GroundShot: Visually Consistent Multi-Shot Long Video Generation via Entity-Grounded Shot Scheduling
Pith reviewed 2026-06-26 18:14 UTC · model grok-4.3
The pith
GroundShot keeps entities consistent across shots in generated videos by anchoring later appearances to verified first views stored in an online memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
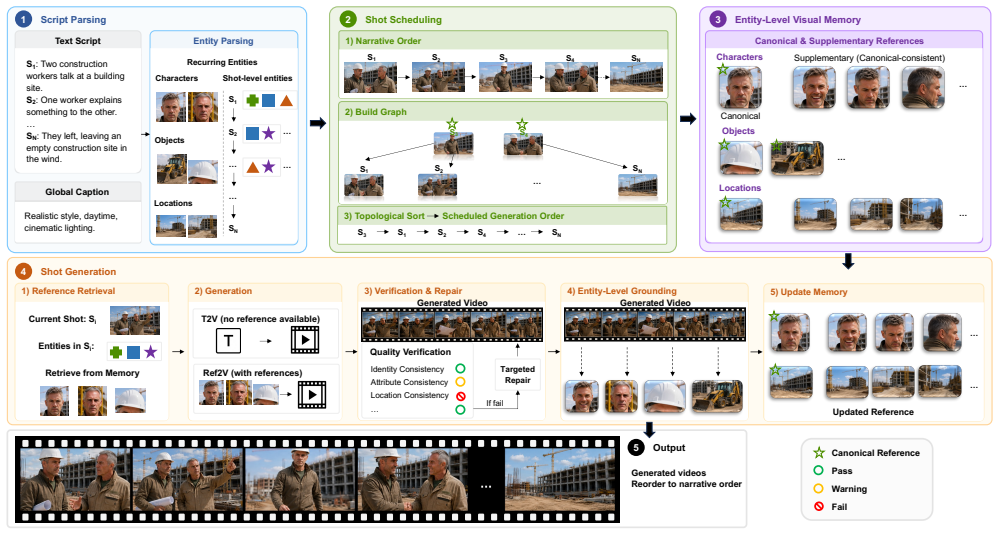
GroundShot is a training-free framework that builds an online entity visual memory from accepted shots, schedules generation order by expected usefulness as entity references, verifies entity reliability before storage, and retrieves references for each new shot to prevent drift from initial appearances.
What carries the argument
Entity-grounded shot scheduling with online verified memory, which decides shot order based on reference usefulness and anchors generation to first reliable entity appearances.
If this is right
- Existing video generation models can produce longer consistent multi-shot videos without modification.
- Consistency can be maintained by prioritizing shots that provide clear entity views early in the process.
- Entity-level evaluation via GroundBench isolates consistency issues from other video quality factors.
- Verification of generated entities before memory addition reduces error propagation.
Where Pith is reading between the lines
- Similar memory mechanisms might apply to other generative tasks like image sequences or 3D scene consistency.
- Testing on videos with more than the evaluated shot counts could reveal limits of the scheduling approach.
- The method assumes entities can be reliably grounded and verified automatically, which may vary by domain.
Load-bearing premise
That scheduling shots by their usefulness as entity references and storing only verified first appearances will stop inconsistencies from accumulating as the number of shots increases.
What would settle it
Generate a multi-shot video using GroundShot and a baseline on a sequence where entities reappear in later shots; measure if entity appearance drift is reduced compared to baseline, or if it matches baseline when shot count exceeds a threshold.
Figures




read the original abstract
Generating visually consistent multi-shot videos remains an open challenge. As videos span more shots, inconsistencies can accumulate across shots, causing entities that reappear across shots -- characters, objects, and locations -- to drift away from how they first appear. We observe that viewers judge consistency by comparing each later appearance of an entity with its first clear appearance; the visual quality of this initial appearance sets the consistency ceiling for all that follows. Motivated by this, we present \textbf{GroundShot}, a training-free, model-agnostic agentic framework for entity-grounded multi-shot generation. GroundShot builds an entity-level visual memory online from accepted generated shots: it schedules shots' generation order by their expected usefulness as entity references, grounds entities from generated videos, verifies their reliability before adding them to memory, and retrieves suitable entity references from memory before each shot is generated. To evaluate this entity-centered view of consistency, we further introduce \textbf{GroundBench}, a diagnostic benchmark that measures consistency at the entity level while isolating controlled challenge dimensions. Experiments show that GroundShot improves multi-shot consistency over existing methods while requiring no additional training or model modification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GroundShot, a training-free, model-agnostic agentic framework for multi-shot long video generation. It constructs an online entity-level visual memory from verified generated shots, orders shot generation by expected reference usefulness, performs entity grounding and reliability verification before memory writes, and retrieves entity references prior to each shot. The work also presents GroundBench, a diagnostic benchmark for entity-level consistency evaluation under controlled challenge dimensions, and reports that GroundShot improves consistency over baselines without model modification or retraining.
