FATE: Pillar Encoding and Frequency-Aware Training for Event-Based Object Detection
Pith reviewed 2026-06-27 03:13 UTC · model grok-4.3
The pith
Pillar Encoding projects event streams onto orthogonal polynomials to form dense pseudo-images that preserve temporal structure for object detection at up to 200 Hz.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
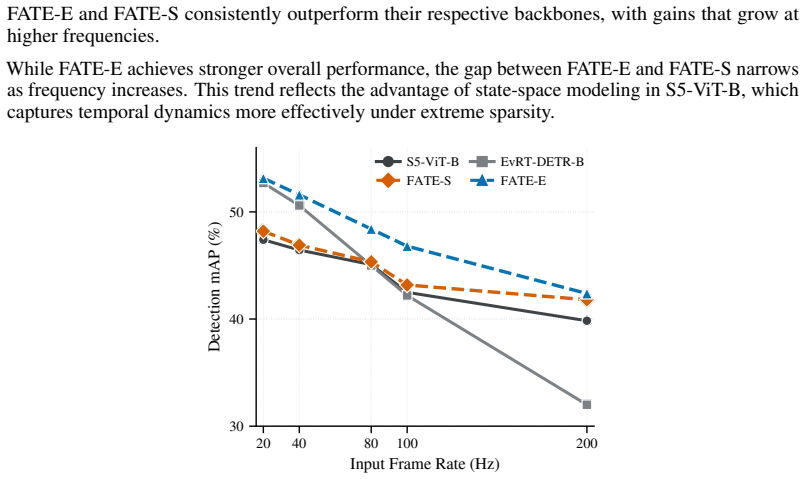
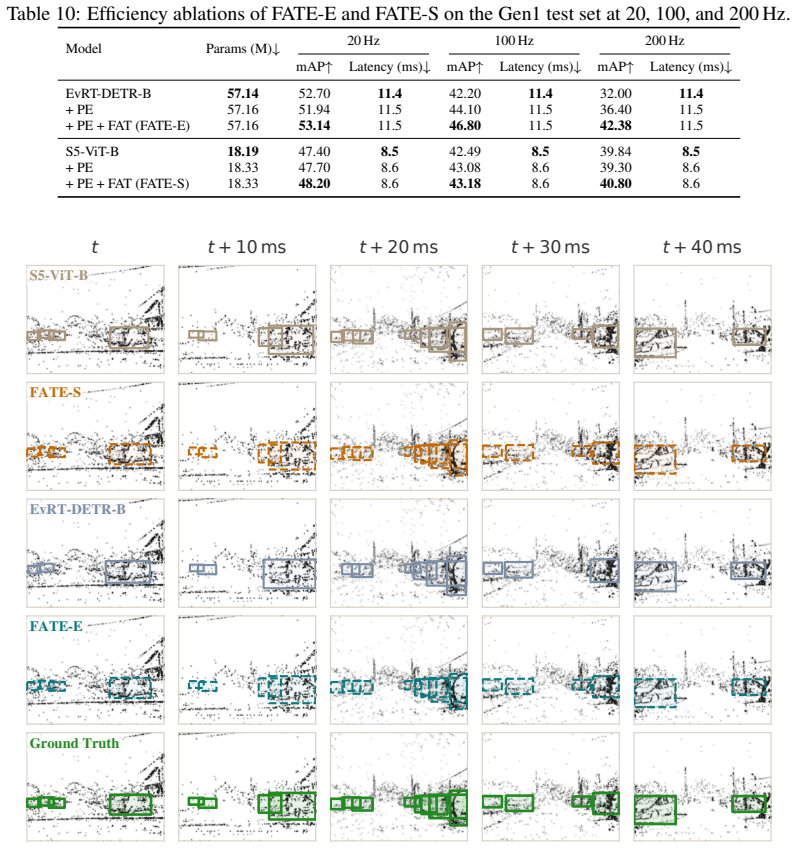
FATE enables robust object detection at high temporal resolutions up to 200 Hz by organizing events into spatial pillars whose intra-window evolution is approximated via projection onto a continuous-time orthogonal polynomial basis, yielding an L2-optimal dense pseudo-image, paired with Frequency-Aware Training that generates temporally dense pseudo-labels through a soft mean-teacher curriculum.
