Hybrid privacy-aware semantic search: SVD-truncated document geometry and CKKS-encrypted query reranking under a restricted threat model
Pith reviewed 2026-06-26 01:13 UTC · model grok-4.3
The pith
Truncating document embeddings onto a secret SVD subspace and rotating them, while reranking queries under CKKS encryption, establishes a tight lower bound on reconstruction error and maintains ranking quality at million-document scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
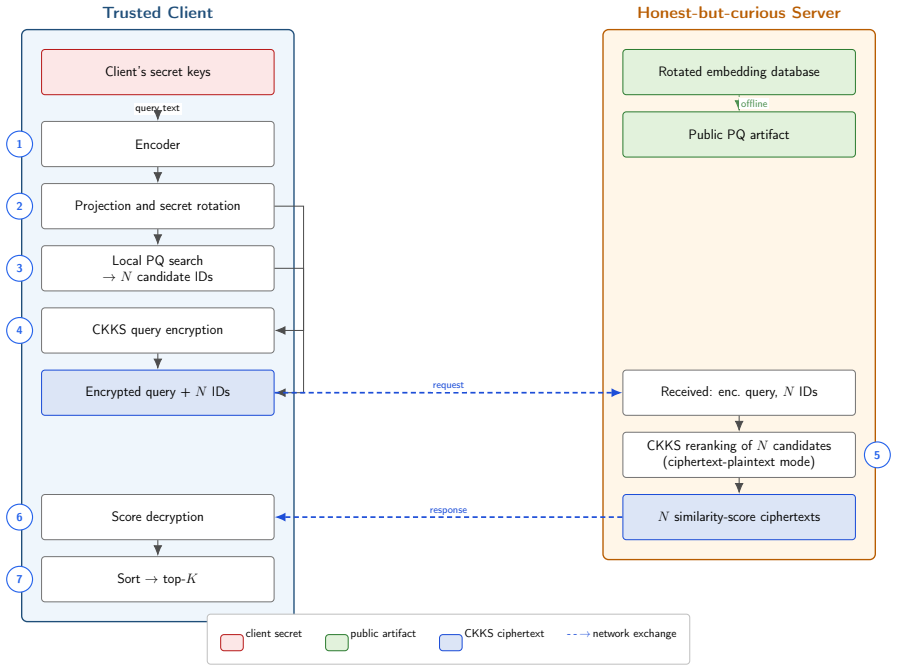
Protecting the static collection geometrically by projecting each embedding onto a lower-dimensional SVD subspace and applying a secret orthogonal rotation, while protecting the dynamic query by reranking it under CKKS homomorphic encryption, yields a tight lower bound on the reconstruction error of any attacker confined to the protected subspace; the scheme preserves ranking quality at million-document scale and sub-second latency, with document protection treated as empirical obfuscation rather than a cryptographic primitive.
What carries the argument
SVD-truncated document geometry combined with a secret orthogonal rotation for the collection and CKKS-encrypted reranking for the query.
If this is right
- Ranking quality is preserved or slightly improved on strong encoders, functioning as a linear denoiser.
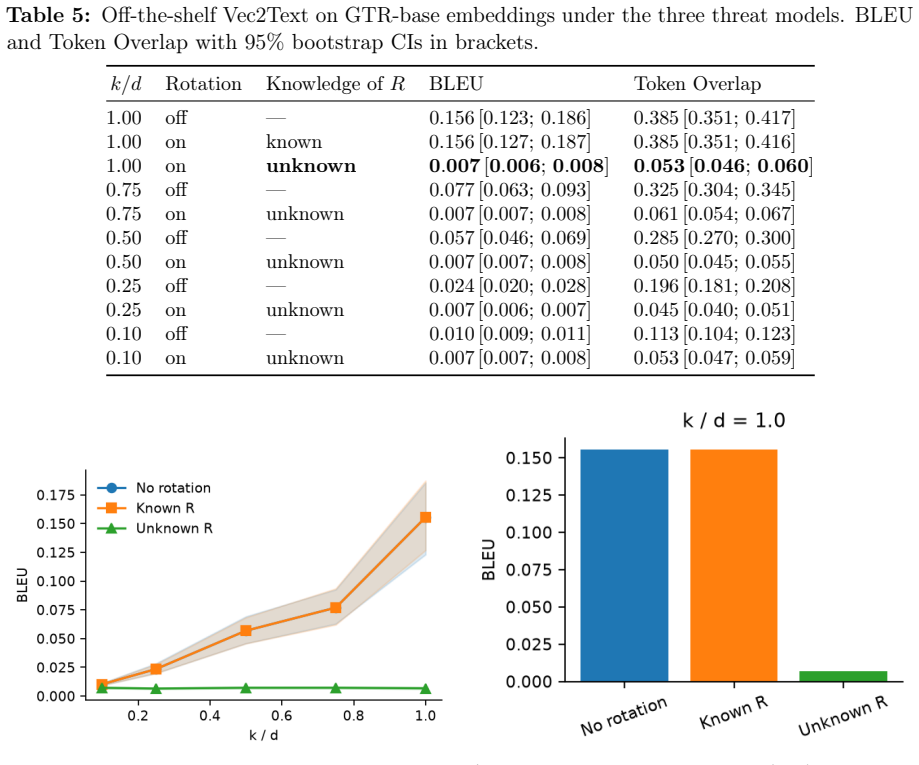
- Off-the-shelf inversion attacks on the protected space fall to the noise floor.
