MemSlides: A Hierarchical Memory Driven Agent Framework for Personalized Slide Generation with Multi-turn Local Revision
Pith reviewed 2026-06-27 03:39 UTC · model grok-4.3
The pith
Separating persistent user profiles, session working memory, and reusable tool experience enables stable personalization and reliable local edits in slide generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
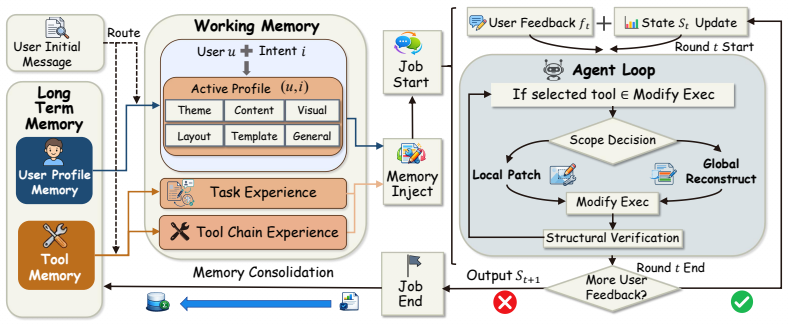
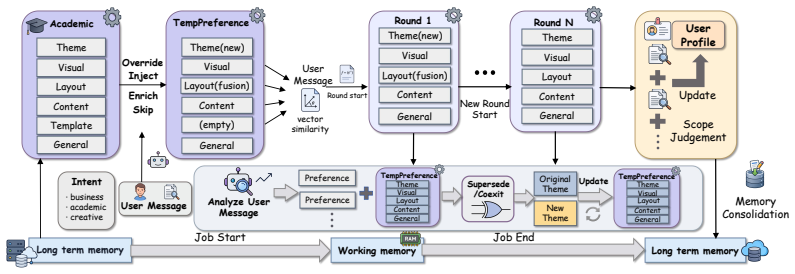
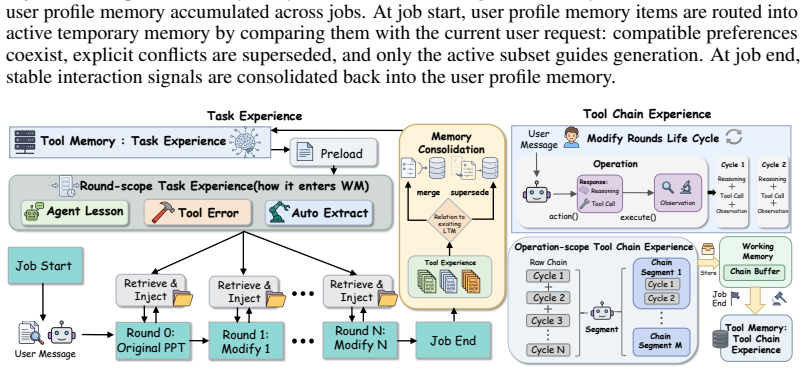
MemSlides separates long-term memory into user profile memory for round-0 personalization and tool memory for execution experience, keeps these distinct from session working memory, and pairs the hierarchy with scoped slide-local revision so that updates affect only the smallest changed region; experiments indicate this yields better persona alignment on multi-persona banks, improved closed-loop modify reliability, and preference carryover across rounds.
What carries the argument
Hierarchical memory framework that divides long-term memory into intent-conditioned user profile memory and reusable tool memory while isolating session working memory, used together with scoped local revision.
If this is right
- User profile memory produces higher persona-alignment judgments across multi-persona, multi-intent profile banks.
- Tool-memory injection raises closed-loop modify success rates in matched-pair diagnostic settings.
- Working memory preserves newly introduced preferences and constraints from one revision round to the next.
