Pinpoint: Grounded Worldwide Image Geolocation via Cross-Source Retrieval and Reranking
Pith reviewed 2026-06-28 10:41 UTC · model grok-4.3
The pith
Pinpoint trains one contrastive embedder on Flickr photos plus street-view images, then reranks candidates with attention over cross-source evidence to geolocate photos worldwide.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A contrastive image-GPS embedder trained jointly on Flickr photos and street-view imagery produces candidate locations whose accuracy is improved by an attention reranker that incorporates cross-source evidence from nearby sites, delivering state-of-the-art results on both internet-photo and street-view benchmarks.
What carries the argument
The contrastive image-GPS embedder that learns a shared embedding space from mixed sources, followed by the attention-based reranker that combines candidate visual and GPS features with cross-source signals.
If this is right
- Geolocation of ordinary user photos and dense street-view imagery can be handled inside one model instead of separate pipelines.
- Inference runs faster and more reproducibly than approaches that depend on multimodal large-language models.
- Cross-source evidence from nearby locations supplies grounding that single-source retrieval lacks.
Where Pith is reading between the lines
- The same retrieve-and-rerank pattern could be tested on other ambiguous visual tasks such as instance-level recognition or temporal event localization.
- If the shared embedding space generalizes, adding additional image sources might further reduce the need for task-specific models.
Load-bearing premise
Training one embedder on the combined Flickr and street-view data creates a single space whose initial retrievals can be reliably improved by the reranker that uses cross-source evidence.
What would settle it
On a held-out worldwide benchmark, the full Pinpoint pipeline shows no accuracy gain over the embedder alone or over prior single-source methods.
Figures
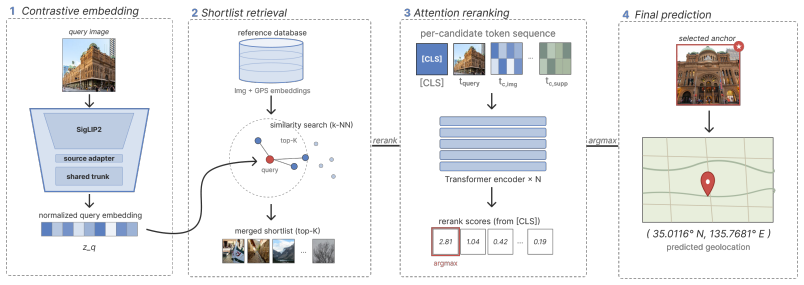
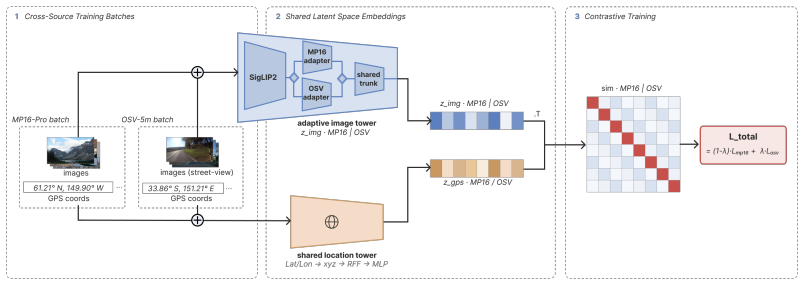
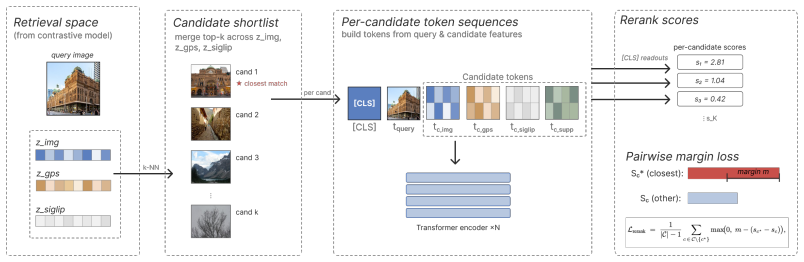
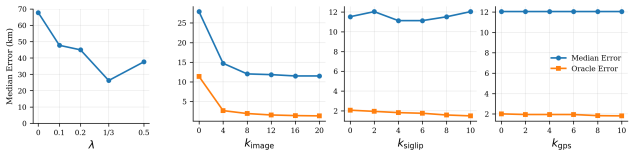


read the original abstract
Image geolocation aims to estimate where a photograph was taken from its visual content. At worldwide scale, this remains challenging because visual evidence is often ambiguous, diverse, and unevenly distributed. Prior work has typically treated geolocation of ordinary internet photos and street-view imagery as separate tasks, despite their complementary strengths: internet photos better match the appearance distribution of user-captured queries, while street-view imagery provides denser, geographically grounded coverage. We present Pinpoint, a retrieve-and-rerank architecture that combines both sources in a coarse-to-fine pipeline. A contrastive image-GPS embedder is trained on both user-uploaded Flickr photos and street-view imagery, learning a shared image-GPS embedding space that is used to retrieve candidate locations. An attention-based reranker then rescores retrieved candidates by combining candidate-level visual and GPS features with cross-source evidence from nearby locations to ground the prediction. Unlike recent prior work, Pinpoint does not rely on multimodal large-language models, making inference faster and more reproducible. Pinpoint achieves state-of-the-art results across all metrics on standard benchmarks for internet photos (IM2GPS3k and YFCC4k) and street-view imagery (OSV-5M).