Sarashina2.2-TTS: Tackling Kanji Polyphony in Japanese Speech Generation via Data Scaling and Targeted Data Synthesis
Pith reviewed 2026-06-25 20:41 UTC · model grok-4.3
The pith
Sarashina2.2-TTS achieves state-of-the-art kanji reading accuracy in Japanese TTS through targeted data augmentation over all Joyo kanji.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
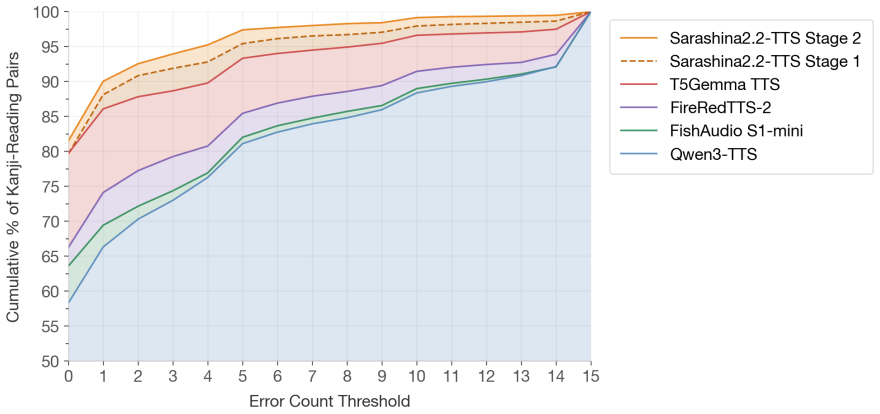
Sarashina2.2-TTS, trained on a large balanced Japanese-English corpus plus targeted synthesis for all 2,136 Joyo kanji and 4,378 readings, reaches state-of-the-art kanji-level reading accuracy, matches leading systems on sentence pronunciation, leads in zero-shot speaker similarity, and is the only model that keeps stable Japanese output regardless of prompt language.
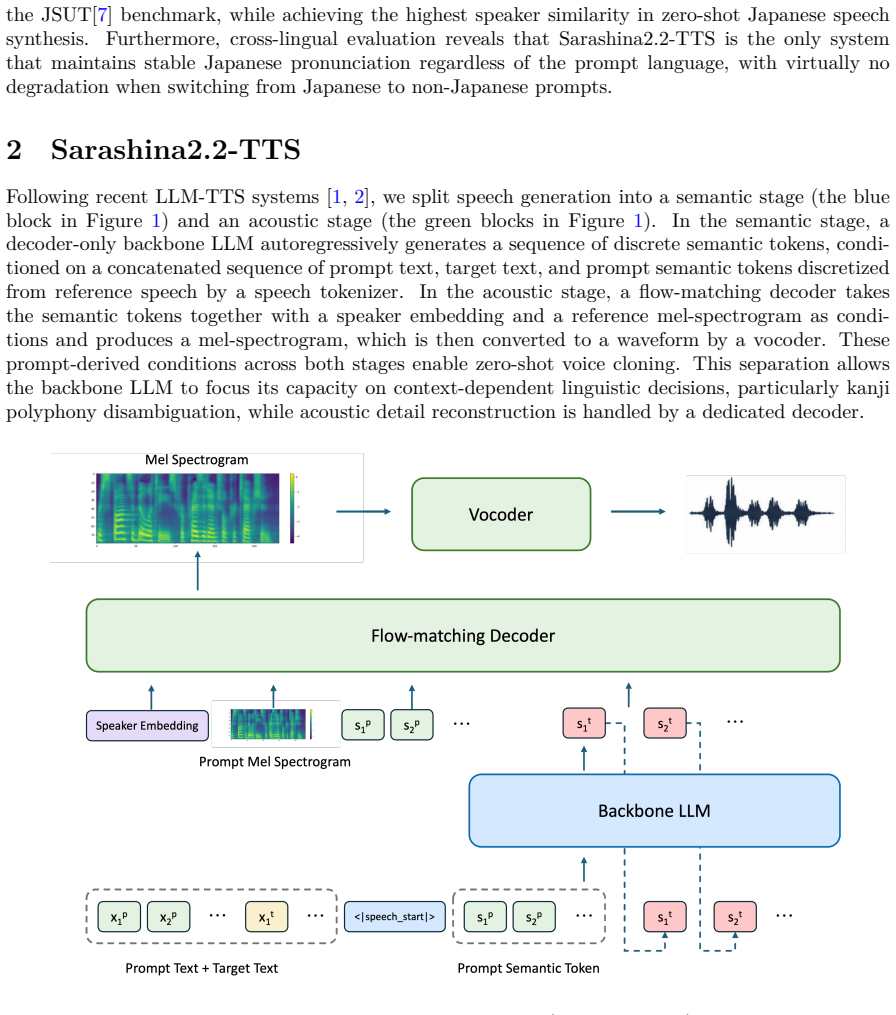
What carries the argument
The targeted data augmentation pipeline that generates examples covering all Joyo kanji and their readings to train disambiguation of context-dependent polyphony.