What carries the argument
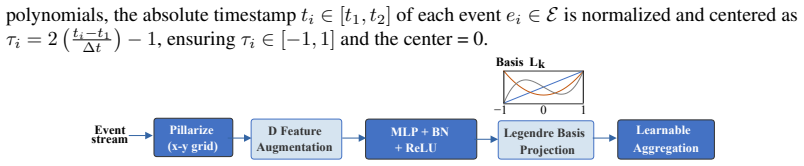
Pillar Encoding, which organizes events into spatial pillars and projects their intra-window time evolution onto a continuous-time orthogonal polynomial basis to produce dense pseudo-images without internal temporal sub-binning.
If this is right
- Standard convolutional detectors can be applied directly to event data at frequencies far above the rate of available ground-truth labels.
- The same encoding works across multiple detector architectures with only minor changes to input channels.
- Parameter count and inference latency remain close to those of the underlying detector.
- Performance gains hold across different event-camera datasets and scene types.
Where Pith is reading between the lines
- The same pillar-plus-polynomial representation could be tested on event-based tasks such as optical flow or semantic segmentation without retraining the encoder.
- Because the basis is continuous, the method might allow variable accumulation windows chosen on the fly rather than fixed at training time.
- If the polynomial order can be chosen per pillar according to local event density, the representation could adapt automatically to regions with very different motion speeds.
Load-bearing premise
Projecting events onto a continuous-time orthogonal polynomial basis inside each accumulation window produces an L2-optimal dense pseudo-image that keeps rich temporal dynamics even when events are sparse.
What would settle it
A controlled test at 200 Hz on a dataset with known sparse regions where the polynomial projection is replaced by uniform binning and accuracy falls below the FATE baseline by more than the reported margin.
Figures
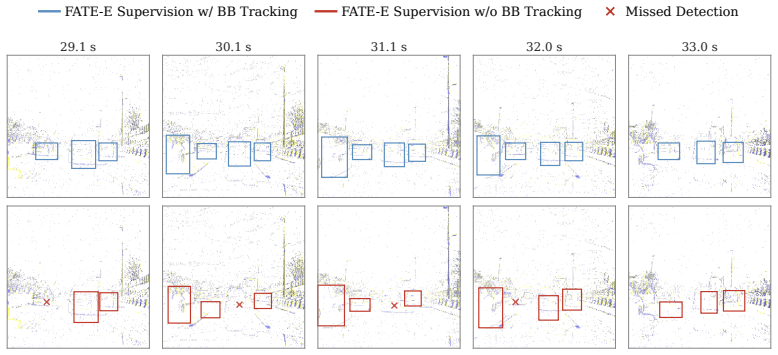
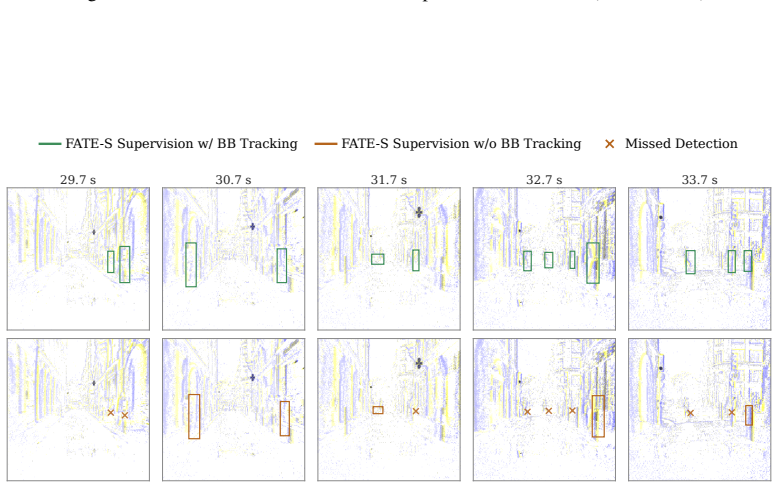
read the original abstract
Event cameras are bio-inspired sensors that asynchronously capture logarithmic intensity changes, offering inherent advantages in high-speed and high-dynamic-range scenarios. However, the sparse and asynchronous nature of event streams poses a fundamental challenge for modern deep learning architectures. To enable compatibility with standard models, most existing approaches partition the accumulation window into fixed temporal sub-bins. While effective for spatial processing, this internal discretization discards fine-grained temporal structure and constrains inference to the low temporal frequencies imposed by training supervision. To address this limitation, we propose FATE, a unified framework built upon a novel Pillar Encoding (PE). While operating over discrete macro-accumulation windows dictated by the target frequency, PE avoids internal temporal sub-binning. It organizes events into spatial pillars and approximates their intra-window evolution via projection onto a continuous-time orthogonal polynomial basis. This