MemDelta: Controlled Baselines and Hidden Confounds in Agent Memory Evaluation
Pith reviewed 2026-06-30 06:43 UTC · model grok-4.3
The pith
Controlled tests show that embedding model choice and base LLM often determine memory rankings more than the memory method.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
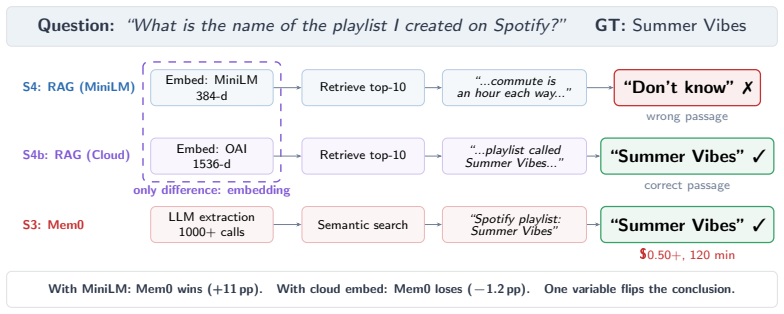
Applying the controlled MemDelta protocol on LongMemEval-S across three model families shows that verbatim RAG matches full-context GPT-4o-mini accuracy (47.2% vs 49.8%), that embedding swaps alone move accuracy by +6.2pp, that self-memory reaches only 42% against 47% for basic retrieval, and that on two of six question types a specialized system matches cloud RAG at fifty times the cost.
What carries the argument
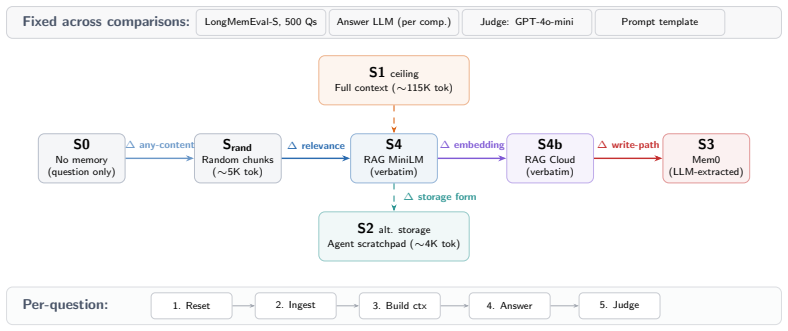
MemDelta, the evaluation protocol that holds all but one pipeline component fixed while measuring accuracy on 500 questions across 50+ sessions.
If this is right
- Verbatim RAG matches full-context performance for GPT-4o-mini but Gemini gains 14pp from full context while Sonnet gains 31pp from RAG.
- Swapping only the embedding model in an otherwise identical pipeline changes accuracy by +6.2pp at n=500.
- Agent self-memory reaches 42% while basic retrieval reaches 47%.
- On two of six question types, a specialized memory system matches cloud RAG at 50x the cost.
- Memory evaluations should fix embedding models, stratify by model family, and report write-path costs.
Where Pith is reading between the lines
- Standardizing the embedding model across all compared systems would isolate whether architectural differences actually drive gains.
- The model-family reversals imply that refusal rates in full-context settings are a hidden variable in many existing comparisons.
- Narrow parity on only two of six question types suggests that claims of general superiority require explicit stratification by query category.
- Requiring cost reporting alongside accuracy would make it harder to attribute small gains to expensive memory architectures.
Load-bearing premise
The LongMemEval-S benchmark and its question types are representative enough that single-variable isolations reveal general truths about memory system value.
What would settle it
A replication study on an independent 500-question benchmark in which memory systems still outperform fixed-embedding RAG baselines by large margins across multiple model families would falsify the central claim.