If this is right
- Targeted data augmentation significantly improves reading accuracy on kanji polyphony.
- The system matches top baselines on general sentence-level pronunciation.
- It delivers the highest speaker similarity in zero-shot Japanese speech synthesis.
- Cross-lingual evaluation shows stable Japanese pronunciation independent of prompt language.
Where Pith is reading between the lines
- Similar targeted coverage of polyphonic elements could be applied to other languages with context-dependent pronunciation rules.
- The Joyo Kanji Yomi Benchmark provides a standardized way to evaluate pronunciation models beyond sentence-level metrics.
- Balancing language data during scaling may be necessary for robustness when the model is prompted in mixed languages.
Load-bearing premise
The targeted data augmentation pipeline covering all 2,136 Joyo kanji and their 4,378 readings sufficiently resolves context-dependent polyphony disambiguation in real usage scenarios without introducing training artifacts or coverage gaps.
What would settle it
Evaluating the model on a held-out set of kanji contexts or rare readings not included in the augmentation pipeline and observing whether accuracy remains high or drops to baseline levels.
Figures
read the original abstract
While large language model (LLM)-based text-to-speech (TTS) systems have achieved high-quality speech synthesis, most existing systems focus on English and Chinese. Japanese, however, remains under-explored, and its unique linguistic challenges, such as widespread context-dependent kanji polyphony, have yet to be adequately tackled. Here we introduce Sarashina2.2-TTS (https://github.com/sbintuitions/sarashina2.2-tts), a Japanese-centric LLM-TTS system that tackles these challenges through a dual approach: data strategy and evaluation methodology. First, we scale training to approximately 361k hours of speech, incorporating a balanced mix of Japanese and English data. Furthermore, we design a targeted data augmentation pipeline covering all 2,136 Joyo (regular-use) kanji designated by Japan's Agency for Cultural Affairs to efficiently address kanji polyphony disambiguation. Second, we introduce the Joyo Kanji Yomi Benchmark (https://github.com/sbintuitions/JoyoKanji-Yomi-Benchmark), covering all 2,136 Joyo kanji and their 4,378 readings. Alongside this benchmark, we propose Kana-CER, a metric that compares synthesized speech against reference readings in the kana space, eliminating orthographic variations to directly measure pronunciation correctness. Experiments demonstrate that our targeted data augmentation significantly improves reading accuracy. Overall, Sarashina2.2-TTS achieves state-of-the-art kanji-level reading accuracy and matches top baselines on general sentence-level pronunciation, while delivering the highest speaker similarity in zero-shot Japanese speech synthesis. Furthermore, cross-lingual evaluation reveals that Sarashina2.2-TTS is the only system that maintains stable Japanese pronunciation regardless of the prompt language, confirming that our balanced training approach improves cross-lingual robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sarashina2.2-TTS, a Japanese LLM-based TTS system that scales training data to approximately 361k hours with a balanced Japanese-English mix and employs a targeted data augmentation pipeline covering all 2,136 Joyo kanji and their 4,378 readings to address context-dependent polyphony. It introduces the Joyo Kanji Yomi Benchmark and Kana-CER metric, claiming that the augmentation significantly improves reading accuracy, yielding SOTA kanji-level performance, competitive sentence-level pronunciation, highest zero-shot speaker similarity, and unique cross-lingual stability in Japanese pronunciation regardless of prompt language.