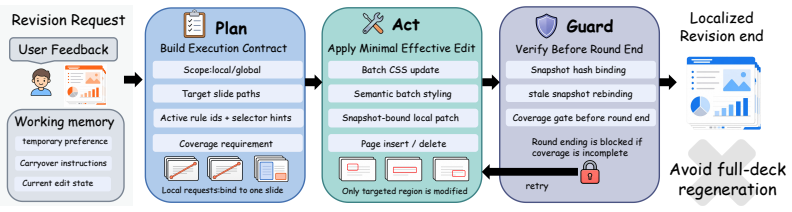
- Scoped slide-local revision confines changes to the smallest affected region rather than requiring full-deck regeneration.
Where Pith is reading between the lines
- The same three-way memory split may reduce error accumulation in other multi-turn agent tasks that require both stable user intent and precise iterative edits.
- Without explicit separation, session constraints could overwrite or dilute long-term profile information in extended interactions.
- Real-user longitudinal tests over dozens of turns would reveal whether independence between the memory stores holds under natural preference drift.
Load-bearing premise
The three memory components can be maintained and accessed independently without interference or information loss across multiple revision turns.
What would settle it
A matched experiment in which a single unified memory baseline produces equivalent or better persona-alignment scores and closed-loop modification success rates than the separated-memory version on the same profile bank and diagnostic edit pairs.
Figures

read the original abstract
Personalized presentation generation requires more than conditioning on a current prompt or template: agents must preserve stable user preferences across tasks, retain newly introduced preferences and constraints during multi-turn revision, and carry out local edits reliably. We propose MemSlides, a hierarchical memory framework for personalized presentation agents that separates long-term memory from working memory and further divides long-term memory into user profile memory and tool memory. User profile memory stores intent-conditioned profiles for round-0 personalization, working memory carries active preferences and session constraints across revision rounds, and tool memory stores reusable execution experience for reliable localized editing. MemSlides pairs this memory design with scoped slide-local revision, so targeted updates act on the smallest affected region instead of repeatedly regenerating the full deck. In controlled experiments, user profile memory improves persona-alignment judgments on a multi-persona, multi-intent profile bank, tool-memory injection improves closed-loop modify behavior in diagnostic matched-pair settings, and qualitative cases illustrate working memory's ability to carryover preferences. Taken together, these results suggest that effective personalization in presentation authoring depends on separating persistent user profiles, session-level working memory, and reusable execution experience across generation and localized revision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MemSlides, a hierarchical memory framework for personalized presentation generation agents. It separates long-term memory into user profile memory (for intent-conditioned profiles) and tool memory (for reusable execution experience), with an additional working memory component for active preferences and session constraints across multi-turn revisions. The framework is paired with scoped slide-local revision to enable targeted edits rather than full regeneration. Controlled experiments are described on a multi-persona, multi-intent profile bank and matched-pair settings, with claims that user profile memory improves persona-alignment judgments, tool memory improves closed-loop modify behavior, and working memory supports preference carryover; the results are taken to indicate that separating these memory types is key to effective personalization.
Significance. If the empirical results hold and the claimed independence of the three memory stores can be verified, the work would provide a concrete architectural pattern for maintaining stable user preferences alongside session-specific and tool-based information in agentic creative tasks. This could inform designs for multi-turn personalization beyond slide generation, particularly where persistent profiles must coexist with dynamic constraints without interference.
major comments (2)
- [Abstract] Abstract: the abstract asserts that 'user profile memory improves persona-alignment judgments on a multi-persona, multi-intent profile bank' and 'tool-memory injection improves closed-loop modify behavior in diagnostic matched-pair settings' yet supplies no methods, baselines, quantitative results, or statistical details. Without these, it is impossible to evaluate whether the data support the central claim that separating the three memory components produces the reported gains.
