Neural Events: Discrete Asynchronous Autoencoders for Event-Based Vision
Pith reviewed 2026-06-26 18:20 UTC · model grok-4.3
The pith
Discrete asynchronous autoencoders turn raw event camera streams into a small set of neural events that preserve performance on detection and classification tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
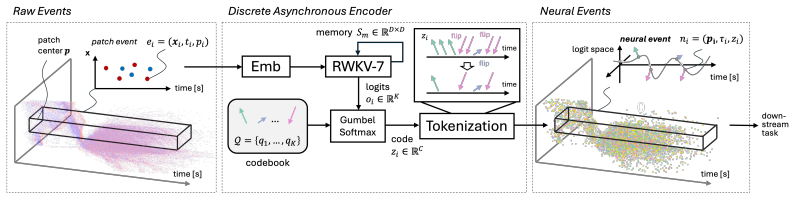
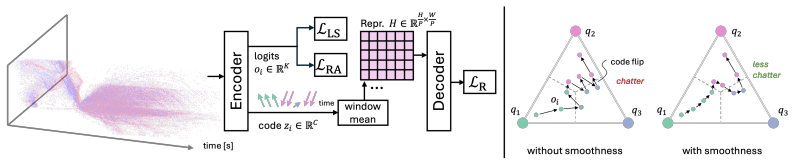
Re-tokenizing event streams into neural events, where each represents a local spatio-temporal context window encoded by a discrete learnable code from an asynchronous autoencoder, produces a highly compressed data stream. Every code flip triggers a neural event. Networks trained on these neural events perform on par with or surpass state-of-the-art approaches on object detection and classification while reducing the event rate by a factor of 2.0.
What carries the argument
Asynchronous autoencoder that outputs discrete learnable codes; a neural event is emitted each time one of these codes flips.
If this is right
- Object detection and classification pipelines can operate on half the data volume while retaining or improving accuracy.
- Downstream algorithms receive a more semantically dense input that balances fine temporal detail with manageable throughput.
- Event-based systems can avoid being overwhelmed by torrents of minimal-information brightness-change events.
- The same neural-event representation supports both classification and detection without separate retraining.
Where Pith is reading between the lines
- The same compression principle could extend to other high-rate asynchronous sensors such as neuromorphic audio or tactile arrays.
- Lower event rates would reduce bandwidth and power demands in embedded robotics or autonomous driving setups.
- If the codes prove task-agnostic, the autoencoder could serve as a general front-end for multiple simultaneous vision tasks.
Load-bearing premise
The discrete learnable codes preserve enough spatio-temporal information for downstream tasks without task-specific retraining or significant quantization loss.
What would settle it
Evaluation on a held-out event-camera dataset in which models trained on neural events drop more than 5 percent in mean average precision or accuracy relative to raw-event baselines at the same compression level.
Figures
read the original abstract
Event cameras capture dynamic scenes with exceptional temporal fidelity by representing them as a continuous stream of microsecond resolution \textit{events}. Each individual event, however, only carries minimal semantic value, merely signaling a localized brightness change. To derive meaningful signals, downstream algorithms need to quickly integrate cues from a potentially massive torrent of low-information events. Current architectures, however, are easily overwhelmed, struggling to balance capturing fine-grained temporal dynamics and maintaining a manageable data throughput. This paper proposes a framework to re-tokenize event streams into a small set of highly informative \textit{neural events}, each representing a local spatio-temporal context window with a discrete learnable code. Every time this code flips, a neural event is triggered, yielding a highly compressed data stream. We demonstrate that, across object detection and classification, networks trained on neural events are on par or surpass the performance of state-of-the-art approaches while reducing the event rate by a factor of 2.0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes neural events as a compressed representation of event-camera data streams, obtained by re-tokenizing raw events via a discrete asynchronous autoencoder whose learnable codes trigger an output event only when they flip. The central empirical claim is that models trained on these neural events achieve object-detection and classification performance on par with or exceeding state-of-the-art event-based methods while reducing the raw event rate by a factor of two.
