A3M: Adaptive, Adversarial and Multi-Objective Learning for Strategic Bidding in Repeated Auctions
Pith reviewed 2026-06-30 09:51 UTC · model grok-4.3
The pith
The A3M framework learns bidding strategies in repeated multi-unit auctions by combining adaptive reinforcement learning, opponent modeling, and multi-objective rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
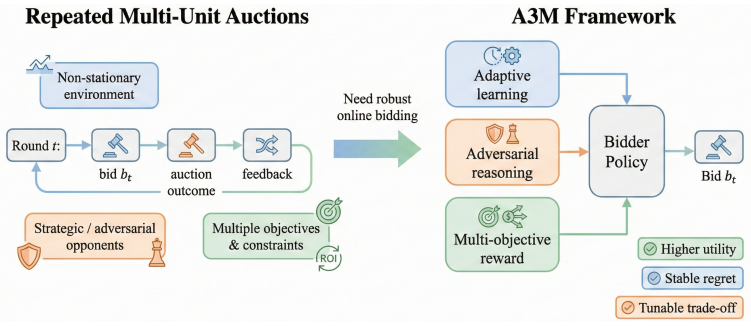
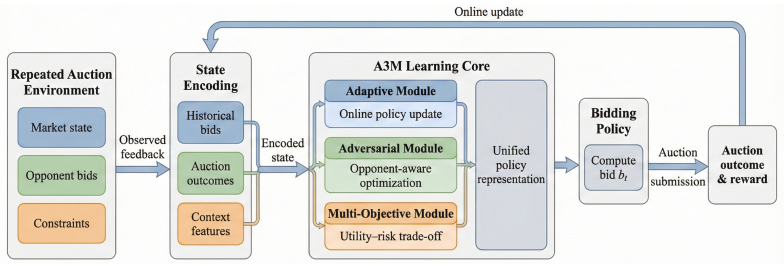
A3M integrates an actor-critic deep reinforcement learning backbone for dynamic exploration-exploitation, an opponent model that enables fictitious play against non-stationary adversaries, and a composite reward function that jointly optimizes bidder utility, auctioneer revenue, and fairness, delivering 30-40% lower final regret than baselines while remaining robust to strategy shifts.