formulation yields an L2-optimal representation that retains rich temporal dynamics in a dense pseudo-image, mitigating information loss under sparse event conditions. To fully leverage this representation, we introduce Frequency-Aware Training (FAT), a soft mean-teacher curriculum that generates temporally dense pseudo-labels, effectively bridging the mismatch between low-frequency supervision and high-frequency inference. Extensive experiments demonstrate that FATE generalizes across architectural paradigms and consistently outperforms strong baselines. It enables robust object detection at high temporal resolutions up to 200 Hz, while incurring minimal overhead in parameter count and inference latency
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FATE, a framework for event-based object detection consisting of Pillar Encoding (PE) that organizes events into spatial pillars and projects their intra-window temporal evolution onto a continuous-time orthogonal polynomial basis to produce an L2-optimal dense pseudo-image, together with Frequency-Aware Training (FAT) that uses a soft mean-teacher curriculum to generate dense pseudo-labels and bridge low-frequency supervision with high-frequency (up to 200 Hz) inference. The method is claimed to generalize across architectures while adding negligible parameter and latency overhead.
Significance. If the central claims hold, the work would enable practical high-temporal-resolution object detection from event cameras without the information loss of fixed sub-binning, addressing a key limitation in current event-vision pipelines.
major comments (1)
- [§3.2] §3.2 (Pillar Encoding): the assertion that the orthogonal-polynomial projection yields an L2-optimal representation that retains rich temporal dynamics under sparse event conditions is not supported when the number of events per pillar falls below the basis dimension (degree + 1); at 200 Hz the shortened accumulation windows make this regime likely, yet no per-pillar event-count statistics, condition-number analysis, or basis-order ablation is reported to demonstrate that the coefficients remain informative rather than degenerate or noise-dominated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment on Pillar Encoding below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Pillar Encoding): the assertion that the orthogonal-polynomial projection yields an L2-optimal representation that retains rich temporal dynamics under sparse event conditions is not supported when the number of events per pillar falls below the basis dimension (degree + 1); at 200 Hz the shortened accumulation windows make this regime likely, yet no per-pillar event-count statistics, condition-number analysis, or basis-order ablation is reported to demonstrate that the coefficients remain informative rather than degenerate or noise-dominated.