Significance. If the empirical results on GroundBench hold, the approach provides a practical, immediately deployable solution to entity drift in multi-shot video synthesis by grounding consistency to first-appearance references and gating memory via verification. The training-free and model-agnostic design, combined with the entity-centered diagnostic benchmark, represents a useful contribution to the video generation literature.
major comments (1)
- [Experiments / Results] The central claim that the entity-memory + usefulness scheduling loop measurably reduces entity drift rests on the experimental comparison in the results section; without the specific quantitative metrics, baselines, and statistical analysis from that section, the improvement cannot be assessed for load-bearing support.
minor comments (2)
- [Abstract] The abstract states that experiments show improvement but supplies no numbers, error bars, or dataset sizes; moving at least one key quantitative result into the abstract would strengthen the claim.
- [Method] Notation for the usefulness scoring function and the verification threshold should be defined explicitly with a short equation or pseudocode block to avoid ambiguity when describing the scheduling and memory-write logic.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim that the entity-memory + usefulness scheduling loop measurably reduces entity drift rests on the experimental comparison in the results section; without the specific quantitative metrics, baselines, and statistical analysis from that section, the improvement cannot be assessed for load-bearing support.
Authors: We agree that the quantitative results are essential to substantiate the central claim. The results section reports entity-level consistency metrics on GroundBench across controlled challenge dimensions, direct comparisons against multiple baselines (including both training-free and fine-tuned methods), and statistical analysis with means and standard deviations computed over repeated generations. To make this support more explicit and self-contained, we will expand the results presentation with additional tabulated breakdowns and clearer linkage between the scheduling/memory components and the observed gains in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes a training-free, model-agnostic framework that builds an online entity memory directly from verified generated shots, schedules by usefulness, and retrieves references before generation. No equations, fitted parameters, or predictions are present. No self-citations are invoked as load-bearing premises, and the central claims rest on empirical evaluation against baselines on the introduced GroundBench. The method is externally falsifiable via the benchmark metrics and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Viewers judge consistency primarily by comparing later entity appearances to the first clear appearance.
invented entities (1)
-
entity-level visual memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhaochong An, Menglin Jia, Haonan Qiu, Zijian Zhou, Xi- aoke Huang, Zhiheng Liu, Yiqi Yuan, Zuwei Li, Huazhu Chang, and Ziwei Liu. Onestory: Coherent multi-shot video generation with adaptive memory.arXiv preprint arXiv:2512.07802, 2025
arXiv 2025
-
[2]
Fan Bao, Chendong Xiang, Gang Yue, Guande He, Hongzhou Zhu, Kaiwen Zheng, Min Zhao, Shilong Liu, Yaole Wang, and Jun Zhu. Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models.arXiv preprint arXiv:2405.04233, 2024
arXiv 2024
-
[3]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[4]
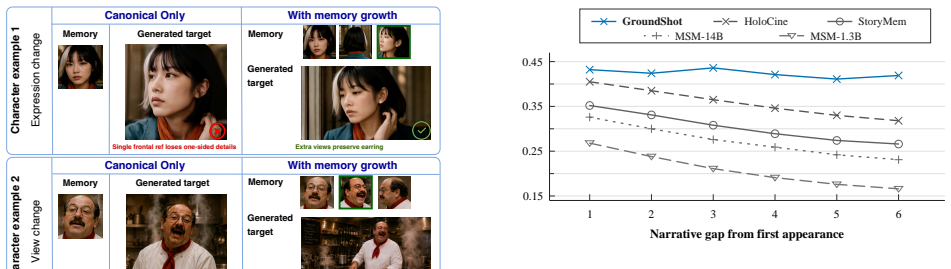
Nicolae Cudlenco, Mihai Masala, and Marius Leordeanu. Agentic video generation: From text to executable event graphs via tool-constrained llm planning.arXiv preprint arXiv:2604.10383, 2026
Pith/arXiv arXiv 2026
-
[5]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 4690–4699, 2019
2019
-
[6]
Mohamed Elmoghany, Liangbing Zhao, Xiaoqian Shen, Subhojyoti Mukherjee, Yang Zhou, Gang Wu, Viet Dac Lai, Seunghyun Yoon, Ryan Rossi, Abdullah Rashwan, Puneet Mathur, Varun Manjunatha, Daksh Dangi, Chien Nguyen, Nedim Lipka, Trung Bui, Krishna Kumar Singh, Ruiyi Zhang, Xiaolei Huang, Jaemin Cho, Yu Wang, Namyong Park, Zhengzhong Tu, Hongjie Chen, Hoda Eld...
