Edge-Inference Governors Need Memory-Clock State
Pith reviewed 2026-06-27 02:40 UTC · model grok-4.3
The pith
Edge-inference DVFS governors must include memory-clock state to meet tight deadlines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frequency-aware latency estimators that model only CPU and GPU clocks fail to predict feasible operating points for deadline-aware DVFS governors because they omit the memory clock state; only models that include per-lockable EMC points can select budget-feasible, energy-minimal clocks for periodic inference.
What carries the argument
Per-lockable-point EMC tables that extend the CPUxGPU latency model to account for memory clock state and identify the feasible side of the energy frontier.
If this is right
- CPUxGPU estimators send the deployed governor to an infeasible operating point.
- Only an EMC-aware model identifies the feasible side of the energy frontier.
- Clustered misses make aggregate QoS rates understate deployment risk.
- Scoped inversion under monotone assumptions can select the wrong clock direction.
Where Pith is reading between the lines
- The requirement for separate EMC tables may appear on other edge SoCs that share a memory clock between CPU and GPU.
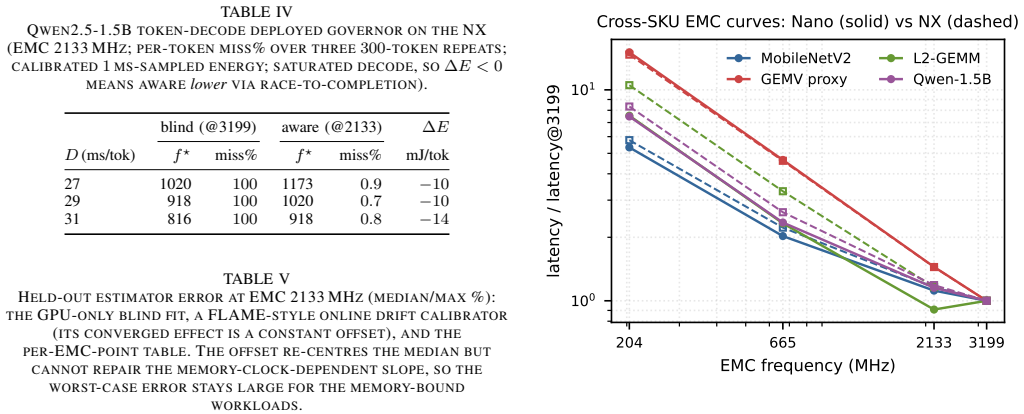
- For saturated LLM decode the EMC-aware policy can deliver lower energy than any blind choice that violates the deadline.
- Releasing the measurement harness allows direct checks on whether the 45% shift holds for new TensorRT engines or additional SKUs.
Load-bearing premise
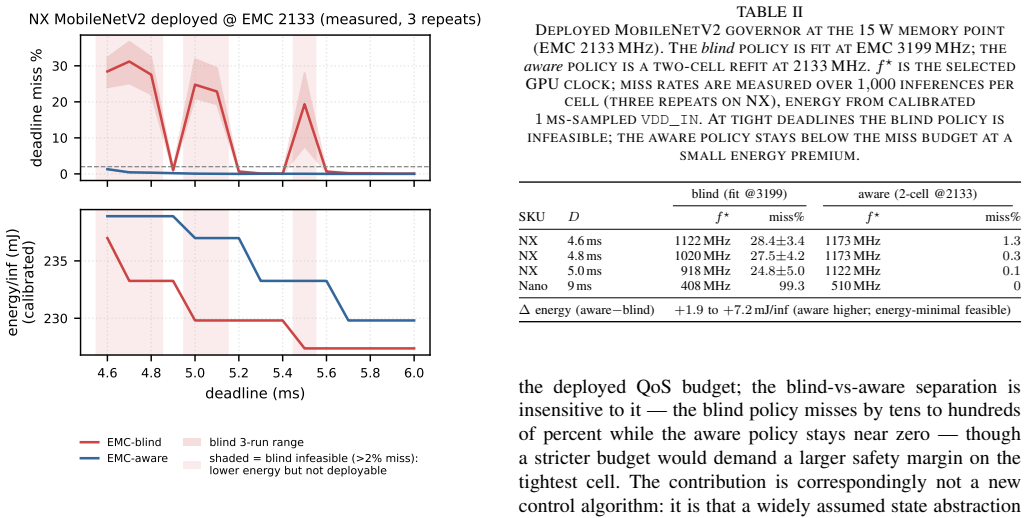
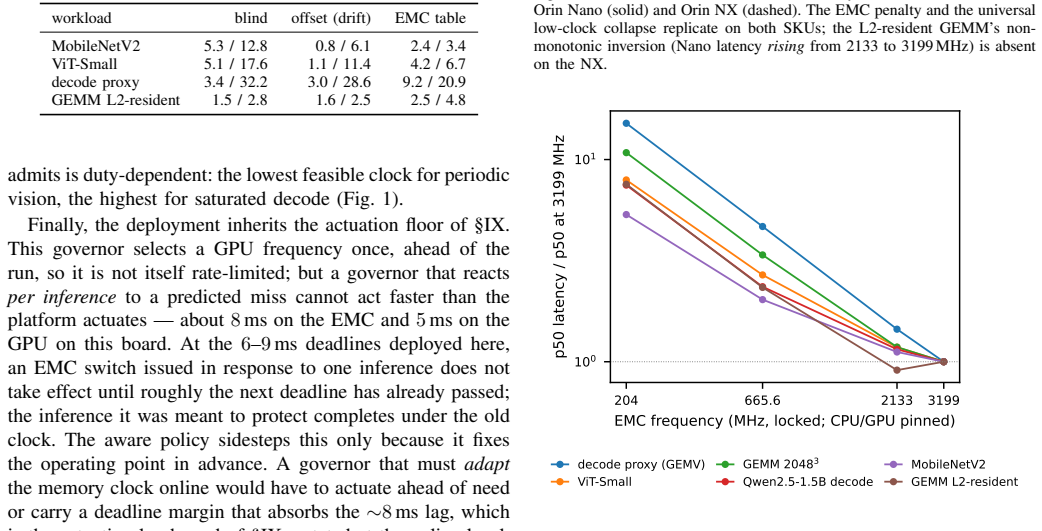
The measured latency shifts from EMC on the two tested Orin SKUs and workloads are representative of cases where CPUxGPU models cannot absorb the effect.
What would settle it
A measurement on additional Orin configurations showing that a single CPUxGPU model predicts the same set of feasible clocks as the per-EMC-point tables.