Authors: We thank the referee for this observation. The L2-optimality claim refers strictly to the fact that the coefficients minimize the squared residual of the polynomial fit to the observed event times within each pillar (i.e., the normal equations solution). We acknowledge, however, that when the number of events falls below the basis dimension the system is underdetermined and the solution via pseudoinverse may become sensitive to noise or fail to capture meaningful dynamics. Because the manuscript currently provides no supporting statistics or ablations for the 200 Hz regime, we will revise §3.2 and the experimental section to include (i) per-pillar event-count histograms at 50 Hz, 100 Hz and 200 Hz, (ii) condition-number statistics of the design matrix across pillars, and (iii) a basis-order ablation measuring both detection mAP and coefficient stability. These additions will directly address the concern. revision: yes
Circularity Check
No circularity; derivation is self-contained
full rationale
The abstract and method description define Pillar Encoding explicitly as projection onto an orthogonal polynomial basis (a standard least-squares operation whose L2-optimality follows directly from the definition of the basis and does not presuppose the downstream detection performance or the FAT curriculum). Frequency-Aware Training is introduced as an independent soft mean-teacher procedure without any equations or claims that reduce the claimed high-frequency detection gains to a fitted parameter or self-citation. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided text; the central claims rest on the architectural choices and external experimental validation rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Projection onto continuous-time orthogonal polynomial basis yields L2-optimal representation retaining rich temporal dynamics
invented entities (2)
-
Pillar Encoding (PE)
no independent evidence
-
Frequency-Aware Training (FAT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
US Department of Commerce, National Bureau of Standards, Washington, D.C., 1964
Milton Abramowitz and Irene A Stegun.Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, volume 55. US Department of Commerce, National Bureau of Standards, Washington, D.C., 1964
1964
-
[2]
A hybrid ANN-SNN architecture for low-power and low-latency visual perception
Asude Aydin, Mathias Gehrig, Daniel Gehrig, and Davide Scaramuzza. A hybrid ANN-SNN architecture for low-power and low-latency visual perception. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024
2024
-
[3]
R. Wes Baldwin, Ruixu Liu, Mohammed Almatrafi, Vijayan Asari, and Keigo Hirakawa. Time-Ordered Recent Event (TORE) V olumes for Event Cameras.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2519–2532, 2023. ISSN 1939-3539. doi: 10.1109/TPAMI.2022.3172212
-
[4]
Ryad Benosman, Charles Clercq, Xavier Lagorce, Sio-Hoi Ieng, and Chiara Bartolozzi. Event- based visual flow.IEEE Transactions on Neural Networks and Learning Systems, 25(2): 407–417, 2013. doi: 10.1109/TNNLS.2013.2273537
-
[5]
Simple online and realtime tracking
Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468, Phoenix, AZ, USA, September 2016. IEEE. doi: 10.1109/ICIP.2016.7533003
-
[6]
Yin Bi, Aaron Chadha, Alhabib Abbas, Eirina Bourtsoulatze, and Yiannis Andreopoulos. Graph- Based Spatio-Temporal Feature Learning for Neuromorphic Vision Sensing.IEEE Transactions on Image Processing, 29:9084–9098, 2020. ISSN 1941-0042. doi: 10.1109/TIP.2020.3023597
-
[7]
A differentiable recurrent surface for asynchronous event-based data
Marco Cannici, Marco Ciccone, Andrea Romanoni, and Matteo Matteucci. A differentiable recurrent surface for asynchronous event-based data. InThe European Conference on Computer Vision (ECCV), August 2020
2020
-
[8]
End -to-End Object Detection with Transformers[J]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-End Object Detection with Transformers. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision – ECCV 2020, volume 12346, pages 213–229. Springer International Publishing. doi: 10.1007/978-3-030-58452-8_13
