Persistent AI Agents in Academic Research: A Single-Investigator Implementation Case Study
Pith reviewed 2026-07-01 16:10 UTC · model grok-4.3
The pith
A persistent AI agent embedded in academic research ran on 82.9 percent cached tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
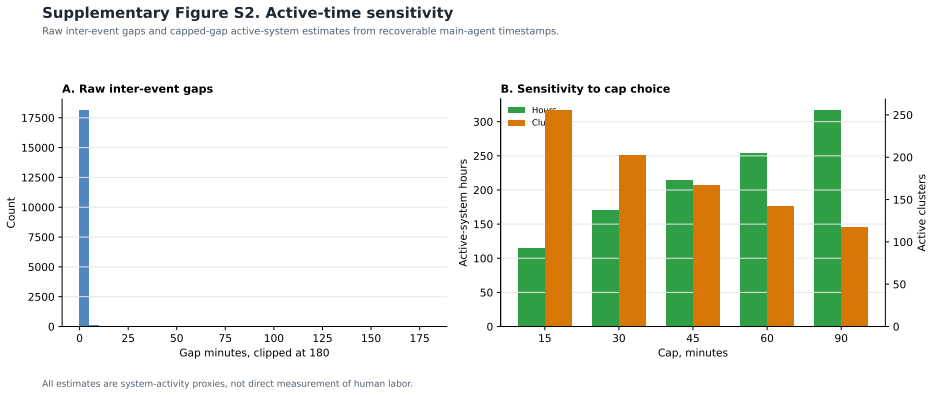
In a persistent agentic research environment the workflow proved cache-dominant, with 82.9 percent of the 73.95 million recorded tokens in a strict May 2026 trajectory subset consisting of cache reads. Across the full period the system logged 75,671 de-duplicated records, 482 output-proxy events, and 889 failure-verification-correction events while maintaining 502 memory files and 17 agent directories. The authors state that this pattern indicates persistent agentic environments shift the economic unit from cost per token to cost per completed artifact.
What carries the argument
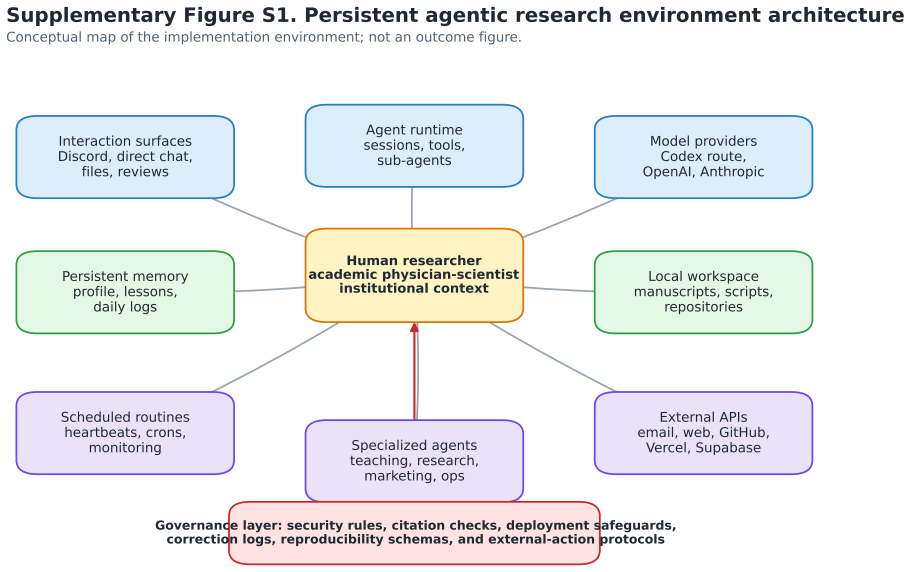
The PARE-M measurement framework applied to the persistent human-agent environment that includes researcher, runtime, memory layer, tools, repositories, scheduled jobs, specialized roles, and governance rules.
If this is right
- Artifact-level denominators become the appropriate unit for evaluating persistent agents.
- Reproducible parsing rules are required to count output events consistently.
- Correction taxonomies and protocol-proxy events must be tracked separately from raw token use.
- Independent coding of governance events is needed to assess safety and role delegation.
Where Pith is reading between the lines
- If cache dominance generalizes, benchmarks that still score agents on token throughput will systematically undervalue long-running deployments.
- The shift to artifact costing would reward agent designs that maximize reuse of prior context over designs that minimize per-turn tokens.
- Single-investigator case studies leave open whether multi-user environments preserve the same cache ratios or introduce new coordination overhead.