- [Framework description (no section or equation cited)] The manuscript provides no mechanism, pseudocode, update rules, or diagnostic test to ensure that user profile memory, working memory, and tool memory can be maintained and retrieved independently without interference or leakage across revision turns (e.g., a session constraint overwriting a persistent profile or tool experience altering active constraints). This independence is load-bearing for the claim that the hierarchical design outperforms a single shared memory; if interference occurs, the reported improvements in the multi-persona bank and matched-pair settings cannot be attributed to the separation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify opportunities to strengthen the presentation of experimental details and the explicitness of the memory separation mechanisms. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts that 'user profile memory improves persona-alignment judgments on a multi-persona, multi-intent profile bank' and 'tool-memory injection improves closed-loop modify behavior in diagnostic matched-pair settings' yet supplies no methods, baselines, quantitative results, or statistical details. Without these, it is impossible to evaluate whether the data support the central claim that separating the three memory components produces the reported gains.
Authors: Abstracts are concise summaries; the full methods (profile bank construction, matched-pair diagnostics), baselines (flat-memory ablations), quantitative results (alignment scores, modify success rates), and statistical details appear in the Experiments section. To improve standalone readability we will add one sentence to the abstract noting the controlled multi-persona setting and the primary metrics used to support the separation claim. revision: yes
-
Referee: [Framework description (no section or equation cited)] The manuscript provides no mechanism, pseudocode, update rules, or diagnostic test to ensure that user profile memory, working memory, and tool memory can be maintained and retrieved independently without interference or leakage across revision turns (e.g., a session constraint overwriting a persistent profile or tool experience altering active constraints). This independence is load-bearing for the claim that the hierarchical design outperforms a single shared memory; if interference occurs, the reported improvements in the multi-persona bank and matched-pair settings cannot be attributed to the separation.
Authors: Independence is maintained by construction: user-profile memory is written once from initial intent and remains read-only thereafter; working memory is scoped to the current session and explicitly cleared or overwritten at turn boundaries; tool memory is accessed solely via execution traces and never writes back to the other stores. Retrieval is type-scoped inside the agent prompt templates. We nevertheless agree that explicit documentation is needed and will insert pseudocode for the three update/retrieval rules plus a short diagnostic experiment measuring cross-store leakage in the revised Framework section. revision: yes
Circularity Check
No significant circularity; framework proposal evaluated via experiments without mathematical derivations
full rationale
The manuscript describes a hierarchical memory architecture (user profile memory, working memory, tool memory) paired with scoped local revision and reports empirical gains from each component in controlled experiments. No equations, first-principles derivations, or parameter-fitting steps appear in the provided text. Claims rest on experimental outcomes rather than any reduction of a 'prediction' to its own inputs by construction, self-citation chains, or renamed ansatzes. The independence assumption is an unverified design premise but is not presented as a derived result, so the circularity patterns do not apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Separating long-term memory into user profile memory and tool memory plus working memory enables stable personalization and reliable local edits across turns.
invented entities (3)
-
user profile memory
no independent evidence
-
working memory
no independent evidence
-
tool memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022. URL https://arxiv.org/ abs/2204.01691
Pith/arXiv arXiv 2022
-
[2]
En- hancing presentation slide generation by LLMs with a multi-staged end-to-end approach
Sambaran Bandyopadhyay, Himanshu Maheshwari, Anandhavelu Natarajan, and Apoorv Saxena. En- hancing presentation slide generation by LLMs with a multi-staged end-to-end approach. InProceed- ings of the 17th International Natural Language Generation Conference, pages 222–229, Tokyo, Japan, September 2024. Association for Computational Linguistics. doi: 10.1...
-
[3]
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens.arXiv preprint arXiv:2112.04426, 2021. URL https://arxiv.org/abs/2112.04426
Pith/arXiv arXiv 2021
-
[4]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. doi: 10.48550/arXiv.2504.19413. URLhttps://arxiv.org/abs/2504.19413
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19413 2025
-
[5]
The vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023. URL https://openreview.net/forum? id=g97OHbQyk1
2023
-
[6]
CoT-VLA: Visual chain-of-thought reasoning for vision- language-action models,
Jiaxin Ge, Zora Zhiruo Wang, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, and Trevor Darrell. AutoPresent: Designing structured visuals from scratch. InProceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2902–2911, June 2025. doi: 10.1109/CVPR52734.202...
