InvestPhilBench: A Multi-Layer Dynamic Benchmark for Evaluating Large Language Model Procedural Reasoning in Expert Investment Philosophy
Pith reviewed 2026-06-25 19:49 UTC · model grok-4.3
The pith
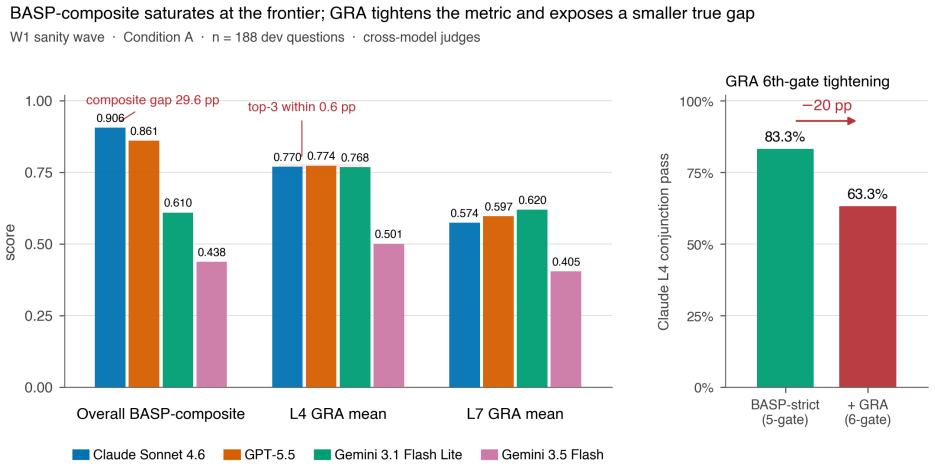
Frontier LLMs reach 0.93 on investment benchmark composites but only 0.77 on procedural gate accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
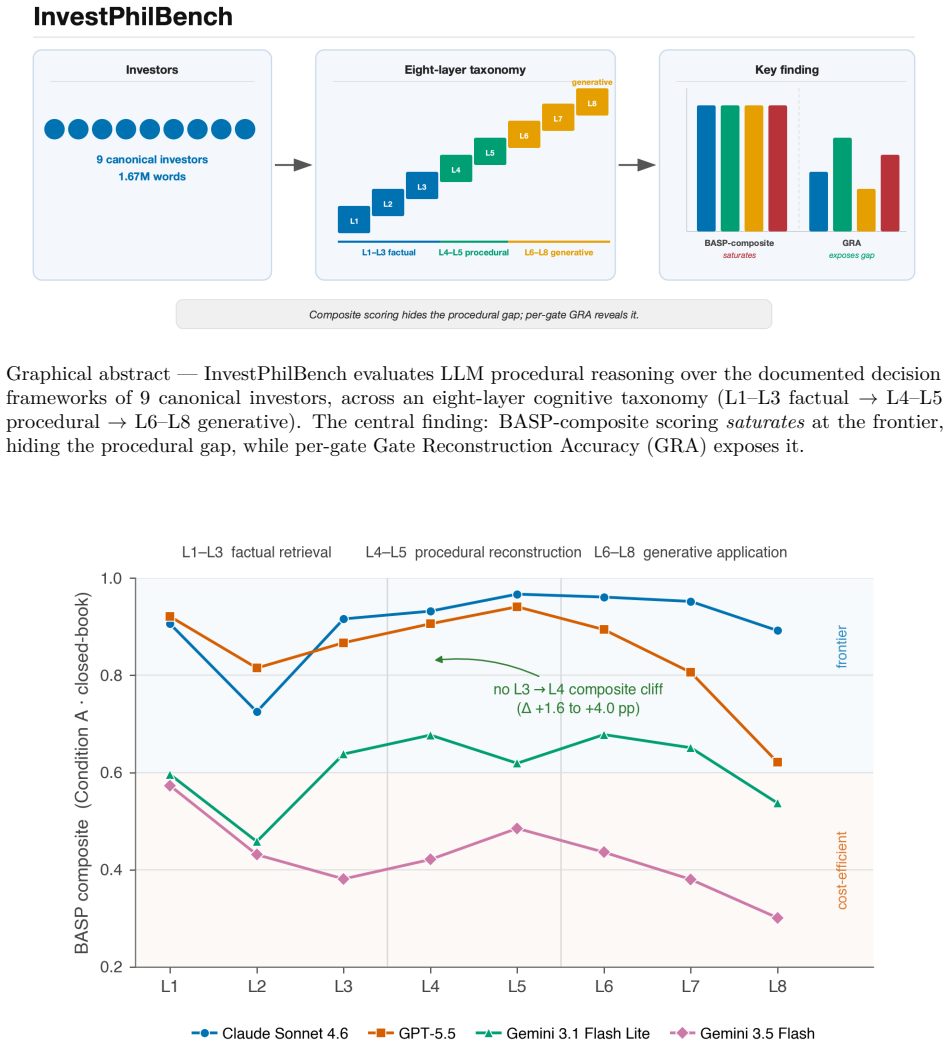
The BASP composite saturates at the frontier (Claude L4 = 0.932) while GRA still exposes a procedural deficit (frontier L4 GRA approx. 0.77, L7 GRA 0.57-0.62) — composite scoring rewards fluent prose and hides the procedural gap.