Significance. If the preservation of task-relevant spatio-temporal information by the discrete codes can be demonstrated, the approach would address a core bottleneck in event-based vision—balancing temporal fidelity against data volume—potentially enabling more efficient downstream pipelines. The use of learnable discrete codes in an asynchronous setting is a conceptually interesting direction, but the abstract supplies no quantitative support for the performance or compression claims.
major comments (2)
- [Abstract] Abstract: the headline result (parity or improvement over SOTA while halving event rate) is asserted without any numerical results, dataset names, baseline methods, codebook size, reconstruction metrics, or ablation on quantization loss. Because the central claim rests on the unshown premise that the discrete codes retain sufficient spatio-temporal information, this absence is load-bearing and prevents evaluation of the data-to-claim link.
- [Abstract] Abstract: no description is given of the autoencoder architecture, training procedure, loss functions, or how the discrete codes are generated and triggered, making it impossible to assess whether fine-grained timing or polarity cues exploited by existing SOTA methods are preserved or discarded.
minor comments (1)
- [Abstract] Abstract: the phrase 'across object detection and classification' is used without naming the specific tasks, datasets, or evaluation protocols that would allow readers to contextualize the claimed factor-of-2.0 reduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on the abstract. We agree that the abstract would benefit from greater specificity to better support the central claims and will revise it accordingly while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (parity or improvement over SOTA while halving event rate) is asserted without any numerical results, dataset names, baseline methods, codebook size, reconstruction metrics, or ablation on quantization loss. Because the central claim rests on the unshown premise that the discrete codes retain sufficient spatio-temporal information, this absence is load-bearing and prevents evaluation of the data-to-claim link.
Authors: The experimental sections of the manuscript report the supporting quantitative results, including task performance metrics, comparisons against listed baselines, the factor-of-2.0 event-rate reduction, and codebook size. We acknowledge that these details are not summarized in the abstract itself. We will revise the abstract to include concise numerical highlights (e.g., the observed event-rate reduction and performance parity/improvement on the evaluated detection and classification tasks) to strengthen the data-to-claim link. revision: yes
-
Referee: [Abstract] Abstract: no description is given of the autoencoder architecture, training procedure, loss functions, or how the discrete codes are generated and triggered, making it impossible to assess whether fine-grained timing or polarity cues exploited by existing SOTA methods are preserved or discarded.
Authors: The methods section provides the full description of the discrete asynchronous autoencoder, its training procedure, the composite loss (including quantization), and the flip-based triggering mechanism for neural events. The design intentionally retains polarity and local spatio-temporal context. To address the abstract-level concern, we will add a brief clause describing the core mechanism (e.g., “re-tokenizing via a discrete asynchronous autoencoder whose learnable codes trigger output events on flips”). revision: yes
Circularity Check
No significant circularity; empirical performance claims are independent of inputs.
full rationale
The paper proposes an asynchronous autoencoder that produces discrete learnable codes to generate compressed neural events from raw event streams, then reports experimental results on object detection and classification tasks. The central claim (performance on par with or exceeding SOTA at 2x lower event rate) is an empirical outcome measured after training and evaluation, not a quantity derived by construction from the method definition or from fitted parameters renamed as predictions. No equations, uniqueness theorems, or self-citations are shown that would reduce the reported metrics to tautological equivalence with the input event data or the autoencoder loss. The derivation chain is self-contained against external benchmarks because success is defined by downstream task metrics that can falsify the preservation assumption.
