Sublinearly Structured Deep Neural Networks Achieve Feature Learning Consistency for Compositional Functions
Pith reviewed 2026-06-26 06:08 UTC · model grok-4.3
The pith
Sublinearly structured DNNs achieve feature-learning consistency for hierarchically compositional functions even when overparameterized.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
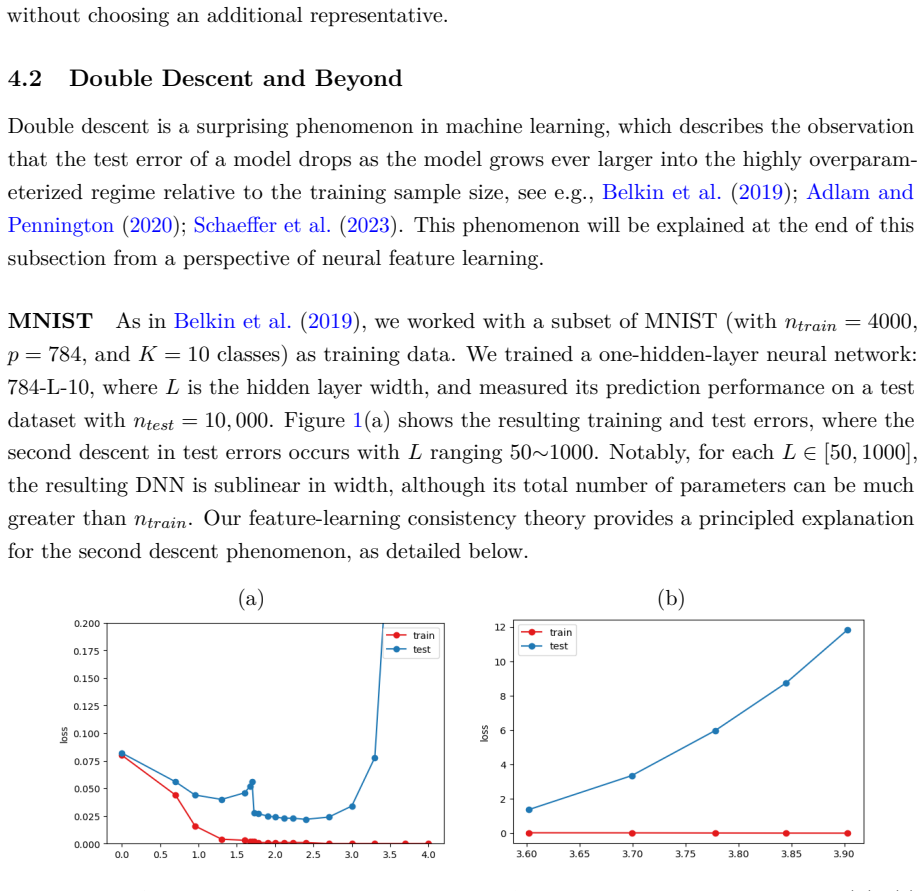
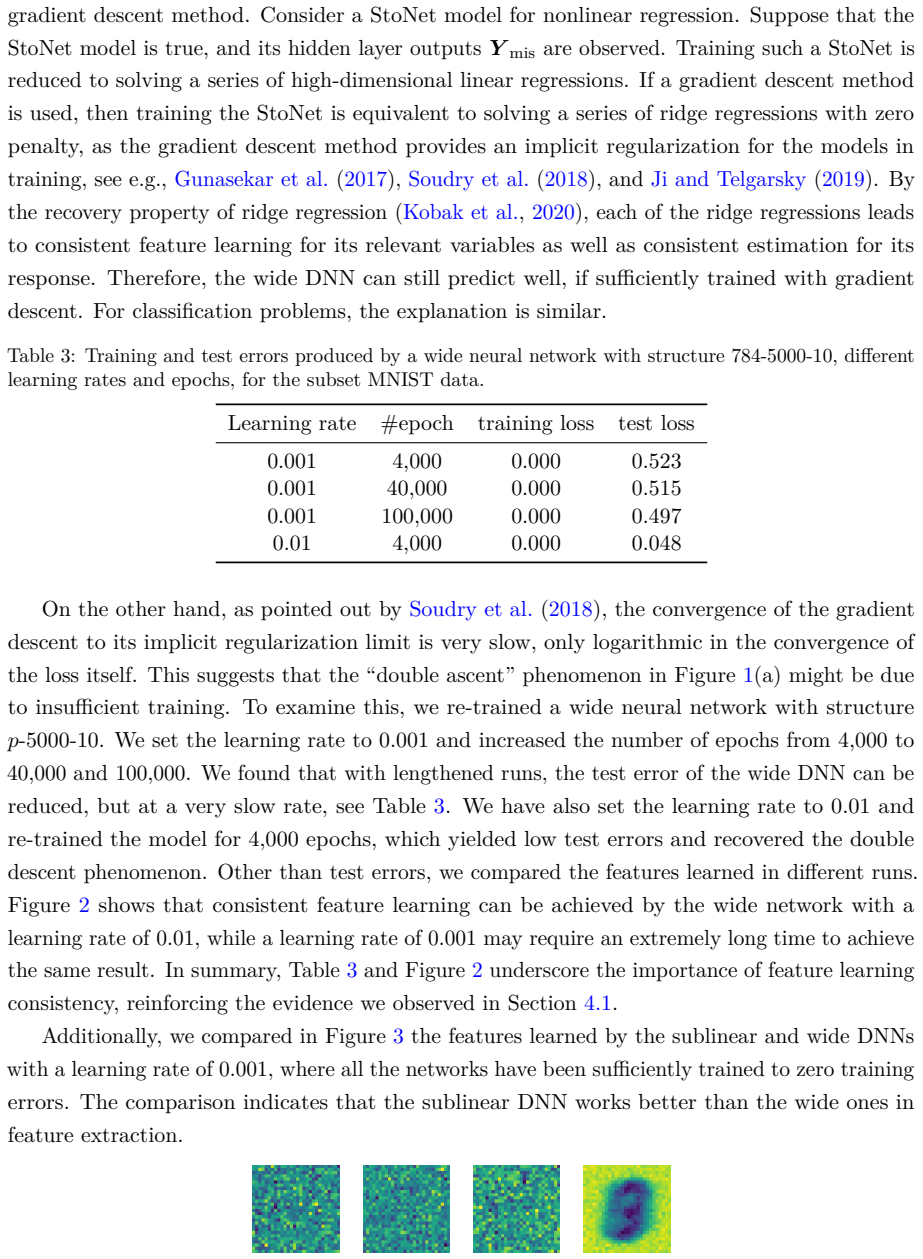
We establish feature-learning consistency guarantees for sublinearly structured DNNs—architectures whose input/output dimensions and number of hidden neurons grow sublinearly with the sample size—when learning hierarchically compositional target functions. Importantly, this consistency still holds even in the conventional over-parameterized regime where the total number of parameters exceeds the number of training samples. We further prove that the sublinearly structured DNNs achieve universal approximation for hierarchically compositional functions in the large-sample limit. Moreover, images exhibit an inherent hierarchical, compositional structure.
What carries the argument
Sublinearly structured DNNs, architectures in which input and output dimensions together with the number of hidden neurons scale sublinearly with sample size, carrying the consistency and approximation arguments for hierarchically compositional targets.
If this is right
- Consistency is retained even when parameter count greatly exceeds sample count.
- Widely used CNNs satisfy the sublinear scaling condition on standard image tasks.
- Universal approximation holds for the same function class in the large-sample limit.
- The results supply a statistical rationale for the observed performance of large models on image data.
Where Pith is reading between the lines
- The emphasis on growth-rate constraints suggests that explicit architectural scaling rules could be derived for other function classes beyond the compositional case.
- If real data deviate from strict hierarchical composition, the same networks may require additional regularization or different width scaling to retain consistency.
- The sublinear condition could be tested directly on non-image domains to see whether the consistency result generalizes or remains domain-specific.
Load-bearing premise
The target functions are hierarchically compositional and the data domain (such as images) possesses this structure.
What would settle it
A demonstration that a sublinearly structured network fails to recover the correct features of a known hierarchically compositional function once sample size exceeds a fixed multiple of the network width would refute the consistency claim.
