Memory Layouts for GPU-Data Transfer Buffering in SPH
Pith reviewed 2026-06-26 06:47 UTC · model grok-4.3
The pith
Splitting monolithic particle structs into access-pattern sub-structs cuts GPU buffer packing time by 20-40% in SPH.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Splitting classic array-of-struct data structures into a split array-of-struct arrangement, in which each logical struct decomposes into substructs determined by kernel read/write access patterns and attribute types, can reduce the time required to pack data to and from buffers by ~20% - 40%, lowering total time spent on GPU-offloading by ~12% - 25%.
What carries the argument
Split array-of-struct arrangement that decomposes each particle struct into multiple finer-grained sub-structs matched to kernel access patterns.
Load-bearing premise
The read and write patterns of the SPH kernels allow the particle struct to be split into sub-structs without adding offsetting overhead during kernel execution or data access.
What would settle it
Measure packing and total offloading times on the same SPH run before and after applying the split layout; the reported 20-40% and 12-25% reductions must appear in those timings.
Figures
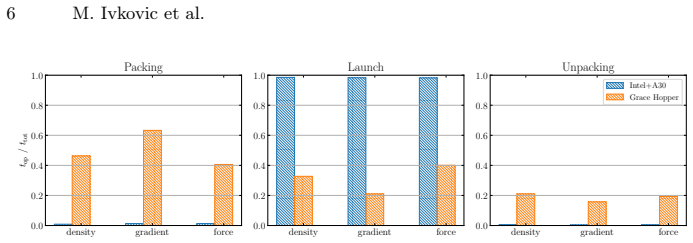
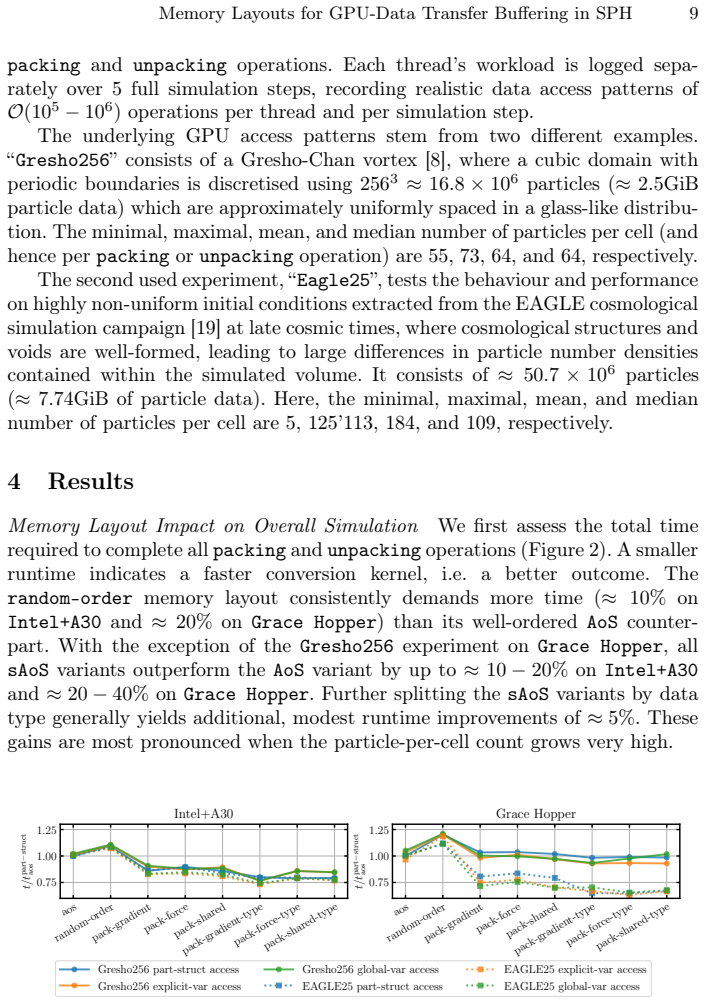
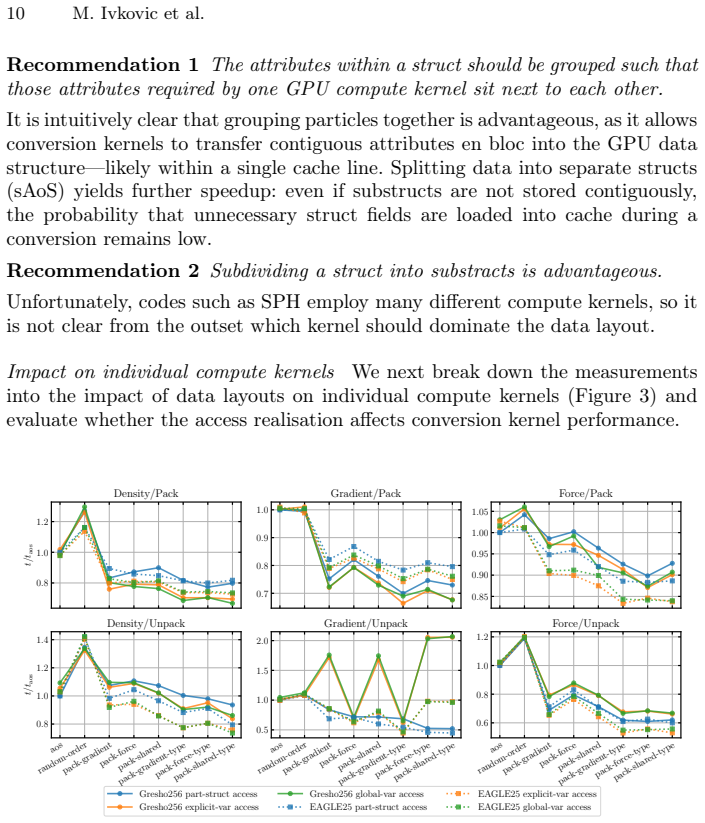

read the original abstract
The rise in GPU compute speed has outpaced improvements in host-to-device memory transfer speeds, despite the advent of shared-memory superchips. Consequently, memory transfer times now constitute an increasingly large fraction of total time-to-solution, compelling developers to compress GPU kernel input and output data into compact, minimal formats prior to GPU-offloading. This complements existing work on GPU- and compute-friendly data arrangements. We study a Smoothed Particle Hydrodynamics solver and propose memory layout strategies for host-side particle data that are particularly well-suited to GPU-offloading. Specifically, we advocate splitting classic array-of-struct data structures into a split array-of-struct arrangement, in which each logical struct decomposes into substructs determined by kernel read/write access patterns and attribute types. Splitting a monolithic particle struct into several bespoke, finer-grained structs can reduce the time required to pack data to and from buffers by ~20% - 40%, lowering total time spent on GPU-offloading by ~12% - 25%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies memory layouts for host-side particle data in a Smoothed Particle Hydrodynamics (SPH) solver to reduce the cost of packing/unpacking data for GPU offloading. It proposes decomposing a monolithic array-of-structs into a split array-of-structs whose sub-structs are chosen according to kernel read/write patterns and attribute types. The central quantitative claim is that this decomposition reduces packing time by ~20–40 % and total GPU-offloading time by ~12–25 %.
