Beyond Tokenization: Direct Timestep Embedding and Contrastive Alignment for Time-Series Question Answering
Pith reviewed 2026-06-26 20:40 UTC · model grok-4.3
The pith
Direct timestep embedding with contrastive alignment overcomes tokenization bottlenecks in time-series question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
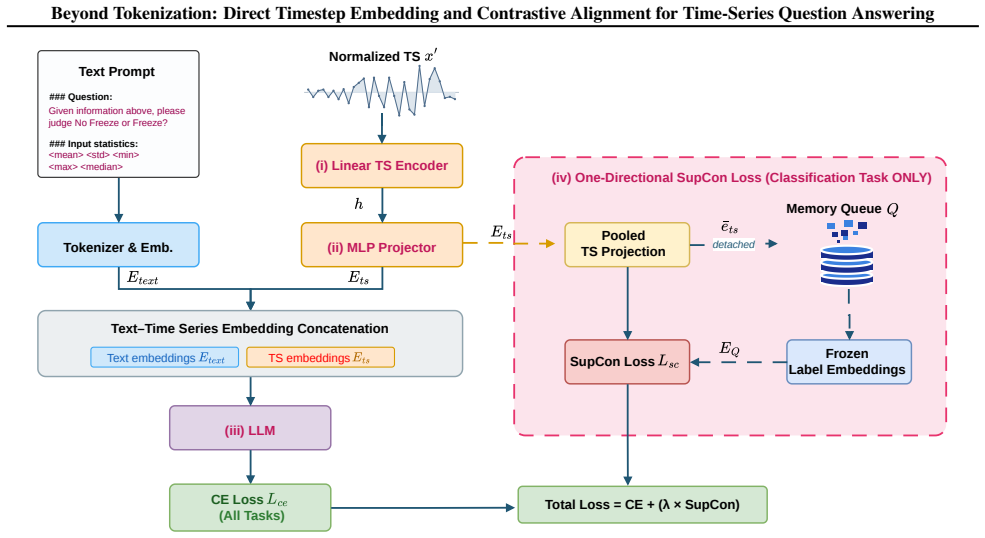
CADE uses direct timestep embedding to preserve exact index-level access and eliminate patching needs, combined with a novel one-directional supervised contrastive loss that aligns time-series embeddings with frozen class-name text anchors, resulting in better performance on time-series question answering tasks.
What carries the argument
The direct timestep embedding mechanism (point-wise linear encoder plus MLP projector) that maps each timestep individually into LLM space, and the one-directional supervised contrastive loss for semantic alignment.
If this is right
- Performance improves consistently across six TSQA tasks on the public Time-MQA benchmark.
- Outperforms both open-source and proprietary LLM baselines.
- Exact index-level access is preserved without the need for patching or padding.
- The semantic gap between time-series and language representations is bridged effectively.
Where Pith is reading between the lines
- Variable-length time series from different sampling rates could be handled more flexibly without retraining patching modules.
- Similar direct embedding approaches might extend to other modalities like audio or sensor data for LLM integration.
Load-bearing premise
The point-wise linear encoder and MLP projector preserve exact index-level access and the contrastive loss successfully aligns the representations without losing magnitude, scale, or trend information.
What would settle it
Running the CADE framework on the Time-MQA benchmark and finding no improvement or worse performance compared to standard LLM baselines would falsify the claim.