Figures
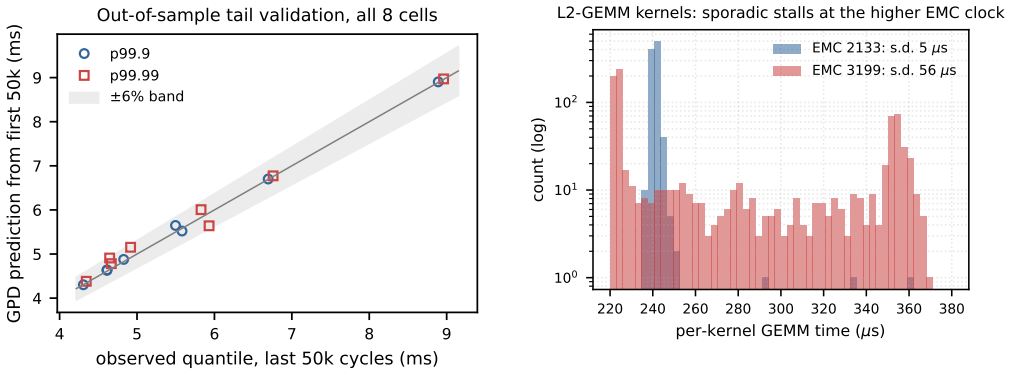
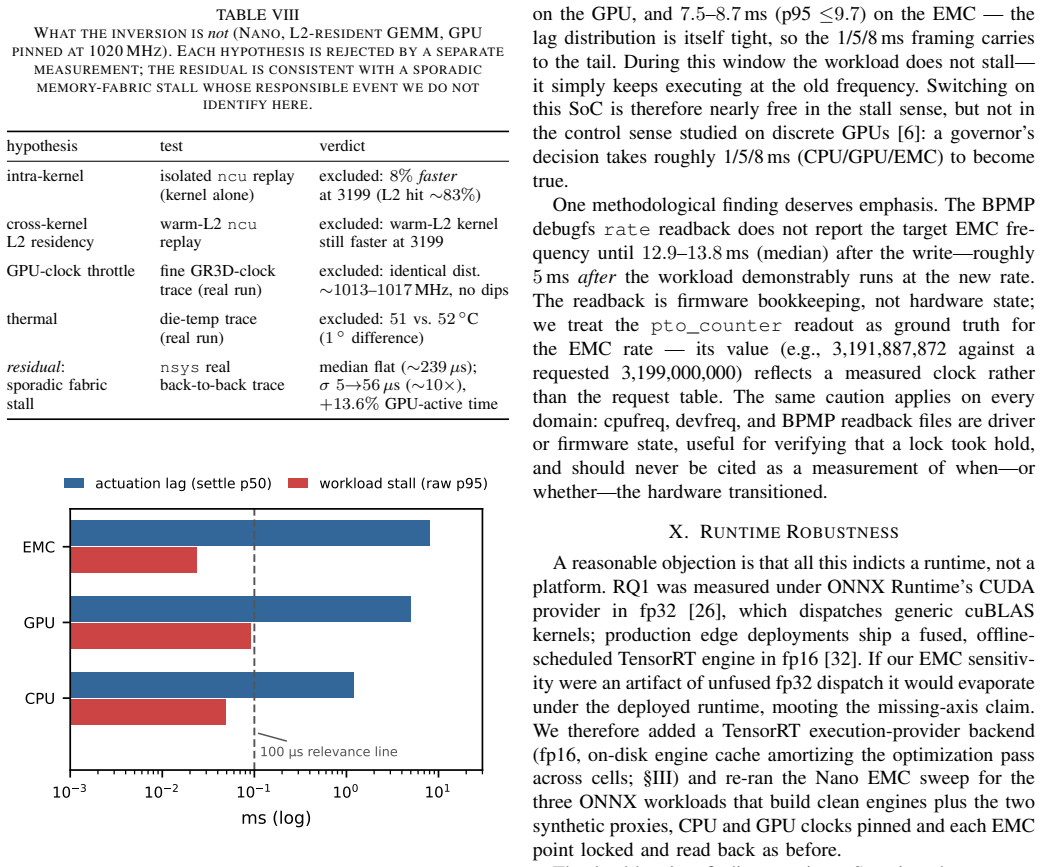
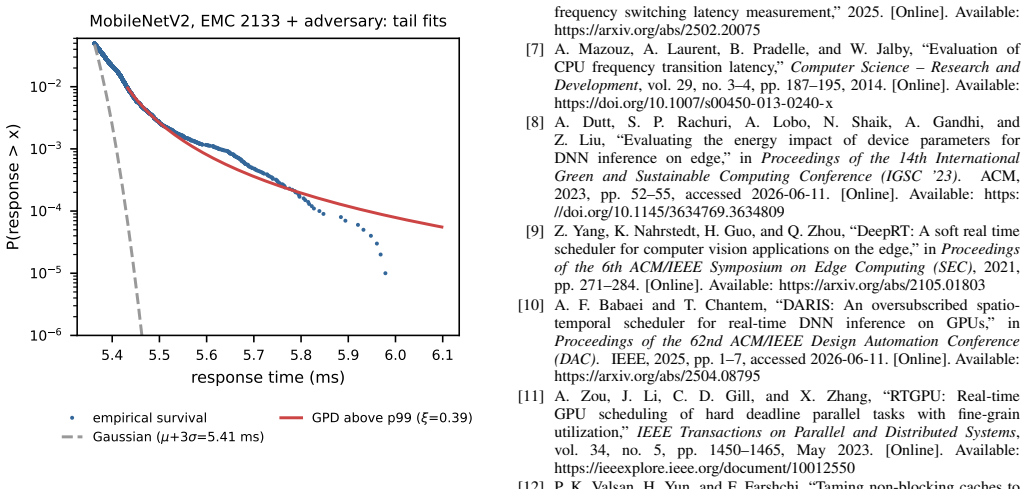
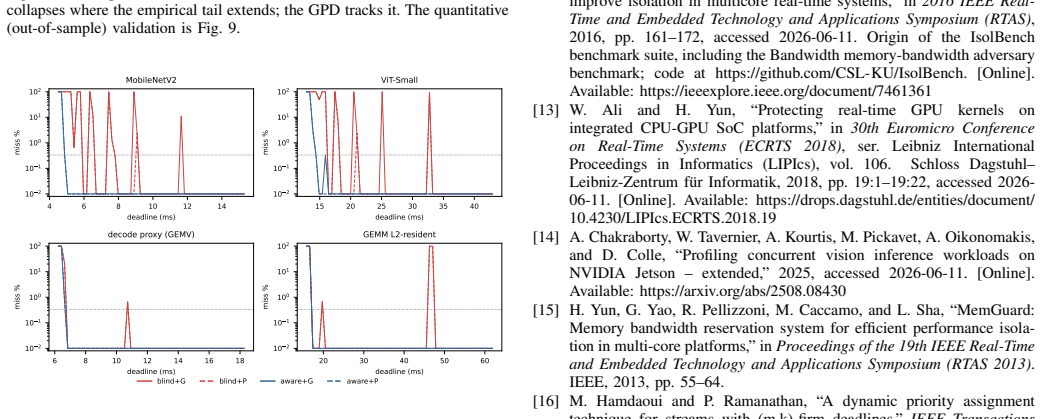
read the original abstract
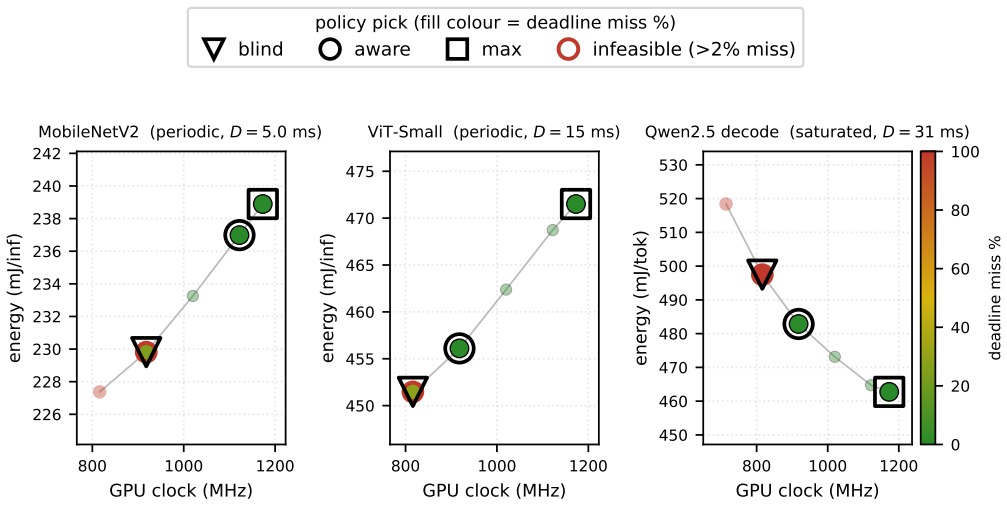
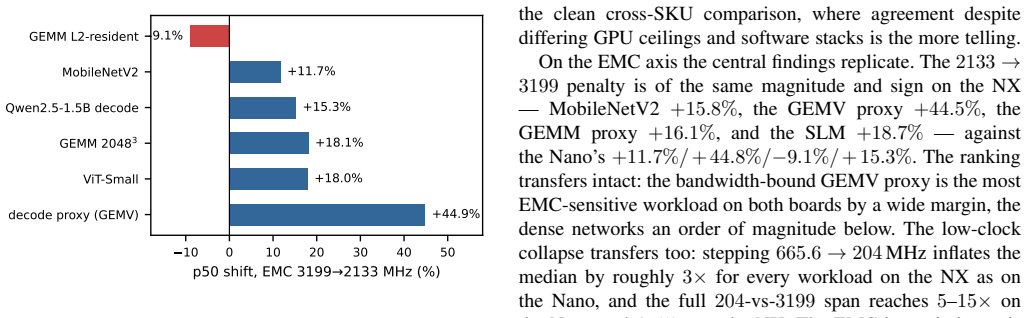
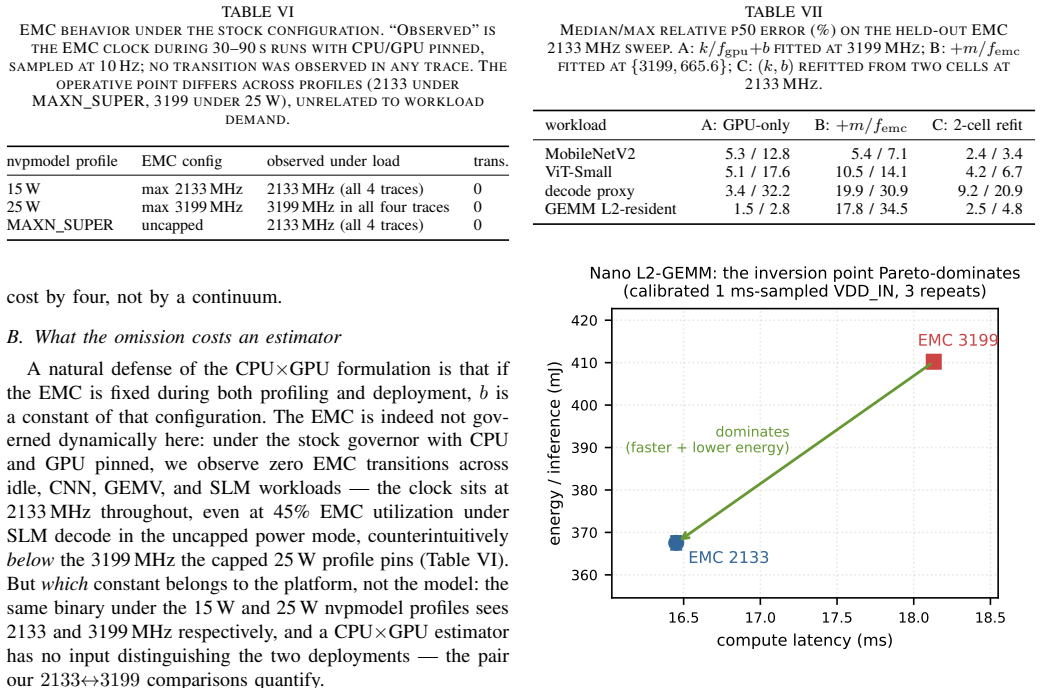
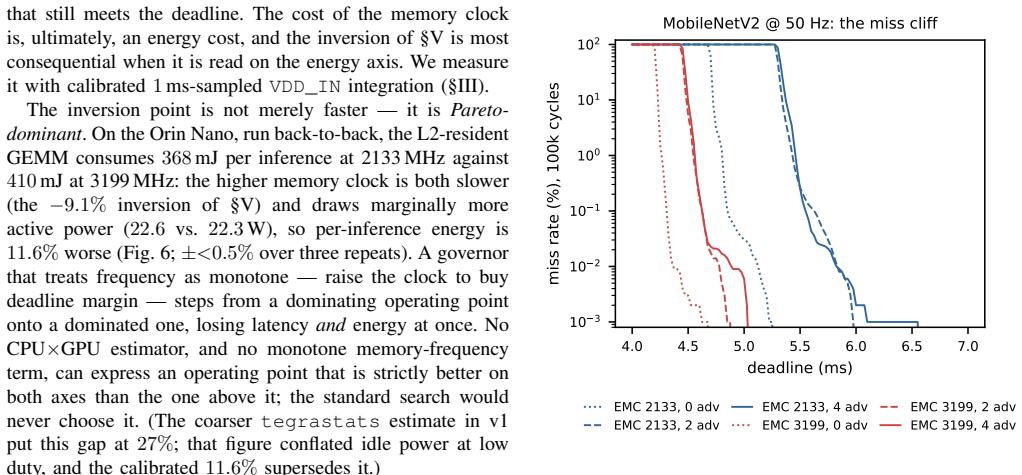
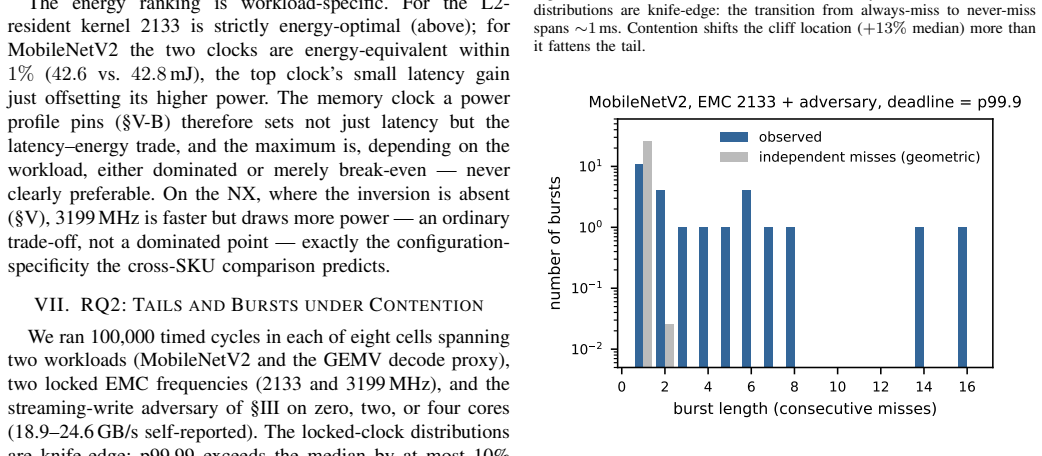
Frequency-aware latency estimators let deadline-aware DVFS governors schedule edge ML inference by modeling latency over CPU and GPU clocks, but they cannot observe the memory clock (EMC) -- a missing deployment state that decides whether a governor meets its deadlines and at what energy. We show this with a deployed, measured governor on a Jetson Orin NX: an EMC-blind GPU-only fit misses 25-28% of cycles at tight deadlines, whereas an EMC-aware refit holds