When Does Non-Uniform Replay Matter in Reinforcement Learning?
Pith reviewed 2026-05-20 22:59 UTC · model grok-4.3
The pith
Non-uniform replay improves sample efficiency in reinforcement learning mainly when replay volume is low.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
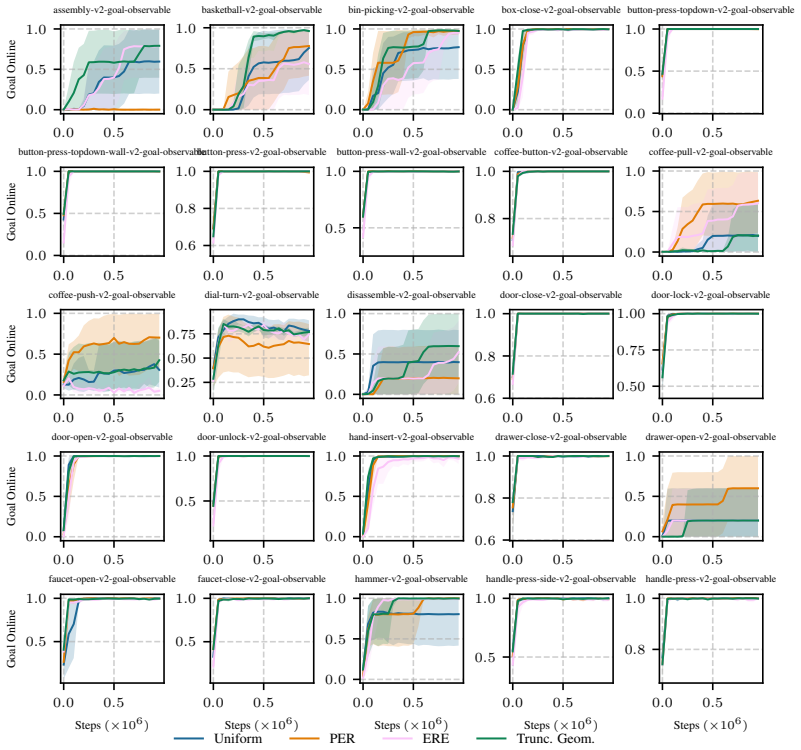
The effectiveness of non-uniform replay is governed by three factors: replay volume, expected recency, and the entropy of the replay sampling distribution. Non-uniform replay is most beneficial when replay volume is low, and high-entropy sampling is important even at comparable expected recency. Motivated by these findings, the authors adopt a simple Truncated Geometric replay that biases sampling toward recent experience while preserving high entropy and incurring negligible computational overhead, improving sample efficiency in low-volume regimes across large-scale parallel simulation, single-task, and multi-task settings with three modern algorithms on five RL benchmark suites.
What carries the argument
Three factors—replay volume (the number of replayed transitions per environment step), expected recency of sampled transitions, and entropy of the replay sampling distribution—that together determine when non-uniform sampling outperforms uniform sampling.
If this is right
- Non-uniform replay should be preferred in low replay-volume regimes to increase sample efficiency.
- Sampling distributions should be chosen for high entropy even when their expected recency is similar to uniform replay.
- The Truncated Geometric replay provides a low-cost way to bias toward recent transitions without losing entropy.
- Uniform replay remains adequate when replay volume is high, so added complexity is unnecessary.
- The same factor analysis applies to large-scale parallel, single-task, and multi-task reinforcement learning.
Where Pith is reading between the lines
- Similar volume-recency-entropy analysis could be applied to other memory mechanisms such as experience replay in supervised or imitation learning.
- In memory-constrained settings the low-volume non-uniform approach may allow training larger models on the same hardware budget.
- Combining the geometric bias with existing prioritized replay could test whether recency and importance weighting add together.
- The entropy emphasis may link to information-theoretic objectives that improve generalization in RL.
Load-bearing premise
The measured improvements arise from differences in replay volume, recency, and entropy rather than from unmeasured variations in experimental setups or algorithm implementations across the five benchmark suites.
What would settle it
An experiment that keeps replay volume low, matches expected recency and entropy across uniform and non-uniform samplers, and still finds no sample-efficiency difference would falsify the claim that these three factors govern the benefits.