Significance. If the claimed reductions are shown to be net gains after accounting for any changes in kernel execution time, the work would provide a practical, access-pattern-driven technique for mitigating the growing fraction of time spent on host–device transfers in GPU-accelerated particle codes. The approach complements existing GPU-friendly data arrangements and could be relevant to other particle-based or irregular-access simulations.
major comments (2)
- [Abstract] Abstract: the performance claims rest on the assumption that the chosen split produces no material increase in SPH kernel runtime or cache behavior that would offset the reported packing-time savings. The text gives no indication that end-to-end timings (packing + transfer + kernel execution + unpacking) or isolated kernel timings before/after the layout change were measured; without such data the net 12–25 % improvement cannot be verified.
- [Abstract] The manuscript supplies no experimental setup, hardware description, compiler flags, error bars, or discussion of potential confounding factors (cache effects, register pressure, indirection overhead). Consequently the quantitative claims cannot be assessed from the given text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that additional experimental details and validation measurements are needed to fully support the quantitative claims. We will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims rest on the assumption that the chosen split produces no material increase in SPH kernel runtime or cache behavior that would offset the reported packing-time savings. The text gives no indication that end-to-end timings (packing + transfer + kernel execution + unpacking) or isolated kernel timings before/after the layout change were measured; without such data the net 12–25 % improvement cannot be verified.
Authors: We agree that net end-to-end gains require confirmation that kernel execution time is not materially increased. The reported 12–25 % reduction in total GPU-offloading time refers specifically to the combined cost of packing, host-to-device transfer, and unpacking; the GPU-side data layout and kernel code remain unchanged by the host-side split. Nevertheless, to address the concern, the revised manuscript will include isolated kernel execution timings (before and after the layout change) along with a brief discussion of cache and indirection effects. This will allow readers to verify that any overhead is negligible relative to the packing savings. revision: yes
-
Referee: [Abstract] The manuscript supplies no experimental setup, hardware description, compiler flags, error bars, or discussion of potential confounding factors (cache effects, register pressure, indirection overhead). Consequently the quantitative claims cannot be assessed from the given text.