-
[7]
REALM: Retrieval- augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval- augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning, 2020. URLhttps://arxiv.org/abs/2002.08909
Pith/arXiv arXiv 2020
-
[8]
Agentic tool use in large language models.arXiv preprint arXiv:2604.00835, 2026
Jinchao Hu, Meizhi Zhong, Kehai Chen, Xuefeng Bai, and Min Zhang. Agentic tool use in large language models.arXiv preprint arXiv:2604.00835, 2026. URLhttps://arxiv.org/abs/2604.00835
arXiv 2026
-
[9]
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, and Kota Yamaguchi. LayoutDM: Discrete diffusion model for controllable layout generation.arXiv preprint arXiv:2303.08137, 2023. URL https: //arxiv.org/abs/2303.08137
arXiv 2023
-
[10]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi- Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language models.arXiv preprint arXiv:2208.03299, 2022. URL https://arxiv.org/abs/ 2208.03299
Pith/arXiv arXiv 2022
-
[11]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J. Taylor, and Dan Roth. Know me, respond to me: Benchmarking LLMs for dynamic user profiling and personalized responses at scale.arXiv preprint arXiv:2504.14225, 2025. doi: 10.48550/arXiv.2504.14225. URLhttps://arxiv.org/abs/2504.14225
-
[12]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961–25970, Suzhou, China, November 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.emnlp-main.1318. URLhttps://aclanthology.org/2025.emnlp-main.1318/. 10
-
[13]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. MRKL systems: A modular, neuro-symbolic architecture that combines large language models, external knowledg...
Pith/arXiv arXiv 2022
-
[14]
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172, 2019. URL https://arxiv.org/abs/1911.00172
arXiv 1911
-
[15]
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models.arXiv preprint arXiv:2310.08491, 2023. URL https://arxiv.org/abs/ 2310.08491
arXiv 2023
-
[16]
Retrieval- augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval- augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020. URLhttps://pr...
2020
-
[17]
A persona- based neural conversation model
Jiwei Li, Michel Galley, Chris Brockett, Georgios Spithourakis, Jianfeng Gao, and Bill Dolan. A persona- based neural conversation model. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 994–1003, Berlin, Germany, August 2016. Association for Computational Linguistics. doi: 10.18653/v...
-
[18]
API-bank: A comprehensive benchmark for tool-augmented LLMs.arXiv preprint arXiv:2304.08244, 2023
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-bank: A comprehensive benchmark for tool-augmented LLMs.arXiv preprint arXiv:2304.08244, 2023. URLhttps://arxiv.org/abs/2304.08244
Pith/arXiv arXiv 2023
-
[19]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939, 2024. URLhttps://arxiv.org/abs/2406.11939
Pith/arXiv arXiv 2024
-
[20]
A survey of personalization: From RAG to agent.arXiv preprint arXiv:2504.10147, 2025
Xiaopeng Li, Pengyue Jia, Derong Xu, Yi Wen, Yingyi Zhang, Wenlin Zhang, Wanyu Wang, Yichao Wang, Zhaocheng Du, Xiangyang Li, Yong Liu, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. A survey of personalization: From RAG to agent.arXiv preprint arXiv:2504.10147, 2025. URL https: //arxiv.org/abs/2504.10147
arXiv 2025
-
[21]
Xin Liang, Xiang Zhang, Yiwei Xu, Siqi Sun, and Chenyu You. SlideGen: Collaborative multimodal agents for scientific slide generation.arXiv preprint arXiv:2512.04529, 2025. doi: 10.48550/arXiv.2512.04529. URLhttps://arxiv.org/abs/2512.04529
-
[22]
Jiawei Lin, Jiaqi Guo, Shizhao Sun, Zijiang James Yang, Jian-Guang Lou, and Dongmei Zhang. Layout- Prompter: Awaken the design ability of large language models.arXiv preprint arXiv:2311.06495, 2023. URLhttps://arxiv.org/abs/2311.06495
arXiv 2023
-
[23]
G-Eval: NLG evaluation using GPT-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023. URL https://arxiv.org/abs/2303.16634
Pith/arXiv arXiv 2023
-
[24]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, volume 36, pages 46534–46594, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 9...