Axiom & Free-Parameter Ledger
invented entities (1)
-
neural events
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: 2021 IEEE International Conference on Image Processing (ICIP)
Banerjee, S., Wang, Z.W., Chopp, H.H., Cossairt, O., Katsaggelos, A.K.: Lossy event compres- sion based on image-derived quad trees and poisson disk sampling. In: 2021 IEEE International Conference on Image Processing (ICIP). pp. 2154–2158. IEEE (2021)
2021
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops
Cannici, M., Ciccone, M., Romanoni, A., Matteucci, M.: Asynchronous convolutional networks for object detection in neuromorphic cameras. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 0–0 (2019)
2019
-
[3]
In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16
Cannici, M., Ciccone, M., Romanoni, A., Matteucci, M.: A differentiable recurrent surface for asynchronous event-based data. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16. pp. 136–152. Springer (2020)
2020
-
[4]
arXiv preprint arXiv:2304.13918 (2023)
Chakrabartty, S., Thakur, C.S., et al.: Neuromorphic computing with aer using time-to-event- margin propagation. arXiv preprint arXiv:2304.13918 (2023)
arXiv 2023
-
[5]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Chen, N.F.: Pseudo-labels for supervised learning on dynamic vision sensor data, applied to object detection under ego-motion. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 644–653 (2018)
2018
-
[6]
In: 2022 International Joint Conference on Neural Networks (IJCNN)
Cordone, L., Miramond, B., Thierion, P.: Object detection with spiking neural networks on automotive event data. In: 2022 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2022)
2022
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Dampfhoffer, M., Mesquida, T., Joubert, D., Dalgaty, T., Vivet, P., Posch, C.: Graph neural network combining event stream and periodic aggregation for low-latency event-based vision. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6909–6918 (2025)
2025
-
[8]
arXiv preprint arXiv:2001.08499 (2020)
De Tournemire, P., Nitti, D., Perot, E., Migliore, D., Sironi, A.: A large scale event-based detection dataset for automotive. arXiv preprint arXiv:2001.08499 (2020)
arXiv 2001
-
[9]
Delbruck, T.: Frame-free dynamic digital vision. In: Proc. Int. Symp. Secure-Life Electron. pp. 21–26 (2008). https://doi.org/10.5167/uzh-17620
-
[10]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Fan, R., Hao, W., Guan, J., Rui, L., Gu, L., Wu, T., Zeng, F., Zhu, Z.: Eventpillars: Pillar-based efficient representations for event data. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2861–2869 (2025)
2025
-
[11]
arXiv preprint arXiv:2504.15371 (2025)
Fang, W., Panda, P.: Event2vec: Processing neuromorphic events directly by representations in vector space. arXiv preprint arXiv:2504.15371 (2025)
Pith/arXiv arXiv 2025
-
[12]
In: 2020 IEEE International Solid-State Circuits Conference-(ISSCC)
Finateu, T., Niwa, A., Matolin, D., Tsuchimoto, K., Mascheroni, A., Reynaud, E., Mostafalu, P., Brady, F., Chotard, L., LeGoff, F., et al.: 5.10 a 1280× 720 back-illuminated stacked temporal contrast event-based vision sensor with 4.86 µm pixels, 1.066 geps readout, programmable event-rate controller and compressive data-formatting pipeline. In: 2020 IEEE...
