Imprint: Online Memory Compression for Long-Horizon Egocentric QA
Pith reviewed 2026-07-02 14:15 UTC · model grok-4.3
The pith
Imprint treats long-horizon egocentric memory as online compression of Interaction Records using recurrence, recency and distinctiveness signals to raise QA accuracy from 31.0% to 35.8%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
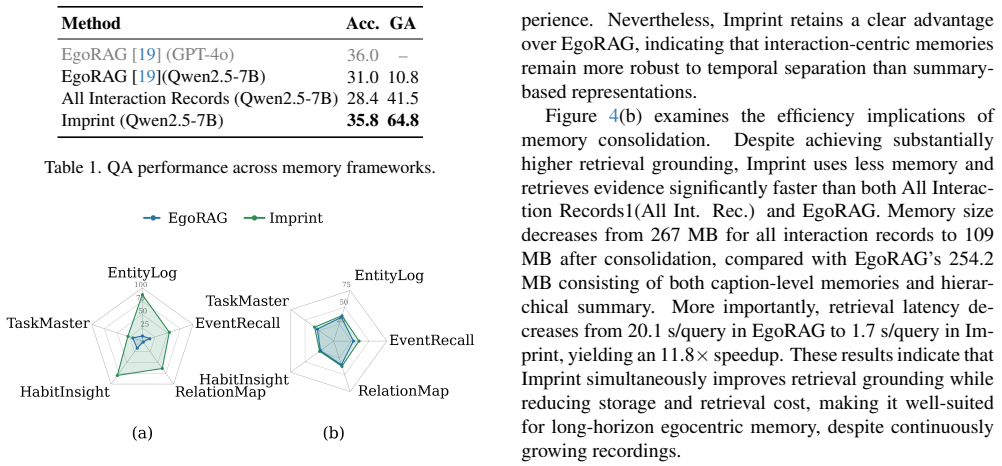
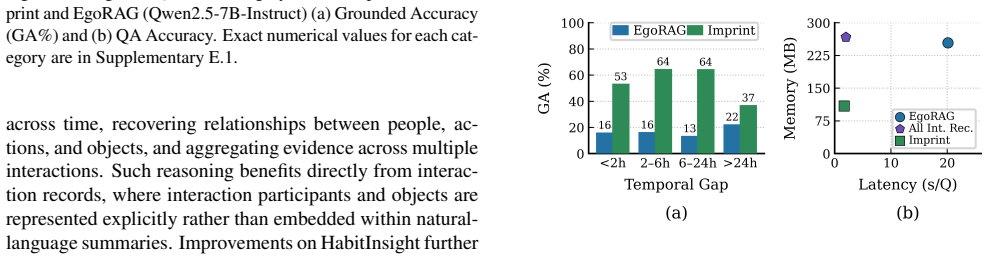
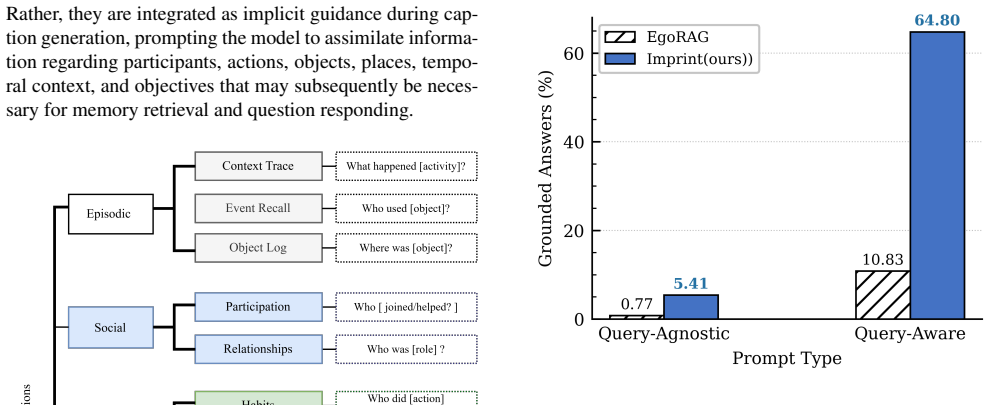
Imprint formulates long-horizon egocentric memory as an online compression problem in which incoming observations are first turned into structured Interaction Records, then continuously organized into recurring interaction patterns, and finally selectively retained or compressed according to recurrence, recency and distinctiveness; on the EgoLifeQA benchmark the resulting memory yields 35.8% QA accuracy, six times more evidence-grounded answers than EgoRAG, 2.3 times smaller memory footprint and 11.8 times lower retrieval latency when the same LLM is used.