-
[9]
Courier Corporation, 2007
Philip J Davis and Philip Rabinowitz.Methods of Numerical Integration. Courier Corporation, 2007
2007
-
[10]
A Large Scale Event-based Detection Dataset for Automotive, 2020
Pierre de Tournemire, Davide Nitti, Etienne Perot, Davide Migliore, and Amos Sironi. A Large Scale Event-based Detection Dataset for Automotive, 2020
2020
-
[11]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yongjian Deng, Hao Chen, Hai Liu, and Youfu Li. A V oxel Graph CNN for Object Classifi- cation with Event Cameras. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1162–1171, 2022. doi: 10.1109/CVPR52688.2022.00124
-
[12]
Rui Fan, Weidong Hao, Juntao Guan, Lai Rui, Lin Gu, Tong Wu, Fanhong Zeng, and Zhangming Zhu. Eventpillars: Pillar-based efficient representations for event data.Proceedings of the AAAI Conference on Artificial Intelligence, 39(3):2861–2869, 2025. doi: 10.1609/aaai.v39i3.32292
-
[13]
Davison, Jörg Conradt, Kostas Daniilidis, et al
Guillermo Gallego, Tobi Delbrück, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew J. Davison, Jörg Conradt, Kostas Daniilidis, et al. Event- based vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 (1):154–180, 2020
2020
-
[14]
Yolox: Exceeding yolo series in 2021.arXiv preprint arXiv:2107.08430, 2021
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021.arXiv preprint arXiv:2107.08430, 2021
Pith/arXiv arXiv 2021
-
[15]
Daniel Gehrig and Davide Scaramuzza. Low-latency automotive vision with event cameras.Na- ture, 629(8014):1034–1040. ISSN 0028-0836, 1476-4687. doi: 10.1038/s41586-024-07409-w
-
[16]
Derpanis, and Davide Scaramuzza
Daniel Gehrig, Antonio Loquercio, Konstantinos G. Derpanis, and Davide Scaramuzza. End- to-end learning of representations for asynchronous event-based data. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5633–5643, 2019. 10
2019
-
[17]
Mathias Gehrig and Davide Scaramuzza. Recurrent Vision Transformers for Object Detec- tion with Event Cameras. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13884–13893, 2023. doi: 10.1109/CVPR52729.2023.01334
-
[18]
Haiqing Hao, Zhipeng Sui, Rong Zou, Zijia Dai, Nikola Zubi´c, Davide Scaramuzza, and Wenhui Wang. Low-latency event-based object detection with spatially-sparse linear attention.arXiv preprint arXiv:2603.06228, 2026
arXiv 2026
-
[19]
Maximizing asynchronicity in event-based neural networks
Haiqing Hao, Nikola Zubic, Weihua He, Zhipeng Sui, Davide Scaramuzza, and Wenhui Wang. Maximizing asynchronicity in event-based neural networks. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Zhuangyi Jiang, Pengfei Xia, Kai Huang, Walter Stechele, Guang Chen, Zhenshan Bing, and Alois Knoll. Mixed Frame-/Event-Driven Fast Pedestrian Detection. In2019 International Conference on Robotics and Automation (ICRA), pages 8332–8338, 2019. doi: 10.1109/ICRA. 2019.8793924
-
[21]
Associative Memory Augmented Asyn- chronous Spatiotemporal Representation Learning for Event-based Perception
Uday Kamal, Saurabh Dash, and Saibal Mukhopadhyay. Associative Memory Augmented Asyn- chronous Spatiotemporal Representation Learning for Event-based Perception. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[22]
Muhammad Ahmed Ullah Khan, Abdul Hannan Khan, and Andreas Dengel. Emf: Event meta formers for event-based real-time traffic object detection.arXiv preprint arXiv:2504.04124, 2025
arXiv 2025
-
[23]
John Wiley & Sons, New York, 1978
Erwin Kreyszig.Introductory Functional Analysis with Applications, volume 1. John Wiley & Sons, New York, 1978
1978
-
[24]
Shi, and Ryad B
Xavier Lagorce, Garrick Orchard, Francesco Galluppi, Bertram E. Shi, and Ryad B. Benosman. HOTS: A Hierarchy of Event-Based Time-Surfaces for Pattern Recognition. 39(7):1346–1359,
-
[25]
doi: 10.1109/TPAMI.2016.2574707
ISSN 1939-3539. doi: 10.1109/TPAMI.2016.2574707
-
[26]
Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom
