Enhancing Part-Level Point Grounding for Any Open-Source MLLMs
Pith reviewed 2026-06-30 08:03 UTC · model grok-4.3
The pith
A module adds accurate part-level point grounding to any frozen open-source MLLM by prompting its existing attention patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
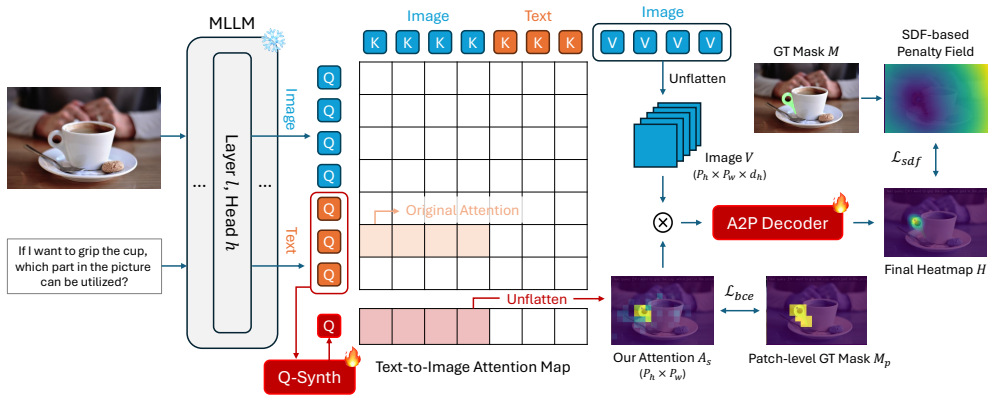
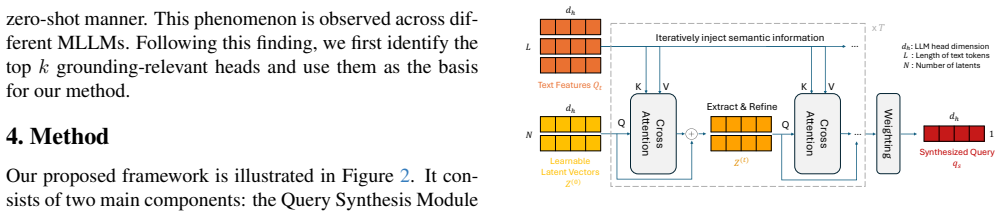
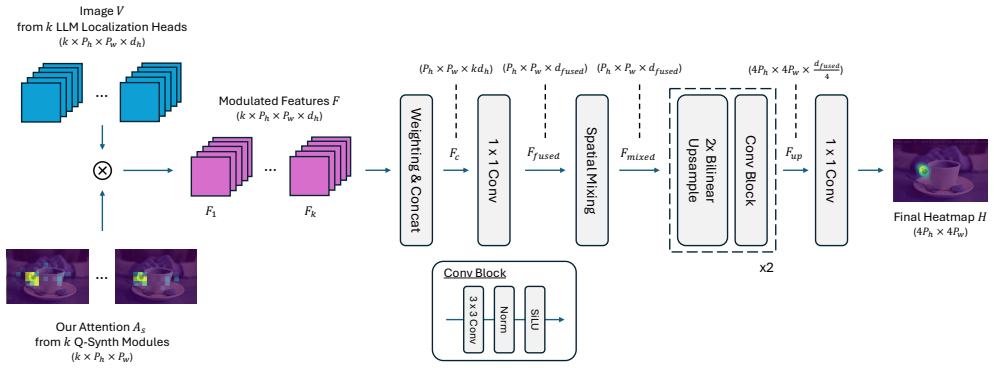
By synthesizing text-conditioned grounding-aware queries inside the intermediate layers of a frozen MLLM with the Q-Synth Module, target-relevant attention patterns are captured and then converted by a lightweight Attention-to-Point Decoder into point-centric heatmaps that deliver accurate part-level point predictions.