What carries the argument
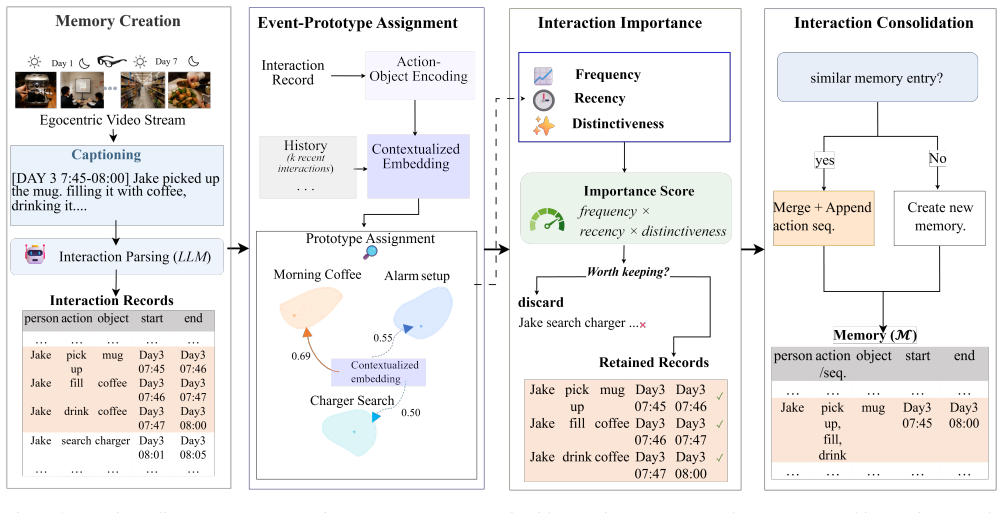
The interaction-centric memory framework that converts observations into Interaction Records and applies recurrence, recency and distinctiveness signals to decide which patterns to retain and how to compress them for retrieval.
If this is right
- QA accuracy on seven-day egocentric questions rises from 31.0% to 35.8% with no change in the underlying LLM.
- Evidence-grounded answers increase by a factor of six relative to hierarchical summarization baselines.
- Memory footprint drops by a factor of 2.3 while retrieval latency drops by a factor of 11.8.
- Long-horizon evidence aggregation becomes feasible because recurring interactions remain explicit rather than absorbed into coarse summaries.
Where Pith is reading between the lines
- The same compression rules could be applied to robot memory or multi-day video archives where recurring events must be retrieved quickly.
- If the consolidation signals prove robust, they might replace hand-crafted rules with data-driven selection that adapts to new environments.
- The approach separates memory design from model scale, suggesting that retrieval performance on long horizons can improve without larger LLMs.
Load-bearing premise
Human memory consolidation signals of recurrence, recency and distinctiveness can be translated into selection and compression rules that keep the specific evidence required for long-horizon QA without critical loss.
What would settle it
Running the EgoLifeQA benchmark with Imprint and finding that the fraction of evidence-grounded answers is not at least six times higher than with EgoRAG.
