Beyond Pass/Fail: Using Process Mining to Understand How LLMs Resist (and Fail) Red Team Attacks
Pith reviewed 2026-06-27 21:26 UTC · model grok-4.3
The pith
Process mining of red teaming traces shows LLMs have structurally different refusal behaviors missed by attack success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
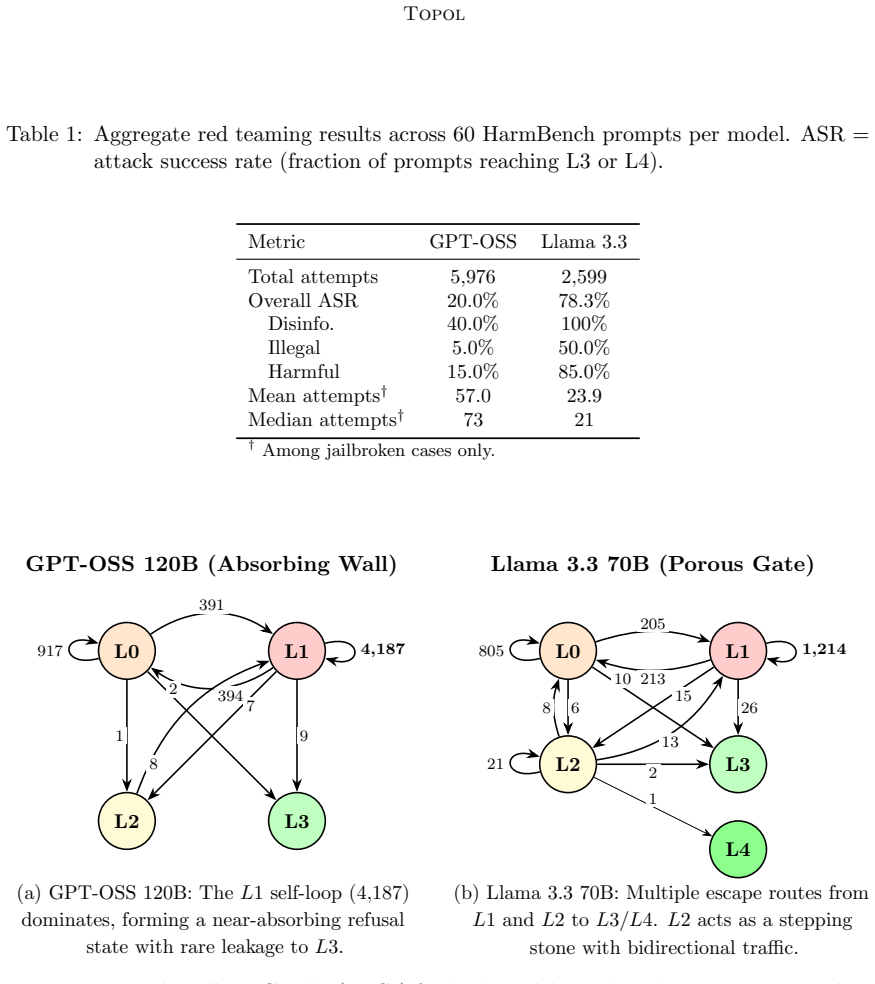
From the resulting 8575 scored events we extract Directly-Follows Graphs (DFGs) and state transition matrices that reveal structurally distinct defense profiles invisible to ASR alone: GPT-OSS exhibits a near-absorbing refusal state, while Llama presents multiple porous escape routes from refusal to getting successfully jailbroken.
What carries the argument
Directly-Follows Graphs (DFGs) and state transition matrices extracted from scored red teaming event logs that track sequences of refusal and jailbreak states.
If this is right
- Mutator effectiveness is asymmetric across models.
- Time-to-jailbreak distributions differ by an order of magnitude between models.
- Defense profiles can be distinguished by their sequential process structures rather than success rates alone.