2023
-
[25]
Himanshu Maheshwari, Sambaran Bandyopadhyay, Aparna Garimella, and Anandhavelu Natarajan. Presentations are not always linear! GNN meets LLM for text document-to-presentation transformation with attribution. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15948–15962, Miami, Florida, USA, November 2024. Association for Compu...
-
[26]
Ishani Mondal, Shwetha S, Anandhavelu Natarajan, Aparna Garimella, Sambaran Bandyopadhyay, and Jordan Boyd-Graber. Presentations by the humans and for the humans: Harnessing LLMs for generating persona-aware slides from documents. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long ...
-
[28]
URLhttps://arxiv.org/abs/2311.09180
-
[29]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021. URL https://arxiv.org/abs/2112. 09332
Pith/arXiv arXiv 2021
-
[30]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patric...
2024
-
[31]
Tarik Can Ozden, Sachidanand VS, Furkan Horoz, Ozgur Kara, Junho Kim, and James M. Rehg. Narrative- driven paper-to-slide generation via ArcDeck.arXiv preprint arXiv:2604.11969, 2026. doi: 10.48550/ arXiv.2604.11969. URLhttps://arxiv.org/abs/2604.11969
Pith/arXiv arXiv 2026
-
[32]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023. doi: 10.48550/arXiv.2310.08560. URLhttps://arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[33]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior.arXiv preprint arXiv:2304.03442,
-
[34]
Generative Agents: Interactive Simulacra of Human Behavior
doi: 10.48550/arXiv.2304.03442. URLhttps://arxiv.org/abs/2304.03442
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.03442
-
[35]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334, 2023. URL https://arxiv.org/abs/ 2305.15334
Pith/arXiv arXiv 2023
-
[36]
Yi-Hao Peng, Jeffrey P. Bigham, and Jason Wu. Designpref: Capturing personal preferences in visual design generation.arXiv preprint arXiv:2511.20513, 2025. doi: 10.48550/arXiv.2511.20513. URL https://arxiv.org/abs/2511.20513
-
[37]
Rossi, Fan Du, Sungchul Kim, Eunyee Koh, Sana Malik, Tak Yeon Lee, and Nesreen K
Xin Qian, Ryan A. Rossi, Fan Du, Sungchul Kim, Eunyee Koh, Sana Malik, Tak Yeon Lee, and Nesreen K. Ahmed. Personalized visualization recommendation.ACM Transactions on the Web, 16(3):11:1–11:47,
-
[38]
URLhttps://doi.org/10.1145/3538703
doi: 10.1145/3538703. URLhttps://doi.org/10.1145/3538703
-
[39]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789, 2023. URLhttps://a...
Pith/arXiv arXiv 2023
-
[40]
LaMP: When large language models meet personalization.arXiv preprint arXiv:2304.11406, 2023
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. LaMP: When large language models meet personalization.arXiv preprint arXiv:2304.11406, 2023. doi: 10.48550/arXiv.2304.11406. URLhttps://arxiv.org/abs/2304.11406
-
[41]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, volume 36, pages 68539–68551, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/ha...
