DisjunctiveNet: Neural Symbolic Learning via Differentiable Convexified Optimization Layers
Pith reviewed 2026-06-29 08:39 UTC · model grok-4.3
The pith
Neural networks can enforce exact satisfaction of input-dependent mixed-integer rules by embedding convex relaxations of disjunctive constraints as differentiable optimization layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that representing rules as disjunctive constraints and applying hierarchical convex relaxations yields tractable linear constraints that embed as differentiable optimization layers, enabling end-to-end neural network training with exact satisfaction of hard, input-dependent mixed integer linear constraints.
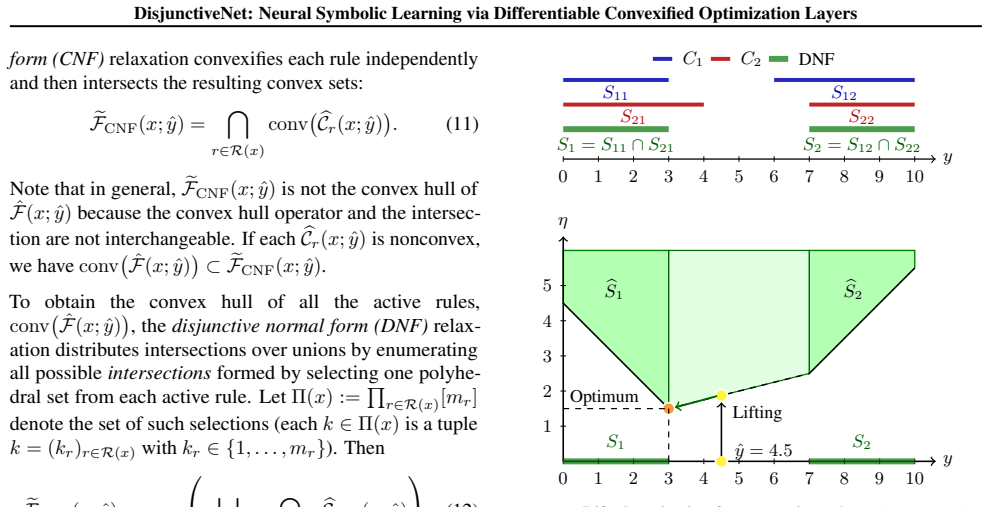
What carries the argument
Hierarchical convex relaxations of disjunctive constraints that produce convex hull formulations embeddable as differentiable linear optimization layers.
Load-bearing premise
The hierarchical convex relaxations produce optimal solutions that coincide exactly with the feasible set of the original mixed-integer constraints for the rules encountered in the target applications.
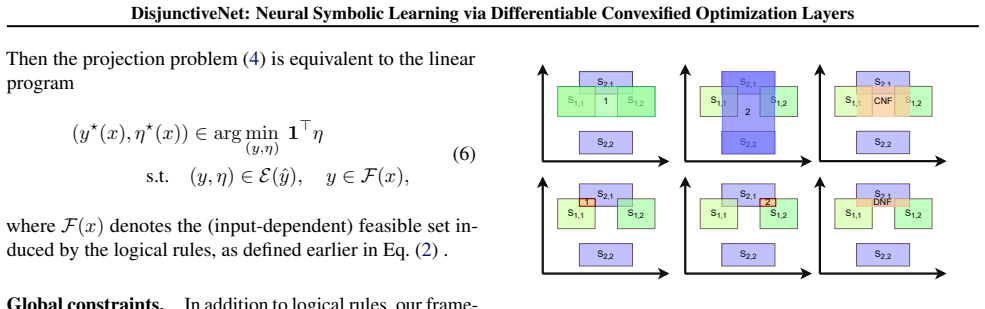
What would settle it
A test input where the network output after the optimization layer violates one of the original logical rules would show that the relaxation does not preserve exact feasibility.