Significance. If the empirical claims hold after detailed validation, the work would be significant for Japanese TTS by demonstrating a data-centric solution to polyphony and releasing both code (https://github.com/sbintuitions/sarashina2.2-tts) and a comprehensive benchmark (https://github.com/sbintuitions/JoyoKanji-Yomi-Benchmark) that covers the full set of Joyo kanji; these artifacts, together with the cross-lingual robustness result, would provide reusable resources and a falsifiable testbed for future systems.
major comments (3)
- [§3] §3 (Data Augmentation Pipeline): the description of the targeted synthesis procedure does not enumerate the syntactic or semantic context diversity used for each of the 4,378 readings; without this, it is impossible to determine whether reported gains on the Joyo Kanji Yomi Benchmark reflect generalizable disambiguation or benchmark-specific pattern matching, directly bearing on the central claim of a general solution to polyphony.
- [Experiments] Experiments section (results tables): no statistical tests, confidence intervals, or error bars are reported for the claimed improvements in kanji-level reading accuracy or speaker similarity, and exact baseline implementations are not specified, leaving the magnitude and reliability of the SOTA claim unsupported.
- [§4.3] §4.3 (Cross-lingual evaluation): the claim that Sarashina2.2-TTS is 'the only system that maintains stable Japanese pronunciation' requires explicit comparison tables showing all competing systems under identical prompt-language conditions; the current presentation does not allow verification that the balanced training mix is the causal factor.
minor comments (3)
- [Abstract] Abstract: the phrase 'approximately 361k hours' should be replaced by the exact total and the precise Japanese/English split once the methods section is expanded.
- [Benchmark definition] Notation: Kana-CER is introduced without an explicit formula; adding the definition (e.g., character error rate after conversion to kana) in the benchmark section would improve reproducibility.
- [Reproducibility] The GitHub links for code and benchmark are welcome; the manuscript should state the exact commit or release tag used for all reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to improve clarity, rigor, and verifiability of the claims.
read point-by-point responses
-
Referee: [§3] §3 (Data Augmentation Pipeline): the description of the targeted synthesis procedure does not enumerate the syntactic or semantic context diversity used for each of the 4,378 readings; without this, it is impossible to determine whether reported gains on the Joyo Kanji Yomi Benchmark reflect generalizable disambiguation or benchmark-specific pattern matching, directly bearing on the central claim of a general solution to polyphony.
Authors: We agree that the current §3 description lacks explicit enumeration of context diversity. In revision we will expand this section to detail the syntactic structures (e.g., subject-object-verb variations, relative clauses) and semantic fields (e.g., daily life, technical, idiomatic) used to generate contexts for each reading, along with the sampling strategy that ensures coverage across the 4,378 readings. This addition will clarify that the pipeline targets generalizable disambiguation. revision: yes
-
Referee: Experiments section (results tables): no statistical tests, confidence intervals, or error bars are reported for the claimed improvements in kanji-level reading accuracy or speaker similarity, and exact baseline implementations are not specified, leaving the magnitude and reliability of the SOTA claim unsupported.
Authors: We accept that statistical support and implementation details are needed. The revised manuscript will report bootstrap confidence intervals, paired statistical tests (e.g., McNemar for accuracy, t-tests for similarity), and error bars where multiple seeds were run. We will also add precise citations and version numbers for all baselines, including any public checkpoints or re-implementations used. revision: yes
-
Referee: [§4.3] §4.3 (Cross-lingual evaluation): the claim that Sarashina2.2-TTS is 'the only system that maintains stable Japanese pronunciation' requires explicit comparison tables showing all competing systems under identical prompt-language conditions; the current presentation does not allow verification that the balanced training mix is the causal factor.
