SplitZip: Ultra Fast Lossless KV Compression for Disaggregated LLM Serving
Pith reviewed 2026-05-12 01:10 UTC · model grok-4.3
The pith
SplitZip achieves over 600 GB/s lossless KV cache compression on GPUs by encoding frequent exponents with fixed-length codes and routing rare ones through a sparse escape stream.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
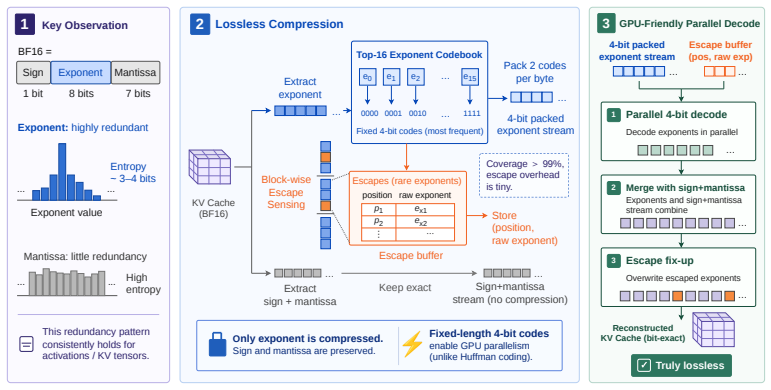
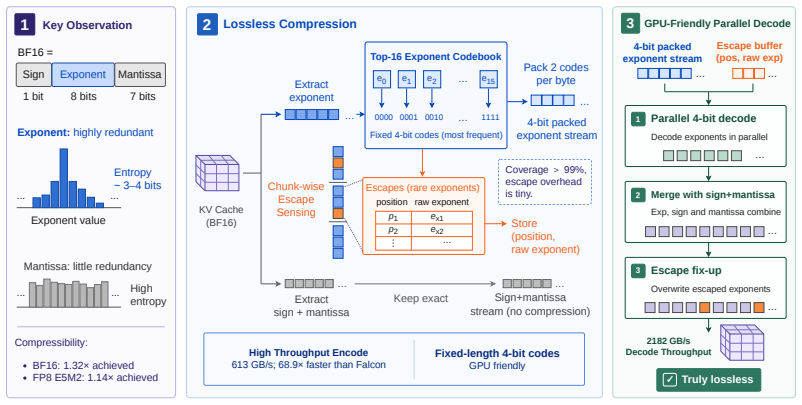
SplitZip preserves KV tensors bitwise by encoding the most frequent exponent values from an offline-calibrated top-16 codebook with fixed-length codes and routing rare exponents through a sparse escape stream of (position, value) pairs. The resulting dense-plus-sparse structure runs at high throughput on GPUs without online histogramming or variable-length decoding.
What carries the argument
The offline top-16 exponent codebook that supplies fixed-length codes for the dense path together with a sparse escape correction stream for rare values.
If this is right
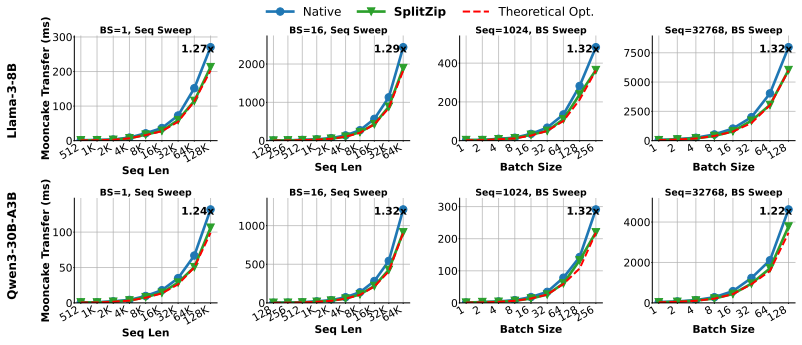
- KV cache transfers between prefill and decode workers become up to 1.32 times faster while remaining exactly lossless.
- Time-to-first-token improves by up to 1.30 times in disaggregated serving setups.
- Request throughput rises by 1.23 times because the transfer step no longer dominates latency.
- The same exponent-coding approach yields up to 1.14 times compression on FP8 KV caches relative to native E5M2 storage.
Where Pith is reading between the lines
- Disaggregated clusters could support longer contexts or higher concurrency by reducing the network bandwidth required for each request.
- Operators might lower the cost of high-bandwidth interconnects between prefill and decode nodes if the compression is adopted widely.