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Pinpoint, a retrieve-and-rerank architecture for worldwide image geolocation. It trains a single contrastive image-GPS embedder on the union of Flickr photos and street-view imagery to learn a shared embedding space for retrieving candidate locations, then applies an attention-based reranker that incorporates candidate-level visual/GPS features and cross-source evidence from nearby locations. The work claims state-of-the-art results across all metrics on IM2GPS3k and YFCC4k (internet photos) and OSV-5M (street-view imagery) without relying on multimodal large language models.
Significance. If the central claims hold, the result would be significant for demonstrating that a shared embedding space can effectively fuse complementary data sources (casual internet photos and dense street-view) in a coarse-to-fine pipeline, yielding reproducible gains over prior single-source or LLM-based methods while maintaining faster inference.
major comments (2)
- [Abstract] Abstract: the claim that Pinpoint 'achieves state-of-the-art results across all metrics' on the three named benchmarks supplies no experimental protocol, ablation results, error bars, or dataset statistics, preventing evaluation of the data-to-claim link.
- [Abstract] The central architectural assumption—that training one contrastive embedder on the mixed Flickr + street-view corpus produces a shared space whose top candidates can be reliably improved by the attention reranker—lacks supporting evidence such as per-source recall@K, embedding alignment metrics (e.g., cosine similarity distributions across sources), or source-specific ablations; without these, the reranker's effectiveness cannot be assessed given the visual mismatch between sources.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for clearer supporting evidence. We address each comment below and will revise the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Pinpoint 'achieves state-of-the-art results across all metrics' on the three named benchmarks supplies no experimental protocol, ablation results, error bars, or dataset statistics, preventing evaluation of the data-to-claim link.
Authors: We agree the abstract is high-level and omits these specifics. The full manuscript details the experimental protocol (Section 4), reports results with standard metrics and comparisons on IM2GPS3k, YFCC4k, and OSV-5M (Section 5), includes ablation studies (Section 5.3), and provides dataset statistics (Section 3). To improve the abstract-to-claim link, we will revise the abstract to briefly note the evaluation benchmarks and direct readers to the results section for protocols, ablations, and statistics. revision: yes
-
Referee: [Abstract] The central architectural assumption—that training one contrastive embedder on the mixed Flickr + street-view corpus produces a shared space whose top candidates can be reliably improved by the attention reranker—lacks supporting evidence such as per-source recall@K, embedding alignment metrics (e.g., cosine similarity distributions across sources), or source-specific ablations; without these, the reranker's effectiveness cannot be assessed given the visual mismatch between sources.