What carries the argument
The Q-Synth Module, which creates text-conditioned queries to elicit grounding-aware attention patterns from frozen intermediate layers, paired with the Attention-to-Point Decoder that refines those patterns into point heatmaps.
If this is right
- Part-level grounding accuracy rises across tested datasets while the base MLLM stays unchanged.
- The same module works with any open-source MLLM without retraining its parameters.
- Point-based output becomes a direct alternative to box or mask grounding representations.
- Pre-trained multimodal capabilities remain fully preserved after adding the grounding skill.
Where Pith is reading between the lines
- The approach could be tested on tasks that need part-level interaction, such as tool-use or assembly instructions.
- If attention patterns differ across model families, the decoder might need light per-model calibration while still freezing the backbone.
- Success here suggests similar query-synthesis tricks could unlock other fine-grained visual outputs without full fine-tuning.
Load-bearing premise
The attention patterns already present in a frozen MLLM's intermediate layers contain enough target-relevant information, once prompted by the Q-Synth Module, to be turned into accurate part-level point predictions.
What would settle it
Running the method on several open-source MLLMs and part-level grounding datasets and finding no consistent accuracy gain, or finding that the extracted attention maps produce heatmaps no better than random point selection.
Figures






read the original abstract
Visual grounding aims to associate free-form textual queries with specific regions in an image. While recent Multimodal Large Language Models (MLLMs) have demonstrated promising capabilities in this domain, they primarily excel at object-level grounding and often struggle with part-level grounding-an essential requirement for fine-grained tasks such as robotic manipulation. In this work, we introduce a general approach that equips any open-source MLLMs with accurate 2D part-level point grounding, offering a more direct alternative to conventional grounding representations. Our method leverages the attention mechanisms inherently present in MLLMs. By synthesizing text-conditioned, grounding-aware queries within intermediate layers via the proposed Q-Synth Module, we capture target-relevant attention patterns and refine them with a lightweight Attention-to-Point Decoder, which converts these patterns into a point-centric heatmap for final prediction. Notably, all original MLLM parameters are frozen, ensuring full preservation of their pre-trained capabilities. Experiments show that our design consistently improves part-level grounding accuracy across datasets and can be seamlessly integrated into any open-source MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a Q-Synth Module that synthesizes text-conditioned, grounding-aware queries in the intermediate layers of any open-source MLLM to capture target-relevant attention patterns, which are then refined by a lightweight Attention-to-Point Decoder into point-centric heatmaps for part-level point grounding. All original MLLM parameters remain frozen, and the authors assert that the design consistently improves part-level grounding accuracy across datasets while preserving pre-trained capabilities.
Significance. If the claimed improvements hold under rigorous evaluation, the approach would be significant as a parameter-efficient method for extending existing MLLMs to fine-grained part-level grounding tasks without retraining, which is relevant for applications such as robotic manipulation.
major comments (2)
- Abstract: the abstract asserts consistent accuracy gains but supplies no quantitative results, error bars, dataset details, or ablation studies; without these it is impossible to verify whether the reported improvements are robust or affected by post-hoc choices.
- Abstract: the central claim depends on the assumption that attention patterns already present in the intermediate layers of a completely frozen MLLM contain sufficient target-specific information for part-level point localization once the Q-Synth Module injects text-conditioned queries; this premise lacks any architectural guarantee and requires explicit validation that pre-trained heads encode part-level rather than only object-level cues.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. Below we address each major comment point by point with honest responses and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [—] Abstract: the abstract asserts consistent accuracy gains but supplies no quantitative results, error bars, dataset details, or ablation studies; without these it is impossible to verify whether the reported improvements are robust or affected by post-hoc choices.
Authors: We agree that the abstract is too concise and does not include the requested quantitative details. The full manuscript reports accuracy improvements with error bars, specific datasets, and ablation studies in the Experiments and Ablation sections. We will revise the abstract to incorporate key quantitative results (e.g., average accuracy gains and dataset names) so that the claims can be assessed directly from the abstract. revision: yes
-
Referee: [—] Abstract: the central claim depends on the assumption that attention patterns already present in the intermediate layers of a completely frozen MLLM contain sufficient target-specific information for part-level point localization once the Q-Synth Module injects text-conditioned queries; this premise lacks any architectural guarantee and requires explicit validation that pre-trained heads encode part-level rather than only object-level cues.