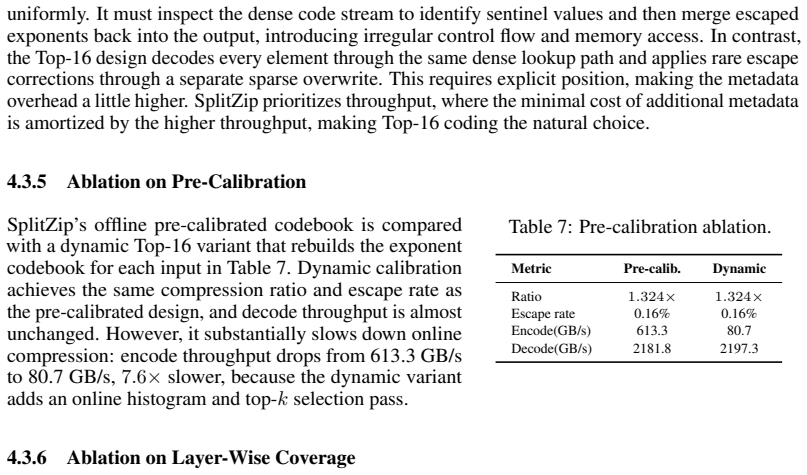
- Periodic recalibration of the codebook on representative production traces would be needed to keep performance stable across changing workloads.
Load-bearing premise
The distribution of exponents seen during online prefill will stay close enough to the offline top-16 calibration that most values receive short codes and the escape stream stays small.
What would settle it
Run SplitZip end-to-end on a long-context or agentic workload whose exponent distribution differs from the calibration set and check whether the measured compression ratio drops below 1.1 times or the transfer speedup disappears.
Figures

read the original abstract
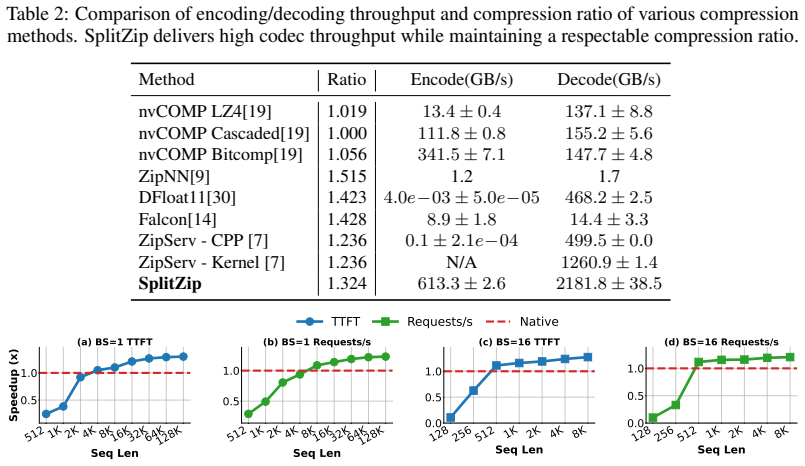
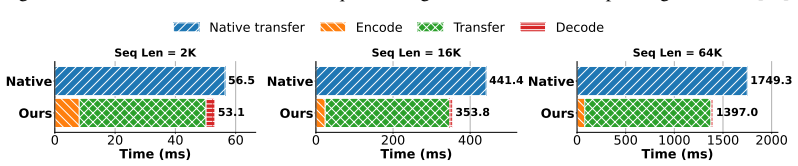
Contemporary systems serving large language models (LLMs) have adopted prefill-decode disaggregation to load-balance between the compute-bound prefill phase and the memory-bound decode phase. Under this design, prefill workers generate a KV cache that must be transferred to decode workers before generation can begin. With these workers residing on different physical systems, this transfer becomes a significant bottleneck to serving LLMs at scale, especially for long-input and agentic workloads. Existing lossless codecs are unsuitable here as they primarily target offline weight compression, run on CPUs, or use variable-length coding whose compression cannot keep up with KV production during prefill. We introduce SplitZip, a GPU-friendly lossless compressor for KV cache transfer that preserves KV tensors bitwise and integrates into existing serving frameworks without modifying model execution. SplitZip exploits redundancy in floating-point exponents of KV activations, encoding frequent exponent values with fixed-length codes and routing rare exponents through a sparse escape stream of (position, value). A calibrated top-16 exponent codebook eliminates online histogramming, while the regular dense path and sparse escape correction make both encoding and decoding efficient on GPUs. On real BF16 activation tensors, SplitZip achieves $613.3$ GB/s compression throughput and $2181.8$ GB/s decompression throughput, outperforming prior lossless compressors on the critical codec path. End-to-end transfer experiments show up to $1.32\times$ speedup for BF16 KV cache transfer, $1.30\times$ speedup for TTFT, and $1.23\times$ increase in Request Throughput. The same approach extends to FP8 KV caches, providing up to $1.14\times$ compression over native E5M2. Code is available at https://github.com/Intelligent-Microsystems-Lab/SplitZip
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SplitZip, a GPU-optimized lossless compressor for KV cache tensors in prefill-decode disaggregated LLM serving. It exploits observed redundancy in BF16 (and FP8) floating-point exponents by encoding the 16 most frequent values with a fixed 4-bit codebook calibrated offline and routing infrequent exponents through a sparse escape stream of (position, value) pairs. The design avoids online histogramming and variable-length coding to achieve high throughput on the critical compression path while preserving tensors bitwise and integrating into existing serving stacks without model changes. On real BF16 activation tensors it reports 613.3 GB/s compression and 2181.8 GB/s decompression throughput, yielding up to 1.32× KV transfer speedup, 1.30× TTFT improvement, and 1.23× request throughput increase; the same approach gives up to 1.14× compression for FP8 E5M2 caches.