Figures



read the original abstract
Over the past decade, deep neural networks (DNNs) have achieved remarkable success on complex machine-learning tasks, yet the theoretical foundations of their performance remain incomplete. From a statistical viewpoint, a natural question is: can DNNs attain feature-learning and prediction consistency comparable to that of classical models? While a full characterization is open, we provide positive results for a broad subclass. We establish feature-learning consistency guarantees for sublinearly structured DNNs-architectures whose input/output dimensions and number of hidden neurons grow sublinearly with the sample size-when learning hierarchically compositional target functions. Importantly, this consistency still holds even in the conventional "over-parameterized" regime where the total number of parameters exceeds the number of training samples. Empirically, sublinearly structured DNNs match or surpass wide DNNs in prediction. A structural audit further indicates that widely used convolutional neural networks (CNNs), including AlexNet, VGGNet, ResNet, GoogLeNet, are sublinearly structured on their image classification benchmarks. We further prove that the sublinearly structured DNNs achieve universal approximation for hierarchically compositional functions in the large-sample limit. Moreover, images exhibit an inherent hierarchical, compositional structure. Taken together, these results explain, through a statistical lens, why many large-scale deep learning models succeed after adequate training on massive image datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sublinearly structured DNNs—defined by input/output dimensions and number of hidden neurons growing sublinearly with sample size n—achieve feature-learning consistency for hierarchically compositional target functions, even in the overparameterized regime where total parameters exceed n. It further claims that standard CNNs (AlexNet, VGGNet, ResNet, GoogLeNet) satisfy this sublinear structure on image benchmarks, that such DNNs achieve universal approximation for these functions in the large-sample limit, and that images possess an inherent hierarchical compositional structure, thereby explaining the success of large-scale DNNs on image data.
Significance. If the consistency and approximation results hold with rigorous proofs, the work would provide a statistical explanation for why overparameterized DNNs succeed on compositional tasks such as image classification, by tying architectural scaling constraints to consistency guarantees. The empirical matching of sublinear DNNs to wide DNNs and the structural audit of existing CNNs add practical relevance, though the strength depends on whether the sublinear condition is shown to be non-vacuous.
major comments (2)
- [Abstract / §3 (definition of sublinear structure)] The central consistency claim in the abstract conditions on hierarchically compositional targets and sublinear growth (input/output dims and hidden neurons = o(n)) while allowing total parameters > n. Without the explicit definition of sublinear structure and the derivation (likely in §3 or §4), it is impossible to verify whether the sublinear condition is load-bearing or reduces by construction to a regime where consistency is already known; this must be checked against the full proofs.
- [Theorem on universal approximation (likely §5)] The universal approximation result for hierarchically compositional functions in the large-sample limit is stated as a supporting theorem. The manuscript must show that this approximation rate is compatible with the sublinear growth rates used for the consistency guarantee, or the two results risk being disconnected.
minor comments (2)
- [Abstract] The abstract refers to 'a structural audit' of CNNs but does not specify the quantitative criteria (e.g., growth rates of channels or kernel sizes relative to n) used to classify architectures as sublinearly structured.
- [Empirical section] Empirical claims that sublinear DNNs 'match or surpass wide DNNs' require details on the exact architectures, datasets, and statistical significance tests to be reproducible.
Simulated Author's Rebuttal
We thank the referee for their careful review and for highlighting the need for clarity on the sublinear structure definition and result compatibility. We address each major comment below with direct references to the manuscript sections.
read point-by-point responses
-
Referee: [Abstract / §3 (definition of sublinear structure)] The central consistency claim in the abstract conditions on hierarchically compositional targets and sublinear growth (input/output dims and hidden neurons = o(n)) while allowing total parameters > n. Without the explicit definition of sublinear structure and the derivation (likely in §3 or §4), it is impossible to verify whether the sublinear condition is load-bearing or reduces by construction to a regime where consistency is already known; this must be checked against the full proofs.
Authors: Section 3 explicitly defines a sublinearly structured DNN by requiring that the input dimension, output dimension, and per-layer hidden neuron count (width) each satisfy o(n) as n → ∞. The total parameter count is permitted to exceed n because it is the sum across layers; the depth can be chosen such that the aggregate exceeds n while each individual dimension remains sublinear. The consistency proof in Section 4 invokes this per-dimension sublinearity to control covering numbers and Rademacher complexity terms under the hierarchical compositional assumption; the argument does not hold if the widths are permitted to grow linearly or faster. This regime is therefore distinct from standard bounded-width or linear-width analyses. We will add a short clarifying paragraph in Section 3 that contrasts the condition with prior regimes to make the load-bearing role transparent. revision: partial
-
Referee: [Theorem on universal approximation (likely §5)] The universal approximation result for hierarchically compositional functions in the large-sample limit is stated as a supporting theorem. The manuscript must show that this approximation rate is compatible with the sublinear growth rates used for the consistency guarantee, or the two results risk being disconnected.