misses to at most 1.3% under a 2% QoS miss budget by selecting a budget-feasible clock -- the energy-minimal one for periodic vision (calibrated module-rail power). The failure generalizes across three workload classes -- MobileNetV2, a ViT transformer, and Qwen2.5 LLM token decode (where saturated decode makes the aware policy lower-energy than the infeasible blind choice): a CPUxGPU estimator sends the deployed governor to an infeasible operating point, and only an EMC-aware model identifies the feasible side of the energy frontier. The effect is real and outside the CPUxGPU state abstraction: across two Orin SKUs sharing the same lockable EMC points it shifts median latency by up to ~45%, replicates on both, and survives a fused TensorRT fp16 engine. CPUxGPU models do not absorb it: per-lockable-point EMC tables are needed, a scoped inversion shows monotone assumptions can pick the wrong direction, and clustered misses make aggregate QoS rates understate deployment risk. We release the harness; this complements, not rebuts, the state of the art within its CPUxGPU scope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that frequency-aware latency estimators for edge ML inference governors, which model latency over CPU and GPU clocks, fail to account for memory clock (EMC) state. Direct hardware measurements on a Jetson Orin NX (and two Orin SKUs) with MobileNetV2, ViT, and Qwen2.5 decode workloads show that an EMC-blind GPU-only fit produces 25-28% deadline misses at tight deadlines, while an EMC-aware refit reduces misses to at most 1.3% under a 2% QoS budget by selecting the energy-minimal feasible clock. The effect produces median latency shifts up to ~45%, is not absorbed by CPUxGPU models (requiring per-lockable-point EMC tables), survives TensorRT fp16, and is demonstrated via a scoped inversion on monotone assumptions; the harness is released.