2023
-
[42]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, pages 8634–8652, 2023. URL https://proceedings.neurips.cc/paper_ files/paper/2023/hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html. 12
2023
-
[43]
Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, and Nancy X. R. Wang. D2S: Document- to-slide generation via query-based text summarization.arXiv preprint arXiv:2105.03664, 2021. doi: 10.48550/arXiv.2105.03664. URLhttps://arxiv.org/abs/2105.03664
-
[44]
Zecheng Tang, Chenfei Wu, Juntao Li, and Nan Duan. LayoutNUWA: Revealing the hidden layout expertise of large language models.arXiv preprint arXiv:2309.09506, 2023. URL https://arxiv.org/ abs/2309.09506
arXiv 2023
-
[45]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. URLhttps://arxiv.org/abs/2305.16291
Pith/arXiv arXiv 2023
-
[47]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022. URLhttps://arxiv.org/abs/2203.11171
Pith/arXiv arXiv 2022
-
[48]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Yu Wang and Xi Chen. Mirix: Multi-agent memory system for LLM-based agents.arXiv preprint arXiv:2507.07957, 2025. doi: 10.48550/arXiv.2507.07957. URL https://arxiv.org/abs/2507. 07957
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.07957 2025
-
[49]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversa- tion.arXiv preprint arXiv:2308.08155, 2023. URLhttps://arxiv.org/abs/2308.08155
Pith/arXiv arXiv 2023
-
[50]
From human memory to AI memory: A survey on memory mechanisms in the era of LLMs
Yaxiong Wu, Sheng Liang, Chen Zhang, Yichao Wang, Yongyue Zhang, Huifeng Guo, Ruiming Tang, and Yong Liu. From human memory to AI memory: A survey on memory mechanisms in the era of LLMs. arXiv preprint arXiv:2504.15965, 2025. URLhttps://arxiv.org/abs/2504.15965
Pith/arXiv arXiv 2025
-
[51]
Personalized response generation via generative split memory network
Yuwei Wu, Xuezhe Ma, and Diyi Yang. Personalized response generation via generative split memory network. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1956–1970, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naac...
-
[52]
Eric Xie, Danielle Waterfield, Michael Kennedy, and Aidong Zhang. SlideBot: A multi-agent framework for generating informative, reliable, multi-modal presentations.arXiv preprint arXiv:2511.09804, 2025. doi: 10.48550/arXiv.2511.09804. URLhttps://arxiv.org/abs/2511.09804
-
[53]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025. doi: 10.48550/arXiv.2502.12110. URL https://arxiv.org/abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[54]
PreGenie: An agentic framework for high-quality visual presentation generation
Xiaojie Xu, Xinli Xu, Sirui Chen, Haoyu Chen, Fan Zhang, and Ying-Cong Chen. PreGenie: An agentic framework for high-quality visual presentation generation. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 3045–3063, Suzhou, China, November 2025. As- sociation for Computational Linguistics. doi: 10.18653/v1/2025.findings-emnl...
-
[56]
URLhttps://arxiv.org/abs/2305.10601
-
[57]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=WE_vluYUL-X
2023
-
[58]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885, 2026. doi: 10.48550/arXiv.2601.01885. URL https://arxiv.org/abs/ 2601.01885
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.01885 2026
-
[59]
Wenzheng Zeng, Mingyu Ouyang, Langyuan Cui, and Hwee Tou Ng. SlideTailor: Personalized presentation slide generation for scientific papers.arXiv preprint arXiv:2512.20292, 2025. doi: 10.48550/arXiv.2512. 20292. URLhttps://arxiv.org/abs/2512.20292. 13
-
[61]
URLhttps://arxiv.org/abs/2303.11589
-
[62]
Zhehao Zhang, Ryan A. Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Der- noncourt, Joe Barrow, Tong Yu, Sungchul Kim, Ruiyi Zhang, Jiuxiang Gu, Tyler Derr, Hongjie Chen, Junda Wu, Xiang Chen, Zichao Wang, Subrata Mitra, Nedim Lipka, Nesreen Ahmed, and Yu Wang. Personalization of large language models: A survey.arXiv preprint arXiv:2...
arXiv 2024
-
[63]
PPTAgent: Generating and evaluating presentations beyond text-to- slides
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. PPTAgent: Generating and evaluating presentations beyond text-to- slides. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14402–14418, Suzhou, China, November 2025. Association for Comput...