What carries the argument
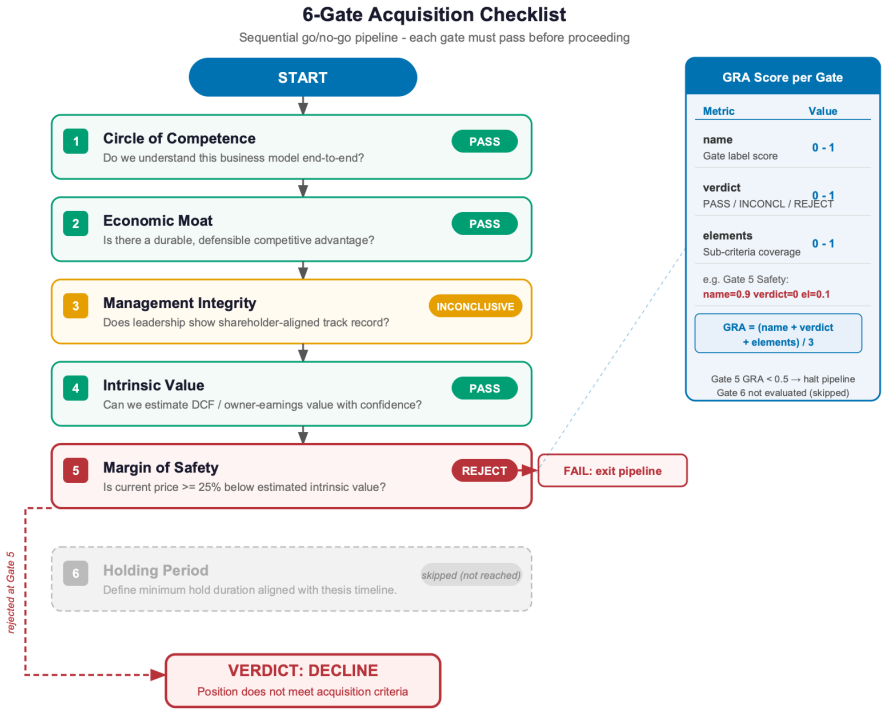
Gate Reconstruction Accuracy (GRA), a per-gate metric for questions supplied with gold reasoning programs, that directly scores whether model outputs preserve the topology and gates of the expert decision framework.
If this is right
- Composite metrics alone are insufficient for evaluating procedural reasoning in expert domains.
- GRA provides a more sensitive signal of whether models follow explicit decision topologies.
- The multi-layer structure from L1 principle identification to L8 novel extrapolation is required to surface the full range of deficits.
- Automated BASP tracks human judgment closely enough for scalable evaluation once de-confounded conditions are applied.
- Failure-mode detection runs at usable sensitivity but requires calibration to reduce over-flagging.
Where Pith is reading between the lines
- Similar composite-versus-procedural gaps are likely to appear in other domains that use explicit decision frameworks, such as medical diagnosis or legal reasoning.
- Models trained with explicit topology metadata during fine-tuning could close the GRA gap without changing overall fluency.
- Extending the benchmark to include real-time market data retrieval would test whether the procedural deficit persists under dynamic conditions.