Figures





read the original abstract
Long-horizon egocentric question answering involves answering about events that have occurred hours or days in the past. This requires memory representations that remain both retrieval-effective and scalable over days or weeks of recording. Existing long-horizon egocentric QA methods construct memory as hierarchical textual summaries of observations. While effective for reducing memory size, summarization optimizes for descriptive compression rather than retrieval: repeated interactions are absorbed into coarse textual descriptions instead of being preserved as explicit, recurring memory units, making long-horizon evidence aggregation difficult. We propose Imprint, an interaction-centric memory framework that formulates long-horizon egocentric memory as an online memory compression problem rather than summarization. Incoming observations are first represented as structured Interaction Records and continuously organized into recurring interaction patterns. Using human memory consolidation signals of recurrence, recency, and distinctiveness, Imprint selectively retains and compresses interactions into a compact retrieval-oriented memory. We evaluate Imprint on EgoLifeQA, a seven-day egocentric benchmark containing questions that require reasoning over interactions occurring hours to days before the query. With the same LLM, Imprint improves QA accuracy from 31.0% to 35.8%, increases evidence-grounded answers by $6\times$ compared with EgoRAG, reduces memory footprint by $2.3\times$, and decreases retrieval latency by $11.8\times$. These results demonstrate that memory compression provides a scalable and retrieval-effective foundation for long-horizon egocentric question answering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Imprint, an interaction-centric online memory compression framework for long-horizon egocentric QA. Observations are encoded as structured Interaction Records that are organized into recurring patterns; human memory consolidation signals (recurrence, recency, distinctiveness) are used to selectively retain and compress these records into a compact, retrieval-oriented memory. On the seven-day EgoLifeQA benchmark the method reports 35.8 % QA accuracy (baseline 31.0 %), a 6× increase in evidence-grounded answers versus EgoRAG, a 2.3× reduction in memory footprint, and an 11.8× reduction in retrieval latency, all with the same underlying LLM.
Significance. If the reported gains prove robust, the work supplies a concrete, retrieval-focused alternative to summarization-based memory for multi-day egocentric streams. The quantitative improvements on a challenging long-horizon benchmark, together with the explicit grounding in recurrence/recency/distinctiveness signals, would be of clear interest to the egocentric vision and long-term memory communities.
major comments (2)
