A Topological Characterization of Graph Neural Networks via Stochastic Block Model Embeddings on the n-Sphere
Pith reviewed 2026-06-28 23:41 UTC · model grok-4.3
The pith
Trained message-passing neural networks factor through bounded step-graphon signals that embed as disjoint spherical caps on the n-sphere.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
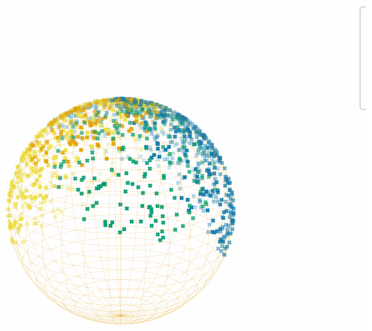
For any prescribed tolerance ε>0, a trained MPNN Φ acting on a sufficiently large graph factors (up to ε) through a step-graphon-signal of bounded complexity, and an explicit measure-preserving map Ψ_n:[0,1]→S^{n−1} places the SBM regions on disjoint spherical caps. This produces a problem-agnostic, low-dimensional fingerprint of a trained GNN that is amenable to visual inspection and to nearest-neighbour search across model zoos, enabling transfer-learning candidate retrieval without retraining.
What carries the argument
The explicit measure-preserving map Ψ_n from the unit interval to the (n-1)-sphere that separates stochastic block model regions into disjoint spherical caps.
If this is right
- The spherical embedding yields a fingerprint that supports nearest-neighbour retrieval of transfer-learning candidates without retraining.
- Concentration of measure in high dimension directly limits the approach for LLM-scale embeddings.
- The same construction applies to any MPNN that satisfies the cut-distance Lipschitz property.
- The framework supplies five listed directions for extension, including hyperbolic and Grassmannian alternatives.
Where Pith is reading between the lines
- The same spherical-cap separation might be tested by feeding known families of trained GNNs and measuring the minimal cap radius needed to keep blocks disjoint.
- Replacing the sphere with a hyperbolic space could reduce the concentration-of-measure obstruction for higher-dimensional fingerprints.
- The cut-distance factoring step could be replaced by a Gromov-Wasserstein distance computation to obtain an isometry-free comparison metric.
Load-bearing premise
Message-passing neural networks are Lipschitz continuous with respect to the cut distance on graphons.
What would settle it
An explicit trained MPNN and sequence of graphs where the network output cannot be approximated within ε by any step-graphon-signal whose blocks map to disjoint caps under any measure-preserving embedding into the sphere.
Figures
read the original abstract
We propose a topological framework for comparing trained Graph Neural Networks (GNNs) by mapping the Stochastic Block Models (SBMs) induced on the graphon-signal space of a Message Passing Neural Network (MPNN) onto the unit $n$-sphere $\sphere^{n-1}\subset\R^n$. The construction rests on three classical pillars: the \emph{compactness} of the cut-distance graphon space $(\Wo,\cutdist)$ \citep{lovasz2006limits,lovasz2012large}, the Frieze--Kannan \emph{weak regularity lemma} together with its graphon-signal extension due to \citet{levie2023graphon}, and the Lipschitz continuity of MPNNs with respect to the cut-distance. We show that, for any prescribed tolerance $\varepsilon>0$, a trained MPNN $\Phi$ acting on a sufficiently large graph factors (up to $\varepsilon$) through a step-graphon-signal of bounded complexity, and we construct an explicit measure-preserving map $\Psi_n\colon[0,1]\to\sphere^{n-1}$ that places the SBM regions on disjoint spherical caps. This produces a problem-agnostic, low-dimensional ``fingerprint'' of a trained GNN that is amenable to visual inspection and to nearest-neighbour search across model zoos, enabling \emph{transfer-learning candidate retrieval} without retraining. We discuss the obstruction posed by concentration of measure in high dimension -- a phenomenon directly relevant to LLM-scale embeddings. We close with five concrete future research directions: hyperbolic and Grassmannian alternatives to the spherical model, Gromov--Wasserstein distances on graphon-signals as an isometry-free alternative to the $n$-sphere map, an information-geometric (Fisher) reformulation of the SBM manifold, persistent-homology fingerprints of layer-wise embedding clouds, and a spectral-distance baseline derived from the graphon eigendecomposition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a topological framework for comparing trained MPNNs by embedding the SBM regions induced in the graphon-signal space onto the unit n-sphere via an explicit measure-preserving map Ψ_n : [0,1] → S^{n-1} that places the regions on disjoint spherical caps. The construction rests on three pillars: compactness of (W, cutdist), the Frieze-Kannan weak regularity lemma (with graphon-signal extension), and Lipschitz continuity of MPNNs w.r.t. cut-distance; this yields an ε-factorization of any trained MPNN through a bounded-complexity step-graphon-signal, producing low-dimensional fingerprints for visual inspection and transfer-learning retrieval. The manuscript also discusses concentration of measure and lists five future directions.