- A known-plaintext attacker recovers the rotation via orthogonal Procrustes once the number of leaked pairs approaches the retained dimension.
- Product-quantization codes retain most nearest-neighbor structure after protection.
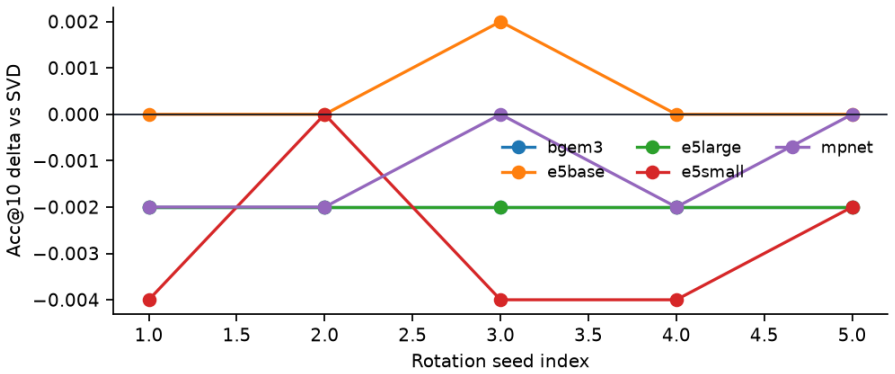
- Truncation accuracy cost depends on the encoder rather than acting as a universal denoiser.
Where Pith is reading between the lines
- The separation of static geometric protection from dynamic cryptographic protection could be tested on other retrieval-augmented generation pipelines to measure leakage reduction without full encryption cost.
- Varying the retained SVD dimension as a function of encoder strength offers a practical knob for tuning the accuracy-privacy trade-off in deployed systems.
- The approach suggests checking whether the same subspace truncation plus rotation can be combined with lighter query protections in settings where full CKKS reranking is too expensive.
- Public product-quantization codes surviving the protection layer points to a possible need for joint design of quantization and geometric masking in future vector databases.
Load-bearing premise
The secret orthogonal rotation stays unknown to the attacker and the SVD truncation supplies enough obfuscation for the empirical protection layer to work.
What would settle it
An attacker who only sees the protected subspace and the truncation dimension recovers source documents with error materially below the stated lower bound.
