Continuous Audio Thinking for Large Audio Language Models
Pith reviewed 2026-06-27 21:51 UTC · model grok-4.3
The pith
Large audio language models preserve acoustic details like prosody and pitch through a continuous latent workspace before generating text responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
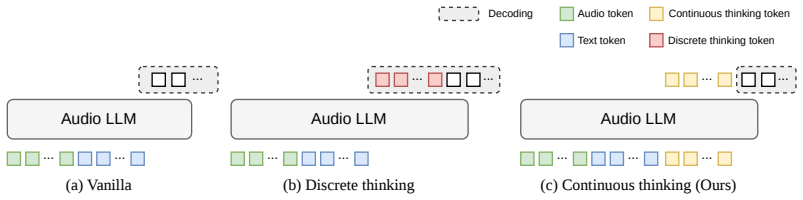
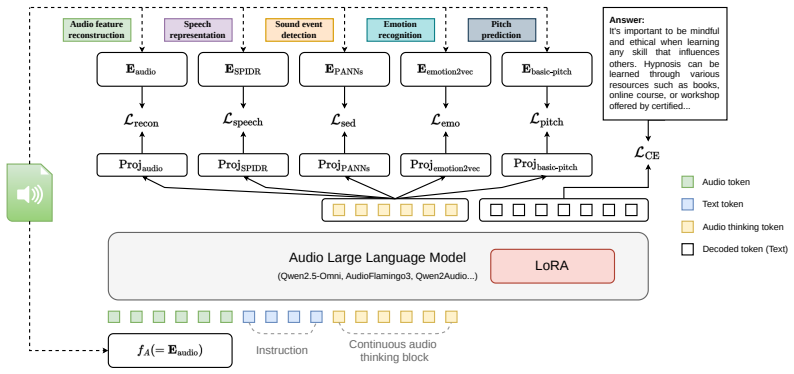
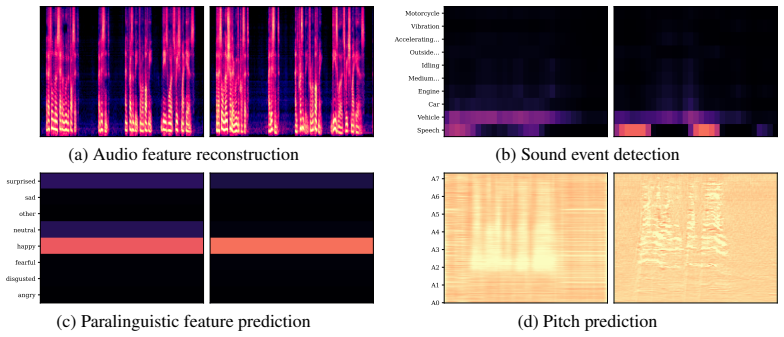
The paper introduces Continuous Audio Thinking (CoAT), a framework that equips large audio language models with a continuous latent workspace for organizing acoustic information prior to response generation. This workspace is grounded by distillation from audio experts, allowing the model to utilize rich acoustic details when generating responses. The continuous thinking block can be processed in a single prefill, incurring no additional autoregressive decoding cost over the baseline. Experiments on three LALMs demonstrate gains across a suite of benchmarks, and analysis shows the supervision propagates to textual responses.
What carries the argument
The continuous latent workspace that organizes acoustic information from expert distillation before text generation.
If this is right
- Performance improves on audio reasoning, audio understanding, music classification, speech emotion, and speech transcription tasks.
- The method works across different large audio language models.
- The continuous thinking block adds no extra autoregressive decoding cost compared with the baseline.
- Auxiliary supervision from the distillation reaches the model's final textual responses.
Where Pith is reading between the lines
- The single-prefill design may support extensions to streaming or low-latency audio applications.
- Similar latent workspaces could be tested for retaining non-text features in other modalities such as video.
- The approach might allow smaller models to achieve results previously requiring larger capacity by better retaining input details.
Load-bearing premise
Distillation from audio experts supplies usable acoustic information into the continuous thinking positions without domain mismatch that negates the performance gains.
What would settle it
A controlled run that keeps the continuous workspace but removes the expert distillation and checks whether benchmark gains vanish would test the central claim.