Alex H. Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. PointPillars: Fast Encoders for Object Detection From Point Clouds. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12689–12697, Long Beach, CA, USA, June 2019. IEEE. doi: 10.1109/CVPR.2019.01298
-
[27]
Dianze Li, Jianing Li, and Yonghong Tian. SODFormer: Streaming object detection with transformer using events and frames.arXiv preprint arXiv:2308.04047, 2023
arXiv 2023
-
[28]
Dianze Li, Jianing Li, Xu Liu, Zhaokun Zhou, Xiaopeng Fan, and Yonghong Tian. HDI-Former: Hybrid dynamic interaction ANN-SNN transformer for object detection using frames and events. arXiv preprint arXiv:2411.18658, 2024
arXiv 2024
-
[29]
Jianing Li, Jia Li, Lin Zhu, Xijie Xiang, Tiejun Huang, and Yonghong Tian. Asynchronous spatio-temporal memory network for continuous event-based object detection.IEEE Transac- tions on Image Processing, 31:2975–2987, 2022. doi: 10.1109/TIP.2022.3162962
-
[30]
Yishi Li, Yuhao Zhang, and Rui Lai. Tinypillarnet: Tiny pillar-based network for 3d point cloud object detection at edge.IEEE Transactions on Circuits and Systems for Video Technology, 34 (3):1772–1785, 2024. doi: 10.1109/TCSVT.2023.3297620
-
[31]
Flexevent: Towards flexible event-frame object detection at varying operational frequencies
Dongyue Lu, Lingdong Kong, Gim Hee Lee, Camille Simon Chane, and Wei Tsang Ooi. Flexevent: Towards flexible event-frame object detection at varying operational frequencies. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[32]
John Wiley & Sons, New York, 1997
David G Luenberger.Optimization by Vector Space Methods. John Wiley & Sons, New York, 1997
1997
-
[33]
PLEIADES: Building temporal kernels with orthogonal polynomials
Yan Ru Pei and Olivier JMD Coenen. PLEIADES: Building temporal kernels with orthogonal polynomials. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. 11
2026
-
[34]
In: IEEE/CVF International Conference on Computer Vision
Yansong Peng, Yueyi Zhang, Zhiwei Xiong, Xiaoyan Sun, and Feng Wu. GET: Group Event Transformer for Event-Based Vision. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6015–6025, 2023. doi: 10.1109/ICCV51070.2023.00555
-
[35]
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Yansong Peng, Hebei Li, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. Scene Adaptive Sparse Transformer for Event-based Object Detection. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16794–16804, 2024. doi: 10.1109/CVPR52733. 2024.01589
-
[36]
Learning to detect objects with a 1 megapixel event camera
Etienne Perot, Pierre de Tournemire, Davide Nitti, Jonathan Masci, and Amos Sironi. Learning to detect objects with a 1 megapixel event camera. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 16639–16652. Curran Associates, Inc., 2020
2020
-
[37]
Cambridge University Press, Cambridge, UK, 2007
William H Press, Saul A Teukolsky, William T Vetterling, and Brian P Flannery.Numerical Recipes 3rd Edition: The Art of Scientific Computing. Cambridge University Press, Cambridge, UK, 2007
2007
-
[38]
Events-to-video: Bringing modern computer vision to event cameras
Henri Rebecq, René Ranftl, Vladlen Koltun, and Davide Scaramuzza. Events-to-video: Bringing modern computer vision to event cameras. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3857–3866, 2019
2019
-
[39]
McGraw-Hill, New York, 3rd edition, 1976
Walter Rudin.Principles of Mathematical Analysis. McGraw-Hill, New York, 3rd edition, 1976
1976
-
[40]
EventNet: Asynchronous Recursive Event Processing
Yusuke Sekikawa, Kosuke Hara, and Hideo Saito. EventNet: Asynchronous Recursive Event Processing. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3882–3891. IEEE. doi: 10.1109/CVPR.2019.00401
-
[41]
HATS: Histograms of Averaged Time Surfaces for Robust Event-Based Object Classification
Amos Sironi, Manuele Brambilla, Nicolas Bourdis, Xavier Lagorce, and Ryad Benosman. HATS: Histograms of Averaged Time Surfaces for Robust Event-Based Object Classification. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1731–1740,
-
[42]
doi: 10.1109/CVPR.2018.00186
-
[43]