Figures




















read the original abstract
Modern off-policy reinforcement learning algorithms often rely on simple uniform replay sampling and it remains unclear when and why non-uniform replay improves over this strong baseline. Across diverse RL settings, we show that the effectiveness of non-uniform replay is governed by three factors: replay volume, the number of replayed transitions per environment step; expected recency, how recent sampled transitions are; and the entropy of the replay sampling distribution. Our main contribution is clarifying when non-uniform replay is beneficial and providing practical guidance for replay design in modern off-policy RL. Namely, we find that non-uniform replay is most beneficial when replay volume is low, and that high-entropy sampling is important even at comparable expected recency. Motivated by these findings, we adopt a simple Truncated Geometric replay that biases sampling toward recent experience while preserving high entropy and incurring negligible computational overhead. Across large-scale parallel simulation, single-task, and multi-task settings, including three modern algorithms evaluated on five RL benchmark suites, this replay sampling strategy improves sample efficiency in low-volume regimes while remaining competitive when replay volume is high.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates when non-uniform replay sampling improves upon uniform sampling in off-policy RL. It identifies three governing factors—replay volume (replayed transitions per environment step), expected recency of sampled transitions, and entropy of the sampling distribution—and shows that non-uniform replay is most beneficial at low volume. Motivated by these observations, the authors introduce Truncated Geometric replay, which biases toward recent experience while preserving high entropy, and report improved sample efficiency in low-volume regimes across three algorithms and five benchmark suites spanning large-scale parallel, single-task, and multi-task settings.
Significance. If the experimental controls successfully isolate the contributions of volume, recency, and entropy, the work supplies actionable guidance for replay-buffer design in modern off-policy RL and clarifies why simple uniform sampling remains competitive at high volume. The emphasis on high-entropy sampling at comparable recency is a useful distinction that could influence practical implementations.
major comments (2)
- [Experimental Evaluation] The central attribution of performance gains to replay volume, expected recency, and entropy requires explicit controls that hold two factors fixed while varying the third. The manuscript does not describe such ablations or confirm that hyper-parameters and implementation details were matched across replay strategies within each of the five benchmark suites; without them the observed differences cannot be confidently assigned to the three factors rather than incidental setup variations.
- [Results and Discussion] The abstract and results sections state that Truncated Geometric replay improves sample efficiency in low-volume regimes, yet no table or figure reports the number of independent seeds, statistical significance tests, or confidence intervals for the reported gains. This omission weakens the claim that the improvements are robust across the three algorithms and five suites.
minor comments (2)
- [Preliminaries] Define 'expected recency' formally (e.g., as the expectation of the age of a sampled transition under the replay distribution) in the main text rather than only in the appendix.
- [Experimental Setup] Clarify whether replay volume was measured in absolute transitions or normalized by environment steps when comparing across parallel and single-task settings.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve the clarity of our experimental controls and the statistical reporting of results.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central attribution of performance gains to replay volume, expected recency, and entropy requires explicit controls that hold two factors fixed while varying the third. The manuscript does not describe such ablations or confirm that hyper-parameters and implementation details were matched across replay strategies within each of the five benchmark suites; without them the observed differences cannot be confidently assigned to the three factors rather than incidental setup variations.
Authors: We agree that explicit controls are necessary to attribute differences specifically to replay volume, expected recency, and entropy. In our experimental design, hyperparameters and implementation details (including network architectures, optimizers, and environment settings) were matched across replay strategies within each benchmark suite. We isolated the factors by (i) varying replay volume while using the same sampling distribution, (ii) comparing distributions with matched expected recency but differing entropy, and (iii) varying entropy at fixed volume and recency. However, we acknowledge that these controls were not described with sufficient detail or accompanied by dedicated ablation tables. In the revised manuscript we will add a new subsection titled 'Factor Isolation and Controls' that explicitly documents the held-constant values for each comparison, including parameter settings used to achieve comparable recency across distributions. revision: yes
-
Referee: [Results and Discussion] The abstract and results sections state that Truncated Geometric replay improves sample efficiency in low-volume regimes, yet no table or figure reports the number of independent seeds, statistical significance tests, or confidence intervals for the reported gains. This omission weakens the claim that the improvements are robust across the three algorithms and five suites.