What carries the argument
The A3M framework, which couples actor-critic reinforcement learning, an opponent model for fictitious play, and a composite multi-objective reward.
If this is right
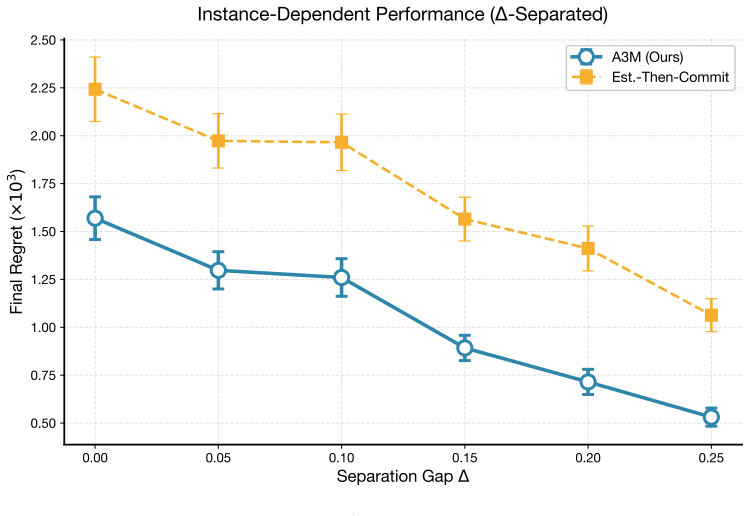
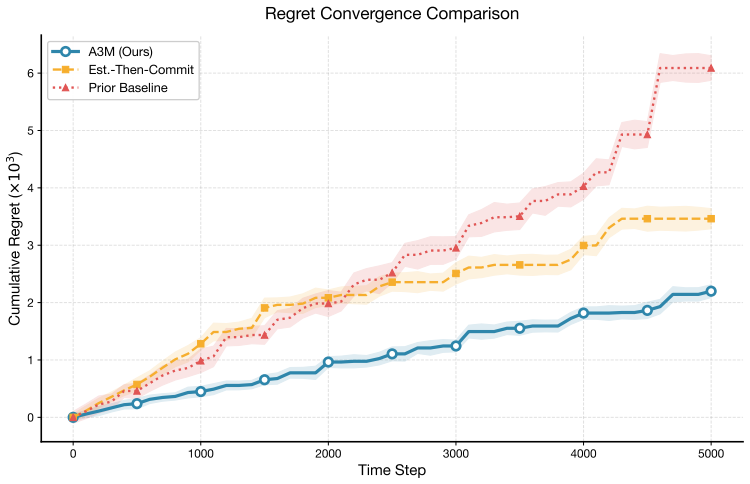
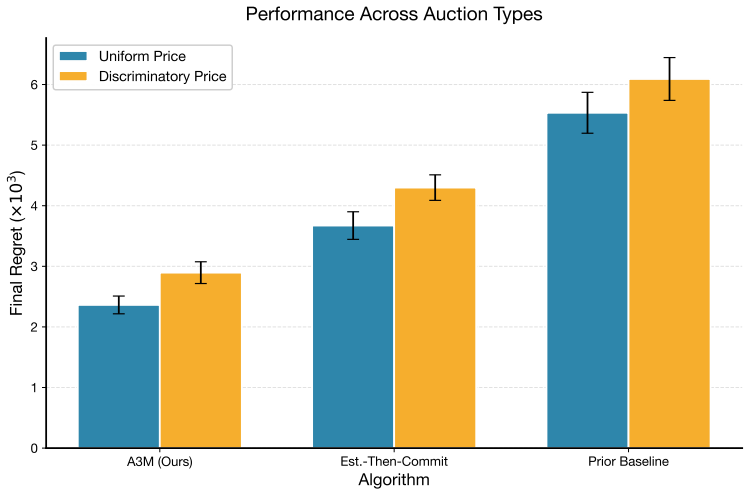
- A3M reduces final regret by 30-40% relative to established baselines in both discriminatory and uniform-price auctions.
- Performance holds when opponents switch strategies mid-sequence.
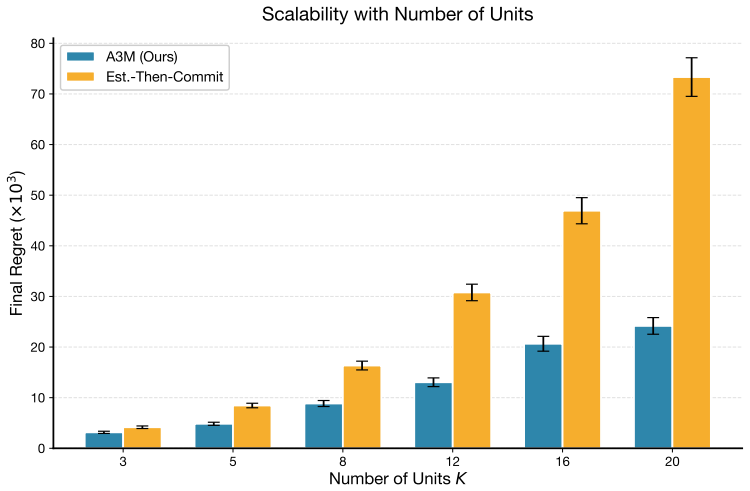
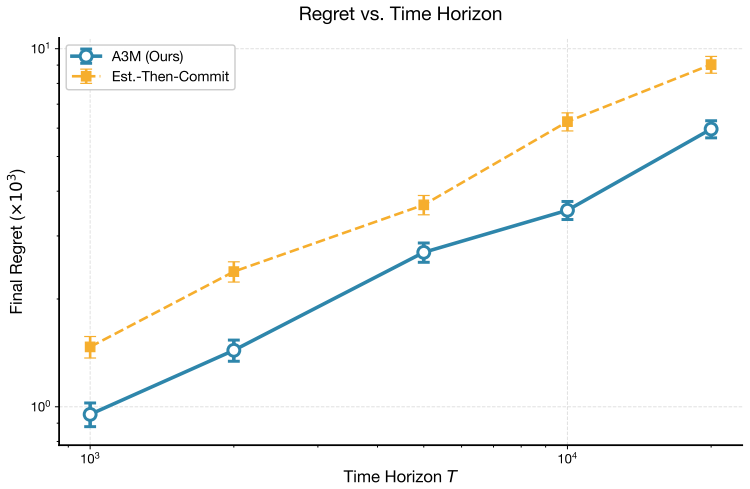
- Regret and runtime scale favorably as the number of units K increases.