arXiv 2025
-
[7]
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xi- aojie Li, Xunsong Li, Yifu Li, Shanchuan Lin, Zhijie Lin, Jiawei Liu, Shu Liu, Xiaonan Nie, Zhiwu Qing, Yuxi Ren, Li Sun, Zhi Tian, Rui Wang, Sen Wang, Guoqiang Wei, Guohong Wu, Jie Wu, Ruiqi Xia, Fei Xiao, Xuefeng Xiao, Jiangqiao Yan, Ceyuan Yang,...
Pith/arXiv arXiv 2025
-
[8]
Animatediff: Animate your personalized text- to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text- to-image diffusion models without specific tuning. InThe Twelfth International Conference on Learning Representa- tions (ICLR), 2024
2024
-
[9]
Ruozhen He, Meng Wei, Ziyan Yang, and Vicente Ordonez. Entitybench: Towards entity-consistent long-range multi- shot video generation.arXiv preprint arXiv:2605.15199, 2026
Pith/arXiv arXiv 2026
-
[10]
Haobo Hu, Qi Mao, Yuanhang Li, and Libiao Jin. Camera artist: A multi-agent framework for cinematic language sto- rytelling video generation.arXiv preprint arXiv:2604.09195, 2025
Pith/arXiv arXiv 2025
-
[11]
Panwen Hu, Jin Jiang, Jianqi Chen, Mingfei Han, Shengcai Liao, Xiaojun Chang, and Xiaodan Liang. Storyagent: Cus- tomized storytelling video generation via multi-agent collab- oration.arXiv preprint arXiv:2411.04925, 2024
arXiv 2024
-
[12]
VBench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
2024
-
[13]
Ozgur Kara, Krishna Kumar Singh, Feng Liu, Duygu Cey- lan, and James M. Rehg. Shotadapter: Text-to-multi-shot 13 video generation with diffusion models.arXiv preprint arXiv:2505.07652, 2025
arXiv 2025
-
[14]
Text2video-zero: Text- to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text- to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[15]
Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
Kling Team. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
Pith/arXiv arXiv 2025
-
[16]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[17]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[18]
Llm- grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models
Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm- grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. Transactions on Machine Learning Research (TMLR), 2024
2024
-
[19]
Llm-grounded video diffusion models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, and Boyi Li. Llm-grounded video diffusion models. InInter- national Conference on Learning Representations (ICLR), 2024
2024
-
[20]
Referdino: Referring video object segmentation with visual grounding founda- tions
Tianming Liang, Kun-Yu Lin, Chaolei Tan, Jianguo Zhang, Wei-Shi Zheng, and Jian-Fang Hu. Referdino: Referring video object segmentation with visual grounding founda- tions. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2025
2025
-
[21]
Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning. InConference on Language Mod- eling (COLM), 2024
2024
-
[22]
Jinzhuo Liu, Jiangning Zhang, Wencan Jiang, Yabiao Wang, Dingkang Liang, Zhucun Xue, Ran Yi, and Yong Liu. Ad- vancing narrative long video generation via training-free identity-aware memory.arXiv preprint arXiv:2605.18733, 2026
Pith/arXiv arXiv 2026
-
[23]
Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Ji- awei Liu, Gen Li, Siyu Zhou, Qian He, and Xinglong Wu. Phantom: Subject-consistent video generation via cross- modal alignment.arXiv preprint arXiv:2502.11079, 2025
arXiv 2025
-
[24]
Grounding dino: Mar- rying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Mar- rying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[25]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jian- feng Gao, Lifang He, and Lichao Sun. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024
Pith/arXiv arXiv 2024
-
[26]
Do Xuan Long, Xingchen Wan, Hootan Nakhost, Chen-Yu Lee, Tomas Pfister, and Sercan ¨O. Arık. Vista: A test- time self-improving video generation agent.arXiv preprint arXiv:2510.15831, 2025
arXiv 2025
-
[27]
