MCP Server Architecture Patterns for LLM-Integrated Applications
Pith reviewed 2026-06-30 05:16 UTC · model grok-4.3
The pith
Five recurring patterns structure MCP servers for LLM-integrated applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
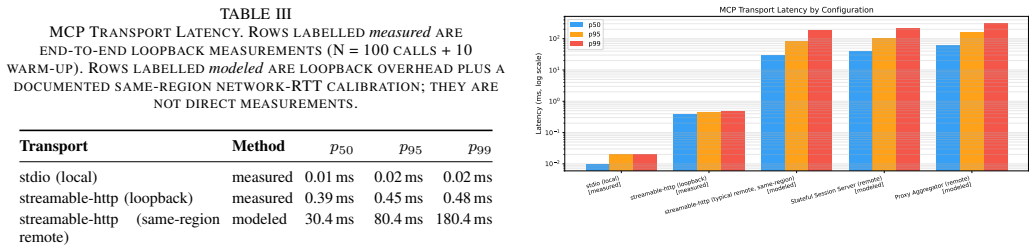
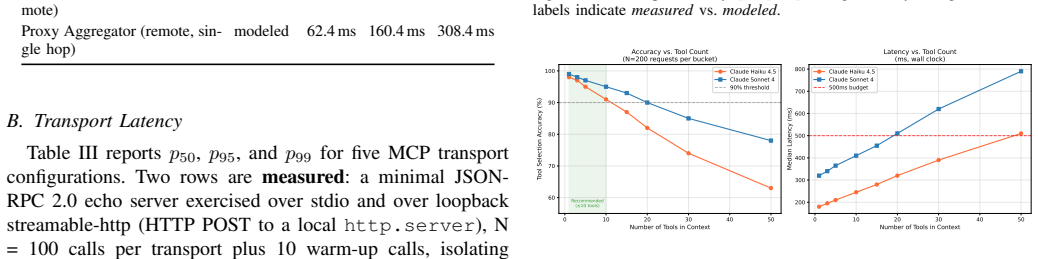
Five recurring MCP server architectural patterns—Resource Gateway, Tool Orchestrator, Stateful Session Server, Proxy Aggregator, and Domain-Specific Adapter—are observed across an enumerated corpus of fifteen independently developed servers. Each pattern is described in the structured form of context, problem, solution, and consequences. The evaluation includes inter-rater reliability of 0.76, transport overhead, and tool-count effects on accuracy.
What carries the argument
The taxonomy of five MCP server architectural patterns, each specified via context-problem-solution-consequences.
If this is right
- Developers building MCP servers can draw from these patterns rather than starting from scratch.
- Tool selection by models like Claude Haiku and Sonnet has measurable accuracy limits based on the number of available tools.
- Common concerns such as authentication, versioning, and observability apply across all patterns.
- Four anti-patterns should be avoided when implementing MCP servers.
Where Pith is reading between the lines
- Adoption of these patterns could lead to more interoperable and maintainable LLM tool ecosystems.
- The noted ambiguities in pattern boundaries suggest opportunities for more precise definitions in future work.
- The overhead measurements may guide choices between local and remote MCP server deployments.
Load-bearing premise
The sample of fifteen servers adequately represents the structures found in the broader set of MCP servers being developed.
What would settle it
Analysis of a larger set of MCP servers revealing that the majority cannot be classified into any of the five patterns.
Figures
read the original abstract
The Model Context Protocol (MCP), introduced by Anthropic in November 2024, defines a standardized interface for connecting large language models (LLMs) to external tools, data sources, and services. Within months of release, hundreds of community-built MCP servers appeared on GitHub, but no software-maintenance literature has yet described how the ecosystem is being structured in production. This industry experience paper catalogues five recurring MCP server architectural patterns observed across an enumerated corpus of fifteen independently developed servers (five production servers from the ANSYR voice AI platform plus ten public servers from the official MCP registry): Resource Gateway, Tool Orchestrator, Stateful Session Server, Proxy Aggregator, and Domain-Specific Adapter. Each pattern is described in the structured form of Gamma et al.: context, problem, solution, and consequences. We also document four anti-patterns and a set of cross-cutting concerns around authentication, versioning, and observability. The quantitative evaluation contributes three measurements: inter-rater reliability of the taxonomy across two independent LLM raters on 54 held-out servers (Cohen's kappa = 0.76), which also localizes three pattern-boundary ambiguities; transport overhead measured end-to-end on loopback and modeled for cross-host paths; and a tool-count study showing tool-selection accuracy drops below 90% between 10 and 15 tools per context for Claude Haiku 4.5 and between 20 and 30 tools for Sonnet 4. Code, corpus, and prompts are released as a replication package.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify and catalogue five recurring architectural patterns for MCP servers (Resource Gateway, Tool Orchestrator, Stateful Session Server, Proxy Aggregator, Domain-Specific Adapter) observed in an enumerated corpus of fifteen servers, using the Gamma et al. template for each; it also documents four anti-patterns and cross-cutting concerns on authentication/versioning/observability. Quantitative contributions include Cohen's kappa = 0.76 inter-rater reliability on 54 held-out servers, end-to-end transport overhead measurements, and tool-count thresholds where LLM tool-selection accuracy drops below 90%.