Significance. If the offline top-16 codebook generalizes and escape overhead stays negligible across models and workloads, SplitZip would provide a practical, drop-in reduction in the KV transfer bottleneck that currently limits disaggregated serving for long-context and agentic workloads. The reported throughputs substantially exceed typical CPU-based lossless codecs and the GPU-friendly dense-plus-sparse structure is a clear engineering contribution. Reproducible end-to-end speedups on real tensors would be a useful data point for the community.
major comments (2)
- [Abstract and experimental evaluation] The headline speedups (1.32× transfer, 1.30× TTFT, 1.23× throughput) rest on the claim that an offline-calibrated top-16 exponent codebook keeps the sparse escape stream negligible on online prefill KV tensors. No escape-rate statistics, calibration corpus description, or sensitivity sweeps across models, layers, or context lengths are supplied; if escape density rises, both throughput and effective compression ratio degrade, undermining the central efficiency argument.
- [Method and evaluation sections] The lossless (bitwise-preserving) property is asserted for both the dense codebook path and the escape correction, yet the verification procedure—bit-exact tensor comparison, checksums, or test-suite coverage—is not described. This is load-bearing for the “lossless” claim and for any downstream correctness guarantees in serving systems.
minor comments (1)
- [Introduction / System overview] A small diagram or pseudocode snippet illustrating the data-flow between prefill worker, SplitZip encoder, network transfer, and decode worker would clarify integration without model changes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we provide point-by-point responses to the major comments and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] The headline speedups (1.32× transfer, 1.30× TTFT, 1.23× throughput) rest on the claim that an offline-calibrated top-16 exponent codebook keeps the sparse escape stream negligible on online prefill KV tensors. No escape-rate statistics, calibration corpus description, or sensitivity sweeps across models, layers, or context lengths are supplied; if escape density rises, both throughput and effective compression ratio degrade, undermining the central efficiency argument.
Authors: We agree with the referee that the manuscript would benefit from explicit escape-rate statistics and sensitivity analysis to support the efficiency claims. In the revised version, we will add these details to the experimental evaluation section. Specifically, we will describe the calibration corpus used for the offline top-16 codebook and present escape-rate measurements across different models, layers, and context lengths. We will also include sensitivity sweeps to demonstrate that the escape stream remains negligible under the evaluated conditions, thereby reinforcing the reported speedups without degradation. revision: yes
-
Referee: [Method and evaluation sections] The lossless (bitwise-preserving) property is asserted for both the dense codebook path and the escape correction, yet the verification procedure—bit-exact tensor comparison, checksums, or test-suite coverage—is not described. This is load-bearing for the “lossless” claim and for any downstream correctness guarantees in serving systems.
Authors: We acknowledge that the current manuscript does not detail the verification procedure for the lossless property. In the revised manuscript, we will expand the method section to describe our verification process, which involves bit-exact tensor comparisons between original and reconstructed KV caches, along with checksum validations and comprehensive test-suite coverage. This addition will substantiate the bitwise-preserving nature of both the dense codebook path and the escape correction mechanism. revision: yes
Circularity Check
No circularity; algorithmic design with offline calibration is self-contained
full rationale
The paper presents SplitZip as a direct GPU implementation that encodes frequent BF16 exponents via a fixed offline top-16 codebook and routes rare values through an explicit sparse escape stream of (position, value) pairs. This construction is described as an engineering choice based on observed exponent redundancy in KV tensors, with throughput numbers reported as measured results on real activation data rather than any derived prediction. No equations reduce a claimed result to its own fitted parameters by construction, no self-citation supplies a load-bearing uniqueness theorem, and the calibration step is a one-time preprocessing step external to the online compression path. The derivation chain therefore contains no self-definitional, fitted-input, or ansatz-smuggling reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-16 exponent codebook
axioms (1)
- domain assumption KV activations in BF16 and FP8 formats exhibit sufficient redundancy in floating-point exponents to allow effective lossless compression via fixed codes for common values and sparse handling for rare ones.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SplitZip exploits redundancy in floating-point exponents of KV activations, encoding the most frequent exponent values with fixed-length codes and routing rare exponents through a sparse escape stream of (position, value). An offline calibrated top-16 exponent codebook eliminates online-histogramming
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the compression ratio is ρ=2/(3/2 + 3ϵ). As escape rates decrease, ρ approaches 4/3 asymptotically
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SpectrumKV: Per-Token Mixed-Precision KV Cache Transfer for Prefill-Decode Disaggregated LLM Serving
SpectrumKV applies per-token mixed-precision KV cache transfer (FP16/INT8/INT4) with a model-specific probe for INT4 tolerance, achieving better perplexity and retrieval than PDTrim at equivalent budgets on Qwen2.5-7B...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.