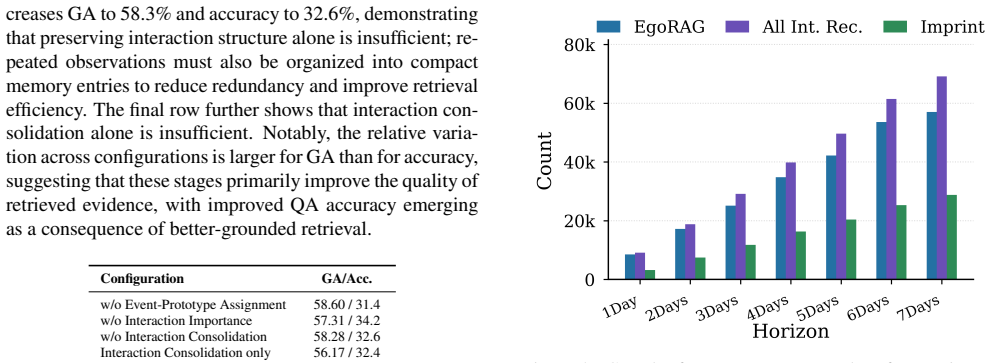
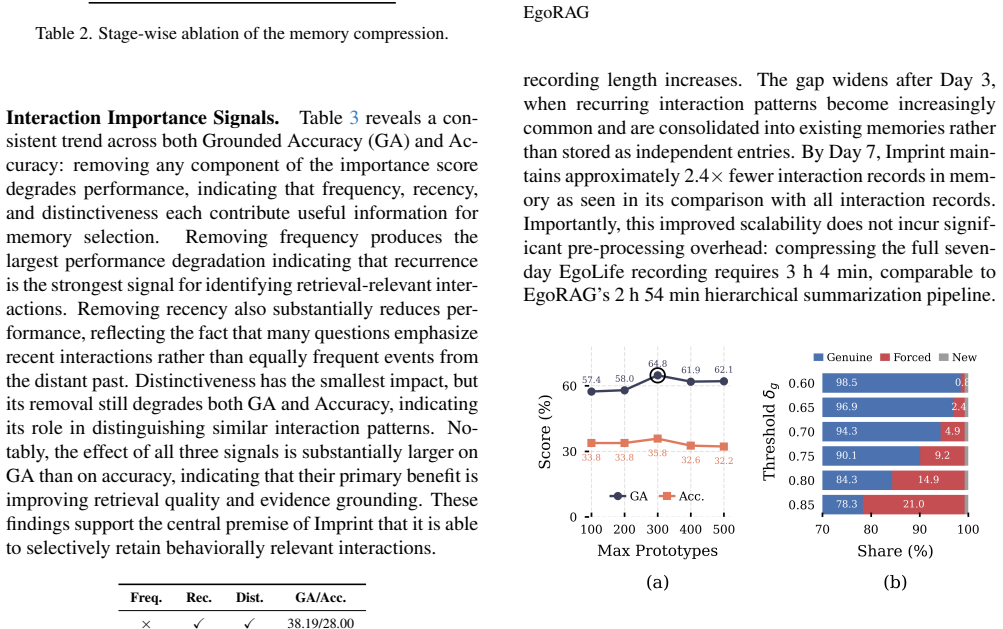
- [Abstract / framework description] Abstract and framework description: the central claim that the three consolidation signals produce the stated accuracy, evidence-grounding, footprint, and latency gains is load-bearing, yet no ablation isolates the contribution of each signal or quantifies sensitivity to the free recurrence/recency/distinctiveness thresholds; without these controls it is impossible to attribute the deltas to the proposed compression rules rather than to unstated pipeline choices.
- [Evaluation] Evaluation section: the 6× evidence-grounded answer increase, 2.3× memory reduction, and 11.8× latency reduction are the primary quantitative support for the method, but the manuscript supplies neither the precise definition of “evidence-grounded,” the data splits used for EgoLifeQA, nor the exact configuration of the EgoRAG baseline; these omissions prevent verification that the metrics reflect the compression mechanism.
minor comments (1)
- [Abstract] The term “Interaction Records” is introduced in the abstract without an explicit definition or example; a short illustrative figure or table in the methods would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, acknowledging the need for additional details and experiments to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / framework description] Abstract and framework description: the central claim that the three consolidation signals produce the stated accuracy, evidence-grounding, footprint, and latency gains is load-bearing, yet no ablation isolates the contribution of each signal or quantifies sensitivity to the free recurrence/recency/distinctiveness thresholds; without these controls it is impossible to attribute the deltas to the proposed compression rules rather than to unstated pipeline choices.
Authors: We agree that the manuscript does not contain ablations isolating the individual contributions of the recurrence, recency, and distinctiveness signals or sensitivity analysis to the associated thresholds. This limits the ability to attribute performance gains specifically to the consolidation rules. In the revised version we will add an ablation study that systematically varies or removes each signal and reports the resulting changes in QA accuracy, evidence-grounded answers, memory footprint, and latency, together with threshold sensitivity results. revision: yes
-
Referee: [Evaluation] Evaluation section: the 6× evidence-grounded answer increase, 2.3× memory reduction, and 11.8× latency reduction are the primary quantitative support for the method, but the manuscript supplies neither the precise definition of “evidence-grounded,” the data splits used for EgoLifeQA, nor the exact configuration of the EgoRAG baseline; these omissions prevent verification that the metrics reflect the compression mechanism.