Figures

read the original abstract
Recent advances in large language models (LLMs) have given rise to time-series question answering (TSQA), which formulates time-series analysis as natural-language question answering. However, directly feeding raw numerical series into LLMs suffers from a tokenization bottleneck: Byte Pair Encoding fragments continuous values into unstable tokens whose embeddings lack meaningful metric structure, resulting in the loss of magnitude, scale, and trend information. Prior methods use patch-based encoders that split the series into fixed windows, locking in one granularity that breaks patterns and hides exact timesteps, through a separate module that rarely transfers across datasets with different lengths or sampling rates. To address this challenge, we propose CADE (Contrastive Alignment with Direct Embedding), a novel framework for TSQA built upon two key components: direct timestep embedding and semantic alignment. The proposed framework maps each timestep directly into the LLM embedding space through a point-wise linear encoder and MLP projector, preserving exact index-level access while eliminating the need for patching and padding. To further bridge the semantic gap between time-series and language representations, we introduce a novel one-directional supervised contrastive loss that aligns time-series embeddings with frozen class-name text anchors. Experimental results on the public Time-MQA benchmark demonstrate that our framework consistently improves performance across six TSQA tasks, outperforming both open-source and proprietary LLM baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the CADE framework for time-series question answering (TSQA). It addresses the tokenization bottleneck by introducing direct timestep embedding using a point-wise linear encoder and an MLP projector, which preserves exact index-level access without patching. Additionally, it uses a one-directional supervised contrastive loss to align time-series embeddings with frozen class-name text anchors to bridge the semantic gap. The authors report that this approach leads to consistent performance improvements across six TSQA tasks on the Time-MQA benchmark, outperforming open-source and proprietary LLM baselines.
Significance. If the experimental results are substantiated and the contrastive alignment proves effective, the work could offer a significant advancement in TSQA by providing a patching-free method that maintains temporal fidelity and enables better integration with LLMs. This might lead to more robust models for time-series analysis framed as QA tasks. The identification of the tokenization issue is a clear contribution.
major comments (2)
- [Abstract] Abstract: The central claim that the framework 'consistently improves performance across six TSQA tasks' and 'outperforms both open-source and proprietary LLM baselines' is presented without any quantitative results, baseline descriptions, ablation studies, or error bars. This absence makes it impossible to assess whether the data supports the claim, which is load-bearing for the paper's main contribution.
- [semantic alignment] semantic alignment: The one-directional supervised contrastive loss with frozen class-name text anchors is presented as bridging the semantic gap between time-series and language representations, but the manuscript provides no analysis or evidence that these anchors encode temporal patterns, magnitudes, or trends. Without ablations isolating the contribution of this loss versus the direct embedding alone, it remains unclear whether the alignment is effective.
minor comments (1)
- [Abstract] The abstract references the 'public Time-MQA benchmark' without a citation to the source introducing the benchmark or prior work on it.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree to revisions that strengthen the presentation of results and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'consistently improves performance across six TSQA tasks' and 'outperforms both open-source and proprietary LLM baselines' is presented without any quantitative results, baseline descriptions, ablation studies, or error bars. This absence makes it impossible to assess whether the data supports the claim, which is load-bearing for the paper's main contribution.
Authors: We agree that the abstract would benefit from quantitative support to substantiate the central claims. In the revised manuscript we will add concise quantitative indicators (e.g., average accuracy gains across the six tasks, reference to the specific open-source and proprietary baselines, and mention of error bars), while preserving the abstract's brevity. The full tables, ablation results, and standard deviations already appear in Section 4; the abstract revision will point readers to these details. revision: yes
-
Referee: [semantic alignment] semantic alignment: The one-directional supervised contrastive loss with frozen class-name text anchors is presented as bridging the semantic gap between time-series and language representations, but the manuscript provides no analysis or evidence that these anchors encode temporal patterns, magnitudes, or trends. Without ablations isolating the contribution of this loss versus the direct embedding alone, it remains unclear whether the alignment is effective.