Authors: The universal approximation theorem (Section 5) derives an error bound whose leading terms are multiples of the sublinear quantities (input dimension / n, width / n, etc.). Under the o(n) growth rates these terms vanish as n → ∞, so the approximation error tends to zero at a rate compatible with the consistency statement. The proof explicitly substitutes the same growth conditions used in Section 4. To eliminate any appearance of disconnection we will insert a cross-reference sentence at the end of both theorems stating that the approximation rate is controlled by the identical sublinear constraints that guarantee consistency. revision: yes
Circularity Check
No significant circularity; claims are conditional on explicit structural assumptions
full rationale
The abstract states consistency guarantees for sublinearly structured DNNs on hierarchically compositional targets, with sublinear growth (input/output dims and hidden neurons = o(n)) as the enabling condition even when total parameters > n. No equations, derivations, or self-citations appear in the provided text that would reduce any prediction or uniqueness claim to a fitted input or prior self-result by construction. The result is scoped explicitly to the stated function class and architecture constraints rather than derived tautologically from data fits or internal definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Target functions are hierarchically compositional
- domain assumption Images exhibit inherent hierarchical compositional structure
invented entities (1)
-
sublinearly structured DNNs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mathematics , year=
Universal Function Approximation by Deep Neural Nets with Bounded Width and ReLU Activations , author=. Mathematics , year=
-
[2]
Davis, Chandler and Kahan, W. M. , title =. SIAM Journal on Numerical Analysis , volume =. 1970 , doi =
1970
-
[3]
and Johnson, Charles R
Horn, Roger A. and Johnson, Charles R. , title =
-
[4]
International Journal of Automation and Computing , year =
Poggio, Tomaso and Mhaskar, Hrushikesh and Rosasco, Lorenzo and Miranda, Brando and Liao, Qianli , title =. International Journal of Automation and Computing , year =
-
[5]
ArXiv , year=
Approximating Continuous Functions by ReLU Nets of Minimal Width , author=. ArXiv , year=
-
[6]
Statistica Sinica , volume=
Uncertainty Quantification for Large-Scale Deep Neural Networks via Post-StoNet Modeling , author=. Statistica Sinica , volume=
-
[7]
Montanelli, Hadrien and Du, Qiang , title =. SIAM J. Math. Data Sci. , volume=
-
[8]
2013 , Publisher=
Matrix Computations (4th Edition) , author=. 2013 , Publisher=
2013
-
[9]
2007 , publisher=
Linear Models in Statistics (2nd Edition) , author=. 2007 , publisher=
2007
-
[10]
ArXiv , year=
Neural Networks can Learn Representations with Gradient Descent , author=. ArXiv , year=
-
[11]
Acta Numerica , year=
Deep learning: a statistical viewpoint , author=. Acta Numerica , year=
-
[12]
2019 , url=
Yi Zhou and Junjie Yang and Huishuai Zhang and Yingbin Liang and Vahid Tarokh , journal=. 2019 , url=
2019
-
[13]
Applied Statistics , year=
On using Principal Components before Separating a Mixture of Two Multivariate Normal Distributions , author=. Applied Statistics , year=
-
[14]
, title =
Zenger, C. , title =. Parallel Algorithms for Partial Differential Equations: Proceedings of the Sixth GAMM. 1991 , isbn =
1991
-
[15]
ICLR 2018 , year=
Measuring the Intrinsic Dimension of Objective Landscapes , author=. ICLR 2018 , year=
2018
-
[16]
ArXiv , year=
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , author=. ArXiv , year=
-
[17]
ICLR 2022 , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. ICLR 2022 , year=
2022
-
[18]
NeurIPS 2023 , year=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. NeurIPS 2023 , year=
2023
-
[19]
ArXiv , year=
Convergence Rates for Multi-classs Logistic Regression Near Minimum , author=. ArXiv , year=
-
[20]
Kakade , booktitle=
Difan Zou and Jingfeng Wu and Vladimir Braverman and Quanquan Gu and Dean Phillips Foster and Sham M. Kakade , booktitle=. The Benefits of Implicit Regularization from. 2021 , url=
2021
-
[21]
2018 Information Theory and Applications Workshop (ITA) , year=
