ChaosBench-Logic v2: Evaluating LLM Logical Reasoning over Dynamical Systems at Scale
Pith reviewed 2026-06-30 14:10 UTC · model grok-4.3
The pith
Even frontier LLMs score near random on regime-transition reasoning over dynamical systems while reaching moderate success on given-premise deduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
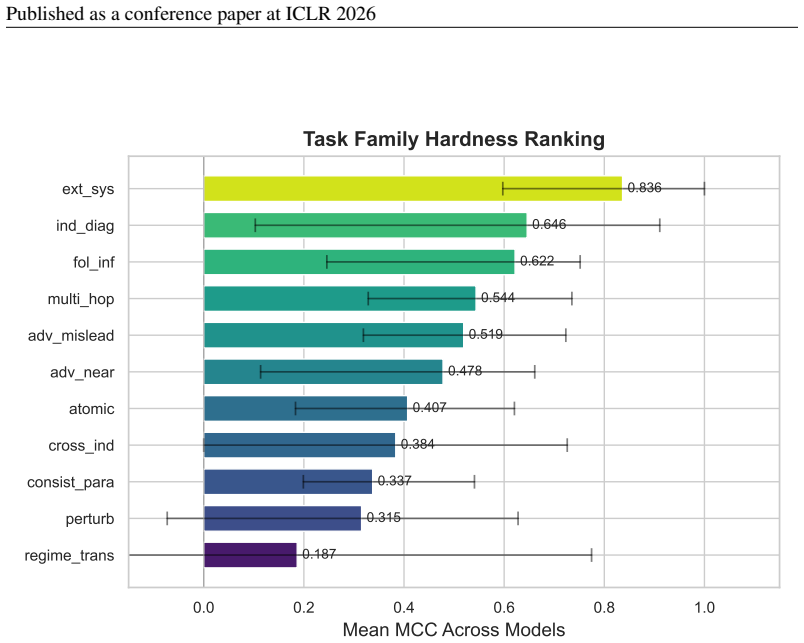
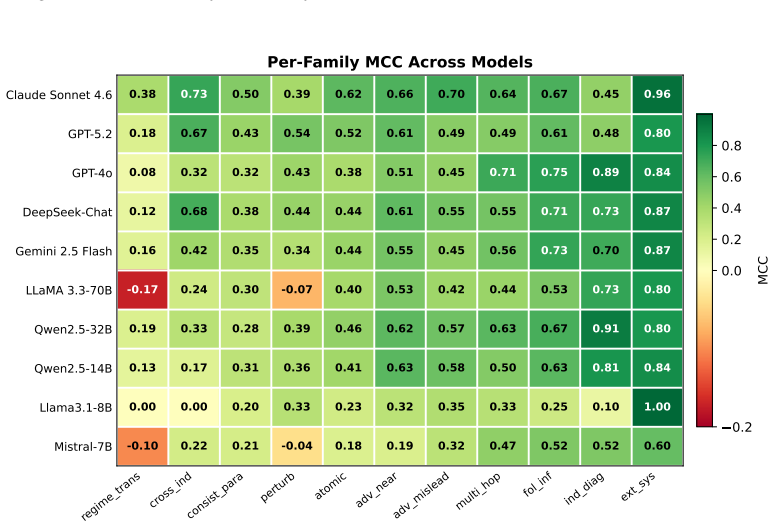
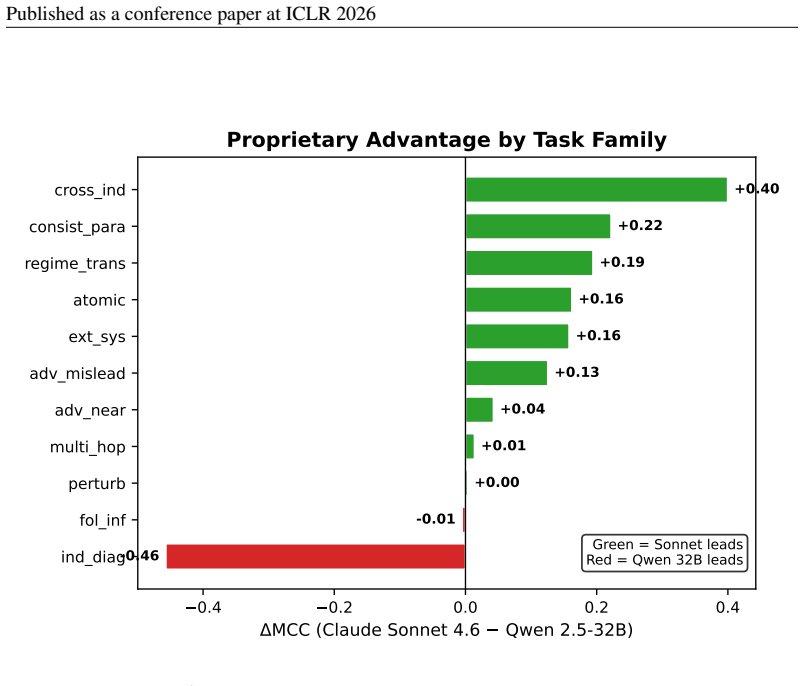
ChaosBench-Logic v2 supplies 40,886 questions over 165 dynamical systems formalized with 27 FOL predicates and 78 axiom edges, together with the CARE evaluation protocol. When 14 models are tested, regime-transition reasoning yields MCC near 0.05 whereas FOL deduction with given premises reaches MCC of 0.52; proprietary-model gains concentrate on cross-indicator (+0.40) and consistency tasks, open-source Qwen 2.5-32B leads indicator diagnostics, and two models exhibit negative MCC on bifurcation questions confirmed by confusion-matrix analysis.
What carries the argument
ChaosBench-Logic v2 benchmark of questions derived from 165 dynamical systems via 27 FOL predicates and 78 axiom edges, scored under the CARE protocol that surfaces prior collapse, paraphrase inconsistency, and parameter-dependent reasoning failures.
If this is right
- Regime-transition reasoning constitutes a distinct and persistent weakness not captured by conventional binary accuracy benchmarks.
- Proprietary models hold a measurable advantage of +0.40 MCC on cross-indicator and consistency tasks.
- Open-source models such as Qwen 2.5-32B outperform on indicator diagnostics with scores of 0.91 versus 0.45.
- Negative MCC values on bifurcation questions reflect systematic anti-correlation rather than random error.
- The CARE protocol isolates three specific pathologies: prior collapse, paraphrase inconsistency, and inability to handle parameter-dependent dynamics.
Where Pith is reading between the lines
- If the encoding premise holds, current LLMs are unlikely to serve as reliable standalone reasoners for scientific tasks that require predicting qualitative shifts in system behavior.
- The benchmark structure could be reused to compare logical reasoning performance against direct simulation outputs on the same dynamical systems.
- The observed gap between deduction with premises and open-ended regime reasoning points to a training-data limitation that future model development might target explicitly.
Load-bearing premise
The 27 FOL predicates and 78 axiom edges correctly and exhaustively encode the logical structure of the 165 dynamical systems so that low model scores reflect reasoning deficits rather than formalization mismatches.
What would settle it
A direct comparison of model answers against numerical simulation trajectories for a random sample of the 165 systems, showing that the FOL encoding systematically diverges from the actual dynamics on questions where models fail, would indicate the benchmark measures encoding mismatch rather than reasoning ability.