Authors: The Q-Synth Module is explicitly designed to synthesize text-conditioned queries that elicit part-relevant attention from the frozen intermediate layers. Our experiments provide supporting evidence through attention visualizations (showing part-level focus after query synthesis) and ablations that compare performance with and without the module, demonstrating that the pre-trained attention can be steered toward part-level cues. We will add an explicit validation subsection with additional attention-map analysis and object-vs-part comparisons in the revised manuscript. revision: partial
Circularity Check
No circularity: architectural addition validated by experiments
full rationale
The paper proposes an architectural method (Q-Synth Module + Attention-to-Point Decoder) that injects queries into frozen MLLM attention layers and decodes to point heatmaps. No equations, parameters, or derivations are presented that reduce the claimed accuracy gains to a fitted quantity defined by the evaluation data itself. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claim rests on experimental integration and measured improvements, which are independent of any definitional or fitting circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms in MLLMs capture target-relevant patterns when text-conditioned queries are synthesized in intermediate layers.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,...
2025
-
[3]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multi- modal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Smith, Fei Xia, Dieter Fox, and Ranjay Krishna
Long Cheng, Jiafei Duan, Yi Ru Wang, Haoquan Fang, Boyang Li, Yushan Huang, Elvis Wang, Ainaz Eftekhar, Ja- son Lee, Wentao Yuan, Rose Hendrix, Noah A. Smith, Fei Xia, Dieter Fox, and Ranjay Krishna. Pointarena: Prob- ing multimodal grounding through language-guided point- ing, 2025. 5, 6, 7, 8, 1
2025
-
[5]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104,
-
[6]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm- e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Moka: Open-world robotic manipulation through mark- based visual prompting.Robotics: Science and Systems (RSS), 2024
Kuan Fang, Fangchen Liu, Pieter Abbeel, and Sergey Levine. Moka: Open-world robotic manipulation through mark- based visual prompting.Robotics: Science and Systems (RSS), 2024. 1, 2
2024
-
[8]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal reasoning of rela- tional keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Your large vision-language model only needs a few attention heads for visual grounding
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9339–9350, 2025. 2, 3, 4, 6, 8, 5
2025
-
[10]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9579–9589, 2024. 2, 3, 5
2024
-
[11]
Towards long-horizon vision-language-action sys- tem: Reasoning, acting and memory
Daixun Li, Yusi Zhang, Mingxiang Cao, Donglai Liu, Weiy- ing Xie, Tianlin Hui, Lunkai Lin, Zhiqiang Xie, and Yun- song Li. Towards long-horizon vision-language-action sys- tem: Reasoning, acting and memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6839–6848, 2025. 1
2025
-
[12]
Lawrence Zitnick, and Piotr Doll ´ar
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Doll ´ar. Microsoft coco: Common objects in context, 2015. 3
2015
-
[13]
Improved baselines with visual instruction tuning, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2024. 2
2024
-
[14]
kpam: Keypoint affordances for category-level robotic ma- nipulation
Lucas Manuelli, Wei Gao, Peter Florence, and Russ Tedrake. kpam: Keypoint affordances for category-level robotic ma- nipulation. InThe International Symposium of Robotics Re- search, pages 132–157. Springer, 2019. 1
2019
-
[15]
Tomohiro Motoda, Takahide Kitamura, Ryo Hanai, and Yukiyasu Domae. Suctionprompt: Visual-assisted robotic picking with a suction cup using vision-language models and facile hardware design.Journal of Robotics and Mechatron- ics, 37(2):374–386, 2025. 1, 2
2025
-
[16]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Perceptiongpt: Effectively fusing visual percep- tion into llm