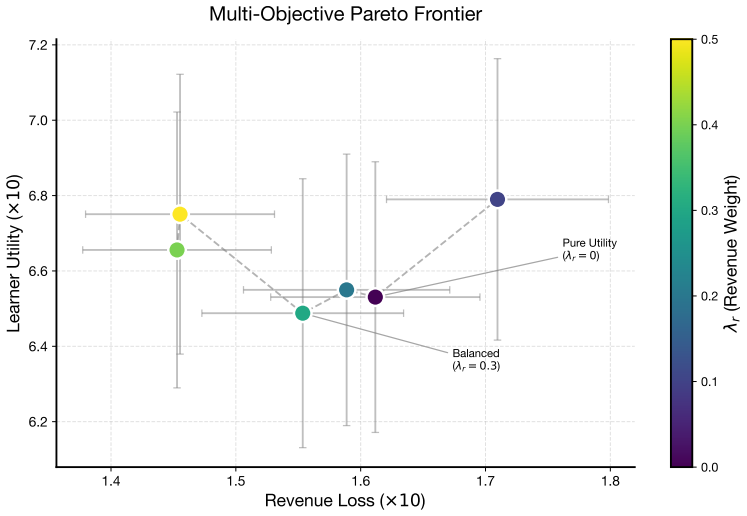
- The composite reward permits explicit tuning among bidder utility, auctioneer revenue, and fairness.
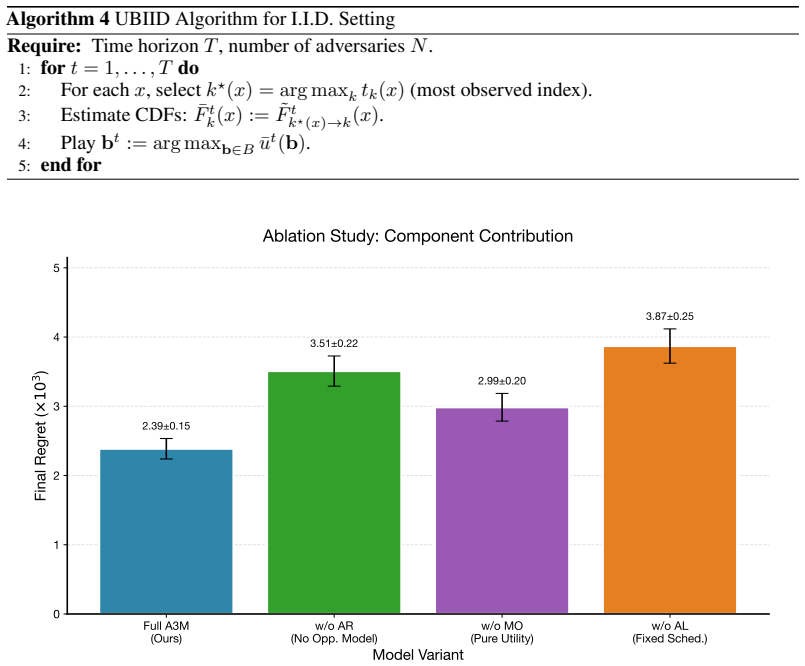
- Ablation experiments confirm that removing any one of the three components degrades results.
Where Pith is reading between the lines
- The same integration of adaptation, opponent modeling, and multi-objective design could be tested in other repeated decision settings that lack stationary opponents.
- Regulators interested in auction fairness might adopt the multi-objective formulation to enforce secondary goals without separate constraints.
- Theoretical analysis of regret bounds under the combined adaptive-adversarial structure remains open.
Load-bearing premise
The opponent model stays accurate enough to support fictitious play even when the real adversary changes behavior in ways the model was not designed to track.