Figures
read the original abstract
Standard accuracy on binary reasoning benchmarks hides critical failure modes: prior collapse, inconsistency under paraphrase, and inability to reason about parameter-dependent dynamics. We present ChaosBench-Logic v2, a 40,886-question benchmark over 165 dynamical systems with 27 FOL predicates and 78 axiom edges, together with CARE (Calibration- and Adversarial-Robust Evaluation), a protocol that surfaces these pathologies. Evaluating 14 models, we find that regime-transition reasoning remains near random (MCC = 0.05) even for frontier models, whereas FOL deduction with given premises reaches MCC = 0.52. Per-family decomposition shows that the proprietary-model advantage concentrates on cross-indicator (+0.40) and consistency tasks, while open-source Qwen 2.5-32B dominates indicator diagnostics (0.91 vs. 0.45). Two models exhibit negative MCC on bifurcation questions, confirmed as systematic anti-correlation via confusion-matrix analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChaosBench-Logic v2, a benchmark of 40,886 questions over 165 dynamical systems formalized via 27 FOL predicates and 78 axiom edges, together with the CARE evaluation protocol. Evaluating 14 LLMs, it reports near-random performance on regime-transition reasoning (MCC = 0.05) even for frontier models, in contrast to MCC = 0.52 on FOL deduction with given premises; proprietary models show advantages on cross-indicator and consistency tasks while open-source models like Qwen 2.5-32B lead on indicator diagnostics, and two models exhibit negative MCC on bifurcation questions confirmed via confusion matrices.
Significance. If the formalization holds, the work identifies concrete failure modes in LLM logical reasoning over parameter-dependent dynamical systems that standard accuracy metrics obscure. The large scale, task-family decomposition, and adversarial-robust protocol provide granular, falsifiable evidence of specific deficits (regime transitions, consistency under paraphrase) that could guide targeted improvements. The explicit per-family and confusion-matrix analyses are methodological strengths.
major comments (3)
- [Abstract] Abstract: the 27 FOL predicates and 78 axiom edges are presented as encoding the logical structure of the 165 systems, yet no derivation method, expert validation, consistency checks against known analytic behaviors, or inter-rater agreement is supplied. This validation is load-bearing for interpreting MCC = 0.05 on regime transitions as evidence of reasoning deficits rather than encoding mismatch.
- [Abstract] Abstract and §4 (question generation): the manuscript supplies no details on how the 40,886 questions were generated from the predicates/axioms, how predicate validation was performed, or what statistical controls (multiple-comparison correction, baseline randomization) accompany the reported MCC values. Without these, the headline contrast between regime-transition and FOL-deduction performance cannot be verified.
- [Results] Results on bifurcation questions: the claim of systematic anti-correlation for the two models with negative MCC rests on confusion-matrix analysis, but the abstract provides neither the matrices nor the exact counts or controls used to establish that the anti-correlation is not an artifact of class imbalance or question sampling.
minor comments (1)
- [Abstract] Abstract: the reported proprietary-model advantage of +0.40 on cross-indicator tasks does not state the reference baseline against which the delta is computed.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify important gaps in the presentation of our formalization and evaluation details. We respond to each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 27 FOL predicates and 78 axiom edges are presented as encoding the logical structure of the 165 systems, yet no derivation method, expert validation, consistency checks against known analytic behaviors, or inter-rater agreement is supplied. This validation is load-bearing for interpreting MCC = 0.05 on regime transitions as evidence of reasoning deficits rather than encoding mismatch.
Authors: We agree that the abstract omits these details and that they are necessary for interpreting the results. Section 3 of the manuscript describes the predicates as derived from standard FOL encodings of dynamical system phase-space properties drawn from the mathematical literature. In the revision we will expand the abstract with a concise description of the derivation approach and add a dedicated validation subsection reporting consistency checks against analytic solutions for canonical systems (e.g., fixed-point and bifurcation conditions) together with inter-rater agreement statistics from two domain experts. These changes will be included in the next version. revision: yes
-
Referee: [Abstract] Abstract and §4 (question generation): the manuscript supplies no details on how the 40,886 questions were generated from the predicates/axioms, how predicate validation was performed, or what statistical controls (multiple-comparison correction, baseline randomization) accompany the reported MCC values. Without these, the headline contrast between regime-transition and FOL-deduction performance cannot be verified.