Figures

read the original abstract
Large audio language models (LALMs) have shown impressive capabilities on diverse audio understanding tasks, ranging from speech transcription to music analysis. However, because LALMs are typically trained to produce text-aligned responses, their hidden states are progressively shaped for text generation rather than for preserving acoustic information. As a result, the diverse acoustic content that audio carries, such as phonetic detail, prosody, sound events, affect, and pitch, is lost along the way and difficult to leverage in the response. We introduce Continuous Audio Thinking (CoAT), a framework that equips audio language models with a continuous latent workspace for organizing acoustic information prior to response generation, grounded by distillation from audio experts. Within the thinking space, the model can utilize the rich acoustic information provided by expert distillation when generating its response. Furthermore, the proposed continuous thinking block can be processed in a single prefill, so CoAT does not require additional autoregressive decoding cost over the baseline. Across three LALMs, Qwen2-Audio, Qwen2.5-Omni-7B, and Audio Flamingo~3, performance gains on a broad benchmark suite spanning audio reasoning, audio understanding, music classification, speech emotion, and speech transcription demonstrate the effectiveness of CoAT. Further analysis confirms that the auxiliary supervision propagates from the thinking positions to the model's textual responses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Continuous Audio Thinking (CoAT) for large audio language models (LALMs). It adds a continuous latent workspace (thinking space) that organizes acoustic information (phonetic detail, prosody, affect, etc.) prior to text response generation; this workspace is populated via distillation from audio expert models and processed in a single prefill pass. The design is claimed to incur no extra autoregressive decoding cost over the baseline LALM. Experiments across Qwen2-Audio, Qwen2.5-Omni-7B, and Audio Flamingo 3 report gains on a suite of benchmarks covering audio reasoning, audio understanding, music classification, speech emotion recognition, and speech transcription; further analysis is said to confirm that the auxiliary supervision propagates from the thinking positions into the final textual outputs.
Significance. If the distillation successfully transfers usable acoustic structure into the latent workspace without domain mismatch or post-hoc tuning that inflates the gains, CoAT would offer an efficient mechanism for preserving non-text-aligned acoustic information inside LALMs. The single-prefill constraint is a concrete efficiency advantage. The breadth of the benchmark suite and the explicit propagation analysis are positive features that would make the result falsifiable and reproducible if the experimental details are complete.
major comments (2)
- [Abstract (final sentence) and the 'further analysis' paragraph] The central claim that expert distillation populates the continuous thinking positions with usable acoustic information (phonetic, prosody, affect) that then propagates to improve textual responses rests on the assumption of clean transfer without domain mismatch. The abstract asserts this propagation but provides no quantitative evidence (e.g., alignment metrics between expert and LALM latent spaces or ablation removing distillation while retaining the thinking block) that would rule out gains arising from added capacity or training rather than preserved acoustics.
- [Method description of the thinking block and prefill procedure] The single-prefill design is presented as incurring no additional autoregressive cost, yet the integration of the continuous thinking block with the existing LALM forward pass is not shown to preserve the original text-generation path exactly. Without an explicit statement of how the thinking positions are masked or bypassed during response generation, it is unclear whether the reported efficiency holds or whether hidden extra computation is introduced.
minor comments (2)
- [Abstract] The abstract lists three specific LALMs but does not state their parameter counts or base training regimes; adding this information would help readers assess the generality of the gains.
- [Method] Notation for the continuous latent workspace (e.g., how the thinking positions are indexed or concatenated with audio tokens) should be introduced with a small diagram or equation in the method section to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of evidence and clarify the implementation details.
read point-by-point responses
-
Referee: [Abstract (final sentence) and the 'further analysis' paragraph] The central claim that expert distillation populates the continuous thinking positions with usable acoustic information (phonetic, prosody, affect) that then propagates to improve textual responses rests on the assumption of clean transfer without domain mismatch. The abstract asserts this propagation but provides no quantitative evidence (e.g., alignment metrics between expert and LALM latent spaces or ablation removing distillation while retaining the thinking block) that would rule out gains arising from added capacity or training rather than preserved acoustics.
Authors: We agree that the manuscript would benefit from more direct quantitative support for the propagation claim. The existing further analysis links performance gains to the thinking positions but does not include the suggested alignment metrics or the specific ablation that isolates distillation from the added block. We will add both: (1) an ablation that retains the thinking block architecture while removing the expert distillation objective, and (2) alignment metrics (e.g., cosine similarity or CCA) between expert representations and the LALM thinking-space activations. These additions will be reported in a revised analysis section. revision: yes
-
Referee: [Method description of the thinking block and prefill procedure] The single-prefill design is presented as incurring no additional autoregressive cost, yet the integration of the continuous thinking block with the existing LALM forward pass is not shown to preserve the original text-generation path exactly. Without an explicit statement of how the thinking positions are masked or bypassed during response generation, it is unclear whether the reported efficiency holds or whether hidden extra computation is introduced.