What would settle it
Run the same auction sequences but replace the learned opponent model with one deliberately trained on mismatched data; if the 30-40% regret reduction vanishes while other methods remain stable, the central claim is undermined.
Figures
read the original abstract
Learning to bid in repeated multi-unit auctions with bandit feedback poses a fundamental challenge. Existing methods often rely on rigid explore-then-exploit schedules, assume stationary adversaries, and optimize solely for bidder utility, thereby limiting adaptability and strategic robustness. To address these limitations, we introduce the A3M framework, which integrates adaptive deep reinforcement learning (DRL), explicit adversarial reasoning, and principled multi-objective reward design for online auction strategy optimization. A3M employs an actor-critic DRL backbone to dynamically balance exploration and exploitation, an opponent model for fictitious play against non-stationary adversaries, and a composite reward function to jointly maximize utility, auctioneer revenue, and fairness. We provide the first comprehensive empirical evaluation of this integrated approach against established baselines in both discriminatory and uniform price auctions. Results show that A3M reduces final regret by 30--40\% in standard settings, maintains robust performance against adversarial strategy shifts, scales favorably with the number of units $K$, and enables tunable multi-objective trade-offs. An extensive ablation study confirms the necessity of each core component. Our work establishes A3M as a powerful and flexible framework for learning in complex auction environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the A3M framework for learning bidding strategies in repeated multi-unit auctions with bandit feedback. It integrates an actor-critic DRL backbone for adaptive exploration-exploitation, an opponent model based on fictitious play to reason against non-stationary adversaries, and a composite reward function that jointly optimizes bidder utility, auctioneer revenue, and fairness. The central claims are a 30--40% reduction in final regret versus baselines in discriminatory and uniform-price auctions, maintained robustness under adversarial strategy shifts, favorable scaling with the number of units K, and the ability to tune multi-objective trade-offs, all supported by comprehensive empirical comparisons and ablation studies.
Significance. If the empirical results prove reproducible with proper statistical controls, the work would offer a concrete advance over rigid explore-then-exploit or stationary-opponent methods by demonstrating an integrated adaptive-adversarial-multi-objective approach. The explicit use of fictitious play within a DRL loop and the ablation confirming component necessity are strengths that could influence subsequent auction-learning research, provided the opponent-model mechanics are fully specified.
major comments (2)
- [Abstract] Abstract: The claim that A3M 'reduces final regret by 30--40%' supplies no information on the number of independent runs, statistical tests, exact baseline implementations, hyperparameter choices, or data-exclusion/reward-weighting procedures. Without these details the central empirical result cannot be evaluated and is therefore load-bearing for any acceptance decision.
- [Abstract] Abstract (method description): The opponent model for fictitious play is asserted to remain effective against non-stationary adversaries, yet the manuscript provides no concrete update rule from bandit feedback, validation procedure, or misspecification safeguards. Because this component is required to attribute the reported robustness to adversarial shifts, its underspecification is a load-bearing gap.
minor comments (1)
- [Abstract] The abstract mentions 'standard settings' without defining the precise auction parameters (e.g., number of bidders, valuation distributions) used for the 30--40% figure; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to improve the clarity and evaluability of the abstract's claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that A3M 'reduces final regret by 30--40%' supplies no information on the number of independent runs, statistical tests, exact baseline implementations, hyperparameter choices, or data-exclusion/reward-weighting procedures. Without these details the central empirical result cannot be evaluated and is therefore load-bearing for any acceptance decision.
Authors: We agree the abstract omits these details. The full manuscript (Section 4 and Appendix) reports averages over 10 independent runs with standard errors, paired t-tests (p<0.05), baselines reimplemented from the cited papers using their published hyperparameters, no data exclusion, and reward weights of (0.6,0.2,0.2). We will revise the abstract to note 'across 10 independent runs with statistical significance' and add a brief clause on the evaluation protocol. revision: partial
-
Referee: [Abstract] Abstract (method description): The opponent model for fictitious play is asserted to remain effective against non-stationary adversaries, yet the manuscript provides no concrete update rule from bandit feedback, validation procedure, or misspecification safeguards. Because this component is required to attribute the reported robustness to adversarial shifts, its underspecification is a load-bearing gap.