Renjie Pi, Lewei Yao, Jiahui Gao, Jipeng Zhang, and Tong Zhang. Perceptiongpt: Effectively fusing visual percep- tion into llm. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27124– 27133, 2024. 2, 3
2024
-
[18]
Keto: Learning keypoint representations for tool manipulation
Zengyi Qin, Kuan Fang, Yuke Zhu, Li Fei-Fei, and Silvio Savarese. Keto: Learning keypoint representations for tool manipulation. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 7278–7285. IEEE,
-
[19]
Paco: Parts and attributes of common objects
Vignesh Ramanathan, Anmol Kalia, Vladan Petrovic, Yi Wen, Baixue Zheng, Baishan Guo, Rui Wang, Aaron Mar- quez, Rama Kovvuri, Abhishek Kadian, et al. Paco: Parts and attributes of common objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7141–7151, 2023. 2, 5, 6, 7, 8, 1, 3, 4
2023
-
[20]
Glamm: Pixel grounding large multimodal model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdel- rahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13009–13018, 2024. 2, 3, 5
2024
-
[21]
Pixellm: Pixel reasoning with large multimodal model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. Pixellm: Pixel reasoning with large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26374–26383, 2024. 2, 3
2024
-
[22]
Going denser with open-vocabulary part segmentation
Peize Sun, Shoufa Chen, Chenchen Zhu, Fanyi Xiao, Ping Luo, Saining Xie, and Zhicheng Yan. Going denser with open-vocabulary part segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15453–15465, 2023. 5, 6, 3
2023
-
[23]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Are- nas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, 9 Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Instruct- part: Task-oriented part segmentation with instruction rea- soning
Zifu Wan, Yaqi Xie, Ce Zhang, Zhiqiu Lin, Zihan Wang, Si- mon Stepputtis, Deva Ramanan, and Katia Sycara. Instruct- part: Task-oriented part segmentation with instruction rea- soning. InThe 63rd Annual Meeting of the Association for Computational Linguistics, 2025. 5, 6, 1, 3
2025
-
[25]
Cong Wei, Haoxian Tan, Yujie Zhong, Yujiu Yang, and Lin Ma. Lasagna: Language-based segmentation assistant for complex queries.arXiv preprint arXiv:2404.08506, 2024. 2, 3
-
[26]
F-lmm: Grounding frozen large multimodal models
Size Wu, Sheng Jin, Wenwei Zhang, Lumin Xu, Wentao Liu, Wei Li, and Chen Change Loy. F-lmm: Grounding frozen large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24710– 24721, 2025. 2, 3, 5
2025
-
[27]
Mldt: Multi-level decom- position for complex long-horizon robotic task planning with open-source large language model
Yike Wu, Jiatao Zhang, Nan Hu, Lanling Tang, Guilin Qi, Jun Shao, Jie Ren, and Wei Song. Mldt: Multi-level decom- position for complex long-horizon robotic task planning with open-source large language model. InInternational Confer- ence on Database Systems for Advanced Applications, pages 251–267. Springer, 2024. 1
2024
-
[28]
Guiding long-horizon task and motion planning with vision language models
Zhutian Yang, Caelan Garrett, Dieter Fox, Tom ´as Lozano- P´erez, and Leslie Pack Kaelbling. Guiding long-horizon task and motion planning with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16847–16853. IEEE, 2025. 1
2025
-
[29]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Robopoint: A vision-language model for spatial affordance prediction for robotics
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousa- vian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024. 1, 2
-
[31]
MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 5
2025
-
[32]
Generalized decoding for pixel, image, and lan- guage
Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, et al. Generalized decoding for pixel, image, and lan- guage. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 15116–15127,
-
[33]
× $!) Our Attention
5, 6, 3 10 Enhancing Part-Level Point Grounding for Any Open-Source MLLMs Supplementary Material A. Overview This supplementary material provides additional details and results that complement the main manuscript. In Sec. B, we describe the architectural details of the proposed Attention- to-Point (A2P) Decoder. In Sec. C, we present plots and visualizati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.