Significance. If the explicit map Ψ_n is measure-preserving with disjoint caps and the Lipschitz property holds uniformly, the framework supplies a problem-agnostic topological fingerprint of trained GNNs that could enable nearest-neighbor search across model zoos without retraining; the explicit construction and the high-dimensional caveat are concrete strengths.
major comments (2)
- [Abstract] Abstract (central claim paragraph): the Lipschitz continuity of MPNNs w.r.t. cut-distance is invoked as one of the three classical pillars to transfer the ε-approximation from the step-graphon-signal to the MPNN output, yet unlike compactness or Frieze-Kannan this property is architecture-dependent (depth, permutation-invariant aggregation, activations) and may fail to be uniform when layers or feature dimension increase; without a self-contained argument or reference establishing the required uniform bound, the ε-factorization does not follow.
- [Construction of Ψ_n] Construction of Ψ_n (the paragraph introducing the map): the manuscript asserts an explicit measure-preserving map Ψ_n : [0,1] → S^{n-1} that places SBM regions on disjoint spherical caps, but supplies no derivation, no verification that the map is measure-preserving, and no check that the caps remain disjoint after embedding; this verification is load-bearing for the fingerprint claim.
minor comments (2)
- The abstract states that the map produces a "problem-agnostic, low-dimensional fingerprint" but does not quantify the dimension n needed to keep caps disjoint for a given number of SBM blocks; a brief bound or example would clarify practicality.
- The discussion of concentration of measure is relevant but should be tied explicitly to the choice of n in the spherical embedding (e.g., via a reference to the dimension at which nearest-neighbor search degrades).
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (central claim paragraph): the Lipschitz continuity of MPNNs w.r.t. cut-distance is invoked as one of the three classical pillars to transfer the ε-approximation from the step-graphon-signal to the MPNN output, yet unlike compactness or Frieze-Kannan this property is architecture-dependent (depth, permutation-invariant aggregation, activations) and may fail to be uniform when layers or feature dimension increase; without a self-contained argument or reference establishing the required uniform bound, the ε-factorization does not follow.
Authors: We agree that Lipschitz continuity of MPNNs w.r.t. cut-distance is architecture-dependent and that uniformity requires explicit conditions on depth, aggregation, and activations. The manuscript invokes this property as a classical pillar (drawing on results for standard MPNNs with Lipschitz activations), but does not supply a self-contained argument or specific reference establishing the uniform bound needed for the ε-factorization. We will add a clarifying paragraph with appropriate references in the revised version to make this step rigorous. revision: yes
-
Referee: [Construction of Ψ_n] Construction of Ψ_n (the paragraph introducing the map): the manuscript asserts an explicit measure-preserving map Ψ_n : [0,1] → S^{n-1} that places SBM regions on disjoint spherical caps, but supplies no derivation, no verification that the map is measure-preserving, and no check that the caps remain disjoint after embedding; this verification is load-bearing for the fingerprint claim.
Authors: The referee is correct that the explicit construction, measure-preservation proof, and disjointness verification for Ψ_n are load-bearing and were not provided. Although the manuscript states that such a map is constructed, the derivation and checks are absent from the text. We will include the full explicit construction, measure-preservation argument, and disjoint-cap verification (possibly in an appendix) in the revision. revision: yes
Circularity Check
No circularity: derivation rests on external classical theorems without self-referential reduction
full rationale
The paper invokes three external pillars—Lovász–Szegedy compactness of (W, cutdist), the Frieze–Kannan weak regularity lemma with its Levie et al. graphon-signal extension, and Lipschitz continuity of MPNNs w.r.t. cut distance—to obtain the ε-factorization of Φ through a bounded-complexity step-graphon-signal. The map Ψ_n : [0,1] → S^{n-1} is introduced by explicit construction that places SBM blocks on disjoint caps; it is not obtained by fitting or by renaming an input. No self-citations appear among the load-bearing steps, and no equation or claim reduces by construction to a fitted parameter or prior result authored by the same team. The derivation chain therefore remains self-contained against the cited external results.