Smith, Andrew Warrington, and Scott Linderman
Jimmy T.H. Smith, Andrew Warrington, and Scott Linderman. Simplified state space layers for sequence modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[44]
Super-convergence: very fast training of neural networks using large learning rates
Leslie N Smith and Nicholay Topin. Super-convergence: very fast training of neural networks using large learning rates. InArtificial Intelligence and Machine Learning for Multi-Domain Operations Applications, volume 11006, page 1100612. SPIE, 2019
2019
-
[45]
Deep directly-trained spiking neural networks for object detection
Qiaoyi Su, Yuhong Chou, Yifan Hu, Jianing Li, Shijie Mei, Ziyang Zhang, and Guoqi Li. Deep directly-trained spiking neural networks for object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6532–6542, 2023
2023
-
[46]
Mean teachers are better role models: Weight-averaged con- sistency targets improve semi-supervised deep learning results.Neural Information Processing Systems, 2017
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged con- sistency targets improve semi-supervised deep learning results.Neural Information Processing Systems, 2017
2017
-
[47]
EvRT-DETR: La- tent Space Adaptation of Image Detectors for Event-based Vision
Dmitrii Torbunov, Yihui Ren, Animesh Ghose, Odera Dim, and Yonggang Cui. EvRT-DETR: La- tent Space Adaptation of Image Detectors for Event-based Vision. InInternational Conference on Computer Vision (ICCV), 2025
2025
-
[48]
ALERT-transformer: Bridging asynchronous and synchronous machine learning for real-time event-based spatio-temporal data
Carmen Martin Turrero, Maxence Bouvier, Manuel Breitenstein, Pietro Zanuttigh, and Vincent Parret. ALERT-transformer: Bridging asynchronous and synchronous machine learning for real-time event-based spatio-temporal data. InForty-first International Conference on Machine Learning, 2024
2024
-
[49]
Shenqi Wang, Yingfu Xu, Amirreza Yousefzadeh, Sherif Eissa, Henk Corporaal, Federico Corradi, and Guangzhi Tang. Sparse convolutional recurrent learning for efficient event-based neuromorphic object detection.arXiv preprint arXiv:2506.13440, 2025. 12
arXiv 2025
-
[50]
Object de- tection using event camera: A moe heat conduction based detector and a new benchmark dataset
Xiao Wang, Yu Jin, Wentao Wu, Wei Zhang, Lin Zhu, Bo Jiang, and Yonghong Tian. Object de- tection using event camera: A moe heat conduction based detector and a new benchmark dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[51]
LEOD: Label- Efficient Object Detection for Event Cameras
Ziyi Wu, Mathias Gehrig, Qing Lyu, Xudong Liu, and Igor Gilitschenski. LEOD: Label- Efficient Object Detection for Event Cameras. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. doi: 10.48550/arXiv.2311.17286
-
[52]
End-to-end semi-supervised object detection with soft teacher.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
Mengde Xu, Zheng Zhang, Han Hu, Jianfeng Wang, Lijuan Wang, Fangyun Wei, Xiang Bai, and Zicheng Liu. End-to-end semi-supervised object detection with soft teacher.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[53]
Nan Yang, Yang Wang, Zhanwen Liu, Meng Li, Yisheng An, and Xiangmo Zhao. Smamba: Sparse mamba for event-based object detection.Proceedings of the AAAI Conference on Artificial Intelligence, 39(9):9229–9237, 2025. doi: 10.1609/aaai.v39i9.32999
-
[54]
Deep Residual Learning for Image Recognition
Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, and Kostas Daniilidis. Unsupervised Event- Based Learning of Optical Flow, Depth, and Egomotion. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 989–997, 2019. doi: 10.1109/CVPR. 2019.00108
-
[55]
Nikola Zubi´c, Mathias Gehrig, and Davide Scaramuzza. State Space Models for Event Cameras. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5819–5828, 2024. doi: 10.1109/CVPR52733.2024.00556. 13 A Theoretical Justifications for Pillar Encoding In this section, we provide the theoretical foundation for our Pillar Encodin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.