Figures
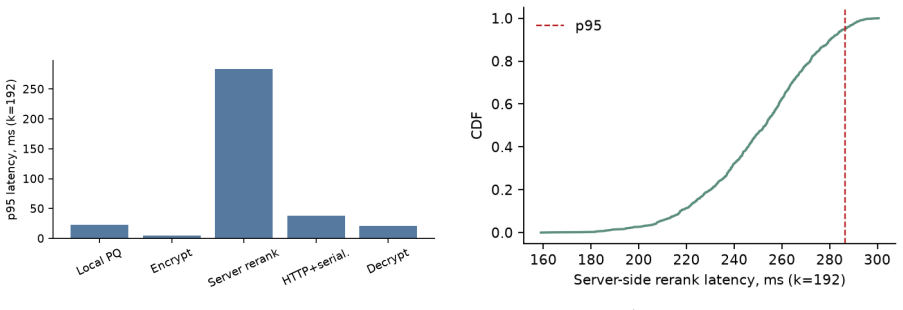
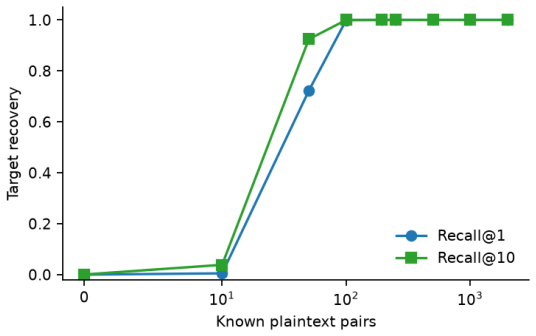
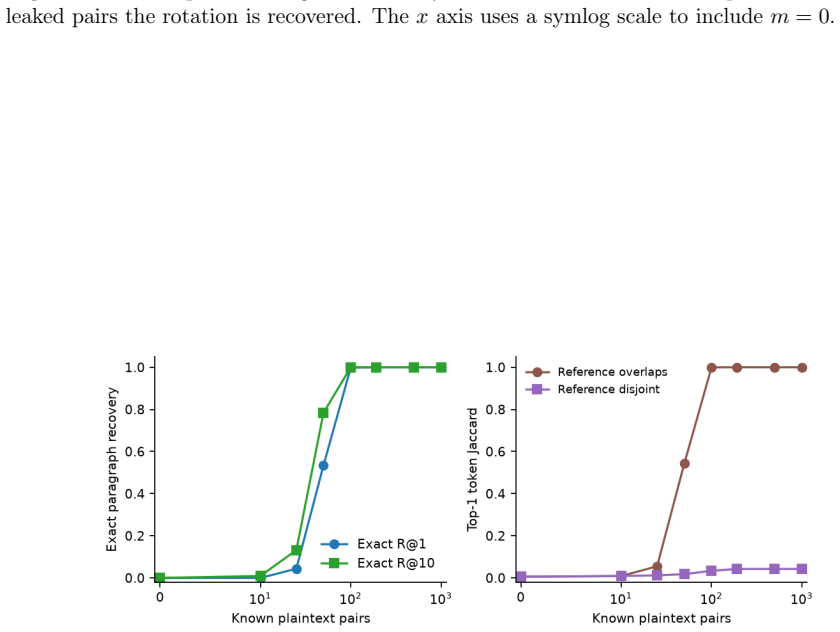
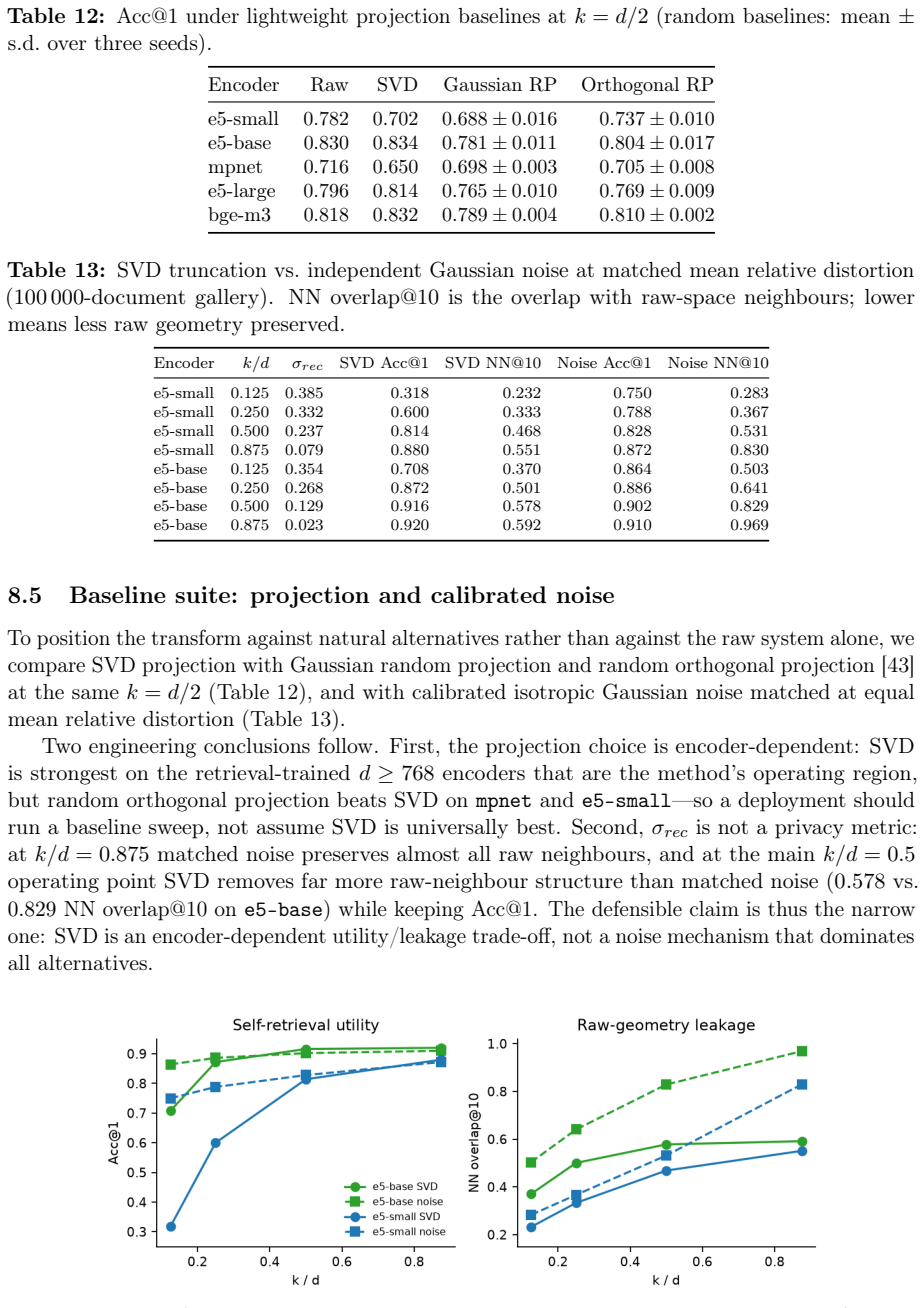
read the original abstract
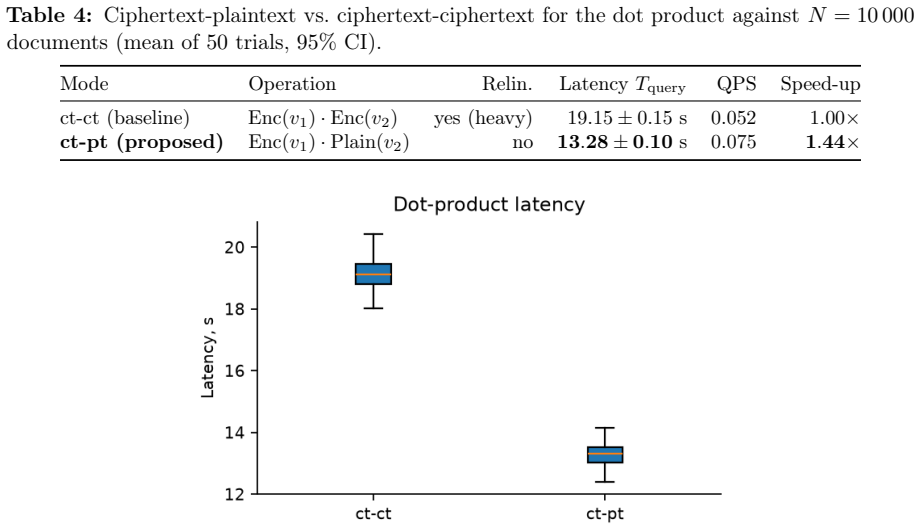
Dense embeddings power semantic search and retrieval-augmented generation, but embedding-inversion attacks can reconstruct source text from a vector: when a vector database leaks, the documents behind it leak too. The textbook defences are extremes - encrypting the whole search homomorphically is sound but too slow at million-document scale, while privacy noise degrades ranking long before it protects. We study a middle path exploiting the asymmetry between the static collection and the dynamic query. The collection is protected geometrically: each vector is truncated onto a lower-dimensional SVD subspace and rotated by a secret orthogonal transform known only to the owner. The query is protected cryptographically: it is reranked under CKKS homomorphic encryption, so an honest-but-curious server never sees the query or the scores. CKKS parameters come from a small offline benchmark. We prove a tight lower bound on the reconstruction error of any attacker confined to the protected subspace. On one million documents and five encoders the scheme preserves ranking quality (slightly improving it on strong encoders, as a linear denoiser) at sub-second latency, and an off-the-shelf inversion attack on the protected space collapses to the noise floor. We then test stronger adversaries: a known-plaintext attacker recovers the rotation by orthogonal Procrustes from about as many leaked pairs as the retained dimension; the public product-quantization codes preserve most nearest-neighbour structure; and random-projection, calibrated-noise and BEIR baselines show the truncation is an encoder-dependent accuracy cost, not a free denoiser. We state the limits: query confidentiality is cryptographic, but document protection is an empirical obfuscation layer (SVD truncation plus a secret rotation), not a cryptographic primitive, and we delimit the threat model for each claim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid privacy-preserving semantic search system. Static document embeddings are protected geometrically via SVD subspace truncation followed by a secret orthogonal rotation known only to the owner; dynamic queries are protected via CKKS homomorphic encryption during reranking