Authors: We concur that the manuscript currently lacks an explicit definition of “evidence-grounded” answers, a description of the EgoLifeQA data splits, and the precise configuration of the EgoRAG baseline. These omissions hinder independent verification. We will revise the evaluation section to supply the exact definition of evidence-grounded answers, document the train/test splits employed, and provide the full configuration details (including prompts, retrieval parameters, and implementation choices) for the EgoRAG baseline. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript contains no equations, derivations, fitted parameters, or self-citation chains that bear the load of the central claims. All reported results (accuracy lift from 31.0% to 35.8%, 6× evidence grounding, 2.3× memory reduction, 11.8× latency reduction) are presented as direct empirical outcomes of running the described pipeline on the EgoLifeQA benchmark against stated baselines. The mapping of recurrence/recency/distinctiveness signals into compression rules is introduced as an explicit design choice rather than derived from prior self-work or reduced to its own inputs. This is the normal case of an empirical systems paper whose claims remain externally falsifiable on the benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- recurrence/recency/distinctiveness thresholds
axioms (1)
- domain assumption Human memory consolidation signals (recurrence, recency, distinctiveness) translate effectively into AI memory selection rules that preserve QA-relevant evidence
invented entities (2)
-
Interaction Records
no independent evidence
-
recurring interaction patterns
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The epic-kitchens dataset: Collection, challenges and base- 8 lines.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):4125–4141, 2020
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. The epic-kitchens dataset: Collection, challenges and base- 8 lines.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):4125–4141, 2020. 2
2020
-
[2]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 2
2022
-
[3]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented gen- eration.arXiv preprint arXiv:2410.05779, 2(3), 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150, 2025
Haoyu Huang, Yongfeng Huang, Junjie Yang, Zhenyu Pan, Yongqiang Chen, Kaili Ma, Hongzhi Chen, and James Cheng. Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150, 2025. 2
-
[5]
Oxford University Press, 2006
R Reed Hunt and James B Worthen.Distinctiveness and memory. Oxford University Press, 2006. 2, 3
2006
-
[6]
Stronger baselines for retrieval-augmented generation with long-context language models
Alex Laitenberger, Christopher D Manning, and Nelson F Liu. Stronger baselines for retrieval-augmented generation with long-context language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 32547–32557, 2025. 2
2025
-
[7]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
In the eye of beholder: Joint learning of gaze and actions in first person video
Yin Li, Miao Liu, and James M Rehg. In the eye of beholder: Joint learning of gaze and actions in first person video. In Proceedings of the European conference on computer vision (ECCV), pages 619–635, 2018. 2
2018
-
[9]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fa- had Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory
James L McClelland, Bruce L McNaughton, and Randall C O’Reilly. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological review, 102(3):419, 1995. 2, 3
1995
-
[11]
The castle 2024 dataset: Advancing the art of multimodal understanding
Luca Rossetto, Werner Bailer, Duc-Tien Dang-Nguyen, Gra- ham Healy, Björn Þór Jónsson, Onanong Kongmeesub, Hoang-Bao Le, Stevan Rudinac, Klaus Schöffmann, Flo- rian Spiess, Allie Tran, Minh-Triet Tran, Quang-Linh Tran, and Cathal Gurrin. The castle 2024 dataset: Advancing the art of multimodal understanding. InProceedings of the 33rd ACM International Con...