Authors: We will revise §4.3 to include side-by-side tables for every baseline under both Japanese-prompt and English-prompt conditions, reporting Kana-CER and other pronunciation metrics. These tables will make the stability claim directly verifiable and allow readers to evaluate the contribution of the balanced Japanese-English training mix. revision: yes
Circularity Check
No circularity detected; empirical claims rest on external comparisons
full rationale
The paper's central results (improved kanji reading accuracy via targeted augmentation, SOTA on the new Joyo Kanji Yomi Benchmark, and cross-lingual robustness) are obtained through training on scaled data plus augmentation, followed by direct measurement with Kana-CER against reference readings and comparison to independent baselines. The augmentation pipeline and benchmark target the same 2,136 kanji / 4,378 readings by design, but success is not guaranteed by construction; it requires the model to learn disambiguation that transfers to the test set. No equations, self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Targeted data augmentation over all Joyo kanji resolves context-dependent polyphony without side effects
Reference graph
Works this paper leans on
-
[1]
CosyVoice 3: Towards in-the-wild speech generation via scaling-up and post-training, 2025
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, Keyu An, Guanrou Yang, Yabin Li, Yanni Chen, Zhifu Gao, Qian Chen, Yue Gu, Mengzhe Chen, Yafeng Chen, Shiliang Zhang, Wen Wang, and Jieping Ye. CosyVoice 3: Towards in-the-wild speech generation via scaling-up and post-training, 2025. URL https...
Pith/arXiv arXiv 2025
-
[2]
Seed-TTS: A family of high-quality versatile speech generation models, 2024
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, Mingqing Gong, Peisong Huang, Qingqing Huang, Zhiying Huang, Yuanyuan Huo, Dongya Jia, Chumin Li, Feiya Li, Hui Li, Jiaxin Li, Xiaoyang Li, Xingxing Li, Lin Liu, Shouda Liu, Sichao Liu, Xudong Liu, Yuchen Liu, Zhengxi Liu, Lu Lu, J...
Pith/arXiv arXiv 2024
-
[3]
Qwen3-TTS technical report, 2026
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. Qwen3-TTS technical report, 2026. URL https://arxiv.org/abs/2601.15621
Pith/arXiv arXiv 2026
-
[4]
FireRedTTS-2: Towards long conversational speech generation for podcast and chatbot, 2025
Kun Xie, Feiyu Shen, Junjie Li, Fenglong Xie, Xu Tang, and Yao Hu. FireRedTTS-2: Towards long conversational speech generation for podcast and chatbot, 2025. URL https://arxiv.org/ abs/2509.02020
arXiv 2025
-
[5]
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Edresson Casanova, Kelly Davis, Eren Gölge, Görkem Göknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, and Julian Weber. XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model. In Interspeech 2024, pages 4978–4982, 2024. doi: 10.21437/Interspeech.2024-2016
-
[6]
CosyVoice 2: Scalable streaming speech synthesis with large language models, 2024
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, and Jingren Zhou. CosyVoice 2: Scalable streaming speech synthesis with large language models, 2024. URL https://arxiv.org/abs/2412.10117
Pith/arXiv arXiv 2024
-
[7]
JSUT corpus: free large-scale japanese speech corpus for end-to-end speech synthesis, 2017
Ryosuke Sonobe, Shinnosuke Takamichi, and Hiroshi Saruwatari. JSUT corpus: free large-scale japanese speech corpus for end-to-end speech synthesis, 2017. URL https://arxiv.org/abs/ 1711.00354
Pith/arXiv arXiv 2017
-
[8]
sarashina2.2-0.5b-instruct-v0.1
SB Intuitions. sarashina2.2-0.5b-instruct-v0.1. https://huggingface.co/sbintuitions/ sarashina2.2-0.5b-instruct-v0.1 , 2025. Hugging Face Model Repository
2025
-
[9]
Neural codec language models are zero-shot text to speech synthesizers, 2023
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. Neural codec language models are zero-shot text to speech synthesizers, 2023. URL https://arxiv.org/abs/2301. 02111
2023
-
[10]
Better speech synthesis through scaling, 2023