on an honest-but-curious server. The authors claim a tight lower bound on reconstruction error for any attacker confined to the protected subspace, report that ranking quality is preserved (and slightly improved on strong encoders) across 1M documents and five encoders at sub-second latency, and show that an off-the-shelf inversion attack falls to the noise floor. Stronger adversaries (known-plaintext Procrustes recovery, public PQ codes) are tested, and the document-protection component is explicitly labeled an empirical obfuscation layer rather than a cryptographic primitive, with the threat model delimited accordingly.
Significance. If the lower-bound derivation holds and the 1M-document experiments are reproducible, the work supplies a concrete middle path between full homomorphic search (impractical at scale) and additive noise (utility loss). Strengths include the explicit scoping of the threat model, the use of standard primitives (SVD, orthogonal transforms, CKKS), the observation that truncation can function as a linear denoiser for strong encoders, and the honest delimitation that document protection is empirical. These elements make the contribution falsifiable within its stated model and potentially useful for practical retrieval systems.
major comments (2)
- [Proof of the tight lower bound] Proof of the tight lower bound on reconstruction error (abstract and limits/threat-model section): the claim that the bound is tight for attackers confined to the SVD-truncated rotated subspace is load-bearing for the privacy guarantee, yet the derivation steps relating the retained dimension, the secret rotation, and the resulting error floor are not visible; without an explicit inequality or reduction showing how the bound is obtained and why it remains tight against the tested inversion attacks, it is unclear whether the bound is achieved or merely asserted.
- [Experimental ranking results] Experimental ranking results on 1M documents (results section): the statements that ranking quality is preserved and 'slightly improving it on strong encoders, as a linear denoiser' are central to the utility claim, but the manuscript does not report effect sizes, variance across encoders, or statistical tests; without these, the improvement cannot be distinguished from experimental noise and the denoiser interpretation remains unsupported.
minor comments (3)