Load-bearing premise
The 100-item expert-annotated gold set together with the five BASP metrics and the six failure-mode rules accurately measure the intended procedural decision frameworks without substantial bias from chosen principles or topologies.
What would settle it
Run GRA on a new set of model outputs that have been independently rated by the same expert annotators for correct execution of each gold reasoning-program gate; if the correlation between GRA and human gate-level correctness falls below 0.6 the metric does not capture the claimed procedural fidelity.
Figures
read the original abstract
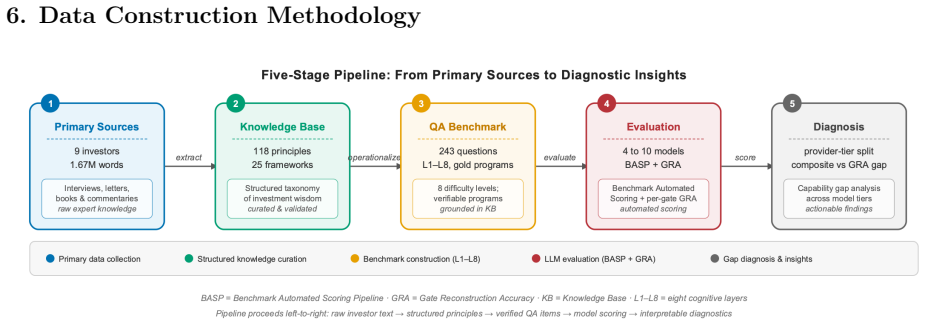
Large language models are increasingly deployed as investment research assistants, yet no benchmark tests whether they can accurately reconstruct and apply the specific procedural decision frameworks of expert investors. We introduce InvestPhilBench, a multi-layer dynamic benchmark spanning eight cognitive tiers, from principle identification (L1) to novel framework extrapolation (L8). The v0.6 release comprises 118 primary-source-verified investment principle cards, 25 decision framework cards with explicit topology metadata, and 243 QA questions (197 dev / 46 held-out test). For reproducible scoring at scale we introduce the Benchmark Automated Scoring Pipeline (BASP) -- five algorithmic metrics (OGRS, KCCS, SAP@k, IVP, CKCA) -- the Failure Mode Detection Protocol (FMDP) with computable rules for six failure modes, and Gate Reconstruction Accuracy (GRA), a per-gate metric for questions with gold reasoning programs. In this release, InvestPhilBench is primarily a benchmark-and-methodology contribution. A four-model sanity wave on the 188-question development split shows a sharp provider-tier split (BASP 0.906 vs. 0.438); these mixed-judge numbers are confounded upper bounds. The central finding: the BASP composite saturates at the frontier (Claude L4 = 0.932) while GRA still exposes a procedural deficit (frontier L4 GRA approx. 0.77, L7 GRA 0.57-0.62) -- composite scoring rewards fluent prose and hides the procedural gap. v0.6 implements a unified judge and true model-in-the-loop retrieval/oracle conditions; the de-confounded multi-model leaderboard and full three-condition run are v1.0 deliverables. On a 100-item expert-annotated gold set the automated BASP composite tracks the human reference at Pearson r = 0.72 (MAE = 0.10), with attribution (SAP@3) the weakest sub-metric and the failure-mode detector running sensitive-but-over-flagging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InvestPhilBench, a multi-layer dynamic benchmark for LLM procedural reasoning in expert investment philosophy, comprising 118 principle cards, 25 decision framework cards, and 243 QA questions. It defines BASP (five algorithmic metrics: OGRS, KCCS, SAP@k, IVP, CKCA), FMDP for failure modes, and GRA for per-gate accuracy on gold reasoning programs. A four-model sanity check on the 188-question dev split reports BASP saturation at the frontier (Claude L4 = 0.932) contrasted with lower GRA scores (L4 ~0.77, L7 0.57-0.62), while BASP correlates at Pearson r=0.72 with human judgment on a 100-item expert gold set.
Significance. If the GRA metric and its contrast with BASP hold after validation, the work would usefully demonstrate that composite fluency-based scores can mask deficits in reconstructing expert procedural topologies, offering a targeted evaluation tool for AI in specialized decision domains. The primary-source verification and automated pipeline elements support reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that 'the BASP composite saturates at the frontier while GRA still exposes a procedural deficit' rests on GRA values (L4 approx. 0.77, L7 0.57-0.62) for which no human correlation, inter-annotator agreement, or expert validation is reported, unlike the BASP composite (r=0.72 on the 100-item gold set). Without this, the asserted saturation-vs-deficit contrast lacks support.