2020
-
[13]
IEEE transactions on pattern analysis and machine intelligence44(1), 154–180 (2020)
Gallego, G., Delbrück, T., Orchard, G., Bartolozzi, C., Taba, B., Censi, A., Leutenegger, S., Davison, A.J., Conradt, J., Daniilidis, K., et al.: Event-based vision: A survey. IEEE transactions on pattern analysis and machine intelligence44(1), 154–180 (2020)
2020
-
[14]
arXiv preprint arXiv:2107.08430 (2021)
Ge, Z., Liu, S., Wang, F., Li, Z., Sun, J.: Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021)
Pith/arXiv arXiv 2021
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gehrig, D., Loquercio, A., Derpanis, K.G., Scaramuzza, D.: End-to-end learning of represen- tations for asynchronous event-based data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5633–5643 (2019)
2019
-
[16]
Gehrig, D., Scaramuzza, D.: Are high-resolution event cameras really needed? In: arxiv:2203.14672 (2022)
arXiv 2022
-
[17]
Nature 629(8014), 1034–1040 (2024) 13
Gehrig, D., Scaramuzza, D.: Low-latency automotive vision with event cameras. Nature 629(8014), 1034–1040 (2024) 13
2024
-
[18]
IEEE Robotics and Automation Letters6(3), 4947–4954 (2021)
Gehrig, M., Aarents, W., Gehrig, D., Scaramuzza, D.: Dsec: A stereo event camera dataset for driving scenarios. IEEE Robotics and Automation Letters6(3), 4947–4954 (2021)
2021
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gehrig, M., Scaramuzza, D.: Recurrent vision transformers for object detection with event cam- eras. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13884–13893 (2023)
2023
-
[20]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Graham, B., Engelcke, M., Van Der Maaten, L.: 3d semantic segmentation with submanifold sparse convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 9224–9232 (2018)
2018
-
[21]
arXiv preprint arXiv:2312.00752 (2023)
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023)
Pith/arXiv arXiv 2023
-
[22]
In: 25th Asia and South Pacific Design Automation Conference (ASP-DAC)
Guo, S., Kang, Z., Wang, L., Li, S., Xu, W.: Hashheat: An O(C) complexity hashing-based filter for dynamic vision sensor. In: 25th Asia and South Pacific Design Automation Conference (ASP-DAC). pp. 452–457 (2020)
2020
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hamaguchi, R., Furukawa, Y ., Onishi, M., Sakurada, K.: Hierarchical neural memory network for low latency event processing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22867–22876 (2023)
2023
-
[24]
arXiv preprint arXiv:2603.06228 (2026)
Hao, H., Sui, Z., Zou, R., Dai, Z., Zubi´c, N., Scaramuzza, D., Wang, W.: Low-latency event- based object detection with spatially-sparse linear attention. arXiv preprint arXiv:2603.06228 (2026)
arXiv 2026
-
[25]
arXiv preprint arXiv:2505.11165 (2025)
Hao, H., Zubi´c, N., He, W., Sui, Z., Scaramuzza, D., Wang, W.: Maximizing asynchronicity in event-based neural networks. arXiv preprint arXiv:2505.11165 (2025)
arXiv 2025
-
[26]
In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Iacono, M., Weber, S., Glover, A., Bartolozzi, C.: Towards event-driven object detection with off-the-shelf deep learning. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 1–9. IEEE (2018)
2018
-
[27]
In: 2019 International Conference on Robotics and Automation (ICRA)
Jiang, Z., Xia, P., Huang, K., Stechele, W., Chen, G., Bing, Z., Knoll, A.: Mixed frame-/event- driven fast pedestrian detection. In: 2019 International Conference on Robotics and Automation (ICRA). pp. 8332–8338. IEEE (2019)
2019
-
[28]
In: 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA)
Jouppi, N.P., Yoon, D.H., Ashcraft, M., Gottscho, M., Jablin, T.B., Kurian, G., Laudon, J., Li, S., Ma, P., Ma, X., et al.: Ten lessons from three generations shaped google’s tpuv4i: Industrial product. In: 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). pp. 1–14. IEEE (2021)
2021
-
[29]
In: The Eleventh International Conference on Learning Representations (2023)
Kamal, U., Dash, S., Mukhopadhyay, S.: Associative memory augmented asynchronous spa- tiotemporal representation learning for event-based perception. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[30]
Ieee Access8, 103149–103163 (2020)
Khan, N., Iqbal, K., Martini, M.G.: Lossless compression of data from static and mobile dynamic vision sensors-performance and trade-offs. Ieee Access8, 103149–103163 (2020)
2020
-
[31]
arXiv preprint arXiv:1412.6980 (2014)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Pith/arXiv arXiv 2014
-
[32]