Do Xuan Long, Yale Song, Min-Yen Kan, Tomas Pfister, and Long T. Le. A2rd: Agentic autoregressive diffusion for long video consistency.arXiv preprint arXiv:2605.06924, 2026
Pith/arXiv arXiv 2026
-
[28]
Fuchen Long, Zhaofan Qiu, Ting Yao, and Tao Mei. Videostudio: Generating consistent-content and multi-scene videos.arXiv preprint arXiv:2401.01256, 2024
arXiv 2024
-
[29]
Luma dream machine.https : / / lumalabs
Luma AI, Inc. Luma dream machine.https : / / lumalabs . ai / dream - machine, 2024. Accessed: 2025
2024
-
[30]
Xiangyang Luo, Qingyu Li, Xiaokun Liu, Wenyu Qin, Miao Yang, and Meng Wang. Filmweaver: Weaving consistent multi-shot videos with cache-guided autoregressive diffu- sion.arXiv preprint arXiv:2512.11274, 2025
arXiv 2025
-
[31]
Yawen Luo, Xiaoyu Shi, Junhao Zhuang, Yutian Chen, Quande Liu, Xintao Wang, Pengfei Wan, and Tianfan Xue. Shotstream: Streaming multi-shot video generation for inter- active storytelling.arXiv preprint arXiv:2603.25746, 2025
arXiv 2025
-
[32]
Holocine: Holis- tic generation of cinematic multi-shot long video narratives
Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Kaijun Chen, Ying He, and Lu Fang. Holocine: Holis- tic generation of cinematic multi-shot long video narratives. arXiv preprint arXiv:2510.20822, 2025
arXiv 2025
-
[33]
Yihao Meng, Zichen Liu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Yue Yu, Hanlin Wang, Haobo Li, Jia- peng Zhu, Yanhong Zeng, Xing Zhu, Yujun Shen, Qifeng Chen, and Huamin Qu. Causalcine: Real-time autoregressive generation for multi-shot video narratives.arXiv preprint arXiv:2605.12496, 2026
Pith/arXiv arXiv 2026
-
[34]
Minimax hailuo ai video generator.https://hailuoai.video/, 2024
MiniMax Technology Co., Ltd. Minimax hailuo ai video generator.https://hailuoai.video/, 2024. Ac- cessed: 2025
2024
-
[35]
GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[36]
OpenAI. GPT-4.1. 2025
2025
-
[37]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e J´egou, Julien Mairal...
Pith/arXiv arXiv 2024
-
[38]
Sampson, Shikai Li, Simone Parmeggiani, Steve Fine, Tara Fowler, Vladan Petro- vic, and Yuming Du
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, David Yan, Dhruv Choudhary, Dingkang Wang, Geet Sethi, Guan Pang, Haoyu Ma, Ishan Misra, Ji Hou, Jialiang Wang, Kiran Jagadeesh, Kunpeng Li, Luxin Zhang, Mannat Singh, Mary Williamson, Matt Le, Matthew Yu, Mitesh Kumar Sin...
Pith/arXiv arXiv 2024
-
[39]
Tianhao Qi, Jianlong Yuan, Wanquan Feng, Shancheng Fang, Jiawei Liu, SiYu Zhou, Qian He, Hongtao Xie, and Yongdong Zhang. Mask 2dit: Dual mask-based diffusion transformer for multi-scene long video generation.arXiv preprint arXiv:2503.19881, 2025
arXiv 2025
-
[40]
Runway Gen-3 alpha.https : / / runwayml
Runway AI, Inc. Runway Gen-3 alpha.https : / / runwayml . com / research / gen - 3 - alpha, 2024. Accessed: 2025
2024
-
[41]
Wenzhang Sun, Zhenyu Wang, Zhangchi Hu, Chunfeng Wang, Hao Li, and Wei Chen. Muse: A multi-agent frame- work for unconstrained story envisioning via closed-loop cognitive orchestration.arXiv preprint arXiv:2602.03028, 2026
arXiv 2026
-
[42]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Wan Team, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
Pith/arXiv arXiv 2025
-
[43]
Jiahao Wang, Hualian Sheng, Sijia Cai, Yuxiao Yang, Weizhan Zhang, Caixia Yan, Bing Deng, and Jieping Ye. Anyid: Ultra-fidelity universal identity-preserving video generation from any visual references.arXiv preprint arXiv:2603.25188, 2025
arXiv 2025
-
[44]
Echoshot: Multi-shot portrait video generation.arXiv preprint arXiv:2506.15838, 2025
Jiahao Wang, Hualian Sheng, Sijia Cai, Weizhan Zhang, Caixia Yan, Yachuang Feng, Bing Deng, and Jieping Ye. Echoshot: Multi-shot portrait video generation.arXiv preprint arXiv:2506.15838, 2025
arXiv 2025
-
[45]
Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu Jia. Multishotmaster: A controllable multi-shot video generation framework.arXiv preprint arXiv:2512.03041, 2025