Figures
read the original abstract
Many learning tasks in science and engineering are characterized by sparse datasets, which limits the effectiveness of purely data-driven approaches. At the same time, these problems are often accompanied by rich domain knowledge derived from physical laws, operational requirements, and expert heuristics. Such knowledge is frequently expressed as rules involving logical propositions and linear inequalities. Existing neuro-symbolic methods typically enforce these rules approximately through soft penalties, assume input-independent rules when designing specialized architectures, or rely on non-differentiable post-processing at inference time to achieve hard constraint satisfaction. While recent advances in differentiable optimization layers enable end-to-end feasibility enforcement within neural networks, extending these approaches to logical or mixed-integer rules remains challenging due to inherent nonconvexity. In this work, we propose a unified end-to-end framework for enforcing hard, input-dependent mixed integer linear constraints within neural networks. Our approach represents rules as disjunctive constraints and applies hierarchical convex relaxations to obtain convex hull formulations. These relaxations yield tractable linear constraints that can be embedded as differentiable optimization layers while enabling exact rule satisfaction. We demonstrate the effectiveness of the proposed framework on real-world datasets, achieving perfect rule satisfaction and strong predictive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DisjunctiveNet, a unified end-to-end framework for embedding hard, input-dependent mixed-integer linear constraints (represented as disjunctive constraints) into neural networks. It applies hierarchical convex relaxations to obtain convex-hull formulations that are embedded as differentiable optimization layers, claiming this enables exact rule satisfaction at inference while supporting training with strong predictive performance on real-world datasets with sparse data and domain knowledge.
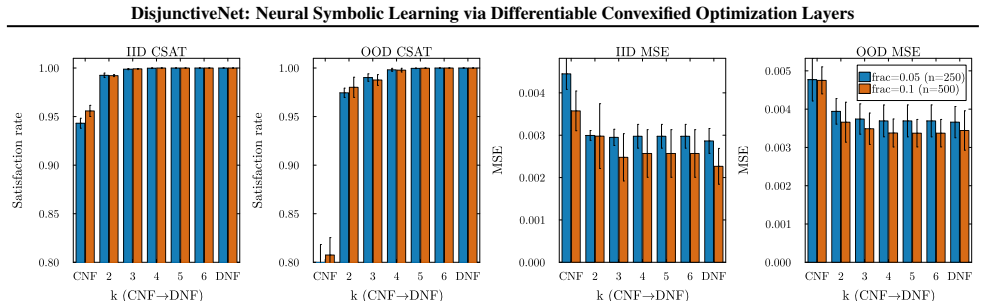
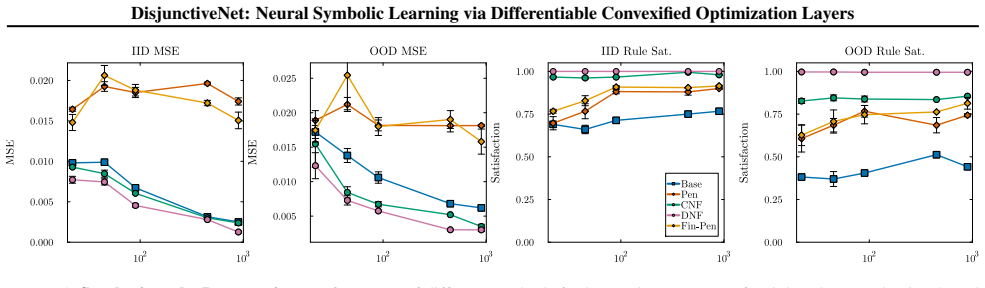
Significance. If the hierarchical convex relaxations are shown to produce tight convex-hull formulations whose optima coincide exactly with the original mixed-integer feasible sets for the target rule structures, the work would advance neuro-symbolic learning by providing a principled way to enforce complex logical rules differentiably without soft penalties or non-differentiable post-processing.