Figures
read the original abstract
Agent memory systems are increasingly evaluated against RAG and full-context baselines, but reported gains often mix changes in the memory method with changes in the language model, embedding model, or retrieval pipeline, making it unclear what is actually being measured. We present MemDelta, a controlled evaluation protocol that varies one component at a time on LongMemEval-S (500 questions, 50+ sessions, three model families). Four findings emerge: (1) verbatim RAG matches full-context GPT-4o-mini (47.2% vs. 49.8%, p = 0.34), but the ranking reverses across models: Gemini gains +14pp from full context, while Sonnet gains +31pp from RAG, partly because it refuses 63% of full-context queries; (2) swapping only the embedding model in an identical pipeline shifts accuracy by +6.2pp at n = 500 (p = 0.004), and Mem0 beats MiniLM-RAG by +11pp but loses to cloud-RAG by 1.2pp, so one variable flips the conclusion; (3) agent self-memory (42%) underperforms basic retrieval (47%); (4) on 2 of 6 question types (n = 88), Mem0 matches cloud RAG (72.7% vs. 73.9%, p = 1.0) at 50x the cost, suggesting narrow rather than general gains. We recommend memory evaluations fix embedding models across comparisons, stratify by model family, and report write-path cost before attributing gains to architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MemDelta, a controlled evaluation protocol for agent memory systems that varies one component at a time on the LongMemEval-S benchmark (500 questions, 50+ sessions, three model families). It reports four findings: (1) verbatim RAG matches full-context GPT-4o-mini (47.2% vs. 49.8%, p=0.34) but rankings reverse across models (e.g., Sonnet gains +31pp from RAG, partly due to 63% refusals on full context); (2) swapping only the embedding model shifts accuracy by +6.2pp (p=0.004), with Mem0 beating MiniLM-RAG by +11pp but losing to cloud-RAG by 1.2pp; (3) agent self-memory (42%) underperforms basic retrieval (47%); (4) on 2 of 6 question types (n=88), Mem0 matches cloud RAG (72.7% vs. 73.9%, p=1.0) at 50x cost. The authors recommend fixing embedding models, stratifying by model family, and reporting write-path costs.
Significance. If the controlled empirical results hold, the work is significant for exposing hidden confounds in agent memory evaluations, such as embedding model choice and model-family interactions that can reverse apparent gains from memory architectures. A key strength is the use of one-at-a-time variation with standard statistical tests on reported accuracies, providing clear, falsifiable demonstrations of evaluation pitfalls rather than parameter-fitted derivations.
major comments (2)
- [Benchmark and question types description] The central claim that controlled one-at-a-time variation on LongMemEval-S reveals general truths about memory system value and hidden confounds rests on the benchmark's representativeness. The manuscript provides no derivation or validation of the six question types against external agent logs or typical workloads (see the benchmark description), which is load-bearing for generalizing findings (2) and (4) beyond this specific set.
- [Results, finding (2)] Finding (2) reports a +6.2pp accuracy shift from embedding model swap alone (p=0.004 at n=500) as evidence of confounds. The methods must explicitly confirm that the retrieval pipeline, prompt, and all other variables were identical across the swap; without this detail, the isolation itself cannot be verified as confound-free.
minor comments (2)
- [Abstract] The abstract mentions six question types and specific refusal rates (e.g., 63%) but does not enumerate the types or provide exact counts/conditions; a table or list in the main text would improve clarity and replicability.
- A consolidated table summarizing all reported accuracies, p-values, sample sizes, and model comparisons across the four findings would aid quick assessment without requiring cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our claims and the transparency of our methods. We address each major comment below, agreeing where revisions are warranted and providing the strongest honest defense of the manuscript's contributions.
read point-by-point responses
-
Referee: [Benchmark and question types description] The central claim that controlled one-at-a-time variation on LongMemEval-S reveals general truths about memory system value and hidden confounds rests on the benchmark's representativeness. The manuscript provides no derivation or validation of the six question types against external agent logs or typical workloads (see the benchmark description), which is load-bearing for generalizing findings (2) and (4) beyond this specific set.
Authors: We acknowledge that the manuscript does not derive or externally validate the six question types in LongMemEval-S against real-world agent logs. The paper positions LongMemEval-S as an established benchmark and uses it to demonstrate that even within a fixed benchmark, single-variable changes can reverse conclusions about memory systems. We do not claim the specific numerical results generalize beyond this benchmark. To address the concern, we will add a limitations paragraph in the discussion explicitly qualifying the scope of findings (2) and (4) and noting the absence of external workload validation. revision: partial
-
Referee: [Results, finding (2)] Finding (2) reports a +6.2pp accuracy shift from embedding model swap alone (p=0.004 at n=500) as evidence of confounds. The methods must explicitly confirm that the retrieval pipeline, prompt, and all other variables were identical across the swap; without this detail, the isolation itself cannot be verified as confound-free.