Authors: We thank the referee for highlighting this omission. All reported results were obtained from multiple independent random seeds (five seeds for the single-task and multi-task suites and three seeds for the large-scale parallel suite). In the revised manuscript we will update all figures and result tables to report the number of seeds, include error bars or shaded regions showing mean ± standard deviation, and add a note on statistical significance (paired t-tests with p < 0.05) for the key comparisons between Truncated Geometric and uniform replay in the low-volume regime. These additions will be placed in the main results section and the appendix. revision: yes
Circularity Check
Empirical study with no circular derivations or self-referential predictions
full rationale
This paper is an empirical investigation that reports observations from controlled experiments across multiple RL algorithms and benchmark suites. It identifies governing factors (replay volume, expected recency, entropy) and motivates a Truncated Geometric sampler directly from those experimental outcomes rather than from any mathematical derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or uniqueness theorems are invoked that reduce to the paper's own inputs by construction; the central claims rest on comparative results that are presented as falsifiable observations rather than tautological restatements of the experimental design.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the effectiveness of non-uniform replay is governed by three factors: replay volume, expected recency, and the entropy of the replay sampling distribution
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Truncated Geometric replay that biases sampling toward recent experience while preserving high entropy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, and Marc G Belle- mare. Deep reinforcement learning at the edge of the statistical precipice.Advances in Neural Information Processing Systems, 2021
work page 2021
-
[2]
What matters for simulation to online reinforcement learning on real robots
Yarden As, Dhruva Tirumala, René Zurbrügg, Chenhao Li, Stelian Coros, Andreas Krause, and Markus Wulfmeier. What matters for simulation to online reinforcement learning on real robots. arXiv preprint arXiv:2602.20220, 2026
-
[3]
Distributed distributional deterministic policy gradients
Gabriel Barth-Maron, Matthew W Hoffman, David Budden, Will Dabney, Dan Horgan, TB Dhruva, Alistair Muldal, Nicolas Heess, and Timothy Lillicrap. Distributed distributional deterministic policy gradients. InInternational Conference on Learning Representations, 2018
work page 2018
-
[4]
Aditya Bhatt, Daniel Palenicek, Boris Belousov, Max Argus, Artemij Amiranashvili, Thomas Brox, and Jan Peters. CrossQ: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity. InInternational conference on learning representations (ICLR), 2024
work page 2024
-
[5]
Vittorio Caggiano, Huawei Wang, Guillaume Durandau, Massimo Sartori, and Vikash Kumar. Myosuite–a contact-rich simulation suite for musculoskeletal motor control.arXiv preprint arXiv:2205.13600, 2022
-
[6]
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
work page 1999
-
[7]
Sample-efficient reinforcement learning by breaking the replay ratio barrier
Pierluca D’Oro, Max Schwarzer, Evgenii Nikishin, Pierre-Luc Bacon, Marc G Bellemare, and Aaron Courville. Sample-efficient reinforcement learning by breaking the replay ratio barrier. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[8]
Compute-optimal scaling for value-based deep rl, 2025
Preston Fu, Oleh Rybkin, Zhiyuan Zhou, Michal Nauman, Pieter Abbeel, Sergey Levine, and Aviral Kumar. Compute-optimal scaling for value-based deep rl, 2025. URL https: //arxiv.org/abs/2508.14881
-
[9]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, 2018
work page 2018
-
[10]
Towards general-purpose model-free reinforcement learning.arXiv preprint arXiv:2501.16142, 2025
Scott Fujimoto, Pierluca D’Oro, Amy Zhang, Yuandong Tian, and Michael Rabbat. Towards general-purpose model-free reinforcement learning.arXiv preprint arXiv:2501.16142, 2025
-
[11]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, 2018
work page 2018
-
[12]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representa- tions, 2019
work page 2019
-
[13]
Array programming with numpy.Nature, 585(7825):357–362, 2020
Charles R Harris, K Jarrod Millman, Stéfan J Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J Smith, et al. Array programming with numpy.Nature, 585(7825):357–362, 2020
work page 2020
-
[14]
Rainbow: Combining improvements in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dab- ney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improvements in deep reinforcement learning. InThirty-Second AAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[15]
Information theory and statistical mechanics.Physical review, 106(4):620, 1957
Edwin T Jaynes. Information theory and statistical mechanics.Physical review, 106(4):620, 1957
work page 1957
-
[16]
Hojoon Lee, Dongyoon Hwang, Donghu Kim, Hyunseung Kim, Jun Jet Tai, Kaushik Subrama- nian, Peter R Wurman, Jaegul Choo, Peter Stone, and Takuma Seno. Simba: Simplicity bias for scaling up parameters in deep reinforcement learning.arXiv preprint arXiv:2410.09754, 2024. 11
-
[18]
Hojoon Lee, Youngdo Lee, Takuma Seno, Donghu Kim, Peter Stone, and Jaegul Choo. Hyperspherical normalization for scalable deep reinforcement learning.arXiv preprint arXiv:2502.15280, 2025
-
[19]
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[20]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Anto- nio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Human-level control through deep reinforcement learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcemen...