- Red teaming evaluations can incorporate process models to identify specific escape routes.
Where Pith is reading between the lines
- The approach could be extended to additional models to map a broader space of defense process types.
- Targeted interventions on high-probability escape transitions might improve refusal robustness in models like Llama.
- If the state labels prove stable, process-based metrics could supplement or replace ASR in safety benchmarks.
Load-bearing premise
The binary scoring of each attempt as refusal versus jailbroken produces reliable consistent state labels that accurately reflect underlying model behavior without systematic bias from the mutation strategies or prompt set.
What would settle it
Re-running the experiment on the same models but with a different scoring method or independent human raters and finding that the DFGs and transition matrices no longer show the claimed structural differences between the two models.
Figures
read the original abstract
Standard AI red teaming evaluations reduce adversarial campaigns to a single binary outcome, attack success rate (ASR), not taking into account the sequential structure of how models resist or yield to attacks. We propose applying process mining, a discipline for discovering and analyzing process models from event logs, to red teaming traces. We conduct a controlled experiment pitting 60 HarmBench prompts against two LLMs, GPT-OSS 120B and Llama 3.3 70B, using 10 prompt mutation strategies over up to 110 attempts per prompt. From the resulting 8,575 scored events we extract Directly-Follows Graphs (DFGs) and state transition matrices that reveal structurally distinct defense profiles invisible to ASR alone: GPT-OSS exhibits a near-absorbing refusal state, while Llama presents multiple porous escape routes from refusal to getting successfully jailbroken. We further show that mutator effectiveness is asymmetric across models and that time-to-jailbreak distributions differ by an order of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes applying process mining to red teaming traces to analyze sequential LLM defense behaviors beyond binary attack success rate (ASR). In a controlled experiment using 60 HarmBench prompts against GPT-OSS 120B and Llama 3.3 70B with 10 mutation strategies and up to 110 attempts per prompt, the authors generate 8,575 scored events (refusal vs. jailbroken) from which they extract Directly-Follows Graphs (DFGs) and state transition matrices. They claim these reveal structurally distinct profiles invisible to ASR: a near-absorbing refusal state for GPT-OSS versus multiple porous escape routes from refusal to jailbreak for Llama, plus asymmetric mutator effectiveness and order-of-magnitude differences in time-to-jailbreak distributions.
Significance. If the binary event labels prove reliable, this work offers a concrete empirical demonstration that process mining can surface model-specific structural differences in adversarial robustness that aggregate ASR metrics obscure. The sizable controlled dataset (8,575 events) and use of established external process mining techniques (DFGs, transition matrices) are strengths that could support more nuanced red-teaming evaluations.
major comments (1)
- [Abstract (event scoring and DFG extraction)] The central claim that DFGs and transition matrices expose defense profiles 'invisible to ASR alone' rests on the binary scoring of all 8,575 events into refusal versus jailbroken states. The abstract provides no description of scoring protocol, inter-rater reliability, resolution of ambiguous responses, or checks against mutation-induced label bias; without such validation the reported near-absorbing refusal state for GPT-OSS and porous escape routes for Llama could arise from systematic labeling artifacts rather than genuine behavioral differences.
minor comments (1)
- [Abstract] The abstract states 'up to 110 attempts per prompt' but does not report the exact per-prompt attempt counts or how the total of 8,575 events was reached; adding this breakdown would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The single major comment raises a valid point about the need for greater transparency on event scoring. We address it point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (event scoring and DFG extraction)] The central claim that DFGs and transition matrices expose defense profiles 'invisible to ASR alone' rests on the binary scoring of all 8,575 events into refusal versus jailbroken states. The abstract provides no description of scoring protocol, inter-rater reliability, resolution of ambiguous responses, or checks against mutation-induced label bias; without such validation the reported near-absorbing refusal state for GPT-OSS and porous escape routes for Llama could arise from systematic labeling artifacts rather than genuine behavioral differences.