- [Abstract] The abstract refers to 'five encoders' without naming them; listing the specific models and their dimensionalities in the experimental setup would improve reproducibility.
- [CKKS parameters] CKKS parameters are stated to come from 'a small offline benchmark'; the exact selection criteria, security level, and resulting latency/accuracy trade-offs should be tabulated or described in the methods.
- Notation for the SVD truncation dimension k and the secret rotation matrix R is introduced late; defining these symbols at first use would aid readability of the geometric-protection description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The two major comments identify areas where the manuscript's presentation of the lower-bound derivation and experimental statistics can be strengthened for greater clarity and rigor. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Proof of the tight lower bound] Proof of the tight lower bound on reconstruction error (abstract and limits/threat-model section): the claim that the bound is tight for attackers confined to the SVD-truncated rotated subspace is load-bearing for the privacy guarantee, yet the derivation steps relating the retained dimension, the secret rotation, and the resulting error floor are not visible; without an explicit inequality or reduction showing how the bound is obtained and why it remains tight against the tested inversion attacks, it is unclear whether the bound is achieved or merely asserted.
Authors: We acknowledge that while the manuscript states a tight lower bound on reconstruction error for attackers limited to the protected subspace, the explicit derivation steps, inequality, and reduction relating retained dimension, secret rotation, and error floor are not fully detailed in the main text. We will revise the limits/threat-model section to include a complete step-by-step derivation demonstrating how the bound is obtained and its tightness against the inversion attacks evaluated in the experiments. revision: yes
-
Referee: [Experimental ranking results] Experimental ranking results on 1M documents (results section): the statements that ranking quality is preserved and 'slightly improving it on strong encoders, as a linear denoiser' are central to the utility claim, but the manuscript does not report effect sizes, variance across encoders, or statistical tests; without these, the improvement cannot be distinguished from experimental noise and the denoiser interpretation remains unsupported.