Axiom & Free-Parameter Ledger
axioms (3)
- standard math Compactness of the cut-distance graphon space (Wo, cutdist)
- standard math Frieze-Kannan weak regularity lemma and its graphon-signal extension
- domain assumption Lipschitz continuity of MPNNs with respect to the cut-distance
invented entities (1)
-
Explicit measure-preserving map Ψ_n : [0,1] → S^{n-1}
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fine-grained expressivity of graph neural networks
Jan Böker, Ron Levie, Ningyuan Huang, Soledad Villar, and Christopher Morris. Fine-grained expressivity of graph neural networks. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023),
2023
-
[2]
arXiv:2306.03698. Gunnar Carlsson. Topology and data.Bulletin of the American Mathematical Society, 46(2):255–308,
-
[3]
arXiv:2106.03693. George Cybenko. Approximation by superpositions of a sigmoidal function.Mathematics of Control, Signals, and Systems, 2(4):303–314,
-
[4]
Schoenholz, Patrick F
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. InProceedings of the 34th International Conference on Machine Learning (ICML 2017), volume 70 ofProceedings of Machine Learning Research, pages 1263–1272. PMLR,
2017
-
[5]
Neural Message Passing for Quantum Chemistry
arXiv:1704.01212. Allen Hatcher.Algebraic Topology. Cambridge University Press, Cambridge,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Strategies for pre-training graph neural networks
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks. InInternational Conference on Learning Representations (ICLR 2020),
2020
- [7]
-
[8]
Semi-Supervised Classification with Graph Convolutional Networks
arXiv:1609.02907. Michel Ledoux.The Concentration of Measure Phenomenon. Mathematical Surveys and Monographs
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
On the transferability of spectral graph filters
Ron Levie, Elvin Isufi, and Gitta Kutyniok. On the transferability of spectral graph filters. In 13th International Conference on Sampling Theory and Applications (SampTA 2019),
2019
-
[10]
On the Transferability of Spectral Graph Filters
arXiv:1901.10524. 16 Ron Levie. A graphon-signal analysis of graph neural networks. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023),
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[11]
László Lovász.Large Networks and Graph Limits
arXiv:2305.15987. László Lovász.Large Networks and Graph Limits. AMS Colloquium Publications
-
[12]
Invariant and equivariant graph networks
Haggai Maron, Heli Ben-Hamu, Nadav Shamir, and Yaron Lipman. Invariant and equivariant graph networks. InInternational Conference on Learning Representations (ICLR 2019),
2019
-
[13]
Invariant and Equivariant Graph Networks
arXiv:1812.09902. Sohir Maskey, Ron Levie, Yunseok Lee, and Gitta Kutyniok. Generalization analysis of message passing neural networks on large random graphs. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022),
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
arXiv:2202.00645. Facundo Mémoli. Gromov–Wasserstein distances and the metric approach to object matching. Foundations of Computational Mathematics, 11(4):417–487,
-
[15]
Poincaré embeddings for learning hierarchical representations
Maximilian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical representations. InAdvances in Neural Information Processing Systems 30 (NIPS 2017),
2017
-
[16]
Generalization, expressivity, and universal- ity of graph neural networks on attributed graphs
Levi Rauchwerger, Stefanie Jegelka, and Ron Levie. Generalization, expressivity, and universal- ity of graph neural networks on attributed graphs. InInternational Conference on Learning Representations (ICLR 2025),
2025
-
[17]
arXiv:2411.05464. Luana Ruiz, Luiz F. O. Chamon, and Alejandro Ribeiro. Graphon neural networks and the transferability of graph neural networks. InAdvances in Neural Information Processing Systems 33 (NeurIPS 2020),
-
[18]
Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, and Alexander B
arXiv:2006.03548. Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, and Alexander B. Wiltschko. A gentle introduction to graph neural networks.Distill, 2021.https://distill.pub/2021/gnn-intro/. doi:10.23915/distill.00033. Frederic Sala, Christopher De Sa, Albert Gu, and Christopher Ré. Representation tradeoffs for hyperbolic embeddings. InProceedings o...
-
[19]
Karl-Theodor Sturm. The space of spaces: Curvature bounds and gradient flows on the space of metric measure spaces.arXiv:1208.0434,
-
[20]
Graph attention networks
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations (ICLR 2018),
2018
-
[21]
arXiv:1710.10903. Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InInternational Conference on Learning Representations (ICLR 2019), 2019a. arXiv:1810.00826. 17 Hongteng Xu, Dixin Luo, and Lawrence Carin. Gromov–Wasserstein learning for graph matching and node embedding. InProceedings of the 36th Interna...
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.