Authors: The class-name text anchors are deliberately frozen semantic embeddings chosen to supply high-level category meaning rather than to encode temporal dynamics, magnitudes, or trends themselves; the one-directional contrastive loss then aligns the direct timestep embeddings toward these fixed semantic points. We acknowledge that the current manuscript lacks both an explicit discussion of the anchors' semantic properties and an ablation isolating the loss from the direct-embedding component. We will add (i) a dedicated paragraph clarifying the role and limitations of the anchors and (ii) an ablation table comparing performance with and without the contrastive term in the revised version. revision: yes
Circularity Check
No circularity; claims rest on experimental results without self-referential derivations
full rationale
The paper introduces CADE with direct timestep embedding via point-wise linear encoder and MLP projector, plus one-directional supervised contrastive loss with frozen class-name anchors. These are presented as novel components whose value is asserted via performance gains on the public Time-MQA benchmark across six tasks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the claimed improvements to inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Knowledge and Data Engineering , volume=
Promptcast: A new prompt-based learning paradigm for time series forecasting , author=. IEEE Transactions on Knowledge and Data Engineering , volume=
-
[2]
Advances in neural information processing systems , volume=
Large language models are zero-shot time series forecasters , author=. Advances in neural information processing systems , volume=
-
[3]
International conference on learning representations , pages=
Time-llm: Time series forecasting by reprogramming large language models , author=. International conference on learning representations , pages=
-
[4]
Chenxi Sun and Hongyan Li and Yaliang Li and Shenda Hong , booktitle=
-
[5]
Proceedings of the ACM Web Conference 2024 , pages=
Unitime: A language-empowered unified model for cross-domain time series forecasting , author=. Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[6]
International Conference on Machine Learning , pages=
A decoder-only foundation model for time-series forecasting , author=. International Conference on Machine Learning , pages=
-
[7]
Transactions on Machine Learning Research , volume=
Chronos: Learning the Language of Time Series , author=. Transactions on Machine Learning Research , volume=
-
[8]
Forty-first International Conference on Machine Learning , year=
Unified training of universal time series forecasting transformers , author=. Forty-first International Conference on Machine Learning , year=
-
[9]
arXiv preprint arXiv:2310.08278 , year=
Lag-llama: Towards foundation models for probabilistic time series forecasting , author=. arXiv preprint arXiv:2310.08278 , year=
-
[10]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[11]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Timechat: A time-sensitive multimodal large language model for long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Advances in Neural Information Processing Systems , volume=
Autotimes: Autoregressive time series forecasters via large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Pan, Zijie and Jiang, Yushan and Garg, Sahil and Schneider, Anderson and Nevmyvaka, Yuriy and Song, Dongjin , booktitle=. s\^
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Time-mqa: Time series multi-task question answering with context enhancement , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
International Conference on Machine Learning , pages=
ITFormer: Bridging Time Series and Natural Language for Multi-Modal QA with Large-Scale Multitask Dataset , author=. International Conference on Machine Learning , pages=
-
[17]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
International conference on learning representations , pages=
Time-moe: Billion-scale time series foundation models with mixture of experts , author=. International conference on learning representations , pages=
-
[19]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=
-
[20]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
Towards cross-modality modeling for time series analytics: a survey in the LLM Era , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
-
[21]
Advances in Neural Information Processing Systems , volume=
Time-ffm: Towards lm-empowered federated foundation model for time series forecasting , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
2025 IEEE 41st International Conference on Data Engineering (ICDE) , pages=
Efficient multivariate time series forecasting via calibrated language models with privileged knowledge distillation , author=. 2025 IEEE 41st International Conference on Data Engineering (ICDE) , pages=
2025
-
[23]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
TS-CLIP: Time Series Understanding by CLIP , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[24]
arXiv preprint arXiv:2506.24124 , year=
Teaching Time Series to See and Speak: Forecasting with Aligned Visual and Textual Perspectives , author=. arXiv preprint arXiv:2506.24124 , year=
-
[25]
Advances in neural information processing systems , volume=
Supervised contrastive learning , author=. Advances in neural information processing systems , volume=
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning , year =
Xie, Zhe and Li, Zeyan and He, Xiao and Xu, Longlong and Wen, Xidao and Zhang, Tieying and Chen, Jianjun and Shi, Rui and Pei, Dan , journal =. ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning , year =
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Chattime: A unified multimodal time series foundation model bridging numerical and textual data , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[29]
Proceedings of the AAAI conference on artificial intelligence , pages=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , pages=
-
[30]
The Eleventh International Conference on Learning Representations , year =
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author =. The Eleventh International Conference on Learning Representations , year =
-
[31]
The Eleventh International Conference on Learning Representations , year =
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author =. The Eleventh International Conference on Learning Representations , year =
-
[32]
GPT-4 Technical Report , author =. arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Deepseek-v3 technical report , author =. arXiv preprint arXiv:2412.19437 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in neural information processing systems , volume=
One fits all: Power general time series analysis by pretrained lm , author=. Advances in neural information processing systems , volume=
-
[36]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
Transformers in time series: a survey , author=. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
-
[37]
Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Neural machine translation of rare words with subword units , author=. Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.