Authors: We agree that the results section does not report effect sizes, per-encoder variance, or statistical tests to support the claims of preserved (and slightly improved) ranking quality or the linear denoiser interpretation. In the revision we will add these elements, including standard deviations across runs, appropriate effect-size measures, and statistical significance tests, to allow readers to evaluate the strength of the observed improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core claims—a mathematical lower bound on reconstruction error within the SVD-truncated rotated subspace, ranking preservation under CKKS reranking, and explicit scoping to a restricted threat model—rely on standard external linear-algebra and cryptographic primitives rather than any self-referential fitting, self-citation chain, or redefinition of inputs as outputs. Document protection is labeled an empirical layer, not a primitive, and no equations or results reduce by construction to parameters fitted from the same data. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- SVD truncation dimension
- CKKS encryption parameters
axioms (2)
- domain assumption The attacker is confined to the protected subspace and does not obtain the secret rotation matrix except via known-plaintext attacks with limited pairs.
- domain assumption Orthogonal Procrustes attack success depends on the number of leaked pairs relative to retained dimension.
Reference graph
Works this paper leans on
-
[1]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” inProc. EMNLP, 2019, pp. 3982–3992. 21
2019
-
[2]
Text Embeddings by Weakly-Supervised Contrastive Pre- training,
L. Wang, N. Yang, X. Huang, et al., “Text Embeddings by Weakly-Supervised Contrastive Pre- training,”arXiv:2212.03533, 2022
Pith/arXiv arXiv 2022
-
[3]
Large Dual Encoders Are Generalizable Retrievers,
J. Ni et al., “Large Dual Encoders Are Generalizable Retrievers,” inProc. EMNLP, 2022, pp. 9844–9855
2022
-
[4]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation,” arXiv:2402.03216, 2024
Pith/arXiv arXiv 2024
-
[5]
Dense Passage Retrieval for Open-Domain Question Answering,
V. Karpukhin et al., “Dense Passage Retrieval for Open-Domain Question Answering,” inProc. EMNLP, 2020, pp. 6769–6781
2020
-
[6]
ColBERT: Efficient and Effective Passage Search via Contextualised Late Interaction over BERT,
O. Khattab and M. Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualised Late Interaction over BERT,” inProc. ACM SIGIR, 2020, pp. 39–48
2020
-
[7]
Text Embeddings Reveal (Almost) As Much As Text,
J. X. Morris, V. Kuleshov, V. Shmatikov, and A. M. Rush, “Text Embeddings Reveal (Almost) As Much As Text,” inProc. EMNLP, 2023
2023
-
[8]
Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence,
H. Li, M. Xu, and Y. Song, “Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence,” inFindings of ACL, 2023, pp. 14022–14040
2023
-
[9]
Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries,
Y.-H. Huang, Y. Tsai, H. Hsiao, H.-Y. Lin, and S.-D. Lin, “Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries,” inProc. ACL (Long), 2024, pp. 4193–4205
2024
-
[10]
ALGEN: Few-shot Inversion Attacks on Textual Embeddings via Cross-Model Alignment and Generation,
Y. Chen, Q. Xu, and J. Bjerva, “ALGEN: Few-shot Inversion Attacks on Textual Embeddings via Cross-Model Alignment and Generation,” inProc. ACL (Long), 2025, pp. 24330–24348. arXiv:2502.11308
arXiv 2025
-
[11]
Universal Zero-shot Embedding Inversion,
C. Zhang, J. X. Morris, and V. Shmatikov, “Universal Zero-shot Embedding Inversion,” arXiv:2504.00147, 2025
arXiv 2025
-
[12]
Harnessing the Universal Geometry of Embeddings (vec2vec),
R. Jha, C. Zhang, V. Shmatikov, and J. X. Morris, “Harnessing the Universal Geometry of Embeddings (vec2vec),”arXiv:2505.12540, 2025
arXiv 2025
-
[13]
Zero2Text: Zero-Training Cross-Domain Inversion Attacks on Textual Embeddings,