Authors: The manuscript supports the shared embedding via overall SOTA gains over single-source methods on both photo and street-view benchmarks, plus the reranker's cross-source attention design. However, we acknowledge the referee's point on the need for finer-grained validation of the mixed training assumption. In revision, we will add per-source recall@K, embedding alignment metrics (intra-/inter-source cosine distributions), and source-specific ablations to explicitly demonstrate the shared space and reranker benefits despite visual differences. revision: yes
Circularity Check
No circularity: empirical pipeline with no derivations or self-referential reductions
full rationale
The paper describes a standard contrastive training plus reranking pipeline on combined Flickr and street-view data, with SOTA claims resting on benchmark evaluations (IM2GPS3k, YFCC4k, OSV-5M). No equations, parameter-fitting steps presented as predictions, uniqueness theorems, or self-citations appear in the provided text. The architecture is self-contained against external benchmarks and does not reduce any central claim to a definitional identity or fitted input renamed as output.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Constantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao Xu, Hongyu Zhou, and Loïc Landrieu. Openstreetview-5m: The many roads to global visual geolocation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattl...
-
[2]
Enhancing contrastive learning for geolocalization by discovering hard negatives on semivari- ograms
Boyi Chen, Zhangyu Wang, Fabian Deuser, Johann Maximilian Zollner, and Martin Werner. Enhancing contrastive learning for geolocalization by discovering hard negatives on semivari- ograms. In Mohamed F. Mokbel, Shashi Shekar, Andreas Züfle, Yao-Yi Chiang, Maria Luisa Damiani, and Moustafa A. Youssef, editors,Proceedings of the 33rd ACM International Confer...
-
[3]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Brandon Clark, Alec Kerrigan, Parth Parag Kulkarni, Vicente Vivanco Cepeda, and Mubarak Shah. Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 23182–23190. IEEE, 2023....
-
[4]
Nicolas Dufour, Vicky Kalogeiton, David Picard, and Loïc Landrieu. Around the world in 80 timesteps: A generative approach to global visual geolocation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 23016–23026. Computer Vi- sion Foundation / IEEE, 2025. doi: 10.1109/CVPR52734.2025...
-
[5]
Hierloc: Hyperbolic entity embeddings for hierarchical visual geolocation
Hari Krishna Gadi, Daniel Matos, Hongyi Luo, Lu Liu, Yongliang Wang, Yanfeng Zhang, and Liqiu Meng. Hierloc: Hyperbolic entity embeddings for hierarchical visual geolocation. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=d5GmZP2qrd
2026
-
[6]
Lukas Haas, Michal Skreta, Silas Alberti, and Chelsea Finn. PIGEON: predicting image geolocations. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 12893–12902. IEEE, 2024. doi: 10.1109/ CVPR52733.2024.01225. URLhttps://doi.org/10.1109/CVPR52733.2024.01225
-
[7]
James Hays and Alexei A. Efros. IM2GPS: estimating geographic information from a single image. In2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008), 24-26 June 2008, Anchorage, Alaska, USA. IEEE Computer Society, 2008. doi: 10.1109/CVPR.2008.4587784. URLhttps://doi.org/10.1109/CVPR.2008.4587784
-
[8]
Pengyue Jia, Yiding Liu, Xiaopeng Li, Yuhao Wang, Yantong Du, Xiao Han, Xuetao Wei, Shuaiqiang Wang, Dawei Yin, and Xiangyu Zhao. G3: An effective and adaptive framework for worldwide geolocalization using large multi-modality models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Informati...