Authors: The current manuscript underspecifies the update mechanics in the abstract and main text. We will revise to include the explicit empirical-frequency update rule from bandit feedback (observed bids and outcomes), the ablation-based validation, and the uniform-prior mixing safeguard against misspecification. This will appear in both the abstract and Section 3. revision: yes
Circularity Check
Empirical framework with no derivation chain or fitted predictions
full rationale
The paper presents A3M as an empirical DRL-based method evaluated via simulations and ablations against baselines. No equations, derivations, or parameter-fitting steps are described that reduce a claimed result (e.g., regret reduction) to its own inputs by construction. Claims rest on experimental outcomes rather than self-referential definitions or self-citation chains. This is the standard honest finding for an applied empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rui Ai, Yang Gao, Long-Bo Huang, Hao Luo, and Zhi-Ming Wang. No-regret learning in repeated first-price auctions with budget constraints.arXiv preprint arXiv:2205.14572,
-
[2]
AOI: Context-Aware Multi-Agent Operations via Dynamic Scheduling and Hierarchical Memory Compression
Zishan Bai, Enze Ge, and Junfeng Hao. Multi-agent collaborative framework for intelligent it operations: An aoi system with context-aware compression and dynamic task scheduling.arXiv preprint arXiv:2512.13956,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ziqian Bi, Lu Chen, Junhao Song, Hongying Luo, Enze Ge, Junmin Huang, Tianyang Wang, Keyu Chen, Chia Xin Liang, Zihan Wei, et al. Exploring efficiency frontiers of thinking budget in medical reasoning: Scaling laws between computational resources and reasoning quality.arXiv:2508.12140,
-
[4]
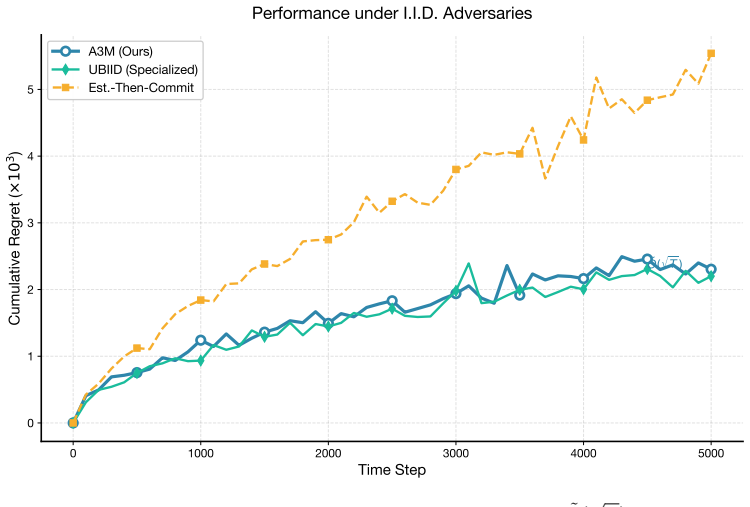
Adversaries A3M (Ours) UBIID (Specialized) Est.-Then-Commit Figure 8: Performance comparison under i.i.d
16 0 1000 2000 3000 4000 5000 Time Step 0 1 2 3 4 5Cumulative Regret (×103) O( T) Performance under I.I.D. Adversaries A3M (Ours) UBIID (Specialized) Est.-Then-Commit Figure 8: Performance comparison under i.i.d. adversaries. A3M achieves ˜O( √ T) regret comparable to the specialized UBIID algorithm, while Est.-Then-Commit exhibits ˜O(T 2/3)scaling. Georg...