Authors: We acknowledge that the current manuscript lacks a dedicated experimental-methods section. The revision will add a new subsection describing the test hardware (CPU, GPU, interconnect), compiler and optimization flags, number of runs used for timing, error-bar methodology, and a short discussion of potential confounding factors including cache behavior, register pressure, and any indirection cost introduced by the split array-of-structs representation. revision: yes
Circularity Check
No circularity: purely empirical timing measurements with no derivations or fitted predictions
full rationale
The paper presents an empirical study of memory layout changes for SPH particle data, reporting measured reductions in packing and GPU-offloading times (20-40% and 12-25% respectively) based on access-pattern-driven struct splitting. No equations, first-principles derivations, parameter fits, or predictions appear in the abstract or described content; the central claims rest on direct timing benchmarks rather than any self-referential construction, self-citation chain, or renamed known result. The derivation chain is therefore self-contained as a set of performance observations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 13th SPHERIC International Workshop
Borrow, J., Bower, R.G., Draper, P.W., Gonnet, P., Schaller, M.: SWIFT: Main- taining weak-scalability with a dynamic range of 10^4 in time-step size to harness extreme adaptivity. In: 13th SPHERIC International Workshop. pp. 44–51. Gal- way, Ireland (Jul 2018)
2018
-
[2]
Borrow, J., Schaller, M., Bower, R.G., Schaye, J.:Sphenix: Smoothed particle hydrodynamics for the next generation of galaxy formation simulations. Monthly Notices of the Royal Astronomical Society511(2), 2367–2389 (Feb 2022). https: //doi.org/10.1093/mnras/stab3166
-
[3]
Journal of Par- allel and Distributed Computing pp
Carter Edwards, H., Trott, C.R., Sunderland, D.: Kokkos: Enabling manycore performance portability through polymorphic memory access patterns. Journal of Parallel and Distributed Computing74(12), 3202–3216 (Dec 2014). https: //doi.org/10.1016/j.jpdc.2014.07.003
-
[4]
Monthly Notices of the Royal Astronomical Society 539(1), 1–33 (2025)
David-Cléris, T., Laibe, G., Lapeyre, Y.: The shamrock code: I–smoothed parti- cle hydrodynamics on gpus. Monthly Notices of the Royal Astronomical Society 539(1), 1–33 (2025)
2025
-
[5]
Computational Particle Mechanics9(5), 867–895 (2022)
Domínguez, J.M., Fourtakas, G., Altomare, C., Canelas, R.B., Tafuni, A., García- Feal, O., Martínez-Estévez, I., Mokos, A., Vacondio, R., Crespo, A.J., et al.: Du- alsphysics: from fluid dynamics to multiphysics problems. Computational Particle Mechanics9(5), 867–895 (2022)
2022
-
[6]
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
Frontiere, N., Emberson, J.D., Buehlmann, M., Rangel, E.M., Habib, S., Heitmann, K., Larsen, P., Morozov, V., Pope, A., Faucher-Giguère, C.A., et al.: Cosmological hydrodynamics at exascale: A trillion-particle leap in capability. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. pp. 25–35 (2025)
2025
-
[7]
Gingold, R.A., Monaghan, J.J.: Smoothed particle hydrodynamics: theory and applicationtonon-sphericalstars.Monthlynoticesoftheroyalastronomicalsociety 181(3), 375–389 (1977)
1977
-
[8]
Gresho, P.M., Chan, S.T.: On the theory of semi-implicit projection methods for viscous incompressible flow and its implementation via a finite element method that also introduces a nearly consistent mass matrix. Part 2: Implementation. International Journal for Numerical Methods in Fluids11(5), 621–659 (1990). https://doi.org/10.1002/fld.1650110510
-
[9]
Nuncius1(aop), 1–20 (2026) 14 M
Jones, M.L.: From gaming to science: How the graphical processor unit became a supercomputer. Nuncius1(aop), 1–20 (2026) 14 M. Ivkovic et al
2026
-
[10]
In: Varbanescu, A.L., Bhatele, A., Luszczek, P., Marc, B
Li, B., Schulz, H., Weinzierl, T., Zhang, H.: Dynamic Task Fusion for a Block- Structured Finite Volume Solver over a Dynamically Adaptive Mesh with Local Time Stepping. In: Varbanescu, A.L., Bhatele, A., Luszczek, P., Marc, B. (eds.) High Performance Computing. pp. 153–173. Springer International Publishing, Cham (2022). https://doi.org/10.1007/978-3-031...