Significance. If the measurements hold, the work is significant because it identifies a deployment-critical state variable lying outside the standard CPUxGPU abstraction used in DVFS governors, with direct, quantified consequences for QoS compliance and energy at the edge. The release of the experimental harness is a clear strength that supports independent verification and extension of the results.
minor comments (2)
- [Abstract] The abstract would benefit from briefly defining 'EMC-aware refit' on first use to improve accessibility for readers outside the immediate sub-area.
- A summary table listing the observed latency shifts, miss rates, and energy values across the three workload classes and two SKUs would improve readability of the quantitative results.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work and the recommendation to accept. The summary accurately captures the core claim that EMC state lies outside the CPUxGPU abstraction and produces measurable QoS and energy consequences on Jetson Orin hardware.
Circularity Check
No significant circularity identified
full rationale
The manuscript presents no derivation chain or first-principles equations. Its load-bearing claims are direct empirical measurements of latency under controlled EMC/CPU/GPU clock combinations on two Orin SKUs, observed miss-rate gaps (25-28% vs. 1.3%) under a QoS budget, and the necessity of per-lockable-point EMC tables because CPUxGPU models fail to absorb the effect. These are falsifiable hardware observations, not fitted parameters renamed as predictions or self-referential definitions. No self-citations, ansatzes, or uniqueness theorems appear in the provided text. The released harness further makes the results externally testable rather than internally constructed.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Taming Asynchronous CPU-GPU Coupling for Frequency-aware Latency Estimation on Mobile Edge
J. Chen, J. You, Z. Liu, and Z. Li, “Taming asynchronous CPU-GPU coupling for frequency-aware latency estimation on mobile edge,” 2026, accessed 2026-06-11. [Online]. Available: https://arxiv.org/abs/2604.15357
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
DVFS-aware DNN inference on GPUs: Latency modeling and performance analysis,
Y . Han, Z. Nan, S. Zhou, and Z. Niu, “DVFS-aware DNN inference on GPUs: Latency modeling and performance analysis,” 2025, accessed 2026-06-11. [Online]. Available: https://arxiv.org/abs/2502.06295
-
[3]
NVIDIA Jetson Linux Developer Guide (Release 36.5): Platform Power and Performance — Jetson Orin Nano Series, Jetson Orin NX Series and Jetson AGX Orin Series,
NVIDIA Corporation, “NVIDIA Jetson Linux Developer Guide (Release 36.5): Platform Power and Performance — Jetson Orin Nano Series, Jetson Orin NX Series and Jetson AGX Orin Series,” https://docs.nvidia.com/jetson/ archives/r36.5/DeveloperGuide/SD/PlatformPowerAndPerformance/ JetsonOrinNanoSeriesJetsonOrinNxSeriesAndJetsonAgxOrinSeries. 5.4 5.5 5.6 5.7 5.8...
