GeoFidelity-Bench: Evaluating Segment-Level Geographic Fidelity in Text-to-Image Street-View Generation
Pith reviewed 2026-06-26 09:09 UTC · model grok-4.3
The pith
Street and neighborhood names raise top-1 retrieval accuracy by 5.5 points in generated street views, yet the similarity margin to the nearest same-city segment stays near zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
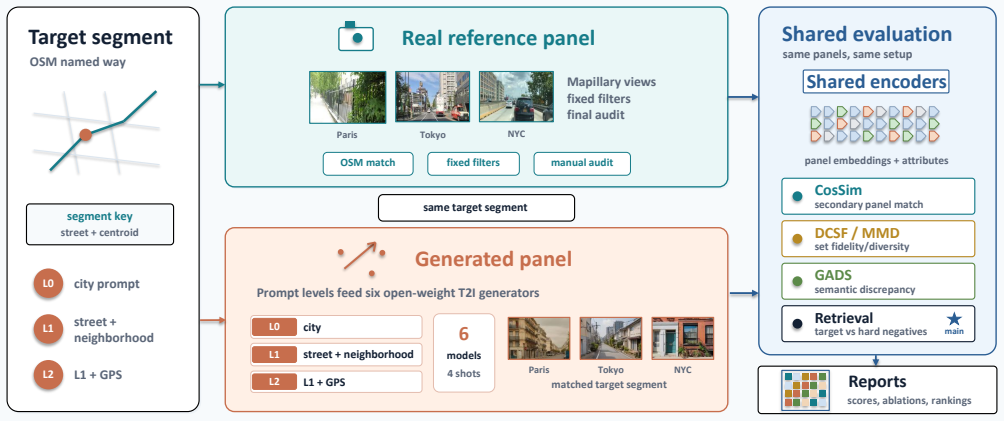
GeoFidelity-Bench ranks generated panels by similarity to the target reference panel versus the nearest same-city segment, other same-city segments, and other-city segments. City-only prompts yield low top-1 accuracy; adding correct street and neighborhood names raises accuracy by 5.5 percentage points, while the similarity margin between target and nearest same-city segment remains near zero. Appending raw GPS coordinates as text yields no statistically clear gain, and prompts with incorrect local names still confer partial improvement. Held-out real-image queries recover segment identity, validating that the references contain recoverable segment-level signal.
What carries the argument
The reference-panel ranking protocol that scores each generated image against target, nearest same-city, other same-city, and other-city panels to isolate segment-level geographic fidelity rather than absolute similarity.
If this is right
- Local names improve broad local plausibility more than exact segment identity.
- Raw GPS coordinates appended as text yield no statistically clear additional benefit.
- Only part of the accuracy gain depends on using the correct local names rather than any local name.
- The benchmark distinguishes real images by segment, confirming usable signal in the references.
Where Pith is reading between the lines
- Future generators may need mechanisms beyond plain text prompts to encode segment-specific visual features.
- The ranking protocol could be reused to measure progress on other fine-grained visual control tasks.
- Persistent near-zero margins suggest that training corpora may under-represent the distinctive appearance of individual road segments.
Load-bearing premise
The curated reference panels contain usable segment-level signal recoverable by real-image queries, and the ranking isolates geographic fidelity without being dominated by lighting, season, or camera angle.
What would settle it
If queries with held-out real images fail to rank the correct segment first at rates above chance, the reference panels lack recoverable segment-level signal.