Authors: We accept that an explicit description of the masking and integration is required. The current method text states that the thinking block is processed in a single prefill but does not detail how its outputs are isolated from the autoregressive loop. We will revise the method section to include a precise account of the forward pass, specifying that thinking positions receive a single prefill computation whose hidden states serve as fixed additional context, with causal masking that excludes them from subsequent token prediction. We will also add pseudocode and a diagram illustrating that the autoregressive decoding path remains unchanged from the baseline. revision: yes
Circularity Check
No circularity detected; CoAT is an independent architectural addition
full rationale
The paper presents CoAT as a new framework that adds a continuous latent workspace to LALMs, populated via distillation from external audio experts, with single-prefill processing and empirical gains on benchmarks. No equations, self-definitional reductions, fitted-input predictions, or load-bearing self-citations appear in the abstract or described method. The central claim rests on the independent effectiveness of the added thinking block and distillation transfer, not on any derivation that reduces to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Distillation from audio experts can ground a continuous latent workspace without domain shift or loss of acoustic fidelity.
- domain assumption Processing the continuous thinking block in a single prefill preserves all benefits without additional autoregressive cost.
invented entities (1)
-
continuous latent workspace (thinking space)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tyers, and Gregor Weber
Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber. Common voice: A massively-multilingual speech corpus, 2020
2020
-
[2]
wav2vec 2.0: A framework for self-supervised learning of speech representations.Advances in neural information processing systems, 33:12449–12460, 2020
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations.Advances in neural information processing systems, 33:12449–12460, 2020
2020
-
[3]
Bittner, Juan José Bosch, David Rubinstein, Gabriel Meseguer-Brocal, and Sebastian Ewert
Rachel M. Bittner, Juan José Bosch, David Rubinstein, Gabriel Meseguer-Brocal, and Sebastian Ewert. A lightweight instrument-agnostic model for polyphonic note transcription and multipitch estimation. InProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, 2022
2022
-
[4]
Iemocap: Interactive emotional dyadic motion capture database.Language resources and evaluation, 42(4):335–359, 2008
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. Iemocap: Interactive emotional dyadic motion capture database.Language resources and evaluation, 42(4):335–359, 2008
2008
-
[5]
Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, et al. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio.arXiv preprint arXiv:2106.06909, 2021
arXiv 2021
-
[6]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre- training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
2022
-
[7]
Beats: Audio pre-training with acoustic tokenizers
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Wanxiang Che, Xiangzhan Yu, and Furu Wei. Beats: Audio pre-training with acoustic tokenizers. In International Conference on Machine Learning, pages 5178–5193. PMLR, 2023
2023
-
[8]
Eat: self-supervised pre-training with efficient audio transformer
Wenxi Chen, Yuzhe Liang, Ziyang Ma, Zhisheng Zheng, and Xie Chen. Eat: self-supervised pre-training with efficient audio transformer. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 3807–3815, 2024
2024
-
[9]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuan- jun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024
Pith/arXiv arXiv 2024
-
[10]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023
Pith/arXiv arXiv 2023
-
[11]
High fidelity neural audio compression.arXiv preprint arXiv:2210.13438, 2022
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression.arXiv preprint arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[12]
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step.arXiv preprint arXiv:2405.14838, 2024
Pith/arXiv arXiv 2024
-
[13]
Pengi: An audio language model for audio tasks.Advances in Neural Information Processing Systems, 36:18090– 18108, 2023
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. Pengi: An audio language model for audio tasks.Advances in Neural Information Processing Systems, 36:18090– 18108, 2023
2023
-
[14]
Clotho: An audio captioning dataset
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 736–740. IEEE, 2020
2020
-
[15]
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities.arXiv preprint arXiv:2503.03983, 2025. 10
arXiv 2025
-
[16]
Gama: A large audio-language model with advanced audio understanding and complex reasoning abilities
Sreyan Ghosh, Sonal Kumar, Ashish Seth, Chandra Kiran Reddy Evuru, Utkarsh Tyagi, S Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha. Gama: A large audio-language model with advanced audio understanding and complex reasoning abilities. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6288–6313, 2024
2024
-
[17]
Looped transformers as programmable computers
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. InInternational Conference on Machine Learning, pages 11398–11442. PMLR, 2023
2023
-
[18]
Switchboard: Telephone speech corpus for research and development
John J Godfrey, Edward C Holliman, and Jane McDaniel. Switchboard: Telephone speech corpus for research and development. In[Proceedings] ICASSP-92: 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, volume 1, pages 517–520. IEEE, 1992
1992
-
[19]