2026
-
[4]
Joint memory frequency and computing frequency scaling for energy-efficient DNN inference,
Y . Han, Z. Nan, S. Zhou, and Z. Niu, “Joint memory frequency and computing frequency scaling for energy-efficient DNN inference,” 2025, accessed 2026-06-11. [Online]. Available: https://arxiv.org/abs/ 2509.17970
-
[5]
zTT: Learning- based DVFS with zero thermal throttling for mobile devices,
S. Kim, K. Bin, S. Ha, K. Lee, and S. Chong, “zTT: Learning- based DVFS with zero thermal throttling for mobile devices,” inProceedings of the 19th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys ’21). Virtual Event, Wisconsin: ACM, 2021, pp. 41–53. [Online]. Available: https://doi.org/10.1145/3458864.3468161
-
[6]
Methodology for GPU frequency switching latency measurement,
D. Velicka, O. Vysocky, and L. Riha, “Methodology for GPU frequency switching latency measurement,” 2025. [Online]. Available: https://arxiv.org/abs/2502.20075
-
[7]
Evaluation of CPU frequency transition latency,
A. Mazouz, A. Laurent, B. Pradelle, and W. Jalby, “Evaluation of CPU frequency transition latency,”Computer Science – Research and Development, vol. 29, no. 3–4, pp. 187–195, 2014. [Online]. Available: https://doi.org/10.1007/s00450-013-0240-x
-
[8]
Evaluating the energy impact of device parameters for DNN inference on edge,
A. Dutt, S. P. Rachuri, A. Lobo, N. Shaik, A. Gandhi, and Z. Liu, “Evaluating the energy impact of device parameters for DNN inference on edge,” inProceedings of the 14th International Green and Sustainable Computing Conference (IGSC ’23). ACM, 2023, pp. 52–55, accessed 2026-06-11. [Online]. Available: https: //doi.org/10.1145/3634769.3634809
-
[9]
DeepRT: A soft real time scheduler for computer vision applications on the edge,
Z. Yang, K. Nahrstedt, H. Guo, and Q. Zhou, “DeepRT: A soft real time scheduler for computer vision applications on the edge,” inProceedings of the 6th ACM/IEEE Symposium on Edge Computing (SEC), 2021, pp. 271–284. [Online]. Available: https://arxiv.org/abs/2105.01803
-
[10]
DARIS: An oversubscribed spatio- temporal scheduler for real-time DNN inference on GPUs,
A. F. Babaei and T. Chantem, “DARIS: An oversubscribed spatio- temporal scheduler for real-time DNN inference on GPUs,” in Proceedings of the 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 2025, pp. 1–7, accessed 2026-06-11. [Online]. Available: https://arxiv.org/abs/2504.08795
-
[11]
RTGPU: Real-time GPU scheduling of hard deadline parallel tasks with fine-grain utilization,
A. Zou, J. Li, C. D. Gill, and X. Zhang, “RTGPU: Real-time GPU scheduling of hard deadline parallel tasks with fine-grain utilization,”IEEE Transactions on Parallel and Distributed Systems, vol. 34, no. 5, pp. 1450–1465, May 2023. [Online]. Available: https://ieeexplore.ieee.org/document/10012550
-
[12]
Taming non-blocking caches to improve isolation in multicore real-time systems,
P. K. Valsan, H. Yun, and F. Farshchi, “Taming non-blocking caches to improve isolation in multicore real-time systems,” in2016 IEEE Real- Time and Embedded Technology and Applications Symposium (RTAS), 2016, pp. 161–172, accessed 2026-06-11. Origin of the IsolBench benchmark suite, including the Bandwidth memory-bandwidth adversary benchmark; code at htt...
-
[13]
Protecting real-time GPU kernels on integrated CPU-GPU SoC platforms,
W. Ali and H. Yun, “Protecting real-time GPU kernels on integrated CPU-GPU SoC platforms,” in30th Euromicro Conference on Real-Time Systems (ECRTS 2018), ser. Leibniz International Proceedings in Informatics (LIPIcs), vol. 106. Schloss Dagstuhl– Leibniz-Zentrum f ¨ur Informatik, 2018, pp. 19:1–19:22, accessed 2026- 06-11. [Online]. Available: https://drop...