Implicit Regularization in Deep Matrix Factorization , author=. 2018 Information Theory and Applications Workshop (ITA) , year=
2018
-
[22]
The Optimal Ridge Penalty for Real-world High-dimensional Data Can Be Zero or Negative due to the Implicit Ridge Regularization , author=. J. Mach. Learn. Res. , year=
-
[23]
ArXiv , year=
Characterizing Implicit Bias in Terms of Optimization Geometry , author=. ArXiv , year=
-
[24]
2020 , url=
The Transformer Model in Equations , author=. 2020 , url=
2020
-
[25]
2015 IEEE International Conference on Computer Vision (ICCV) , year=
Deep Learning Face Attributes in the Wild , author=. 2015 IEEE International Conference on Computer Vision (ICCV) , year=
2015
-
[26]
Communications of the ACM , year=
ImageNet classification with deep convolutional neural networks , author=. Communications of the ACM , year=
-
[27]
CoRR , year=
Very Deep Convolutional Networks for Large-Scale Image Recognition , author=. CoRR , year=
-
[28]
Szegedy and Wei Liu and Yangqing Jia and P
C. Szegedy and Wei Liu and Yangqing Jia and P. Sermanet and S. Reed and D. Anguelov and D. Erhan and V. Vanhoucke and A. Rabinovich , booktitle =. Going deeper with convolutions , year =
-
[29]
Statistical Inference for Deep Learning via Stochastic Modeling , author=. , year=
-
[30]
ICLR , year=
Causal-StoNet: Causal Inference for High-Dimensional Complex Data , author=. ICLR , year=
-
[31]
Nonparametric regression using deep neural networks with ReLU activation function , author=. , year=
-
[32]
ArXiv , year=
Minimum Width for Universal Approximation , author=. ArXiv , year=
-
[33]
Minimum width for universal approximation using
Namjun Kim and Chanho Min and Sejun Park , journal=. Minimum width for universal approximation using. 2023 , volume=
2023
-
[34]
Proceedings of Machine Learning Research , year=
Universal Approximation with Deep Narrow Networks , author=. Proceedings of Machine Learning Research , year=
-
[35]
Annual Conference Computational Learning Theory , year=
The implicit bias of gradient descent on nonseparable data , author=. Annual Conference Computational Learning Theory , year=
-
[36]
The Implicit Bias of Gradient Descent on Separable Data , author=. J. Mach. Learn. Res. , year=
-
[37]
ArXiv , year=
A Theoretical Analysis on Feature Learning in Neural Networks: Emergence from Inputs and Advantage over Fixed Features , author=. ArXiv , year=
-
[38]
ArXiv , year=
Deep Learning Scaling is Predictable, Empirically , author=. ArXiv , year=
-
[39]
ArXiv , year=
Scaling Laws for Neural Language Models , author=. ArXiv , year=
-
[40]
International Conference on Machine Learning , year=
Tensor Programs IV: Feature Learning in Infinite-Width Neural Networks , author=. International Conference on Machine Learning , year=
-
[41]
Kernel and Rich Regimes in Overparametrized Models , author=. , year=
-
[42]
2022 , journal=
Mechanism of feature learning in deep fully connected networks and kernel machines that recursively learn features , author=. 2022 , journal=
2022
-
[43]
2024 , journal=
Mechanism for feature learning in neural networks and backpropagation-free machine learning models , author=. 2024 , journal=
2024
-
[44]
Russel Merris , title=
-
[45]
ArXiv , year=
Propagating Uncertainty through the tanh Function with Application to Reservoir Computing , author=. ArXiv , year=
-
[46]
arXiv: Machine Learning , year=
Semi-analytical approximations to statistical moments of sigmoid and softmax mappings of normal variables , author=. arXiv: Machine Learning , year=
-
[47]
IEEE Transactions on Neural Networks and Learning Systems , year=
Singular Values for ReLU Layers , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[48]
Linear Algebra and its Applications , year=
Modifying the inertia of matrices arising in optimization , author=. Linear Algebra and its Applications , year=
-
[49]
Finite-sample analysis of interpolating linear classifiers in the overparameterized regime , author=. , year=
-
[50]
NeurIPS , year=
Overfitting or perfect fitting? Risk bounds for classification and regression rules that interpolate , author=. NeurIPS , year=
-
[51]
Lyons , editor =
Patrick Kidger and Terry J. Lyons , editor =. Universal Approximation with Deep Narrow Networks , booktitle =. 2020 , url =
2020
-
[52]