James Betker. Better speech synthesis through scaling, 2023. URL https://arxiv.org/abs/ 2305.07243
arXiv 2023
-
[11]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow Matching for Generative Modeling. In Proc. ICLR, 2023. 28 pages
2023
-
[12]
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In Proc. NeurIPS, volume 33, pages 17022–17033, 2020
2020
-
[13]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th Interna- tional Conference on Machine Learning , ICML’23. JMLR.org, 2023
2023
-
[14]
OWSM v4: Improving Open Whisper-Style Speech Models via Data Scaling and Cleaning
Yifan Peng, Muhammad Shakeel, Yui Sudo, William Chen, Jinchuan Tian, Chyi-Jiunn Lin, and 14 Shinji Watanabe. OWSM v4: Improving Open Whisper-Style Speech Models via Data Scaling and Cleaning. In Interspeech 2025, pages 2225–2229, 2025. doi: 10.21437/Interspeech.2025-1062
-
[15]
OWSM-CTC: An open encoder- only speech foundation model for speech recognition, translation, and language identification
Yifan Peng, Yui Sudo, Muhammad Shakeel, and Shinji Watanabe. OWSM-CTC: An open encoder- only speech foundation model for speech recognition, translation, and language identification. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , pages 10192–10209, 2024
2024
-
[16]
TouchTTS: An embarrassingly simple TTS framework that everyone can touch, 2024
Xingchen Song, Mengtao Xing, Changwei Ma, Shengqiang Li, Di Wu, Binbin Zhang, Fuping Pan, Dinghao Zhou, Yuekai Zhang, Shun Lei, Zhendong Peng, and Zhiyong Wu. TouchTTS: An embarrassingly simple TTS framework that everyone can touch, 2024. URL https://arxiv.org/ abs/2412.08237
arXiv 2024
-
[17]
Kiyoshi Kurihara, Nobumasa Seiyama, and Tadashi Kumano. Prosodic features control by sym- bols as input of sequence-to-sequence acoustic modeling for neural tts. IEICE Transactions on Information and Systems , E104.D(2):302–311, 2021. doi: 10.1587/transinf.2020EDP7104
-
[18]
Applying conditional random fields to japanese morphological analysis
Taku Kudo, Kaoru Yamamoto, and Yuji Matsumoto. Applying conditional random fields to japanese morphological analysis. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 230–237, 2004
2004
-
[19]
Corpus of spontaneous japanese: Its design and evaluation
Kikuo Maekawa. Corpus of spontaneous japanese: Its design and evaluation. In Proceedings of the International Symposium: Toward the Realization of Spontaneous Speech Engineering , pages 7–12, 2003
2003
-
[20]
T5Gemma-TTS technical report, 2026
Chihiro Arata and Kiyoshi Kurihara. T5Gemma-TTS technical report, 2026. URL https:// arxiv.org/abs/2604.01760
arXiv 2026
-
[21]
OpenAudio S1: Introducing S1
OpenAudio. OpenAudio S1: Introducing S1. https://openaudio.com/blogs/s1, 2025. Blog post
2025
-
[22]
CAM++: A fast and efficient network for speaker verification using context-aware masking, 2023
Hui Wang, Siqi Zheng, Yafeng Chen, Luyao Cheng, and Qian Chen. CAM++: A fast and efficient network for speaker verification using context-aware masking, 2023. URL https://arxiv.org/ abs/2303.00332
arXiv 2023
-
[23]
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hi- roshi Saruwatari. UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022. In Proc. Interspeech, pages 4521–4525, 2022
2022
-
[24]
Kaito Baba, Wataru Nakata, Yuki Saito, and Hiroshi Saruwatari. The t05 system for the voicemos challenge 2024: Transfer learning from deep image classifier to naturalness mos prediction of high- quality synthetic speech. In 2024 IEEE Spoken Language Technology Workshop (SLT) , pages 818–824, 2024. doi: 10.1109/SLT61566.2024.10832315
-
[25]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors
Chandan K A Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 6493–6497,
2021
-
[26]
doi: 10.1109/ICASSP39728.2021.9414878
-
[27]
DNSMOS p.835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors
Chandan K A Reddy, Vishak Gopal, and Ross Cutler. DNSMOS p.835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 886–890,
2022
-
[28]
doi: 10.1109/ICASSP43922.2022.9746108. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.