2000
-
[5]
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Zongsheng Cao, Yangfan He, Anran Liu, Jun Xie, Zhepeng Wang, and Feng Chen. Cofi-dec: Hallucination-resistant decoding via coarse-to-fine generative feedback in large vision-language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10709– 10718, 2025a. Zongsheng Cao, Yangfan He, Anran Liu, Jun Xie, Zhepeng Wang, and Feng...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
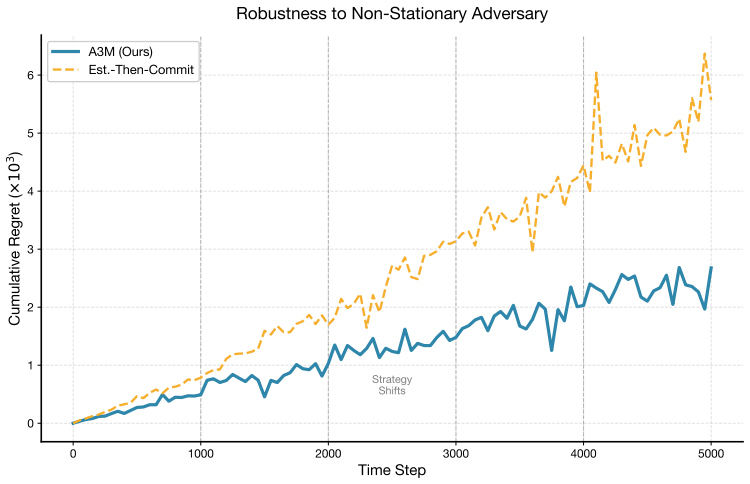
A3M quickly recovers after each shift, while Est.-Then-Commit accumulates persistent regret
17 0 1000 2000 3000 4000 5000 Time Step 0 1 2 3 4 5 6Cumulative Regret (×103) Strategy Shifts Robustness to Non-Stationary Adversary A3M (Ours) Est.-Then-Commit Figure 9: Robustness comparison under non-stationary adversaries with strategy shifts at t= 1000,2000,3000,4000 . A3M quickly recovers after each shift, while Est.-Then-Commit accumulates persiste...
2000
-
[7]
Xudong Han, Xianglun Gao, Xiaoyi Qu, and Zhenyu Yu. Multi-agent medical decision consensus matrix system: An intelligent collaborative framework for oncology mdt consultations.arXiv preprint arXiv:2512.14321,
-
[8]
A comprehensive guide to explainable ai: From classical models to llms.arXiv:2412.00800,
Weiche Hsieh, Ziqian Bi, Chuanqi Jiang, Junyu Liu, Benji Peng, Sen Zhang, Xuanhe Pan, Jiawei Xu, Jinlang Wang, Keyu Chen, et al. A comprehensive guide to explainable ai: From classical models to llms.arXiv:2412.00800,
-
[9]
GUI Agents for Continual Game Generation
Yixu Huang, Bo Li, Na Li, Zhe Wang, Kaijie Chen, Haonan Ge, Qingyi Si, Yuanzhe Shen, Rui- han Yang, Guangjing Wang, et al. Gui agents for continual game generation.arXiv preprint arXiv:2605.28258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ming Li, Ziqian Bi, Tianyang Wang, Yizhu Wen, Qian Niu, Junyu Liu, Benji Peng, Sen Zhang, Xuanhe Pan, Jiawei Xu, et al. Deep learning and machine learning with gpgpu and cuda: Unlocking the power of parallel computing.arXiv:2410.05686,
-
[11]
Shiyin Lin. Abductive inference in retrieval-augmented language models: Generating and validating missing premises, 2025a. URLhttps://arxiv.org/abs/2511.04020. Shiyin Lin. Hybrid fuzzing with llm-guided input mutation and semantic feedback, 2025b. URL https://arxiv.org/abs/2511.03995. Shiyin Lin. Llm-driven adaptive source-sink identification and false po...
-
[12]
Asynchronous methods for deep reinforcement learning.International Conference on Machine Learning, pages 1928–1937,
V olodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning.International Conference on Machine Learning, pages 1928–1937,
1928
-
[13]
Mingqiao Mo, Yunlong Tan, Hao Zhang, Heng Zhang, and Yangfan He. Shieldedcode: Learning robust representations for virtual machine protected code.arXiv preprint arXiv:2601.20679,
-
[14]
Qian Niu, Keyu Chen, Ming Li, Pohsun Feng, Ziqian Bi, Lawrence KQ Yan, Yichao Zhang, Cait- lyn Heqi Yin, Cheng Fei, Junyu Liu, Benji Peng, Tianyang Wang, Yunze Wang, Silin Chen, and Ming Liu. From text to multimodality: Exploring the evolution and impact of large language models in medical practice, 2024a. URLhttps://arxiv.org/abs/2410.01812. Qian Niu, Ju...