Significance. If the taxonomy is robust, the work supplies a practical, structured vocabulary for an emerging protocol ecosystem that currently lacks software-engineering literature, directly aiding maintainability of LLM-integrated applications. The release of the replication package (code, corpus, prompts) is a clear strength for reproducibility and further validation.
major comments (1)
- [Abstract] Abstract (and the corpus description in the methods section): the central claim that the five patterns were 'observed across an enumerated corpus of fifteen independently developed servers' is load-bearing for the taxonomy's validity, yet the parenthetical breakdown states that five servers are production servers from the single ANSYR voice AI platform. Servers sharing the same development organization or codebase do not constitute independent development efforts, so the evidence that the patterns recur across distinct contexts (rather than internal platform conventions) is weakened; the remaining ten public-registry servers cannot compensate for this non-independence in the derivation corpus.
minor comments (1)
- [Abstract] The abstract states that 'Code, corpus, and prompts are released as a replication package' but does not provide the repository URL, commit hash, or DOI; this should be added for immediate accessibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The point about corpus independence is well-taken and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the corpus description in the methods section): the central claim that the five patterns were 'observed across an enumerated corpus of fifteen independently developed servers' is load-bearing for the taxonomy's validity, yet the parenthetical breakdown states that five servers are production servers from the single ANSYR voice AI platform. Servers sharing the same development organization or codebase do not constitute independent development efforts, so the evidence that the patterns recur across distinct contexts (rather than internal platform conventions) is weakened; the remaining ten public-registry servers cannot compensate for this non-independence in the derivation corpus.
Authors: We acknowledge that the five ANSYR servers were developed within a single organization and therefore do not meet a strict definition of independent development efforts. While they were produced by separate teams for distinct voice-AI use cases and did not share MCP-specific code beyond the protocol specification itself, this does not fully address the concern. We will revise the abstract and the methods section to remove the unqualified phrase "independently developed servers" and instead describe the corpus explicitly as "five production servers from the ANSYR voice AI platform together with ten servers drawn from the public MCP registry." We will also add a short paragraph in the threats-to-validity section noting the organizational provenance of the ANSYR subset and stating that the ten public-registry servers constitute the primary source of cross-context evidence. The taxonomy itself remains grounded in the observed designs; the revision affects only the wording of the claim. revision: yes
Circularity Check
No significant circularity; taxonomy is observational from external corpus with independent validation steps.