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao- Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, et al. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models.arXiv preprint arXiv:2507.08128, 2025
Pith/arXiv arXiv 2025
-
[20]
Listen, think, and understand.arXiv preprint arXiv:2305.10790, 2023
Yuan Gong, Hongyin Luo, Alexander H Liu, Leonid Karlinsky, and James Glass. Listen, think, and understand.arXiv preprint arXiv:2305.10790, 2023
arXiv 2023
-
[21]
V ocalsound: A dataset for improving human vocal sounds recognition
Yuan Gong, Jin Yu, and James Glass. V ocalsound: A dataset for improving human vocal sounds recognition. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 151–155. IEEE, 2022
2022
-
[22]
Onellm: One framework to align all modalities with language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xiangyu Yue. Onellm: One framework to align all modalities with language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26584–26595, 2024
2024
-
[23]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
Pith/arXiv arXiv 2024
-
[24]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM transactions on audio, speech, and language processing, 29:3451–3460, 2021
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM transactions on audio, speech, and language processing, 29:3451–3460, 2021
2021
-
[25]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[26]
Masked autoencoders that listen.Advances in neural information processing systems, 35:28708–28720, 2022
Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, and Christoph Feichtenhofer. Masked autoencoders that listen.Advances in neural information processing systems, 35:28708–28720, 2022
2022
-
[27]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models, 2024
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models, 2024
2024
-
[28]
Audiocaps: Generat- ing captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generat- ing captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 119–132, 2019
2019
-
[29]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[30]
Panns: Large-scale pretrained audio neural networks for audio pattern recognition.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:2880–2894, 2020
Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, and Mark D Plumbley. Panns: Large-scale pretrained audio neural networks for audio pattern recognition.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:2880–2894, 2020. 11
2020
-
[31]
Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities. arXiv preprint arXiv:2402.01831, 2024
arXiv 2024
-
[32]
Clotho-aqa: A crowdsourced dataset for audio question answering
Samuel Lipping, Parthasaarathy Sudarsanam, Konstantinos Drossos, and Tuomas Virtanen. Clotho-aqa: A crowdsourced dataset for audio question answering. In2022 30th European Signal Processing Conference (EUSIPCO), pages 1140–1144. IEEE, 2022
2022
-
[33]
Music understand- ing llama: Advancing text-to-music generation with question answering and captioning
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, and Ying Shan. Music understand- ing llama: Advancing text-to-music generation with question answering and captioning. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 286–290. IEEE, 2024
2024
-
[34]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, et al. Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix.arXiv preprint arXiv:2505.13032, 2025
arXiv 2025
-
[35]
emotion2vec: Self-supervised pre-training for speech emotion representation
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, Shiliang Zhang, and Xie Chen. emotion2vec: Self-supervised pre-training for speech emotion representation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 15747–15760, 2024
2024
-
[36]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization, 2024
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, and Soujanya Poria. Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization, 2024
2024
-
[37]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:3339–3354, 2024
2024
-
[38]
Mustango: Toward controllable text-to-music generation
Jan Melechovsky, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, and Soujanya Poria. Mustango: Toward controllable text-to-music generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8286–8309, 2024
2024
-
[39]
O’Neill, Vitaly Lavrukhin, Somshubra Majumdar, Vahid Noroozi, Yuekai Zhang, Oleksii Kuchaiev, Jagadeesh Balam, Yuliya Dovzhenko, Keenan Freyberg, Michael D
Patrick K. O’Neill, Vitaly Lavrukhin, Somshubra Majumdar, Vahid Noroozi, Yuekai Zhang, Oleksii Kuchaiev, Jagadeesh Balam, Yuliya Dovzhenko, Keenan Freyberg, Michael D. Shulman, Boris Ginsburg, Shinji Watanabe, and Georg Kucsko. Spgispeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition, 2021
2021
-
[40]
Librispeech: an asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015
2015
-
[41]
Spidr: Learning fast and stable linguistic units for spoken language models without supervision
Maxime Poli, Mahi Luthra, Youssef Benchekroun, Yosuke Higuchi, Martin Gleize, Jiayi Shen, Robin Algayres, Yu-An Chung, Mido Assran, Juan Pino, and Emmanuel Dupoux. Spidr: Learning fast and stable linguistic units for spoken language models without supervision. Transactions on Machine Learning Research, 2025
2025
-
[42]
Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 527–536, 2019
2019
-
[43]
Yiming Qin, Bomin Wei, Jiaxin Ge, Konstantinos Kallidromitis, Stephanie Fu, Trevor Darrell, and XuDong Wang. Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens.arXiv preprint arXiv:2511.19418, 2025
arXiv 2025
-
[44]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine Mcleavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Andreas Krause, Emma Brun- skill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Pro- ceedings of the 40th International Conference on Machine Learning, volume 202 ofPro...