-
[9]
Georanker: Distance- aware ranking for worldwide image geolocalization
Pengyue Jia, Seongheon Park, Song Gao, Xiangyu Zhao, and Sharon Li. Georanker: Distance- aware ranking for worldwide image geolocalization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= Zjq1CkKDGt
2026
-
[10]
Recognition through reasoning: Reinforcing image geo-localization with large vision-language models
Ling Li, Yao Zhou, Yuxuan Liang, Fugee Tsung, and Jiaheng Wei. Recognition through reasoning: Reinforcing image geo-localization with large vision-language models. InThe 10 Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id=wuMdBGMe3y
2026
-
[12]
URLhttp://arxiv.org/abs/1901.04085
Pith/arXiv arXiv 1901
-
[13]
Where in the world is this image? transformer-based geo-localization in the wild
Shraman Pramanick, Ewa Magdalena Nowara, Joshua Gleason, Carlos Domingo Castillo, and Rama Chellappa. Where in the world is this image? transformer-based geo-localization in the wild. In Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Isr...
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
2021
-
[15]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In John C. Platt, Daphne Koller, Yoram Singer, and Sam T. Roweis, editors,Advances in Neural Infor- mation Processing Systems 20, Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, December 3-6, 2007...
2007
-
[16]
Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps
Paul Hongsuck Seo, Tobias Weyand, Jack Sim, and Bohyung Han. Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors,Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part X, Lecture Notes in...
-
[17]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
Pith/arXiv arXiv 2025
-
[18]
KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
Fuwen Tan, Jiangbo Yuan, and Vicente Ordonez. Instance-level image retrieval using reranking transformers. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 12085–12095. IEEE, 2021. doi: 10.1109/ ICCV48922.2021.01189. URLhttps://doi.org/10.1109/ICCV48922.2021.01189
-
[19]
Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li
Bart Thomee, David A. Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. YFCC100M: the new data in multimedia research.Commun. ACM, 59(2):64–73, 2016. doi: 10.1145/2812802. URLhttps://doi.org/10.1145/2812802
-
[20]
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multi- lingual vision-language encoders with improved semantic understanding, localization, and dense feat...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[21]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman 11 Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Confere...
2017
-
[22]
Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8690–8701. Curran Associates, Inc., 2023. U...
2023
-
[24]
GRE suite: Geo-localization inference via fine-tuned vision-language models and enhanced reasoning chains
Chun Wang, Xiaojun Ye, Xiaoran Pan, Zihao Pan, Haofan Wang, and Yiren Song. GRE suite: Geo-localization inference via fine-tuned vision-language models and enhanced reasoning chains. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[25]
URLhttps://openreview.net/forum?id=4H3xG3aDS1
-
[26]
Locdiff: Identifying locations on earth by diffusing in the hilbert space
Zhangyu Wang, Zeping Liu, Jielu Zhang, Zhongliang Zhou, Qian Cao, Nemin Wu, Lan Mu, Yang Song, Yiqun Xie, Ni Lao, and Gengchen Mai. Locdiff: Identifying locations on earth by diffusing in the hilbert space. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=ghybX0Qlls
2026
-
[27]
Planet - photo geolocation with con- volutional neural networks
Tobias Weyand, Ilya Kostrikov, and James Philbin. Planet - photo geolocation with con- volutional neural networks. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII, Lecture Notes in Computer Sci- ence, pages 37–5...
-
[28]
In: IEEE/CVF International Conference on Computer Vision (ICCV), pp
Scott Workman, Richard Souvenir, and Nathan Jacobs. Wide-area image geolocalization with aerial reference imagery. In2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015, pages 3961–3969. IEEE Computer Society, 2015. doi: 10.1109/ICCV .2015.451. URLhttps://doi.org/10.1109/ICCV.2015.451
-
[29]
doi: 10.1109/ICCV51070.2023.00649
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 11941–11952. IEEE, 2023. doi: 10.1109/ ICCV51070.2023.01100. URLhttps://doi.org/10.1109/ICCV51070.2023.01100
-
[30]
Zhongliang Zhou, Jielu Zhang, Zihan Guan, Mengxuan Hu, Ni Lao, Lan Mu, Sheng Li, and Gengchen Mai. Img2loc: Revisiting image geolocalization using multi-modality foundation models and image-based retrieval-augmented generation. In Grace Hui Yang, Hongning Wang, Sam Han, Claudia Hauff, Guido Zuccon, and Yi Zhang, editors,Proceedings of the 47th Internation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.