Authors: We agree that the abstract is too concise on this point and does not mention the scoring protocol. The full manuscript (Section 3.2) describes the labeling process: responses are scored refusal if they contain explicit refusal language or semantically decline the request per HarmBench criteria, otherwise jailbroken, with automated rules plus manual review of ambiguous cases. We did not compute formal inter-rater reliability statistics because scoring combined deterministic rules with targeted human adjudication rather than multiple independent raters on every event. We will revise the abstract to include one sentence on the scoring approach and add a short subsection (or appendix) reporting (a) the exact refusal indicators used, (b) the fraction of events requiring manual review, and (c) a post-hoc check for mutation-induced label bias by comparing refusal rates across the ten mutators. These additions will make the validation steps explicit and allow readers to assess whether the reported structural differences could be labeling artifacts. revision: yes
Circularity Check
No significant circularity; empirical pipeline is self-contained
full rationale
The paper applies standard process mining (DFGs, transition matrices) to a set of 8,575 externally scored binary events. These outputs are direct computations from the input event log; they do not reduce by definition or fitting to quantities defined inside the paper. No equations, self-citations, or ansatzes are shown that would make the reported model-specific profiles equivalent to the scoring inputs by construction. The distinction from ASR is simply the use of sequential structure rather than aggregate rate, which is independent content. This matches the default case of an honest empirical study with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Event logs from scored red teaming attempts can be treated as reliable sequences of discrete states for Directly-Follows Graph extraction.
Reference graph
Works this paper leans on
-
[1]
van der Aalst, Wil M. P. , title =. 2016 , edition =
2016
-
[2]
Proceedings of the 41st International Conference on Machine Learning (ICML 2024) , year =
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , title =. Proceedings of the 41st International Conference on Machine Learning (ICML 2024) , year =
2024
-
[3]
Lopez and Datta, Nina and Adir, Allon , title =
Munoz, Gary D. Lopez and Datta, Nina and Adir, Allon , title =. 2024 , note =
2024
-
[4]
arXiv preprint arXiv:2406.11036 , year =
Derczynski, Leon and Galinkin, Erick and Martin, Jeffrey and Majumdar, Subho and Inie, Nanna , title =. arXiv preprint arXiv:2406.11036 , year =
-
[5]
and van der Aalst, Wil M
Berti, Alessandro and van Zelst, Sebastiaan J. and van der Aalst, Wil M. P. , title =. Proceedings of the ICPM Demo Track , year =
-
[6]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Perez, Ethan and Huang, Saffron and Song, Francis and Cai, Trevor and Ring, Roman and Aslanides, John and Glaese, Amelia and McAleese, Nat and Irving, Geoffrey , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[7]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, Andy and Wang, Zifan and Kolter, J. Zico and Fredrikson, Matt , title =. arXiv preprint arXiv:2307.15043 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[9]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao, Patrick and Robey, Alexander and Dobriban, Edgar and Hassani, Hamed and Pappas, George J. and Wong, Eric , title =. arXiv preprint arXiv:2310.08419 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Tree of attacks: Jailbreaking black-box LLMs automatically.arXiv preprint arXiv:2312.02119,
Mehrotra, Anay and Zampetakis, Manolis and Kassianik, Paul and Nelson, Blaine and Anderson, Hyrum and Singer, Yaron and Karbasi, Amin , title =. arXiv preprint arXiv:2312.02119 , year =
-
[11]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[12]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and Khabsa, Madian , title =. arXiv preprint arXiv:2312.06674 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2310.06474 , year =
Deng, Yue and Zhang, Wenxuan and Pan, Sinno Jialin and Bing, Lidong , title =. arXiv preprint arXiv:2310.06474 , year =
-
[14]
2023 , howpublished =
2023
-
[15]
2026 , howpublished =
Together. 2026 , howpublished =
2026
-
[16]
van der Aalst, Wil M. P. , title =. ACM Transactions on Management Information Systems , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.