-
[15]
URLhttps://arxiv.org/abs/2511.01243. William Vickrey. Counterspeculation, auctions, and competitive sealed tenders.The Journal of Finance, 16(1):8–37,
-
[16]
Deep learning model security: Threats and defenses
Tianyang Wang, Ziqian Bi, Yichao Zhang, Ming Liu, Weiche Hsieh, Pohsun Feng, Lawrence KQ Yan, Yizhu Wen, Benji Peng, Junyu Liu, et al. Deep learning model security: Threats and defenses. InarXiv:2412.08969, 2024a. Tianyang Wang, Ming Liu, Benji Peng, Xinyuan Song, Charles Zhang, Xintian Sun, Qian Niu, Junyu Liu, Silin Chen, Keyu Chen, Ming Li, Pohsun Feng...
-
[17]
URLhttps://arxiv.org/abs/2502.03478. Yuyao Wang. Low-power design of advanced image processing algorithms under fpga in real-time applications. In2024 IEEE 4th International Conference on Power, Electronics and Computer Applications (ICPECA), pages 1080–1084. IEEE,
-
[18]
Learning-Based Automated Adversarial Red-Teaming for Robustness Evaluation of Large Language Models
Ze-Lin Wei, Hong-Yu An, Yao Yao, Wei-Cong Su, Guo Li, Saifullah, Bi-Feng Sun, and Mu-Jiang- Shan Wang. Fstgat: Financial spatio-temporal graph attention network for non-stationary financial systems and its application in stock price prediction.Symmetry, 17(8):1344, 2025a. 21 Zhang Wei, Peilu Hu, Shengning Lang, Hao Yan, Li Mei, Yichao Zhang, Chen Yang, Ju...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Yi Xin, Qi Qin, Siqi Luo, Kaiwen Zhu, Juncheng Yan, Yan Tai, Jiayi Lei, Yuewen Cao, Keqi Wang, Yibin Wang, et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding.arXiv preprint arXiv:2510.06308, 2025a. Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Ren...
-
[20]
URLhttps://arxiv.org/abs/2410.21348. Chen Yang, Yangfan He, Aaron Xuxiang Tian, Dong Chen, Jianhui Wang, Tianyu Shi, Arsalan Heydarian, and Pei Liu. Wcdt: World-centric diffusion transformer for traffic scene generation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6566–6572. IEEE,
-
[21]
Lin Yu, Xiaofei Han, Yifei Kang, Chiung-Yi Tseng, Danyang Zhang, Ziqian Bi, and Zhimo Han. Af- fective multimodal agents with proactive knowledge grounding for emotionally aligned marketing dialogue.arXiv preprint arXiv:2511.21728,
-
[22]
Probability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
22 Wenhao Yu, Shaohang Wei, Jiahong Liu, Yifan Li, Minda Hu, Aiwei Liu, Hao Zhang, and Irwin King. Probability-entropy calibration: An elastic indicator for adaptive fine-tuning.arXiv preprint arXiv:2602.01745,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Hao Zhang, Bo Huang, Zhenjia Li, Xi Xiao, Hui Yi Leong, Zumeng Zhang, Xinwei Long, Tianyang Wang, and Hao Xu. Sensitivity-lora: Low-load sensitivity-based fine-tuning for large language models.arXiv preprint arXiv:2509.09119, 2025a. Hao Zhang, Zhenjia Li, Runfeng Bao, Yifan Gao, Xi Xiao, Heng Zhang, Shuyang Zhang, Bo Huang, Yuhang Wu, Tianyang Wang, et al...
-
[24]
Reagent-v: A reward-driven multi-agent framework for video understanding
Yiyang Zhou, Yangfan He, Yaofeng Su, Siwei Han, Joel Jang, Gedas Bertasius, Mohit Bansal, and Huaxiu Yao. Reagent-v: A reward-driven multi-agent framework for video understanding.arXiv preprint arXiv:2506.01300,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.