arXiv 2025
-
[46]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023
Pith/arXiv arXiv 2023
-
[47]
Dreamvideo: Composing your dream videos with customized subject and motion
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhi- heng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, and Hong- ming Shan. Dreamvideo: Composing your dream videos with customized subject and motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[48]
Echo-forcing: A scene memory framework for interactive long video generation
Mingqiang Wu, Weilun Feng, Zhefeng Zhang, Haotong Qin, Yuqi Li, Guoxin Fan, Xiaokun Liu, Zhulin An, Libo Huang, Yongjun Xu, and Chuanguang Yang. Echo-forcing: A scene memory framework for interactive long video generation. arXiv preprint arXiv:2605.16003, 2026
Pith/arXiv arXiv 2026
-
[49]
Auto- mated movie generation via multi-agent cot planning.arXiv preprint arXiv:2503.07314, 2025
Weijia Wu, Zeyu Zhu, and Mike Zheng Shou. Auto- mated movie generation via multi-agent cot planning.arXiv preprint arXiv:2503.07314, 2025
arXiv 2025
-
[50]
Xiaoxue Wu, Xinyuan Chen, Yaohui Wang, and Yu Qiao. Shotdirector: Directorially controllable multi-shot video generation with cinematographic transitions.arXiv preprint arXiv:2512.10286, 2025
arXiv 2025
-
[51]
Captain cinema: Towards short movie generation.arXiv preprint arXiv:2507.18634, 2025
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, and Gordon Wetzstein. Captain cinema: Towards short movie generation.arXiv preprint arXiv:2507.18634, 2025
arXiv 2025
-
[52]
Zhifei Xie, Daniel Tang, Dingwei Tan, Jacques Klein, and Tegawend´e F. Bissyand´e. Dreamfactory: Pioneering multi- scene long video generation with a multi-agent framework. arXiv preprint arXiv:2408.11788, 2024
arXiv 2024
-
[53]
Xuenan Xu, Jiahao Mei, Chenliang Li, Yuning Wu, Ming Yan, Shaopeng Lai, Ji Zhang, and Mengyue Wu. Mm- storyagent: Immersive narrated storybook video generation with a multi-agent paradigm across text, image and audio. arXiv preprint arXiv:2503.05242, 2025
arXiv 2025
-
[54]
Zhenran Xu, Longyue Wang, Jifang Wang, Zhouyi Li, Sen- bao Liao, Baotian Tan, and Min Zhang. Filmagent: A multi- agent framework for end-to-end film automation in virtual 3d spaces.arXiv preprint arXiv:2501.12909, 2025
arXiv 2025
-
[55]
Yuhang Yang, Fan Zhang, Huaijin Pi, Shuai Guo, Guowei Xu, Wei Zhai, Yang Cao, and Zheng-Jun Zha. Gloria: Con- sistent character video generation via content anchors.arXiv preprint arXiv:2603.29931, 2025
arXiv 2025
-
[56]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[57]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721, 2023
Pith/arXiv arXiv 2023
-
[58]
Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2024
Kaiwen Zhang, Liming Jiang, Angtian Wang, Jacob Zhiyuan Fang, Tiancheng Zhi, Qing Yan, Hao Kang, Xin Lu, and 15 Xingang Pan. Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2024
arXiv 2024
-
[59]
Anime: Adap- tive multi-agent planning for long animation generation
Lisai Zhang, Baohan Xu, Siqian Yang, Mingyu Yin, Jing Liu, Chao Xu, Siqi Wang, Yidi Wu, Yuxin Hong, Zihao Zhang, Yanzhang Liang, and Yudong Jiang. Anime: Adap- tive multi-agent planning for long animation generation. arXiv preprint arXiv:2508.18781, 2025
arXiv 2025
-
[60]
Peixuan Zhang, Zijian Jia, Kaiqi Liu, Shuchen Weng, Si Li, and Boxin Shi. Stage: Storyboard-anchored gener- ation for cinematic multi-shot narrative.arXiv preprint arXiv:2512.12372, 2025
arXiv 2025
-
[61]
Canyu Zhao, Mingyu Liu, Wen Wang, Weihua Chen, Hao Chen, Zhe Yuan, Jianming Fan, Jian Wang, Ying Shan, and Chunhua Li. Moviedreamer: Hierarchical genera- tion for coherent long visual sequence.arXiv preprint arXiv:2407.16655, 2024
arXiv 2024
-
[62]
