[31]
International Conference on Machine Learning , pages=
Agent Workflow Memory , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[32]
Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems , year=
Han, Dongge and Couturier, Camille and Diaz, Daniel Madrigal and Zhang, Xuchao and R. Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems , year=
-
[33]
Hosseini, Peyman and Bohdal, Ondrej and Ceritli, Taha and Castro, Ignacio and Purver, Matthew and Ozay, Mete and Michieli, Umberto , journal=
-
[34]
Efficient solutions for an intriguing failure of
Hosseini, Peyman and Castro, Ignacio and Ghinassi, Iacopo and Purver, Matthew , booktitle=. Efficient solutions for an intriguing failure of
-
[35]
You Need to Pay Better Attention:
Hosseini, Mehran and Hosseini, Peyman , journal=. You Need to Pay Better Attention:
-
[36]
Shenaj, Donald and Bohdal, Ondrej and Ceritli, Taha and Ozay, Mete and Zanuttigh, Pietro and Michieli, Umberto , booktitle=
-
[37]
Shenaj, Donald and Bohdal, Ondrej and Ozay, Mete and Zanuttigh, Pietro and Michieli, Umberto , booktitle=
-
[38]
Ceritli, Taha and Bohdal, Ondrej and Ozay, Mete and Moon, Jijoong and Lee, Kyeng-Hun and Ko, Hyeonmok and Michieli, Umberto , booktitle=
-
[39]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
On-device System of Compositional Multi-tasking in Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[40]
Bini, Massimo and Bohdal, Ondrej and Michieli, Umberto and Akata, Zeynep and Ozay, Mete and Ceritli, Taha , journal=
-
[41]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Demystifying small language models for edge deployment , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
A review on edge large language models:
Zheng, Yue and Chen, Yuhao and Qian, Bin and Shi, Xiufang and Shu, Yuanchao and Chen, Jiming , journal=. A review on edge large language models:. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.