major comments (1)
- [Abstract] Abstract (paragraph on the proposed approach): The central claim that the hierarchical convex relaxations 'yield tractable linear constraints ... while enabling exact rule satisfaction' and produce 'convex hull formulations' requires that the relaxations are tight (i.e., their optimal solutions coincide with the mixed-integer feasible set). The manuscript must provide a proof, explicit conditions, or empirical verification that no fractional solutions remain for the input-dependent disjunctions considered; otherwise the differentiable layer can return points satisfying the continuous relaxation but violating the original logical rules.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to substantiate the tightness of the relaxations. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on the proposed approach): The central claim that the hierarchical convex relaxations 'yield tractable linear constraints ... while enabling exact rule satisfaction' and produce 'convex hull formulations' requires that the relaxations are tight (i.e., their optimal solutions coincide with the mixed-integer feasible set). The manuscript must provide a proof, explicit conditions, or empirical verification that no fractional solutions remain for the input-dependent disjunctions considered; otherwise the differentiable layer can return points satisfying the continuous relaxation but violating the original logical rules.
Authors: We agree that the claim of exact rule satisfaction at inference requires the relaxations to be tight. The manuscript constructs the hierarchical convex relaxations precisely to recover convex-hull formulations of the input-dependent disjunctive sets (see Sections 3.2–3.3), with the layer solved via the resulting linear program. To make this explicit, we will add a dedicated subsection in the revised manuscript that states the conditions under which the hierarchy yields the convex hull, includes a short proof sketch for the disjunctive structures considered, and reports an empirical check confirming that the layer outputs lie at vertices of the original mixed-integer feasible set on the evaluated rule families. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a framework that represents rules as disjunctive MIL constraints and applies hierarchical convex relaxations to produce convex-hull linear programs embeddable as differentiable layers. The central claim that these relaxations enable exact rule satisfaction rests on the asserted coincidence of the relaxed optima with the original mixed-integer feasible set for the target rule structures. No equations or steps in the provided text reduce a prediction or result to a fitted parameter by construction, nor does any load-bearing premise collapse to a self-citation chain; the derivation is presented as a direct technical construction from standard convex-relaxation techniques. The method is therefore self-contained against external benchmarks of the relaxation properties.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1287/ijoc.2022.0283. Ceria, S. and Soares, J. Convex programming for disjunctive convex optimization.Mathematical Programming, 86(3): 595–614, 1999. Chen, H., Flores, G. E. C., and Li, C. Physics-informed neural networks with hard linear equality constraints. Computers & Chemical Engineering, 189:108764, 10
-
[2]
ISSN 00981354. doi: 10.1016/j.compchemeng. 2024.108764. Chen, R. T., Rubanova, Y ., Bettencourt, J., and Duvenaud, D. K. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018. Constante-Flores, G. E., Chen, H., and Li, C. Enforcing hard linear constraints in deep learning models with decision rules.Advances in ...
-
[3]
Fischer, M., Balunovic, M., Drachsler-Cohen, D., Gehr, T., Zhang, C., and Vechev, M
Springer, 2020. Fischer, M., Balunovic, M., Drachsler-Cohen, D., Gehr, T., Zhang, C., and Vechev, M. DL2: Training and query- ing neural networks with logic. In Chaudhuri, K. and Salakhutdinov, R. (eds.),Proceedings of the 36th Inter- national Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 1931–
2020
-
[4]
Frerix, T., Niesner, M., and Cremers, D
PMLR, 09–15 Jun 2019. Frerix, T., Niesner, M., and Cremers, D. Homogeneous linear inequality constraints for neural network activa- tions. In2020 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition Workshops (CVPRW), pp. 3229–3234. IEEE, 6 2020. ISBN 978-1-7281-9360-1. doi: 10.1109/CVPRW50498.2020.00382. Giunchiglia, E., Stoian, M. C., and Lu...
-
[5]
Multi-agentmotionplanningusingdifferentialgameswithlexicographicpreferences,
URL https://openreview.net/forum? id=rx0TCew0Lj. Tabas, D. and Zhang, B. Safe and efficient model predictive control using neural networks: An interior point approach. In2022 IEEE 61st Conference on Decision and Control (CDC), pp. 1142–1147. IEEE, 12 2022. ISBN 978-1- 6654-6761-2. doi: 10.1109/CDC51059.2022.9993046. Tordesillas, J., How, J. P., and Hutter...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.