Mingzhe Zheng, Yongqi Xu, Haojian Huang, Xuran Ma, Yexin Liu, Wenjie Li, Jiahao Wang, Hao Tang, Wenqi Zhou, Yingqing Wang, Ao Wang, Pengfei Zhang, Bo Chen, and Yu Qiao. Videogen-of-thought: Step-by-step generating multi- shot video with minimal manual intervention.arXiv preprint arXiv:2503.15138, 2025
arXiv 2025
-
[63]
Jinsong Zhou, Yihua Du, Xinli Xu, Luozhou Wang, Zijie Zhuang, Yehang Zhang, Shuaibo Li, Xiaojun Hu, Bolan Su, and Ying-cong Chen. Videomemory: Toward consis- tent video generation via memory integration.arXiv preprint arXiv:2601.03655, 2025
arXiv 2025
-
[64]
Storydiffusion: Consistent self- attention for long-range image and video generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self- attention for long-range image and video generation. InAd- vances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[65]
Jiahao Zhu, Shanshan Lao, Lijie Liu, Gen Li, Tianhao Qi, Wei Han, Bingchuan Li, Fangfang Liu, Zhuowei Chen, Tianxiang Ma, Qian He, Yi Zhou, and Xiaohua Xie. Libra- gen: Playing a balance game in subject-driven video genera- tion.arXiv preprint arXiv:2603.13506, 2025
arXiv 2025
-
[66]
Vlogger: Make your dream a vlog.arXiv preprint arXiv:2401.09414, 2024
Shaobin Zhuang, Kunchang Li, Xinyuan Chen, Yaohui Wang, Ziwei Liu, Yu Qiao, and Yali Wang. Vlogger: Make your dream a vlog.arXiv preprint arXiv:2401.09414, 2024. 16 GroundShot: Visually Consistent Multi-Shot Long Video Generation via Entity-Grounded Shot Scheduling Supplementary Material
arXiv 2024
-
[67]
Alex Chen, a male detective in a dark trench coat, enters the police station lobby
Supplementary Method Details 6.1. Entity Graph Construction GroundShot relies on a lightweight entity graph to connect script-level semantics with visual grounding and reference reuse. For each shots i, the LLM parser outputs a set of entity recordsE i. Each record contains: • a stable entity ID (e.g.,char alex,obj briefcase, orloc station); • an entity t...
-
[68]
Chars.” and “Objs
GroundBench: Detailed Specification 7.1. Benchmark Taxonomy and Distribution GroundBench contains 54 Y AML scripts and 309 shots. It is organized into 18 sub-modules under four diag- nostic modules; each sub-module has three scripts with challenge level∈ {1,2,3}. The level split is balanced at the script level (18 scripts per level), with 99/103/107 shots...
-
[69]
Characters and objects use foreground crops; locations use reconstructed scene references
Entity-Level Visual Memory The entity-level visual memoryR={R e}e stores a com- pact active reference set for each entity. Characters and objects use foreground crops; locations use reconstructed scene references. Each entity has one protected canonical referencer ∗ e and, after canonical initialization, a small aux- iliary pool for canonical-consistent v...
-
[70]
High quality:q(c)≥0.85for foreground references, or qloc(cloc, e)≥0.85for location scene references
-
[71]
Canonical-ready visibility: face confidence≥0.7and near-frontal visibility for characters; recognizable, com- plete appearance for objects; artifact-free, foreground- free reconstruction for locations
-
[72]
The first candidate satisfying these conditions initializesr∗ e, regardless of narrative or execution index
Empty canonical slot: no canonical reference already ex- ists for this entity. The first candidate satisfying these conditions initializesr∗ e, regardless of narrative or execution index. Beforer ∗ e exists, non-canonical candidates are rejected rather than stored as auxiliaries. Afterr ∗ e exists, later candidates may enter only as auxiliary references a...
-
[73]
use_canonical
Agentic Reference Selection When multiple references are available, GroundShot selects a target-aware subset rather than blindly using the highest- quality image. The canonical reference remains the default consistency anchor, but it is not mandatory in every gen- eration call: characters usually keep it for identity, while objects and locations may use a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.