-
[11]
Astro- nomical Journal, vol
Lucy, L.B.: A numerical approach to the testing of the fission hypothesis. Astro- nomical Journal, vol. 82, Dec. 1977, p. 1013-1024.82, 1013–1024 (1977)
1977
-
[12]
RAS Techniques and Instruments5, rzag008 (Jan 2026)
Nasar, A.M.A., Rogers, B.D., Fourtakas, G., Ivkovic, M., Weinzierl, T., Kay, S.T., Schaller, M.: Task-parallelism in SWIFT for heterogeneous compute architectures. RAS Techniques and Instruments5, rzag008 (Jan 2026). https://doi.org/10.1093/ rasti/rzag008
2026
-
[13]
Jour- nal of Computational Physics231(3), 759–794 (Feb 2012)
Price, D.J.: Smoothed Particle Hydrodynamics and Magnetohydrodynamics. Jour- nal of Computational Physics231(3), 759–794 (Feb 2012). https://doi.org/10. 1016/j.jcp.2010.12.011
2012
-
[14]
arXiv e-prints arXiv:2502.16517 (Feb 2025)
Radtke, P.K., Weinzierl, T.: Annotation-guided AoS-to-SoA conversions and GPU offloading with data views in C++. arXiv e-prints arXiv:2502.16517 (Feb 2025). https://doi.org/10.48550/arXiv.2502.16517
-
[15]
https://doi.org/10.48550/ arXiv.2512.05516
Radtke, P.K., Weinzierl, T.: Compiler-supported reduced precision and AoS-SoA transformations for heterogeneous hardware (Dec 2025). https://doi.org/10.48550/ arXiv.2512.05516
arXiv 2025
-
[16]
In: Proceedings of the 2026 SIAM Conference on Parallel Processing for Scientific Computing (PP)
Radtke, P.K., Weinzierl, T.: Compiler-supported reduced precision and aos-soa transformations for heterogeneous hardware. In: Proceedings of the 2026 SIAM Conference on Parallel Processing for Scientific Computing (PP). pp. 103–116. SIAM (2026)
2026
-
[17]
Schaller, M., Borrow, J., Draper, P.W., Ivkovic, M., McAlpine, S., Vandenbroucke, B., Bahé, Y., Chaikin, E., Chalk, A.B.G., Chan, T.K., Correa, C., van Daalen, M., Elbers, W., Gonnet, P., Hausammann, L., Helly, J., Huško, F., Kegerreis, J.A., Nobels, F.S.J., Ploeckinger, S., Revaz, Y., Roper, W.J., Ruiz-Bonilla, S., Sandnes, T.D., Uyttenhove, Y., Willis, ...
-
[18]
Monthly Notices of the Royal Astronomical Society548(1), stag375 (2026)
Schaye, J., Chaikin, E., Schaller, M., Ploeckinger, S., Huško, F., McGibbon, R.J., Trayford, J.W., Benítez-Llambay, A., Correa, C., Frenk, C.S., et al.: The colibre project: cosmological hydrodynamical simulations of galaxy formation and evolu- tion. Monthly Notices of the Royal Astronomical Society548(1), stag375 (2026)
2026
-
[19]
Schaye, J., Crain, R.A., Bower, R.G., Furlong, M., Schaller, M., Theuns, T., Dalla Vecchia, C., Frenk, C.S., McCarthy, I.G., Helly, J.C., Jenkins, A., Rosas- Guevara, Y.M., White, S.D.M., Baes, M., Booth, C.M., Camps, P., Navarro, J.F., Qu, Y., Rahmati, A., Sawala, T., Thomas, P.A., Trayford, J.: The EA- GLE project: Simulating the evolution and assembly ...
-
[20]
Schaye, J., Kugel, R., Schaller, M., Helly, J.C., Braspenning, J., Elbers, W., McCarthy, I.G., Van Daalen, M.P., Vandenbroucke, B., Frenk, C.S., et al.: The flamingo project: cosmological hydrodynamical simulations for large-scale struc- tureandgalaxyclustersurveys.MonthlyNoticesoftheRoyalAstronomicalSociety 526(4), 4978–5020 (2023)
2023
-
[21]
Computer physics communications271, 108171 (2022)
Thompson, A.P., Aktulga, H.M., Berger, R., Bolintineanu, D.S., Brown, W.M., Crozier, P.S., In’t Veld, P.J., Kohlmeyer, A., Moore, S.G., Nguyen, T.D., et al.: Memory Layouts for GPU-Data Transfer Buffering in SPH 15 Lammps-a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales. Computer physics communicat...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.