Authors: The methods already describe performing an embedding-model swap while holding the rest of the pipeline fixed. To make this isolation fully verifiable, we will insert an explicit statement in the experimental setup confirming that retrieval pipeline, prompt templates, chunk size, top-k, and all other variables remained unchanged during the embedding-model comparisons. This matches the actual experimental design. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations
full rationale
The paper reports controlled empirical comparisons of memory systems on the LongMemEval-S benchmark, including accuracy percentages, p-values from statistical tests, and model-specific reversals. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. All findings (e.g., verbatim RAG matching full-context at 47.2% vs 49.8%, embedding swap effects) are direct measurements against external benchmarks and standard tests, with no reduction of claims to inputs by construction. The analysis is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Statistical tests with reported p-values correctly identify whether observed accuracy differences are due to chance.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2602.16313 , year=
He, Z., et al. MemoryArena: Benchmarking agent memory in interdependent multi-session agentic tasks.arXiv:2602.16313,
-
[2]
Pollertlam, N. and Kornsuwannawit, W. Beyond the context window: A cost-performance analysis of fact-based memory vs. long-context LLMs for persistent agents.arXiv:2603.04814,
-
[3]
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications
Zhao, Y ., et al. AMA-Bench: Evaluating long-horizon memory for agentic applications. arXiv:2602.22769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
MemGPT: Towards LLMs as Operating Systems
Packer, C., et al. MemGPT: Towards LLMs as operating systems.arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Memory in the Age of AI Agents
Hu, Y ., et al. Memory in the age of AI agents.arXiv:2512.13564,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Graphiti: Temporal knowledge graphs for LLM agents
Mem0: The memory layer for AI agents.https://mem0.ai, 2024–2026. Graphiti: Temporal knowledge graphs for LLM agents. Zep AI, https://github.com/getzep/ graphiti,
2024
-
[7]
MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems
Ai, Q., et al. MemoryBench: A benchmark for memory and continual learning in LLM systems. arXiv:2510.17281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Semantic Needles in Document Haystacks: Sensitivity Testing of LLM-as-a-Judge Similarity Scoring
Aksoy, S. G., et al. Semantic needles in document haystacks: Sensitivity testing of LLM-as-a-judge similarity scoring.arXiv:2604.18835,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2502.13595 (2025) https://doi.org/10.48550/arXiv.2502.13595
Enevoldsen, K., et al. MMTEB: Massive multilingual text embedding benchmark.arXiv:2502.13595,
-
[10]
Zhou, Y ., et al. Beyond chunk-then-embed: A comprehensive taxonomy and evaluation of document chunking strategies for information retrieval.arXiv:2602.16974,
-
[11]
Yang, E. and Wang, D. Benchmark illusion: Disagreement among LLMs and its scientific conse- quences.arXiv:2602.11898,
-
[12]
NEBULA: Do we evaluate vision-language-action agents correctly?arXiv:2510.16263,
Peng, J., et al. NEBULA: Do we evaluate vision-language-action agents correctly?arXiv:2510.16263,
-
[13]
An hour each way
Telemetry disabled. Each instance requires ∼1,000+ LLM API calls during ingestion (one extraction call per session, plus embedding calls). A.3 LLM Judge All accuracy judgments use GPT-4o-mini with a binary prompt: given the ground-truth answer and the model’s response, output YES if the response contains the correct information, NO otherwise. The judge do...
2024
-
[14]
Needle-in-a-haystack
compared Mem0 against long- context LLMs, finding a 33pp accuracy gap on LongMemEval and a cost crossover at approximately 10 turns. However, this comparison does not isolate whether the gap comes from extraction, retrieval, embeddings, or model-specific context behavior. Recent work provides mechanistic insight into why full-context baselines are unstabl...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.