2023
-
[45]
Mmau: A massive multi-task audio understanding and reasoning benchmark, 2024
S Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark, 2024
2024
-
[46]
Min-Han Shih, Ho-Lam Chung, Yu-Chi Pai, Ming-Hao Hsu, Guan-Ting Lin, Shang-Wen Li, and Hung-yi Lee. Gsqa: An end-to-end model for generative spoken question answering.arXiv preprint arXiv:2312.09781, 2023
arXiv 2023
-
[47]
Llasm: Large language and speech model.arXiv preprint arXiv:2308.15930, 2023
Yu Shu, Siwei Dong, Guangyao Chen, Wenhao Huang, Ruihua Zhang, Daochen Shi, Qiqi Xiang, and Yemin Shi. Llasm: Large language and speech model.arXiv preprint arXiv:2308.15930, 2023
arXiv 2023
-
[48]
Bob L Sturm. The gtzan dataset: Its contents, its faults, their effects on evaluation, and its future use.arXiv preprint arXiv:1306.1461, 2013
Pith/arXiv arXiv 2013
-
[49]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models.arXiv preprint arXiv:2310.13289, 2023
Pith/arXiv arXiv 2023
-
[50]
V oxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation, 2021
Changhan Wang, Morgane Rivière, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux. V oxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation, 2021
2021
-
[51]
Dingdong Wang, Jincenzi Wu, Junan Li, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark.arXiv preprint arXiv:2506.04779, 2025
Pith/arXiv arXiv 2025
-
[52]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[53]
Muchomusic: Evaluating music understanding in multimodal audio-language models
Benno Weck, Ilaria Manco, Emmanouil Benetos, Elio Quinton, György Fazekas, and Dmitry Bogdanov. Muchomusic: Evaluating music understanding in multimodal audio-language models. InProceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR), 2024
2024
-
[54]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[55]
Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025
Pith/arXiv arXiv 2025
-
[56]
Air-bench: Benchmarking large audio-language models via generative comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, et al. Air-bench: Benchmarking large audio-language models via generative comprehension. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1979–1998, 2024
1979
-
[57]
Mert: Acoustic music understanding model with large-scale self-supervised training
LI Yizhi, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Chenghao Xiao, Chenghua Lin, Anton Ragni, Emmanouil Benetos, et al. Mert: Acoustic music understanding model with large-scale self-supervised training. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[58]
Soundstream: An end-to-end neural audio codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021
2021
-
[59]
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629, 2024. 13
Pith/arXiv arXiv 2024
-
[60]
Anygpt: Unified multimodal llm with discrete sequence modeling
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, et al. Anygpt: Unified multimodal llm with discrete sequence modeling. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9637–9662, 2024
2024
-
[61]
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Reality check on the evaluation of large multimodal models.arXiv preprint arXiv:2407.12772, 2024
Pith/arXiv arXiv 2024
-
[62]
Speaking clearly: A simplified whisper-based codec for low-bitrate speech coding
Xin Zhang, Lin Li, Xiangni Lu, Jianquan Liu, and Kong Aik Lee. Speaking clearly: A simplified whisper-based codec for low-bitrate speech coding. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17037–17041. IEEE, 2026
2026
-
[63]
The reference answer is[XXX], while the model’s answer is[YYY]. I think
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yu Wang, and Yanfeng Wang. Librisqa: A novel dataset and framework for spoken question answering with large language models.IEEE Transactions on Artificial Intelligence, 2024. 14 Table A: Audio expert encoders used in CoAT.ek is the expert embedding dimension and rk is the frame rate at which the expert emits features...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.