-
[64]
DeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation
Hao Zheng, Guozhao Mo, Xinru Yan, Qianhao Yuan, Wenkai Zhang, Xuanang Chen, Yaojie Lu, Hongyu Lin, Xianpei Han, and Le Sun. DeepPresenter: Environment-grounded reflection for agentic presentation generation.arXiv preprint arXiv:2602.22839, 2026. doi: 10.48550/arXiv.2602.22839. URL https: //arxiv.org/abs/2602.22839
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.22839 2026
-
[65]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al. Judging LLM-as-a-judge with MT-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023. URLhttps://arxiv.org/abs/2306.05685
Pith/arXiv arXiv 2023
-
[66]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory.arXiv preprint arXiv:2305.10250, 2023. doi: 10.48550/arXiv. 2305.10250. URLhttps://arxiv.org/abs/2305.10250
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[67]
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. JudgeLM: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631, 2023. URL https://arxiv.org/abs/2310.17631. 14 A Appendix The appendix provides protocol details, supplemental quantitative tables, and qualitative examples that clarify how different memory signals appear in genera...
arXiv 2023
-
[68]
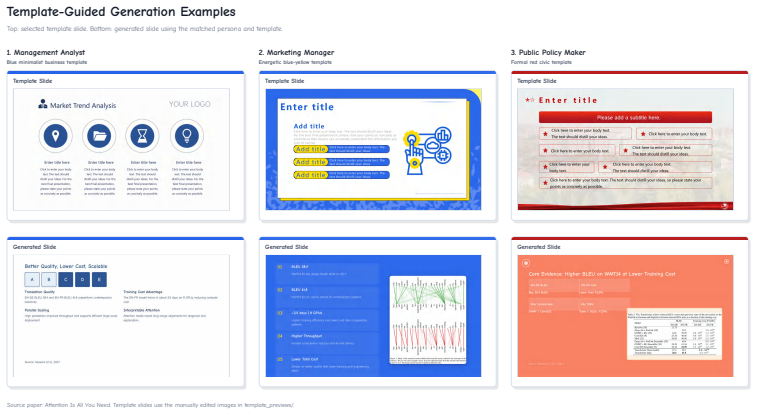
Management Analyst Blue minimalist business template Template Slide Generated Slide
-
[69]
Marketing Manager Energetic blue-yellow template Template Slide Generated Slide
-
[70]
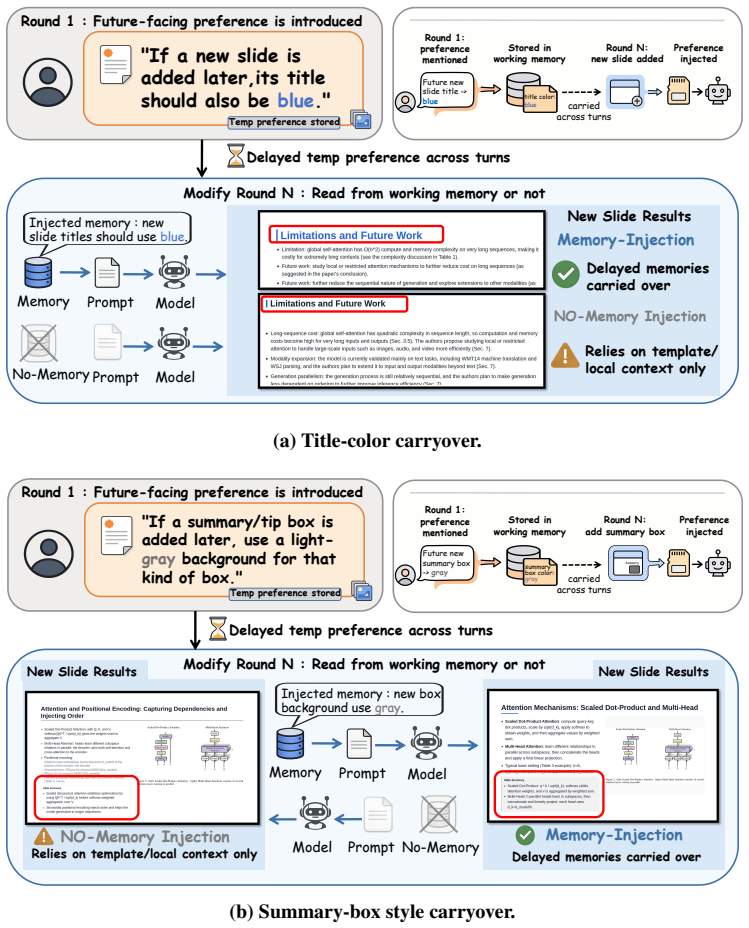
If a new slide is added later,its title should also be blue
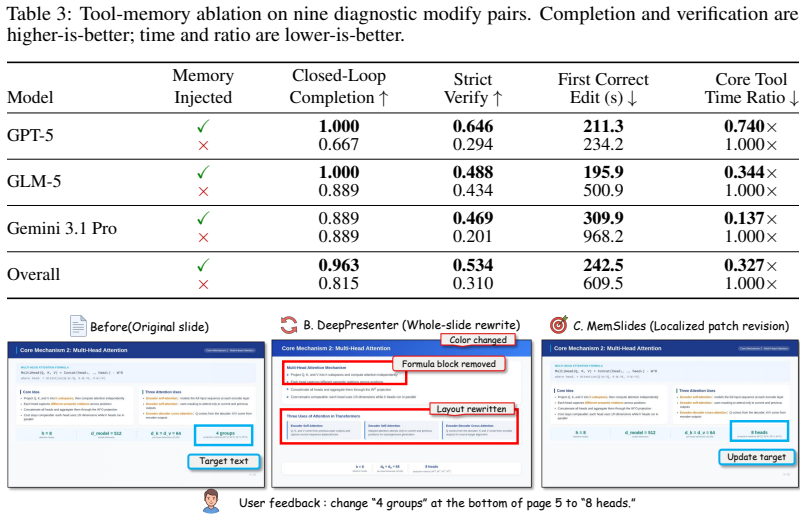
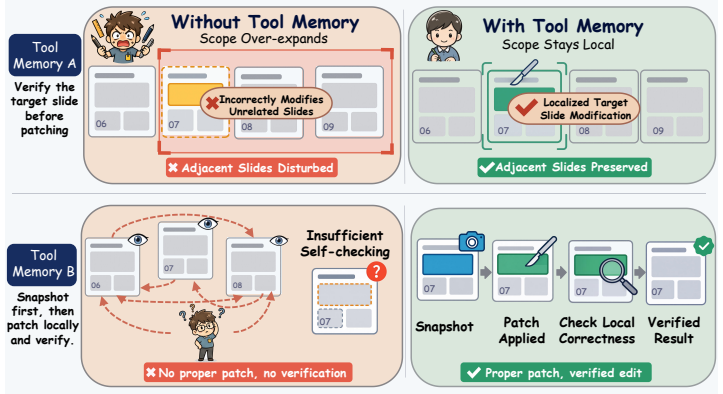
Public Policy Maker Formal red civic template Template Slide Generated Slide Source paper: Attention Is All You Need. Template slides use the manually edited images in template_previews/. Figure 7: Template-guided generation examples: selected template slides (top) and matched per- sona/template generations (bottom). A.8 Tool-Memory Pair-Level Details The...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.