Annals of the Institute of Statistical Mathematics , year=
Multinomial logistic regression algorithm , author=. Annals of the Institute of Statistical Mathematics , year=
-
[53]
Mathematics of Computation , year=
A formula for the approximation of definite integrals of the normal distribution function , author=. Mathematics of Computation , year=
-
[54]
Communications in Statistics - Theory and Methods , year=
New approximations for standard normal distribution function , author=. Communications in Statistics - Theory and Methods , year=
-
[55]
Shafer, Glenn and Vovk, Vladimir , title =. J. Mach. Learn. Res. , month =. 2008 , volume =
2008
-
[56]
Journal of Machine Learning Research , year=
A tutorial on conformal prediction , author=. Journal of Machine Learning Research , year=
-
[57]
2005 , publisher=
Algorithmic Learning in a Random World , author=. 2005 , publisher=
2005
-
[58]
Journal of Machine Learning Research , year=
Nonparametric sparsity and regularization , author=. Journal of Machine Learning Research , year=
-
[59]
Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
Learning Sparse Nonparametric DAGs , author=. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[60]
NeurIPS , year=
A Universal Approximation Theorem of Deep Neural Networks for Expressing Probability Distributions , author=. NeurIPS , year=
-
[61]
, author=
Greedy function approximation: A gradient boosting machine. , author=. Annals of Statistics , year=
-
[62]
Machine Learning , year=
Random Forests , author=. Machine Learning , year=
-
[63]
Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year=
XGBoost: A Scalable Tree Boosting System , author=. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year=
-
[64]
Proceedings of the National Academy of Sciences , year=
Reconciling modern machine-learning practice and the classical bias–variance trade-off , author=. Proceedings of the National Academy of Sciences , year=
-
[65]
ArXiv , year=
Double Descent Demystified: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle , author=. ArXiv , year=
-
[66]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Densely connected convolutional networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[67]
NeurIPS , year=
Understanding Double Descent Requires a Fine-Grained Bias-Variance Decomposition , author=. NeurIPS , year=
-
[68]
Krizhevsky, Alex , biburl =
-
[69]
NeurIPS , year=
On the linearity of large non-linear models: when and why the tangent kernel is constant , author=. NeurIPS , year=
-
[70]
NeurIPS , year=
Sparse Deep Learning for Time Series Data: Theory and Applications , author=. NeurIPS , year=
-
[71]
Benign overfitting in ridge regression , author=. J. Mach. Learn. Res. , year=
-
[72]
AISTATS , year=
Tight bounds for minimum l1-norm interpolation of noisy data , author=. AISTATS , year=
-
[73]
Proceedings of the National Academy of Sciences of the United States of America , year=
Unsupervised learning by competing hidden units , author=. Proceedings of the National Academy of Sciences of the United States of America , year=
-
[74]
Journal of the Royal Statistical Society Series B , volume=
A kernel-expanded stochastic neural network , author=. Journal of the Royal Statistical Society Series B , volume=. 2022 , publisher=
2022
-
[75]
NeurIPS , year =
Siqi Liang and Yan Sun and Faming Liang , title =. NeurIPS , year =
-
[76]
Journal of Machine Learning Research , volume=
Regularized M-estimators with nonconvexity: Statistical and algorithmic theory for local optima , author=. Journal of Machine Learning Research , volume=. 2015 , publisher=
2015
-
[77]
The Annals of Statistics , volume=
Support recovery without incoherence: A case for nonconvex regularization , author=. The Annals of Statistics , volume=. 2017 , publisher=
2017
-
[78]
IEEE transactions on information theory , volume=
Sharp thresholds for High-Dimensional and noisy sparsity recovery using _1 -Constrained Quadratic Programming (Lasso) , author=. IEEE transactions on information theory , volume=. 2009 , publisher=
2009
-
[79]
LoRA: Low-rank adaptation of large language models , author=. arXiv:2106.09685v2 , year=
-
[80]
QLoRA: Efficient Finetuning of Quantized LLMs , author=. arXiv:2305.14314v1 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.