D. Kim, D. Kang, K. Lee, H. Baek, and B. B. Kang, “Zero2Text: Zero-Training Cross-Domain Inversion Attacks on Textual Embeddings,”arXiv:2602.01757, 2026
arXiv 2026
-
[14]
The Good and the Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG),
S. Zeng et al., “The Good and the Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG),” inFindings of ACL, 2024, pp. 4505–4524
2024
-
[15]
Information Leakage in Embedding Models,
C. Song and A. Raghunathan, “Information Leakage in Embedding Models,” inProc. ACM CCS, 2020, pp. 377–390
2020
-
[16]
Membership Inference Attacks Against Machine Learning Models,
R. Shokri et al., “Membership Inference Attacks Against Machine Learning Models,” inProc. IEEE S&P, 2017, pp. 3–18
2017
-
[17]
Extracting Training Data from Large Language Models,
N. Carlini et al., “Extracting Training Data from Large Language Models,” inProc. USENIX Security, 2021, pp. 2633–2650
2021
-
[18]
Differential Privacy,
C. Dwork, “Differential Privacy,” inProc. ICALP, 2006, pp. 1–12
2006
-
[19]
Deep Learning with Differential Privacy,
M. Abadi et al., “Deep Learning with Differential Privacy,” inProc. ACM CCS, 2016, pp. 308–318
2016
-
[20]
Differentially Private Representation for NLP,
L. Lyu, X. He, and Y. Li, “Differentially Private Representation for NLP,” inFindings of EMNLP, 2020, pp. 2355–2365
2020
-
[21]
Privacy via the Johnson-Lindenstrauss Transform,
K. Kenthapadi, A. Korolova, I. Mironov, and N. Mishra, “Privacy via the Johnson-Lindenstrauss Transform,”J. Privacy and Confidentiality, vol. 5, no. 1, 2013
2013
-
[22]
Random Projection-Based Multiplicative Data Perturbation for Privacy Preserving Distributed Data Mining,
K. Liu, H. Kargupta, and J. Ryan, “Random Projection-Based Multiplicative Data Perturbation for Privacy Preserving Distributed Data Mining,”IEEE TKDE, vol. 18, no. 1, 2006, pp. 92–106. 22
2006
-
[23]
Homomorphic Encryption for Arithmetic of Approximate Numbers,
J. H. Cheon, A. Kim, M. Kim, and Y. Song, “Homomorphic Encryption for Arithmetic of Approximate Numbers,” inAdvances in Cryptology—ASIACRYPT 2017, LNCS 10624, pp. 409–437
2017
-
[24]
Bootstrapping for Approximate Homomorphic Encryption,
J. H. Cheon, K. Han, A. Kim et al., “Bootstrapping for Approximate Homomorphic Encryption,” in Advances in Cryptology—EUROCRYPT 2018, LNCS 10820, pp. 360–384
2018
-
[25]
Homomorphic Encryption Security Standard,
M. Albrecht et al., “Homomorphic Encryption Security Standard,” HomomorphicEncryption.org, 2018
2018
-
[26]
On the Concrete Hardness of Learning with Errors,
M. R. Albrecht, R. Player, and S. Scott, “On the Concrete Hardness of Learning with Errors,”Journal of Mathematical Cryptology, vol. 9, no. 3, 2015, pp. 169–203 (lattice-estimator methodology)
2015
-
[27]
A Generalized Solution of the Orthogonal Procrustes Problem,
P. H. Schönemann, “A Generalized Solution of the Orthogonal Procrustes Problem,”Psychometrika, vol. 31, no. 1, 1966, pp. 1–10
1966
-
[28]
OpenFHE: Open-Source Fully Homomorphic Encryption Library,
A. Al Badawi et al., “OpenFHE: Open-Source Fully Homomorphic Encryption Library,” inProc. WAHC ’22, 2022, pp. 53–63
2022
-
[29]
EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation,
R. Dathathri et al., “EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation,” inProc. ACM PLDI, 2020, pp. 546–561
2020
-
[30]
CHET: An Optimizing Compiler for Fully-Homomorphic Neural-Network Inferencing,
R. Dathathri et al., “CHET: An Optimizing Compiler for Fully-Homomorphic Neural-Network Inferencing,” inProc. ACM PLDI, 2019, pp. 142–156
2019
-
[31]
Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimisation with GPUs,
W. Jung, S. Kim, J. H. Ahn et al., “Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimisation with GPUs,”IACR TCHES, vol. 2021, no. 4, pp. 114–148
2021
-
[32]
Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52,