Figures



read the original abstract
Text-to-image models can generate visually plausible city streets, but whether their outputs correspond to a requested road segment rather than a generic city prior remains unclear. We introduce GeoFidelity-Bench, a reference-panel benchmark for segment-conditioned geographic fidelity in street-view generation. It contains 7,117 curated Mapillary images covering 109 named OpenStreetMap road segments in 25 cities across six continents. For each generated panel, the benchmark ranks the target reference panel against panels from the nearest segment in the same city, other segments in the same city, and segments from other cities, making local discrimination rather than absolute target similarity the primary test. We evaluate six open-weight text-to-image generators under city-only, street-and-neighborhood, and GPS-augmented prompts. Adding street and neighborhood names is associated with an increase of 5.5 percentage points in top-1 retrieval accuracy over city-only prompts, with a 95% confidence interval from 3.4 to 7.7 percentage points. However, the similarity margin between the target and the nearest segment in the same city remains near zero, indicating that local names improve broad local plausibility more than exact segment identity. Prompts that keep the city fixed but use incorrect street or neighborhood names further show that only part of the gain depends on the correct local names, while appending raw GPS coordinates as ordinary text yields no statistically clear additional benefit. Held-out real-image queries successfully recover segment identity, showing that the curated references contain usable segment-level signal. GeoFidelity-Bench thus reveals a persistent gap between city- or neighborhood-plausible street-view generation and faithful generation for a specific road segment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoFidelity-Bench, a reference-panel benchmark with 7,117 curated Mapillary images spanning 109 named OpenStreetMap road segments across 25 cities on six continents. It evaluates six open-weight text-to-image models under city-only, street-and-neighborhood, and GPS-augmented prompts by ranking each generated panel against the target reference, the nearest same-city segment, other same-city segments, and other-city segments. The central empirical claim is that adding street and neighborhood names raises top-1 retrieval accuracy by 5.5 percentage points (95% CI 3.4–7.7) relative to city-only prompts, yet the similarity margin between target and nearest same-city segment remains near zero; incorrect local names still confer partial gains while raw GPS text adds none. A held-out real-image validation confirms that the reference panels contain recoverable segment-level signal under the same protocol.
Significance. If the reported effect sizes and validation hold, the work supplies a concrete, multi-continent benchmark that quantifies the gap between city- or neighborhood-plausible street-view generation and faithful segment-level fidelity. The inclusion of a real-image control, non-overlapping confidence interval, and explicit distinction between broad-plausibility and exact-identity gains strengthens the empirical contribution and provides a reproducible testbed for future conditional-generation research.
minor comments (3)
- [§4] §4 (evaluation protocol): the exact embedding model, similarity metric, and aggregation rule used for the reported top-1 accuracy and margins are not stated explicitly; adding one sentence or a short pseudocode block would remove ambiguity without altering the central claim.
- [§3] Table 1 or §3: the six evaluated models are named only in the abstract; listing their exact checkpoints and parameter counts in the main text or a table would improve reproducibility.
- [Results] The manuscript reports a 95% CI but does not indicate whether the interval accounts for multiple comparisons across prompt conditions; a brief note on the statistical procedure would be helpful.
Simulated Author's Rebuttal
We thank the referee for their detailed summary of the work, positive assessment of its significance, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity in empirical benchmark
full rationale
This paper introduces an empirical benchmark (GeoFidelity-Bench) consisting of curated Mapillary reference panels and a retrieval-ranking protocol. All reported results—top-1 accuracy gains of 5.5 pp with CI, near-zero target-vs-nearest margins, and held-out real-image validation—are direct statistical outputs of applying the fixed protocol to model generations under varying prompts. No derivations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear; the central claims follow from the described data collection and ranking procedure without reduction to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The curated 7,117-image reference set contains usable segment-level signal recoverable by real-image queries.
- domain assumption Top-1 retrieval accuracy against nearest same-city, other same-city, and other-city panels isolates geographic fidelity.
Reference graph
Works this paper leans on
-
[1]
CoT-VLA: Visual chain-of-thought reasoning for vision- language-action models,
Feng, Chao and Chen, Ziyang and Ho. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. doi:10.1109/CVPR52734.2025.00264 , publisher=
-
[2]
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation , url=
Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion , author=. ACM SIGGRAPH 2024 Conference Papers , pages=. doi:10.1145/3641519.3657513 , publisher=