-
[14]
Profiling concurrent vision inference workloads on NVIDIA Jetson – extended,
A. Chakraborty, W. Tavernier, A. Kourtis, M. Pickavet, A. Oikonomakis, and D. Colle, “Profiling concurrent vision inference workloads on NVIDIA Jetson – extended,” 2025, accessed 2026-06-11. [Online]. Available: https://arxiv.org/abs/2508.08430
-
[15]
MemGuard: Memory bandwidth reservation system for efficient performance isola- tion in multi-core platforms,
H. Yun, G. Yao, R. Pellizzoni, M. Caccamo, and L. Sha, “MemGuard: Memory bandwidth reservation system for efficient performance isola- tion in multi-core platforms,” inProceedings of the 19th IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS 2013). IEEE, 2013, pp. 55–64
2013
-
[16]
A dynamic priority assignment technique for streams with (m,k)-firm deadlines,
M. Hamdaoui and P. Ramanathan, “A dynamic priority assignment technique for streams with (m,k)-firm deadlines,”IEEE Transactions on Computers, vol. 44, no. 12, pp. 1443–1451, 1995
1995
-
[17]
Weakly hard real-time systems,
G. Bernat, A. Burns, and A. Llamos ´ı, “Weakly hard real-time systems,” IEEE Transactions on Computers, vol. 50, no. 4, pp. 308–321, 2001
2001
-
[18]
Control- system stability under consecutive deadline misses constraints,
M. Maggio, A. Hamann, E. Mayer-John, and D. Ziegenbein, “Control- system stability under consecutive deadline misses constraints,” in Proceedings of the 32nd Euromicro Conference on Real-Time Systems (ECRTS 2020), ser. LIPIcs, vol. 165. Schloss Dagstuhl – Leibniz- Zentrum f ¨ur Informatik, 2020, pp. 21:1–21:24
2020
-
[19]
Statistical analysis of WCET for scheduling,
S. Edgar and A. Burns, “Statistical analysis of WCET for scheduling,” inProceedings of the 22nd IEEE Real-Time Systems Symposium (RTSS 2001). IEEE Computer Society, 2001, pp. 215–224
2001
-
[20]
Measurement-based probabilistic timing analysis for multi-path pro- grams,
L. Cucu-Grosjean, L. Santinelli, M. Houston, C. Lo, T. Vardanega, L. Kosmidis, J. Abella, E. Mezzetti, E. Qui ˜nones, and F. J. Cazorla, “Measurement-based probabilistic timing analysis for multi-path pro- grams,” inProceedings of the 24th Euromicro Conference on Real-Time Systems (ECRTS 2012). IEEE Computer Society, 2012, pp. 91–101
2012
-
[21]
A survey of probabilistic timing analysis techniques for real-time systems,
R. I. Davis and L. Cucu-Grosjean, “A survey of probabilistic timing analysis techniques for real-time systems,”Leibniz Transactions on Embedded Systems (LITES), vol. 6, no. 1, pp. 03:1–03:60, 2019
2019
-
[22]
Symbolic execution for software testing: Three decades later,
J. Dean and L. A. Barroso, “The tail at scale,”Communications of the ACM, vol. 56, no. 2, pp. 74–80, Feb. 2013. [Online]. Available: https://doi.org/10.1145/2408776.2408794
-
[23]
V . J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka, C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S. Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. St. John, P. Kanwar, D. Lee, J. Liao, A. Lokhmotov, F. Massa, P. Meng, P. Micikevicius, C. Osborne, ...
-
[24]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,” inProceedings of Machine Learning and Systems, D. Song, M. Carbin, and T. Chen, Eds., vol. 5. Curan, 2023, pp. 606–624. [On- line]. Available: https://proceedings.mlsys.org/paper files/paper/2023/ hash/c4be71ab...
2023
-
[25]
Full stack optimization of transformer inference: a survey,
S. Kim, C. Hooper, T. Wattanawong, M. Kang, R. Yan, H. Genc, G. Dinh, Q. Huang, K. Keutzer, M. W. Mahoney, Y . S. Shao, and A. Gholami, “Full stack optimization of transformer inference: a survey,” 2023, accessed 2026-06-11. [Online]. Available: https: //arxiv.org/abs/2302.14017
-
[26]
ONNX runtime,
Microsoft, “ONNX runtime,” https://github.com/microsoft/onnxruntime, release v1.23.0, CUDA execution provider. Accessed 2026-06-12
2026
-
[27]
MobileNetV2: Inverted residuals and linear bottlenecks,
M. Sandler, A. G. Howard, M. Zhu, A. Zhmoginov, and L. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018, pp. 4510–4520
2018
-
[28]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in9th International Conference on Learning Representations (ICLR 2021), 2021. [Online]. Available: https://openreview.n...
2021
-
[29]
Qwen Team, “Qwen2.5 technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
llama.cpp: LLM inference in C/C++,
G. Gerganov and contributors, “llama.cpp: LLM inference in C/C++,” https://github.com/ggml-org/llama.cpp, commit ac4cdde, CUDA back- end, Q4 K M GGUF. Accessed 2026-06-12
2026
-
[31]
Roofline: An insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. A. Patterson, “Roofline: An insightful visual performance model for multicore architectures,”Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009
2009
-
[32]
TensorRT developer guide,
NVIDIA, “TensorRT developer guide,” https://docs.nvidia.com/ deeplearning/tensorrt/, accessed 2026-06-12
2026
-
[33]
Real-time group scheduling,
The Linux Kernel documentation, “Real-time group scheduling,” documentation/scheduler/sched-rt-group.rst. Accessed 2026-06-12. [On- line]. Available: https://docs.kernel.org/scheduler/sched-rt-group.html
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.