- [Abstract] Abstract: It is unspecified how many of the 188 dev questions possess gold reasoning programs, so the GRA results could derive from a small or non-representative subset; this detail is load-bearing for interpreting the procedural gap finding.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on the abstract. Both points identify gaps in the current reporting of GRA that weaken the central claim. We address each below and commit to revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the BASP composite saturates at the frontier while GRA still exposes a procedural deficit' rests on GRA values (L4 approx. 0.77, L7 0.57-0.62) for which no human correlation, inter-annotator agreement, or expert validation is reported, unlike the BASP composite (r=0.72 on the 100-item gold set). Without this, the asserted saturation-vs-deficit contrast lacks support.
Authors: We agree that the manuscript reports human correlation only for BASP and provides no equivalent validation (correlation, IAA, or expert review) for the GRA scores themselves. GRA is computed directly from expert gold programs, but this does not substitute for the validation performed on BASP. We will revise the abstract, methods, and discussion to state the current validation status of GRA explicitly, note it as a limitation relative to BASP, and add any feasible IAA computation on the gold programs. revision: yes
-
Referee: [Abstract] Abstract: It is unspecified how many of the 188 dev questions possess gold reasoning programs, so the GRA results could derive from a small or non-representative subset; this detail is load-bearing for interpreting the procedural gap finding.
Authors: The manuscript does not state the exact number of the 188 dev questions that have gold reasoning programs. Gold programs are linked to the 25 decision framework cards, but the overlap count and representativeness across tiers are not reported. We will add this detail in the revised version, including the precise count and confirmation that the subset covers the benchmark's cognitive tiers. revision: yes
Circularity Check
No significant circularity; metrics defined by explicit rules with external human correlation
full rationale
The paper introduces InvestPhilBench with BASP (OGRS, KCCS, SAP@k, IVP, CKCA), FMDP, and GRA defined via algorithmic rules on principle cards, framework topologies, and gold reasoning programs. BASP composite correlation (Pearson r=0.72) is reported against a separate 100-item expert-annotated gold set, and the development split uses held-out elements. No equations, self-citations, or fitted parameters reduce reported scores or the saturation-vs-deficit claim to inputs by construction. The work is self-contained as a benchmark-and-methodology contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The expert-annotated gold set and defined metrics accurately represent procedural decision frameworks in investment philosophy.
Reference graph
Works this paper leans on
-
[1]
(1983).The Architecture of Cognition
Anderson, J.R. (1983).The Architecture of Cognition. Harvard University Press
1983
-
[2]
& Krathwohl, D.R
Anderson, L.W. & Krathwohl, D.R. (2001).A Taxonomy for Learning, Teaching, and Assessing. Longman
2001
-
[3]
Araci, D. (2019). FinBERT.arXiv:1908.10063
Pith/arXiv arXiv 2019
-
[4]
(1977–2023).Berkshire Hathaway Annual Shareholder Letters
Buffett, W.E. (1977–2023).Berkshire Hathaway Annual Shareholder Letters
1977
-
[5]
(1996).An Owner’s Manual
Buffett, W.E. (1996).An Owner’s Manual. Berkshire Hathaway Inc
1996
-
[6]
(2018–2024).Annual Reports and Investment Framework
Canada Pension Plan Investment Board. (2018–2024).Annual Reports and Investment Framework. 56