Load-bearing premise
Telemetry collected by the single investigator who designed and operated the agent supplies an unbiased record of persistent agent behavior.
What would settle it
An independent replication of the same persistent setup that records a cache-read rate materially below 82.9 percent or that shows token costs still dominate artifact costs.
Figures

read the original abstract
Background: Large language models are typically evaluated as models, benchmarks, or short conversational episodes. Less is known about what happens when an agent is embedded persistently in a real academic research environment with durable memory, local files, external tools, scheduled routines, delegated roles, and explicit safety protocols. Methods: A structured self-observed implementation case study was conducted from January 31 to May 25, 2026. The unit of analysis was the persistent human-agent environment: researcher, agent runtime, memory layer, tools, repositories, scheduled jobs, specialized agent roles, and governance rules. Outcomes were organized using PARE-M (Persistent Agentic Research Environment Measurement), a measurement framework covering architecture, utilization, artifact production, resource use, reproducibility, and governance. Results: Recoverable main-agent telemetry contained 75,671 de-duplicated records across 96 active days, with 8,059 user-role and 23,710 assistant-role messages. The workspace included 502 memory-related files, 17 configured agent directories, and 57 skill files. Active system time was 579.7 hours (30-minute capped-gap estimate). Memory-derived records identified 482 output-proxy events and 889 failure, verification, correction, or protocol-proxy events. A strict May 2026 trajectory subset captured 627 model-completed events and 73.95 million recorded tokens, of which 82.9% were cache reads. Conclusions: The workflow was cache-dominant, suggesting that persistent agentic environments may shift the economic unit from cost per token to cost per completed artifact. Future evaluations should use artifact-level denominators, reproducible parsing rules, correction taxonomies, and independent coding of governance events.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a single-investigator case study of a persistent AI agent embedded in academic research from January 31 to May 25, 2026. Using the PARE-M measurement framework, it analyzes architecture, utilization, artifact production, resource use, reproducibility, and governance via 75,671 de-duplicated telemetry records (including 8,059 user and 23,710 assistant messages), 502 memory files, 17 agent directories, 57 skill files, 482 output-proxy events, and 889 failure events. A May 2026 subset shows 627 model-completed events and 73.95M tokens with 82.9% cache reads. The central conclusion is that the workflow was cache-dominant, suggesting persistent agentic environments may shift the economic unit from cost per token to cost per completed artifact.
Significance. If the telemetry holds, the study supplies rare longitudinal, artifact-level data on persistent agents in a real research setting, including explicit counts of active system time (579.7 hours) and governance events. The PARE-M framework and correction taxonomies provide a reusable structure for future evaluations. The cache-dominance observation, if generalizable, supports shifting metrics toward completed artifacts rather than tokens.
major comments (2)
- [Results] Results (May 2026 trajectory subset): The 82.9% cache-read rate for 73.95M tokens is derived from 75,671 de-duplicated records and PARE-M parsing rules for output-proxy and failure events, all classified by the single investigator who designed the memory layer and governance protocols; this self-observation makes it unclear whether cache dominance is an inherent property of persistent agents or an artifact of the chosen state structure and de-duplication choices.
- [Methods] Methods (PARE-M framework): No independent audit, blinded re-coding, or inter-rater reliability is reported for the classification of the 482 output-proxy events and 889 failure/verification events, which is load-bearing for the claim that the observed cache dominance supports an economic shift to cost per completed artifact.
minor comments (1)
- [Abstract] The abstract introduces PARE-M without expanding the acronym on first use; a parenthetical definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our single-investigator case study. We address the major comments point by point below, with revisions where appropriate to clarify scope and limitations.
read point-by-point responses
-
Referee: [Results] Results (May 2026 trajectory subset): The 82.9% cache-read rate for 73.95M tokens is derived from 75,671 de-duplicated records and PARE-M parsing rules for output-proxy and failure events, all classified by the single investigator who designed the memory layer and governance protocols; this self-observation makes it unclear whether cache dominance is an inherent property of persistent agents or an artifact of the chosen state structure and de-duplication choices.
Authors: We agree that the single-investigator design and investigator-designed memory structure introduce the possibility that observed cache dominance reflects specific implementation choices rather than an inherent property of persistent agents. The manuscript already frames the work as a case study and presents the 82.9% figure as an observation from this trajectory. We will revise the results and conclusions sections to explicitly note that the finding is tied to the de-duplication rules and state architecture employed, and to recommend that future multi-configuration studies test robustness. The economic-unit hypothesis is offered as a direction for further inquiry rather than a general claim. revision: partial
-
Referee: [Methods] Methods (PARE-M framework): No independent audit, blinded re-coding, or inter-rater reliability is reported for the classification of the 482 output-proxy events and 889 failure/verification events, which is load-bearing for the claim that the observed cache dominance supports an economic shift to cost per completed artifact.