IEEE transactions on pattern analysis and machine intelligence39(7), 1346–1359 (2016)
Lagorce, X., Orchard, G., Galluppi, F., Shi, B.E., Benosman, R.B.: Hots: a hierarchy of event- based time-surfaces for pattern recognition. IEEE transactions on pattern analysis and machine intelligence39(7), 1346–1359 (2016)
2016
-
[33]
In: European conference on computer vision
Lee, C., Kosta, A.K., Zhu, A.Z., Chaney, K., Daniilidis, K., Roy, K.: Spike-flownet: event-based optical flow estimation with energy-efficient hybrid neural networks. In: European conference on computer vision. pp. 366–382. Springer (2020)
2020
-
[34]
IEEE Transactions on Image Processing 31, 2975–2987 (2022) 14
Li, J., Li, J., Zhu, L., Xiang, X., Huang, T., Tian, Y .: Asynchronous spatio-temporal memory network for continuous event-based object detection. IEEE Transactions on Image Processing 31, 2975–2987 (2022) 14
2022
-
[35]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y ., Zhou, H., Yang, B., Zhang, Y ., Cui, Z., Bao, H., Zhang, G.: Graph-based asynchronous event processing for rapid object recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 934–943 (2021)
2021
-
[36]
Journal of Machine Learning Research23(42), 1–85 (2022)
Li, Z., Han, J., Li, Q., et al.: Approximation and optimization theory for linear continuous-time recurrent neural networks. Journal of Machine Learning Research23(42), 1–85 (2022)
2022
-
[37]
Lichtsteiner, P., Posch, C., Delbruck, T.: A 128 ×128 120 dB 15 µs latency asyn- chronous temporal contrast vision sensor. IEEE J. Solid-State Circuits43(2), 566–576 (2008). https://doi.org/10.1109/JSSC.2007.914337
-
[38]
Liu, H., Brandli, C., Li, C., Liu, S.C., Delbruck, T.: Design of a spatiotemporal correlation filter for event-based sensors. In: IEEE Int. Symp. Circuits Syst. (ISCAS). pp. 722–725 (2015). https://doi.org/10.1109/ISCAS.2015.7168735
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Z., Hu, H., Lin, Y ., Yao, Z., Xie, Z., Wei, Y ., Ning, J., Cao, Y ., Zhang, Z., Dong, L., et al.: Swin transformer v2: Scaling up capacity and resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12009–12019 (2022)
2022
-
[40]
In: International Conference on Learning Representations (2018)
Martin, E., Cundy, C.: Parallelizing linear recurrent neural nets over sequence length. In: International Conference on Learning Representations (2018)
2018
-
[41]
In: European Conference on Computer Vision
Messikommer, N., Gehrig, D., Loquercio, A., Scaramuzza, D.: Event-based asynchronous sparse convolutional networks. In: European Conference on Computer Vision. pp. 415–431. Springer (2020)
2020
-
[42]
arXiv preprint arXiv:2510.26614 (2025)
Øhrstrøm, C.K., Güldenring, R., Nalpantidis, L.: Spiking patches: Asynchronous, sparse, and efficient tokens for event cameras. arXiv preprint arXiv:2510.26614 (2025)
arXiv 2025
-
[43]
Frontiers in neuroscience9, 437 (2015)
Orchard, G., Jayawant, A., Cohen, G.K., Thakor, N.: Converting static image datasets to spiking neuromorphic datasets using saccades. Frontiers in neuroscience9, 437 (2015)
2015
-
[44]
arXiv preprint arXiv:2305.13048 (2023)
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., et al.: Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048 (2023)
Pith/arXiv arXiv 2023
-
[45]
arXiv preprint arXiv:2404.058923(2024)
Peng, B., Goldstein, D., Anthony, Q., Albalak, A., Alcaide, E., Biderman, S., Cheah, E., Ferdinan, T., Hou, H., Kazienko, P., et al.: Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.058923(2024)
Pith/arXiv arXiv 2024
-
[46]
In: Second Conference on Language Modeling (2025)
Peng, B., Zhang, R., Goldstein, D., Alcaide, E., Du, X., Hou, H., Lin, J., Liu, J., Lu, J., Merrill, W., et al.: Rwkv-7" goose" with expressive dynamic state evolution. In: Second Conference on Language Modeling (2025)
2025
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peng, Y ., Zhang, Y ., Xiong, Z., Sun, X., Wu, F.: Get: Group event transformer for event-based vision. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6038–6048 (2023)
2023
-
[48]
Advances in Neural Information Processing Systems33, 16639–16652 (2020)
Perot, E., De Tournemire, P., Nitti, D., Masci, J., Sironi, A.: Learning to detect objects with a 1 megapixel event camera. Advances in Neural Information Processing Systems33, 16639–16652 (2020)
2020
-
[49]
In: Meila, M., Zhang, T
Ramesh, A., Pavlov, M., Goh, G., Gray, S., V oss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 8821–8831. PMLR (18–24 Jul 2021), https://proceedings.mlr.press/ v139/r...