2018
-
[7]
(2024).Our Investment Strategy: Total Portfolio Approach and the Factor Lens.CPP Investments
Canada Pension Plan Investment Board. (2024).Our Investment Strategy: Total Portfolio Approach and the Factor Lens.CPP Investments. https://www.cppinvestments.com/the-fund/how-we-invest/
2024
-
[8]
Chen, Z., et al. (2021). FinQA: A Dataset of Numerical Reasoning over Financial Data.EMNLP 2021. [Execution acc: expert 91.16%, FinQANet 61.24%]
2021
-
[9]
(2013).How the Economic Machine Works
Dalio, R. (2013).How the Economic Machine Works. Bridgewater Associates
2013
-
[10]
(2017).Principles: Life and Work
Dalio, R. (2017).Principles: Life and Work. Simon & Schuster
2017
-
[11]
(2018).Principles for Navigating Big Debt Crises
Dalio, R. (2018).Principles for Navigating Big Debt Crises. Bridgewater Associates
2018
-
[12]
(2021).Principles for Dealing with the Changing World Order
Dalio, R. (2021).Principles for Dealing with the Changing World Order. Simon & Schuster
2021
-
[13]
Dong, Y., et al. (2024). Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models.ACL 2024 Findings;arXiv:2402.15938
arXiv 2024
-
[14]
Fabbri, A.R., et al. (2021). SummEval: Re-evaluating Summarization Evaluation.TACL, 9
2021
-
[15]
(1958).Common Stocks and Uncommon Profits
Fisher, P.A. (1958).Common Stocks and Uncommon Profits. Harper & Brothers
1958
-
[16]
(1949/1973).The Intelligent Investor
Graham, B. (1949/1973).The Intelligent Investor. Harper & Row
1949
-
[17]
& Dodd, D
Graham, B. & Dodd, D. (1934).Security Analysis. Whittlesey House
1934
-
[18]
(1997).You Can Be a Stock Market Genius
Greenblatt, J. (1997).You Can Be a Stock Market Genius. Simon & Schuster
1997
-
[19]
Guha, N., et al. (2023). LegalBench.NeurIPS 2023
2023
-
[20]
Hendrycks, D., et al. (2021). MMLU.ICLR 2021
2021
-
[21]
Islam, P., et al. (2023). FinanceBench.arXiv:2311.11944. [10,231Q; GPT-4-Turbo 11% closed-book, ~19% with retrieval]
Pith/arXiv arXiv 2023
-
[22]
Jin, D., et al. (2021). MedQA.Applied Sciences, 11(14)
2021
-
[23]
Kim, A.G., Muhn, M., & Nikolaev, V.V. (2024). Financial Statement Analysis with Large Language Models.University of Chicago Booth Working Paper; SSRN 4762860(arXiv:2407.17866, withdrawn pending data review)
arXiv 2024
-
[24]
(1991).Margin of Safety
Klarman, S.A. (1991).Margin of Safety. HarperCollins
1991
-
[25]
Kojima, T., et al. (2022). Large Language Models are Zero-Shot Reasoners.NeurIPS 2022
2022
-
[26]
Lewis, P., et al. (2020). Retrieval-Augmented Generation.NeurIPS 2020
2020
-
[27]
Liang, P., et al. (2023). HELM: Holistic Evaluation of Language Models.TMLR
2023
-
[28]
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., & Cobbe, K. (2024). Let’s Verify Step by Step.ICLR 2024;arXiv:2305.20050
Pith/arXiv arXiv 2024
-
[29]
Lin, S., Hilton, J., & Evans, O. (2022). TruthfulQA.ACL 2022
2022
-
[30]
Liu, N., et al. (2024). Lost in the Middle.TACL, 12, 157–173
2024
-
[31]
Liu, Y., et al. (2023). G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment.EMNLP 2023
2023
-
[32]
Wang, W., et al. (2026). Intelligence Degradation in Long-Context LLMs: Critical Threshold Determi- nation via Natural Length Distribution Analysis.arXiv:2601.15300
arXiv 2026
-
[33]
Ramezanali, M., Vazifeh, M., & Santi, P. (2025). seqBench: A Tunable Benchmark to Quantify Sequential Reasoning Limits of LLMs.EMNLP 2025, pp. 33771–33792;arXiv:2509.16866
arXiv 2025
- [34]
-
[35]
& Rothchild, J
Lynch, P. & Rothchild, J. (1989).One Up on Wall Street. Simon & Schuster
1989
-
[36]
& Rothchild, J
Lynch, P. & Rothchild, J. (1993).Beating the Street. Simon & Schuster
1993
-
[37]
Malo, P., et al. (2014). Good Debt or Bad Debt.JASIST, 65(4)
2014
-
[38]