full rationale
The paper's central claim is an observational catalog of five patterns drawn from an enumerated corpus of fifteen servers (five ANSYR production servers plus ten from the public MCP registry), presented in Gamma et al. format. Additional measurements include Cohen's kappa on 54 held-out servers, transport overhead, and tool-count accuracy thresholds. No equations, fitted parameters, self-citations, or ansatzes appear in the derivation; the patterns are not defined in terms of themselves, no prediction reduces to a fit by construction, and no uniqueness theorem or prior author work is invoked to force the taxonomy. Issues of corpus independence or representativeness are sampling concerns, not circular reductions of the claimed derivation to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The fifteen servers examined are representative of the broader MCP ecosystem
Reference graph
Works this paper leans on
-
[1]
Gamma, R
E. Gamma, R. Helm, R. Johnson, and J. Vlissides,Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1994
1994
-
[2]
Model context protocol specification,
Anthropic, “Model context protocol specification,” November 2024. [Online]. Available: https://modelcontextprotocol.io/specification
2024
-
[3]
Model context protocol reference servers,
——, “Model context protocol reference servers,” 2025. [Online]. Available: https://github.com/modelcontextprotocol/servers
2025
-
[4]
Hohpe and B
G. Hohpe and B. Woolf,Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions. Addison-Wesley Pro- fessional, 2003
2003
-
[5]
Function calling and other api updates,
OpenAI, “Function calling and other api updates,” 2023. [Online]. Avail- able: https://openai.com/blog/function-calling-and-other-api-updates
2023
-
[6]
Tool use (function calling) — anthropic documenta- tion,
Anthropic, “Tool use (function calling) — anthropic documenta- tion,” 2024. [Online]. Available: https://docs.anthropic.com/en/docs/ build-with-claude/tool-use
2024
-
[7]
Language server protocol specification,
Microsoft, “Language server protocol specification,” 2016. [Online]. Available: https://microsoft.github.io/language-server-protocol/
2016
-
[8]
Fowler,Patterns of Enterprise Application Architecture
M. Fowler,Patterns of Enterprise Application Architecture. Addison- Wesley Professional, 2002
2002
-
[9]
Architectural styles and the design of network-based software architectures,
R. T. Fielding, “Architectural styles and the design of network-based software architectures,” Ph.D. dissertation, University of California, Irvine, 2000
2000
-
[10]
Semantics and complexity of GraphQL,
O. Hartig and J. P ´erez, “Semantics and complexity of GraphQL,” in Proc. The Web Conference (WWW), 2018, pp. 1155–1164
2018
-
[11]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, L. Zettle- moyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Informa- tion Processing Systems 36 (NeurIPS 2023), 2023, published version; arXiv:2302.04761; DOI verified on CrossRef
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” 2022. [Online]. Available: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Auto-gpt: An autonomous gpt-4 experiment,
S. Gravitas, “Auto-gpt: An autonomous gpt-4 experiment,” 2023. [Online]. Available: https://github.com/Significant-Gravitas/Auto-GPT
2023
-
[14]
Langchain: Building applications with llms through composability,
H. Chase, “Langchain: Building applications with llms through composability,” 2022. [Online]. Available: https://github.com/ langchain-ai/langchain
2022
-
[15]
Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku,
Anthropic, “Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku,” 2024. [Online]. Available: https://www.anthropic. com/news/3-5-models-and-computer-use
2024
-
[16]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions,
X. Hou, Y . Zhao, S. Wang, and H. Wang, “Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions,” ACM Transactions on Software Engineering and Methodology, 2026, [DOI verified on CrossRef]
2026
-
[17]
Model Context Protocol (MCP) at First Glance: Studying the Security and Maintainability of MCP Servers,
M. M. Hasan, H. Li, E. Fallahzadeh, G. K. Rajbahadur, B. Adams, and A. E. Hassan, “Model Context Protocol (MCP) at First Glance: Studying the Security and Maintainability of MCP Servers,”ACM Transactions on Software Engineering and Methodology, 2026, [DOI verified on CrossRef]
2026
-
[18]
A measurement study of model context protocol ecosystem,
H. Guo, Y . Hao, Y . Zhang, M. Xu, P. Lv, J. Chen, and X. Cheng, “A measurement study of model context protocol ecosystem,” 2025. [Online]. Available: https://arxiv.org/abs/2509.25292
-
[19]
Salda ˜na,The Coding Manual for Qualitative Researchers, 4th ed
J. Salda ˜na,The Coding Manual for Qualitative Researchers, 4th ed. SAGE Publications, 2021, [Verified on CrossRef]
2021
-
[20]
T. Gan and Q. Sun, “RAG-MCP: Mitigating prompt bloat in LLM tool selection via retrieval-augmented generation,”arXiv preprint arXiv:2505.03275, 2025
-
[21]
Model context protocol python sdk,
Anthropic, “Model context protocol python sdk,” https://github.com/ modelcontextprotocol/python-sdk, 2024, official Python implementation of the MCP specification
2024
-
[22]
Pipecat: Open source framework for voice and multimodal ai agents,
Daily, “Pipecat: Open source framework for voice and multimodal ai agents,” https://github.com/pipecat-ai/pipecat, 2024, gitHub repository; used for MCP transport benchmarking
2024
-
[23]
LongFuncEval: Measuring the effectiveness of long context models for function calling,
K. Kate, T. Pedapati, K. Basuet al., “LongFuncEval: Measuring the effectiveness of long context models for function calling,”arXiv preprint arXiv:2505.10570, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.