-
[3]
Hall, Melissa and Ross, Candace and Williams, Adina and Carion, Nicolas and Drozdzal, Michal and Romero-Soriano, Adriana , journal=
-
[4]
doi:10.52202/075280-2888 , publisher=
Ramaswamy, Vikram V and Lin, Sing Yu and Zhao, Dora and Adcock, Aaron and van der Maaten, Laurens and Ghadiyaram, Deepti and Russakovsky, Olga , booktitle=. doi:10.52202/075280-2888 , publisher=
-
[5]
doi:10.52202/075280-0379 , publisher=
Vivanco Cepeda, Vicente and Nayak, Gaurav Kumar and Shah, Mubarak , booktitle=. doi:10.52202/075280-0379 , publisher=
-
[6]
V*: Guided visual search as a core mechanism in multimodal llms
Astruc, Guillaume and Dufour, Nicolas and Siglidis, Ioannis and Aronssohn, Constantin and Bouia, Nacim and Fu, Stephanie and Loiseau, Romain and Nguyen, Van Nguyen and Raude, Charles and Vincent, Elliot and Xu, Lintao and Zhou, Hongyu and Landrieu, Loic , booktitle=. doi:10.1109/CVPR52733.2024.02074 , publisher=
-
[7]
V*: Guided visual search as a core mechanism in multimodal llms
Li, Zuoyue and Li, Zhenqiang and Cui, Zhaopeng and Pollefeys, Marc and Oswald, Martin R , booktitle=. doi:10.1109/CVPR52733.2024.00682 , publisher=
-
[8]
European Conference on Computer Vision (ECCV) , pages=
Geospecific View Generation -- Geometry-Context Aware High-Resolution Ground View Inference from Satellite Views , author=. European Conference on Computer Vision (ECCV) , pages=. doi:10.1007/978-3-031-72970-6_20 , publisher=
-
[9]
V*: Guided visual search as a core mechanism in multimodal llms
Xie, Haozhe and Chen, Zhaoxi and Hong, Fangzhou and Liu, Ziwei , booktitle=. doi:10.1109/CVPR52733.2024.00923 , publisher=
-
[10]
doi:10.48550/arXiv.2407.11965 , year=
Shang, Yu and Lin, Yuming and Zheng, Yu and Fan, Hangyu and Ding, Jingtao and Feng, Jie and Chen, Jiansheng and Tian, Li and Li, Yong , howpublished=. doi:10.48550/arXiv.2407.11965 , year=. 2407.11965 , archiveprefix=
-
[11]
Transactions on Machine Learning Research , url=
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , url=
-
[12]
Masked-attention Mask Transformer for Universal Image Segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. doi:10.1109/CVPR52688.2022.00135 , publisher=
-
[13]
Journal of Machine Learning Research , volume=
A Kernel Two-Sample Test , author=. Journal of Machine Learning Research , volume=
-
[14]
Dataset condensation with distribution matching
Ali-bey, Amar and Chaib-draa, Brahim and Gigu. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. doi:10.1109/WACV56688.2023.00301 , publisher=
-
[15]
doi:10.1109/LRA.2023.3343602 , year=
Keetha, Nikhil and Mishra, Avneesh and Karhade, Jay and Jatavallabhula, Krishna Murthy and Scherer, Sebastian and Krishna, Madhava and Garg, Sourav , journal=. doi:10.1109/LRA.2023.3343602 , year=
-
[16]
V*: Guided visual search as a core mechanism in multimodal llms
Haas, Lukas and Skreta, Michal and Alberti, Silas and Finn, Chelsea , booktitle=. doi:10.1109/CVPR52733.2024.01225 , publisher=
-
[17]
doi:10.48550/arXiv.2406.11988 , year=
Decomposed Evaluations of Geographic Disparities in Text-to-Image Models , author=. doi:10.48550/arXiv.2406.11988 , year=. 2406.11988 , archiveprefix=
-
[18]
International Conference on Learning Representations (ICLR) , publisher=
Podell, Dustin and English, Zion and Lacey, Kyle and Blattmann, Andreas and Dockhorn, Tim and M. International Conference on Learning Representations (ICLR) , publisher=
-
[19]
doi:10.1007/978-3-031-73411-3_5 , publisher=
Chen, Junsong and Ge, Chongjian and Xie, Enze and Wu, Yue and Yao, Lewei and Ren, Xiaozhe and Wang, Zhongdao and Luo, Ping and Lu, Huchuan and Li, Zhenguo , booktitle=. doi:10.1007/978-3-031-73411-3_5 , publisher=
-
[20]
Li, Zhimin and Zhang, Jianwei and Lin, Qin and Xiong, Jiangfeng and Long, Yanxin and Deng, Xinchi and Zhang, Yingfang and Liu, Xingchao and Huang, Minbin and Xiao, Zedong and others , howpublished=. doi:10.48550/arXiv.2405.08748 , year=. 2405.08748 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.08748
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Sigmoid Loss for Language Image Pre-Training , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=. 2023 , doi=
2023
-
[22]
Neuhold, Gerhard and Ollmann, Tobias and Bul. The. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=. doi:10.1109/ICCV.2017.534 , publisher=
-
[23]
Place identity: a generative
Jang, Kee Moon and Chen, Junda and Kang, Yuhao and Kim, Junghwan and Lee, Jinhyung and Duarte, Fabio and Ratti, Carlo , journal=. Place identity: a generative. 2024 , publisher=
2024
-
[24]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[25]
CLIP- Score: A reference-free evaluation metric for image captioning
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Le Bras, Ronan and Choi, Yejin , booktitle=. doi:10.18653/v1/2021.emnlp-main.595 , year=
-
[26]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. doi:10.1109/CVPR.2018.00068 , publisher=
-
[27]
doi:10.1109/MPRV.2008.80 , year=
Haklay, Mordechai and Weber, Patrick , journal=. doi:10.1109/MPRV.2008.80 , year=
-
[28]
Ali-bey, A.; Chaib-draa, B.; and Gigu \`e re, P. 2023. MixVPR : Feature Mixing for Visual Place Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2998--3007. Los Alamitos, CA, USA: IEEE Computer Society
2023
-
[29]
N.; Raude, C.; Vincent, E.; Xu, L.; Zhou, H.; and Landrieu, L
Astruc, G.; Dufour, N.; Siglidis, I.; Aronssohn, C.; Bouia, N.; Fu, S.; Loiseau, R.; Nguyen, V. N.; Raude, C.; Vincent, E.; Xu, L.; Zhou, H.; and Landrieu, L. 2024. OpenStreetView-5M : The Many Roads to Global Visual Geolocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 21967--21977. Los Alamitos, CA, US...