(2011).The Most Important Thing
Marks, H. (2011).The Most Important Thing. Columbia University Press
2011
-
[39]
(2018).Mastering the Market Cycle
Marks, H. (2018).Mastering the Market Cycle. Houghton Mifflin Harcourt
2018
-
[40]
(2023, July)
Marks, H. (2023, July). Taking the Temperature.Oaktree Capital Memo
2023
-
[41]
(2024, January)
Marks, H. (2024, January). Easy Money.Oaktree Capital Memo
2024
-
[42]
(2025, November)
Marks, H. (2025, November). Cockroaches in the Coal Mine.Oaktree Capital Memo
2025
-
[43]
Munger, C.T. (1994). A Lesson on Elementary, Worldly Wisdom.USC Business School Speech
1994
-
[44]
(2020–2024).Annual Reports and Responsible Investment Reports
Norges Bank Investment Management. (2020–2024).Annual Reports and Responsible Investment Reports
2020
-
[45]
(2023).Annual Report 2023
Council on Ethics for the Norwegian Government Pension Fund Global. (2023).Annual Report 2023. Norwegian Ministry of Finance
2023
-
[46]
(2005, amended 2021).Government Pension Fund Act
Norway Ministry of Finance. (2005, amended 2021).Government Pension Fund Act
2005
-
[47]
Pal, A., et al. (2022). MedMCQA.CHIL 2022
2022
-
[48]
(2021).Santiago Principles Self-Assessment Report
Public Investment Fund. (2021).Santiago Principles Self-Assessment Report. 57
2021
-
[49]
Ribeiro, M.T., et al. (2020). Beyond Accuracy: Behavioral Testing with CheckList.ACL 2020(Best Paper Award)
2020
-
[50]
(2024).PIF Strategy
Saudipedia / Public Investment Fund. (2024).PIF Strategy
2024
-
[51]
Shi, F., et al. (2023). LLMs Can Be Easily Distracted by Irrelevant Context.ICML 2023
2023
-
[52]
(1987).The Alchemy of Finance
Soros, G. (1987).The Alchemy of Finance. Simon & Schuster
1987
-
[53]
(1995).Soros on Soros
Soros, G. (1995).Soros on Soros. Wiley
1995
-
[54]
Li, H., et al. (2025). INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent.ACL 2025, pp. 2509–2525;arXiv:2412.18174. [13 LLMs; stocks/crypto/ETF; agent decision-making]
arXiv 2025
-
[55]
Wei, J., et al. (2022). Chain-of-Thought Prompting.NeurIPS 2022
2022
-
[56]
Wu, S., et al. (2023). BloombergGPT.arXiv:2303.17564
Pith/arXiv arXiv 2023
-
[57]
Xie, Q., et al. (2023). PIXIU: A Comprehensive Benchmark, Instruction Dataset and Large Language Model for Finance.NeurIPS 2023
2023
-
[58]
Zha, Y., et al. (2023). AlignScore: Evaluating Factual Consistency.ACL 2023
2023
-
[59]
Zhang, H., et al. (2025). FinCalcBench: A Benchmark for Financial Calculation and Expert-Level Quantitative Reasoning.Companion benchmark (v0.3; 50 questions); released with FinanceBench repository — see Data Availability.(No separate arXiv preprint at time of submission.)
2025
-
[60]
Zhang, T., et al. (2020). BERTScore: Evaluating Text Generation with BERT.ICLR 2020
2020
-
[61]
Zhang, Z., et al. (2025). XFinBench: Benchmarking LLMs in Complex Financial Problem Solving and Reasoning.ACL 2025 Findings; arXiv:2508.15861. [4,235Q; 5 capabilities; o1 67.3% vs human ~80%]
arXiv 2025
-
[62]
Chen, Z. (Zhiyu), et al. (2022). ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversa- tional Finance Question Answering.EMNLP 2022;arXiv:2210.03849
arXiv 2022
-
[63]
Zhu, F., Lei, W., Wang, C., Zheng, J., Lv, S., Feng, F., & Chua, T.-S. (2021). TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance.ACL 2021, pp. 3277– 3287
2021
-
[64]
Chen, S., et al. (2025). Benchmarking Large Language Models Under Data Contamination: A Survey from Static to Dynamic Evaluation.EMNLP 2025 Main; arXiv:2502.17521. Appendix A: Representative Questions by Layer A.1 Layer 3 (Operationalization) — Medium IPB-P-003:“Buffett’s concept of ‘owner earnings’ differs from reported net income. Explain the formula, w...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.