Authors: As a single-investigator study, independent audit or inter-rater reliability statistics cannot be generated. We will add explicit language in the methods and limitations sections stating that all event classifications were performed by the investigator responsible for system design, and that the PARE-M framework is intended as an initial structure for subsequent studies that may incorporate multiple coders. The suggestion of an economic shift is presented as a hypothesis derived from the observed data rather than a validated general result. revision: yes
- Independent inter-rater reliability assessment for event classifications, which is not feasible within a single-investigator case study design.
Circularity Check
Observational case study with no derivation chain or fitted predictions
full rationale
The paper is a descriptive self-observed case study reporting telemetry counts, file inventories, and percentages from a single-investigator implementation. It contains no equations, no parameter fitting, no predictions derived from models, and no claimed first-principles derivations. The conclusion that the workflow is cache-dominant is a direct summary of the observed 82.9% cache-read statistic in the May subset; it does not reduce to any input by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear. The analysis is therefore self-contained empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
Bommasani R, Hudson DA, Adeli E, et al. On the opportunities and risks of foundation models. arXiv:2108.07258. 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Holistic Evaluation of Language Models
Liang P, Bommasani R, Lee T, et al. Holistic evaluation of language models. arXiv:2211.09110. 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao S, Zhao J, Yu D, et al. ReAct: Synergizing reasoning and acting in language models. arXiv:2210.03629. 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
MemGPT: Towards LLMs as Operating Systems
Packer C, Fang V, Patil SG, Lin K, Wooders S, Gonzalez JE, Stoica I. MemGPT: Towards LLMs as operating systems. arXiv:2310.08560. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Jimenez CE, Yang J, Wettig A, et al. SWE-bench: Can language models resolve real-world GitHub issues? arXiv:2310.06770. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
AgentBench: Evaluating LLMs as Agents
Liu X, Yu H, Zhang H, et al. AgentBench: Evaluating LLMs as agents. arXiv:2308.03688. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
GAIA: a benchmark for General AI Assistants
Mialon G, Fourrier C, Swift C, Wolf T, LeCun Y, Scialom T. GAIA: A benchmark for general AI assistants. arXiv:2311.12983. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Lu C, Lu C, Lange RT, Foerster J, Clune J, Ha D. The AI Scientist: Towards fully automated open-ended scientific discovery. arXiv:2408.06292. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Damschroder LJ, Aron DC, Keith RE, Kirsh SR, Alexander JA, Lowery JC. Fostering im- plementation of health services research findings into practice: a consolidated framework for advancing implementation science. Implement Sci. 2009;4:50. doi:10.1186/1748-5908-4-50. 20
-
[10]
Evaluating the public health impact of health promo- tion interventions: the RE-AIM framework
Glasgow RE, Vogt TM, Boles SM. Evaluating the public health impact of health promo- tion interventions: the RE-AIM framework. Am J Public Health. 1999;89(9):1322-1327. doi:10.2105/AJPH.89.9.1322
-
[11]
Greenhalgh T, Wherton J, Papoutsi C, et al. Beyond adoption: a new framework for theorizing and evaluating nonadoption, abandonment, scale-up, spread, and sustainability of health and care technologies. J Med Internet Res. 2017;19(11):e367. doi:10.2196/jmir.8775
-
[12]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Chhikara P, Khant D, Aryan S, Singh T, Yadav D. Mem0: Building production-ready AI agents with scalable long-term memory. arXiv:2504.19413. 2025. doi:10.48550/arXiv.2504.19413
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19413 2025
-
[13]
Kang J, Ji M, Zhao Z, Bai T. Memory OS of AI Agent. arXiv:2506.06326. 2025. doi:10.48550/arXiv.2506.06326
-
[14]
MemBench : Towards more comprehensive evaluation on the memory of LLM -based agents
Tan H, Zhang Z, Ma C, Chen X, Dai Q, Dong Z. MemBench: Towards more com- prehensive evaluation on the memory of LLM-based agents. arXiv:2506.21605. 2025. doi:10.48550/arXiv.2506.21605
-
[15]
Deshpande D, Gangal V, Mehta H, Kannappan A, Qian R, Wang P. MEMTRACK: Evalu- ating long-term memory and state tracking in multi-platform dynamic agent environments. arXiv:2510.01353. 2025. 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.