2024
-
[12]
Stochastic consolidation of lifelong memory
Nimrod Shaham, Jay Chandra, Gabriel Kreiman, and Haim Sompolinsky. Stochastic consolidation of lifelong memory. Scientific Reports, 12(1):13107, 2022. 2, 3
2022
-
[13]
Charades-Ego: A Large-Scale Dataset of Paired Third and First Person Videos
Gunnar A Sigurdsson, Abhinav Gupta, Cordelia Schmid, Ali Farhadi, and Karteek Alahari. Charades-ego: A large-scale dataset of paired third and first person videos.arXiv preprint arXiv:1804.09626, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Detecting social engagement of elderly from lifelog image-streams to identify effective cues for autobio- graphic recall
Vengateswaran Subramaniam, Vigneshwaran Subbaraju, Debaditya Roy, Pramath Krishna, Thivya Kandappu, and Qianli Xu. Detecting social engagement of elderly from lifelog image-streams to identify effective cues for autobio- graphic recall. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 3380– 3389, 2026. 1
2026
-
[15]
Saki-rag: Mitigating context fragmentation in long- document rag via sentence-level attention knowledge inte- gration
Wenyu Tao, Xiaofen Xing, Zeliang Li, and Xiangmin Xu. Saki-rag: Mitigating context fragmentation in long- document rag via sentence-level attention knowledge inte- gration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1195–1213,
2025
-
[16]
Ego-r1: Agentic chain-of- tool-thought for ultra-long egocentric video reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence,
Shulin Tian, Ruiqi Wang, Hongming Guo, Penghao Wu, Yuhao Dong, Xiuying Wang, Jingkang Yang, Hao Zhang, Hongyuan Zhu, and Ziwei Liu. Ego-r1: Agentic chain-of- tool-thought for ultra-long egocentric video reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence,
-
[17]
Encoding specificity and retrieval processes in episodic memory.Psychological review, 80(5):352, 1973
Endel Tulving and Donald M Thomson. Encoding specificity and retrieval processes in episodic memory.Psychological review, 80(5):352, 1973. 2
1973
-
[18]
Efficient integration of external knowledge to llm-based world models via retrieval-augmented generation and reinforcement learning
Chang Yang, Xinrun Wang, Qinggang Zhang, Qi Jiang, and Xiao Huang. Efficient integration of external knowledge to llm-based world models via retrieval-augmented generation and reinforcement learning. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 9484– 9501, 2025. 2
2025
-
[19]
Egolife: Towards ego- centric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xi- amengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, et al. Egolife: Towards ego- centric life assistant. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28885–28900,
-
[20]
1, 2, 5, 6, 7, 8, 9, 10, 14, 15, 16, 17
-
[21]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 1, 2 A. Query-Aware Captioning To improve the extraction of interaction records, we define set of meta-questions based on EgoLifeQA [19]. Condi- tioning caption creation on these meta-questions...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
No text before or after
Output ONLY a valid JSON array. No text before or after
-
[23]
Create ONE FIO per distinct interaction
-
[24]
"persons" MUST list ALL named persons in the scene
-
[25]
speech_content
"speech_content" MUST include exact words when a person speaks
-
[26]
object" and
"object" and "tool" are different
-
[27]
Use null for missing string fields
-
[28]
Do NOT invent information not present in the caption
-
[29]
The caption is from an egocentric camera
-
[30]
I" refers to the camera wearer. EXAMPLES: Caption:
"I" refers to the camera wearer. EXAMPLES: Caption: "I looked at my phone, opened the timer, and set it to 10 seconds." Output: [ { "persons": "Jake", "action": "looked at", "object": "phone", "tool": null, "app": null, "source_location": null, "target_location": null, "speech_content": "", "attributes": {} } ] Now extract all interactions record from the...
-
[31]
No explanations, no comments, no markdown
Output ONLY valid JSON. No explanations, no comments, no markdown
-
[32]
Use ONLY the allowed values listed in the schema
-
[33]
If a value is unknown or not explicitly stated, use null
-
[34]
Do NOT invent new fields or values
-
[35]
Choose the entity the question is ASKING ABOUT, not merely mentioning
-
[36]
The "action" field: set ONLY if the question explicitly states a concrete action
-
[37]
Now X does Y, what/who...?
For contextual questions ("Now X does Y, what/who...?"), extract entity and action
-
[38]
whose" and
"whose" and "who" both map to query_intent "who". SCHEMA: { "entity": string | null, "entity_relation": "reference" | "ownership" | "possession", "action": string | null, "object_relation": "contained_object" | "on_object" | null, "related_person": string | null, "temporal_relation":"first_time" | "last_time" | "before" | "after" | "habitual" | "yesterday...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.