2024
-
[30]
Black Forest Labs . 2024. Announcing Black Forest Labs . https://bfl.ai/announcing-black-forest-labs. Introduces the FLUX.1 suite of text-to-image models. Accessed: 2026-06-22
2024
-
[31]
Chen, J.; Ge, C.; Xie, E.; Wu, Y.; Yao, L.; Ren, X.; Wang, Z.; Luo, P.; Lu, H.; and Li, Z. 2024. PixArt- : Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation. In European Conference on Computer Vision (ECCV), volume 15090 of Lecture Notes in Computer Science, 74--91. Cham, Switzerland: Springer Science and Business Media Deut...
2024
-
[32]
G.; Kirillov, A.; and Girdhar, R
Cheng, B.; Misra, I.; Schwing, A. G.; Kirillov, A.; and Girdhar, R. 2022. Masked-attention Mask Transformer for Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1290--1299. Los Alamitos, CA, USA: IEEE Computer Society
2022
-
[33]
Deng, B.; Tucker, R.; Li, Z.; Guibas, L.; Snavely, N.; and Wetzstein, G. 2024. Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion. In ACM SIGGRAPH 2024 Conference Papers, 1--11. New York, NY, USA: Association for Computing Machinery. Article 27
2024
-
[34]
A.; and Owens, A
Feng, C.; Chen, Z.; Ho y \'n ski, A.; Efros, A. A.; and Owens, A. 2025. GPS as a Control Signal for Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2766--2778. Los Alamitos, CA, USA: IEEE Computer Society
2025
-
[35]
M.; Rasch, M
Gretton, A.; Borgwardt, K. M.; Rasch, M. J.; Sch \"o lkopf, B.; and Smola, A. 2012. A Kernel Two-Sample Test. Journal of Machine Learning Research, 13(25): 723--773
2012
-
[36]
Haas, L.; Skreta, M.; Alberti, S.; and Finn, C. 2024. PIGEON : Predicting Image Geolocations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12893--12902. Los Alamitos, CA, USA: IEEE Computer Society
2024
-
[37]
Haklay, M.; and Weber, P. 2008. OpenStreetMap : User-Generated Street Maps. IEEE Pervasive Computing, 7(4): 12--18
2008
-
[38]
Hall, M.; Ross, C.; Williams, A.; Carion, N.; Drozdzal, M.; and Romero-Soriano, A. 2024. DIG In : Evaluating Disparities in Image Generations with Indicators for Geographic Diversity. Transactions on Machine Learning Research
2024
-
[39]
Hessel, J.; Holtzman, A.; Forbes, M.; Le Bras, R.; and Choi, Y. 2021. CLIPScore : A Reference-free Evaluation Metric for Image Captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 7514--7528. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics
2021
-
[40]
Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; and Hochreiter, S. 2017. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems (NeurIPS), volume 30, 6626--6637. Red Hook, NY, USA: Curran Associates, Inc
2017
-
[41]
M.; Chen, J.; Kang, Y.; Kim, J.; Lee, J.; Duarte, F.; and Ratti, C
Jang, K. M.; Chen, J.; Kang, Y.; Kim, J.; Lee, J.; Duarte, F.; and Ratti, C. 2024. Place identity: a generative AI 's perspective. Humanities and Social Sciences Communications, 11: 1156
2024
-
[42]
M.; Scherer, S.; Krishna, M.; and Garg, S
Keetha, N.; Mishra, A.; Karhade, J.; Jatavallabhula, K. M.; Scherer, S.; Krishna, M.; and Garg, S. 2023. AnyLoc : Towards Universal Visual Place Recognition. IEEE Robotics and Automation Letters, 9(2): 1286--1293
2023
-
[43]
Li, Z.; Li, Z.; Cui, Z.; Pollefeys, M.; and Oswald, M. R. 2024 a . Sat2Scene : 3D Urban Scene Generation from Satellite Images with Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7141--7150. Los Alamitos, CA, USA: IEEE Computer Society