F. Boemer et al., “Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52,” inProc. WAHC ’21, 2021, pp. 57–62
2021
-
[33]
CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy,
R. Gilad-Bachrach et al., “CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy,” inProc. ICML, 2016, vol. 48, pp. 201–210
2016
-
[34]
Private Web Search with Tiptoe,
A. Henzinger, E. Dauterman, H. Corrigan-Gibbs, and N. Zeldovich, “Private Web Search with Tiptoe,” inProc. ACM SOSP, 2023
2023
-
[35]
PIR with Compressed Queries and Amortised Query Processing,
S. Angel, H. Chen, K. Laine, and S. Setty, “PIR with Compressed Queries and Amortised Query Processing,” inProc. IEEE S&P, 2018, pp. 962–979
2018
-
[36]
One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval (SimplePIR),
A. Henzinger, M. M. Hong, H. Corrigan-Gibbs, S. Meiklejohn, and V. Vaikuntanathan, “One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval (SimplePIR),” in Proc. USENIX Security, 2023
2023
-
[37]
OnionPIR: Response Efficient Single-Server PIR,
M. H. Mughees, H. Chen, and L. Ren, “OnionPIR: Response Efficient Single-Server PIR,” inProc. ACM CCS, 2021, pp. 2292–2306
2021
-
[38]
Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions,
N. Halko, P.-G. Martinsson, and J. A. Tropp, “Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions,”SIAM Review, vol. 53, no. 2, 2011, pp. 217–288
2011
-
[39]
Product Quantisation for Nearest Neighbor Search,
H. Jegou, M. Douze, and C. Schmid, “Product Quantisation for Nearest Neighbor Search,”IEEE TPAMI, vol. 33, no. 1, 2011, pp. 117–128
2011
-
[40]
Efficient and Robust Approximate Nearest Neighbour Search Using Hierarchical Navigable Small World Graphs,
Y. A. Malkov and D. A. Yashunin, “Efficient and Robust Approximate Nearest Neighbour Search Using Hierarchical Navigable Small World Graphs,”IEEE TPAMI, vol. 42, no. 4, 2020, pp. 824–836
2020
-
[41]
Milvus: A Purpose-Built Vector Data Management System,
J. Wang, X. Yi, R. Guo et al., “Milvus: A Purpose-Built Vector Data Management System,” inProc. ACM SIGMOD, 2021, pp. 2614–2627
2021
-
[42]
The Approximation of One Matrix by Another of Lower Rank,
C. Eckart and G. Young, “The Approximation of One Matrix by Another of Lower Rank,”Psychome- trika, vol. 1, no. 3, 1936, pp. 211–218
1936
-
[43]
Extensions of Lipschitz Mappings into a Hilbert Space,
W. B. Johnson and J. Lindenstrauss, “Extensions of Lipschitz Mappings into a Hilbert Space,” Contemporary Mathematics, vol. 26, 1984, pp. 189–206. 23
1984
-
[44]
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models,
N. Thakur, N. Reimers, A. Rücklé, A. Srivastava, and I. Gurevych, “BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models,” inProc. NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[45]
BLEU: a Method for Automatic Evaluation of Machine Translation,
K. Papineni et al., “BLEU: a Method for Automatic Evaluation of Machine Translation,” inProc. ACL, 2002, pp. 311–318
2002
-
[46]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,
P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” inProc. NeurIPS, 2020
2020
-
[47]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,
A. Asai et al., “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,” in Proc. ICLR, 2024
2024
-
[48]
Corrective Retrieval Augmented Generation,
S.-Q. Yan et al., “Corrective Retrieval Augmented Generation,”arXiv:2401.15884, 2024
Pith/arXiv arXiv 2024
-
[49]
Retrieval-Augmented Generation for Large Language Models: A Survey,
Y. Gao et al., “Retrieval-Augmented Generation for Large Language Models: A Survey,” arXiv:2312.10997, 2024
Pith/arXiv arXiv 2024
-
[50]
S. M. Kurilenko, “Hybrid Method for Privacy-Preserving Semantic Search Based on Homomorphic Encryption and Random Projections,”Vestnik Komp’yuternykh i Informatsionnykh Tekhnologiy, no. 3, 2026, pp. 44–49. doi:10.14489/vkit.2026.03.pp.044-049. 24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.