-
[22]
Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło´s, and Marek Cygan. Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control. Advances in neural information processing systems, 2024
work page 2024
-
[23]
Michal Nauman, Marek Cygan, Carmelo Sferrazza, Aviral Kumar, and Pieter Abbeel. Bigger, regularized, categorical: High-capacity value functions are efficient multi-task learners.arXiv preprint arXiv:2505.23150, 2025
-
[24]
Daniel Palenicek, Florian V ogt, Joe Watson, Ingmar Posner, and Jan Peters. Xqc: Well-conditioned optimization accelerates deep reinforcement learning.arXiv preprint arXiv:2509.25174, 2025
-
[25]
Pleiss, Tobias Sutter, and Maximilian Schiffer
Leonard S. Pleiss, Tobias Sutter, and Maximilian Schiffer. Reliability-adjusted prioritized experience replay, 2025. URLhttps://arxiv.org/abs/2506.18482
-
[26]
Martin L Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., 1994
work page 1994
-
[27]
Value-based deep rl scales predictably.arXiv preprint arXiv:2502.04327, 2025
Oleh Rybkin, Michal Nauman, Preston Fu, Charlie Snell, Pieter Abbeel, Sergey Levine, and Aviral Kumar. Value-based deep rl scales predictably.arXiv preprint arXiv:2502.04327, 2025
-
[28]
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. International Conference on Learning Representations (ICLR), 2015. 12
work page 2015
-
[29]
Prioritized experience replay,
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay,
-
[30]
URLhttps://arxiv.org/abs/1511.05952
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Sferrazza, C., Huang, D.-M., Lin, X., Lee, Y ., and Abbeel, P
Younggyo Seo, Carmelo Sferrazza, Juyue Chen, Guanya Shi, Rocky Duan, and Pieter Abbeel. Learning sim-to-real humanoid locomotion in 15 minutes.arXiv preprint arXiv:2512.01996, 2025
-
[32]
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control.arXiv preprint arXiv:2505.22642, 2025
-
[33]
Carmelo Sferrazza, Dun-Ming Huang, Xingyu Lin, Youngwoon Lee, and Pieter Abbeel. Hu- manoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation. arXiv preprint arXiv:2403.10506, 2024
-
[34]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
work page 2017
-
[35]
Laura Smith, Ilya Kostrikov, and Sergey Levine. A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning.arXiv preprint arXiv:2208.07860, 2022
-
[36]
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[37]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Boosting Soft Actor-Critic: Emphasizing Recent Experience without Forgetting the Past
Che Wang and Keith Ross. Boosting soft actor-critic: Emphasizing recent experience without forgetting the past, 2019. URLhttps://arxiv.org/abs/1906.04009
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
Che Wang, Yanqiu Wu, Quan Vuong, and Keith Ross. Striving for simplicity and performance in off-policy drl: Output normalization and non-uniform sampling. InInternational Conference on Machine Learning, pp. 10070–10080. PMLR, 2020
work page 2020
-
[40]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning.CoRR, abs/1910.10897, 2019. URLhttp://arxiv.org/abs/1910.10897. 13 A Limitations Our experiments focus on continuous-control off-policy RL, where replay buffers are cent...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.