2024
-
[44]
Li, Z.; Zhang, J.; Lin, Q.; Xiong, J.; Long, Y.; Deng, X.; Zhang, Y.; Liu, X.; Huang, M.; Xiao, Z.; et al. 2024 b . Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding. arXiv preprint. arXiv:2405.08748
Pith/arXiv arXiv 2024
-
[45]
Mapillary . 2024. An Introduction to Mapillary . https://help.mapillary.com/hc/en-us/articles/115001770269-An-Introduction-to-Mapillary. Accessed: 2026-06-22
arXiv 2024
-
[46]
R.; and Kontschieder, P
Neuhold, G.; Ollmann, T.; Bul \`o , S. R.; and Kontschieder, P. 2017. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 5000--5009. Los Alamitos, CA, USA: IEEE Computer Society
2017
-
[47]
Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. 2024. DINOv2 : Learning Robust Visual Features without Supervision. Transactions on Machine Learning Research
2024
-
[48]
Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; M \"u ller, J.; Penna, J.; and Rombach, R. 2024. SDXL : Improving Latent Diffusion Models for High-Resolution Image Synthesis. In International Conference on Learning Representations (ICLR). Vienna, Austria: OpenReview.net
2024
-
[49]
V.; Lin, S
Ramaswamy, V. V.; Lin, S. Y.; Zhao, D.; Adcock, A.; van der Maaten, L.; Ghadiyaram, D.; and Russakovsky, O. 2023. GeoDE : A Geographically Diverse Evaluation Dataset for Object Recognition. In Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 66127--66137. Red Hook, NY, USA: Curran Associates, Inc
2023
-
[50]
Shang, Y.; Lin, Y.; Zheng, Y.; Fan, H.; Ding, J.; Feng, J.; Chen, J.; Tian, L.; and Li, Y. 2024. UrbanWorld : An Urban World Model for 3D City Generation. arXiv preprint. arXiv:2407.11965
arXiv 2024
-
[51]
Stability AI . 2024. Introducing Stable Diffusion 3.5. https://stability.ai/news/introducing-stable-diffusion-3-5. Accessed: 2026-06-22
2024
-
[52]
Sureddy, A.; Padalia, D.; Periyakaruppa, N.; Saha, O.; Williams, A.; Romero-Soriano, A.; Richards, M.; Kirichenko, P.; and Hall, M. 2024. Decomposed Evaluations of Geographic Disparities in Text-to-Image Models. arXiv preprint. arXiv:2406.11988
arXiv 2024
-
[53]
K.; and Shah, M
Vivanco Cepeda, V.; Nayak, G. K.; and Shah, M. 2023. GeoCLIP : Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization. In Advances in Neural Information Processing Systems (NeurIPS), 8690--8701. Red Hook, NY, USA: Curran Associates, Inc
2023
-
[54]
Xie, H.; Chen, Z.; Hong, F.; and Liu, Z. 2024. CityDreamer : Compositional Generative Model of Unbounded 3D Cities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9666--9675. Los Alamitos, CA, USA: IEEE Computer Society
2024
-
[55]
Xu, N.; and Qin, R. 2024. Geospecific View Generation -- Geometry-Context Aware High-Resolution Ground View Inference from Satellite Views. In European Conference on Computer Vision (ECCV), volume 15105 of Lecture Notes in Computer Science, 349--366. Cham, Switzerland: Springer Nature Switzerland
2024
-
[56]
Zhai, X.; Mustafa, B.; Kolesnikov, A.; and Beyer, L. 2023. Sigmoid Loss for Language Image Pre-Training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 11975--11986. Los Alamitos, CA, USA: IEEE Computer Society
2023
-
[57]
A.; Shechtman, E.; and Wang, O
Zhang, R.; Isola, P.; Efros, A. A.; Shechtman, E.; and Wang, O. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 586--595. Los Alamitos, CA, USA: IEEE Computer Society
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.