2021
-
[50]
IEEE transactions on pattern analysis and machine intelligence43(6), 1964–1980 (2019)
Rebecq, H., Ranftl, R., Koltun, V ., Scaramuzza, D.: High speed and high dynamic range video with an event camera. IEEE transactions on pattern analysis and machine intelligence43(6), 1964–1980 (2019)
1964
-
[51]
In: European Conference on Computer Vision
Santambrogio, R., Cannici, M., Matteucci, M.: Farse-cnn: Fully asynchronous, recurrent and sparse event-based cnn. In: European Conference on Computer Vision. pp. 1–18. Springer (2024) 15
2024
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Schaefer, S., Gehrig, D., Scaramuzza, D.: Aegnn: Asynchronous event-based graph neural net- works. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12371–12381 (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sekikawa, Y ., Hara, K., Saito, H.: Eventnet: Asynchronous recursive event processing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3887–3896 (2019)
2019
-
[54]
In: Applications of Digital Image Processing XLVIII
Sezavar, A., Brites, C., Ascenso, J., Ebrahimi, T.: A learning-based lossless event data compres- sion for computer vision applications. In: Applications of Digital Image Processing XLVIII. vol. 13605, pp. 230–236. SPIE (2025)
2025
-
[55]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shiba, S., Aoki, Y ., Gallego, G.: Simultaneous motion and noise estimation with event cameras. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6959–6969 (2025)
2025
-
[56]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Simonovsky, M., Komodakis, N.: Dynamic edge-conditioned filters in convolutional neural networks on graphs. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3693–3702 (2017)
2017
-
[57]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Sironi, A., Brambilla, M., Bourdis, N., Lagorce, X., Benosman, R.: Hats: Histograms of averaged time surfaces for robust event-based object classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1731–1740 (2018)
2018
-
[58]
Advances in Neural Information Processing Systems37, 48784–48809 (2024)
Vladymyrov, M., V on Oswald, J., Sandler, M., Ge, R.: Linear transformers are versatile in-context learners. Advances in Neural Information Processing Systems37, 48784–48809 (2024)
2024
-
[59]
Advances in Neural Information Processing Systems36, 74021–74038 (2023)
Wang, S., Xue, B.: State-space models with layer-wise nonlinearity are universal approximators with exponential decaying memory. Advances in Neural Information Processing Systems36, 74021–74038 (2023)
2023
-
[60]
arXiv preprint arXiv:2603.12231 (2026)
Wang, Y ., Bounou, O., Zhou, G., Balestriero, R., Rudner, T.G., LeCun, Y ., Ren, M.: Temporal straightening for latent planning. arXiv preprint arXiv:2603.12231 (2026)
arXiv 2026
-
[61]
Zhu, A.Z., Yuan, L., Chaney, K., Daniilidis, K.: Unsupervised event-based learning of optical flow, depth, and egomotion. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR). pp. 989–997 (2019). https://doi.org/10.1109/CVPR.2019.00108
-
[62]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zubic, N., Gehrig, M., Scaramuzza, D.: State space models for event cameras. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5819–5828 (2024) 16
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.