Authors: We acknowledge that explicit procedural details are missing from both the abstract and §4. The revised manuscript will expand §4 to document the template-based generation pipeline that instantiates axiom-derived questions while maintaining class balance, the manual predicate validation performed on a random sample, and the statistical controls: MCC is used because it corrects for imbalance, baseline random-guessing MCC values are near zero, and no multiple-comparison correction was applied because the task families were defined a priori. These additions will enable independent verification of the reported performance contrast. revision: yes
-
Referee: [Results] Results on bifurcation questions: the claim of systematic anti-correlation for the two models with negative MCC rests on confusion-matrix analysis, but the abstract provides neither the matrices nor the exact counts or controls used to establish that the anti-correlation is not an artifact of class imbalance or question sampling.
Authors: The confusion matrices, exact counts, and controls demonstrating that negative MCC is not explained by imbalance or sampling are already reported in §5.3. We agree, however, that the abstract should not assert the finding without reference to this evidence. We will therefore revise the abstract to include a short clause summarizing the confusion-matrix support for the anti-correlation claim. This constitutes a partial revision focused on the abstract. revision: partial
Circularity Check
Empirical benchmark with no derivation chain or self-referential reductions
full rationale
The paper is an empirical evaluation benchmark (ChaosBench-Logic v2) that constructs 27 FOL predicates and 78 axiom edges over 165 dynamical systems and reports model performance metrics such as MCC scores. No equations, predictions, or first-principles derivations are claimed that reduce to inputs by construction. The encoding is presented as an input to the benchmark rather than derived from model outputs or prior fitted results within the paper. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the provided content. The central claims rest on direct model evaluations against the fixed benchmark, making the work self-contained against external benchmarks with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simple tools to study global dynamics in non-axisymmetric galactic potentials – I.Astronomy and Astrophysics Supplement Series, 147:205–228,
8 Published as a conference paper at ICLR 2026 Pablo M Cincotta and Carles Sim ´o. Simple tools to study global dynamics in non-axisymmetric galactic potentials – I.Astronomy and Astrophysics Supplement Series, 147:205–228,
2026
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning chal- lenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
FOLIO: Natural language reasoning with first-order logic.arXiv preprint arXiv:2209.00840,
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Schmitt, Hinrich Sch¨utze, V olker Tresp, and Nanyun Peng. FOLIO: Natural language reasoning with first-order logic.arXiv preprint arXiv:2209.00840,
-
[5]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. SciBench: Evaluating college-level sci- entific problem-solving abilities of large language models.arXiv preprint arXiv:2307.10635, 2023a. 9 Published as a conference paper at ICLR 2026 Xuezhi Wang, Jason Wei, Dale Schuu...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
FluidTrampoline is strongly mixing. Strongly mix- ing⇒weakly mixing⇒ergodic⇒bounded. Is it bounded?
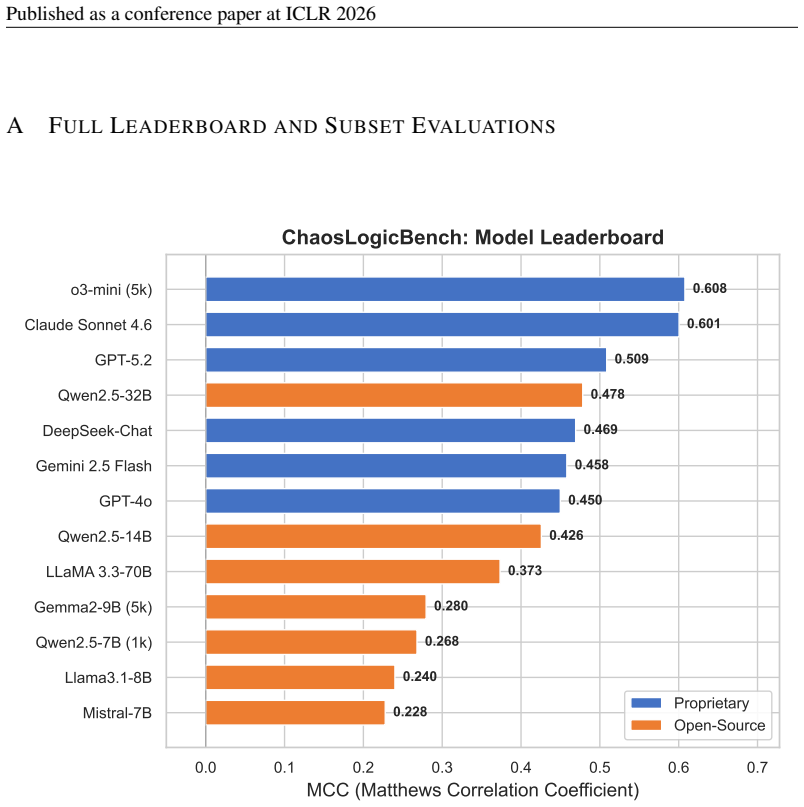
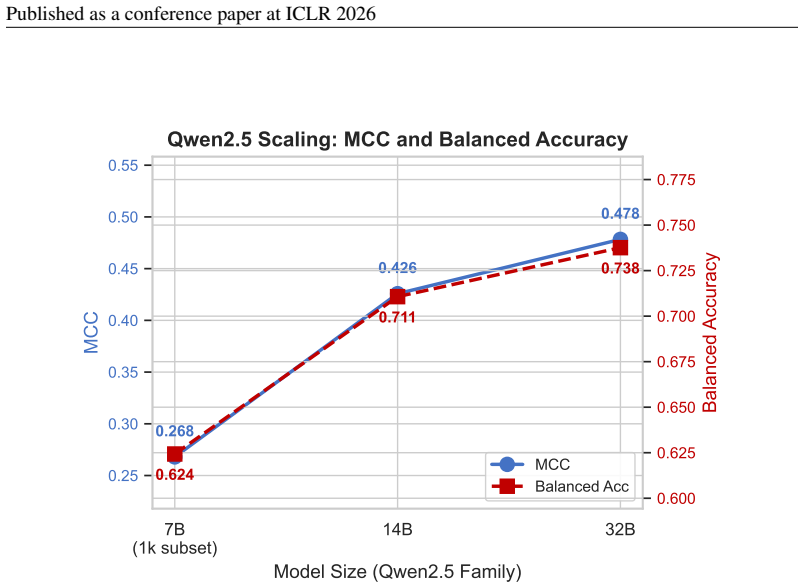
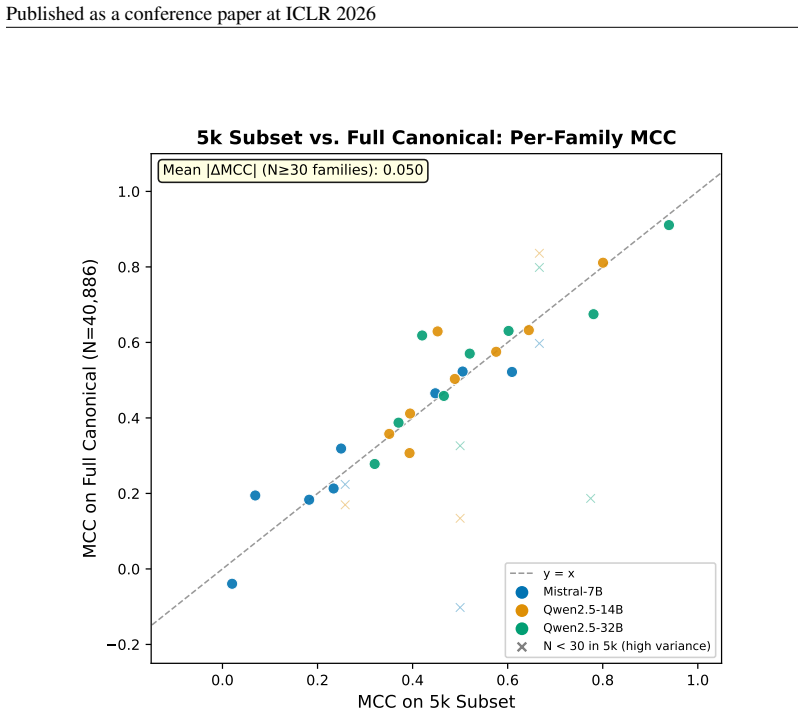
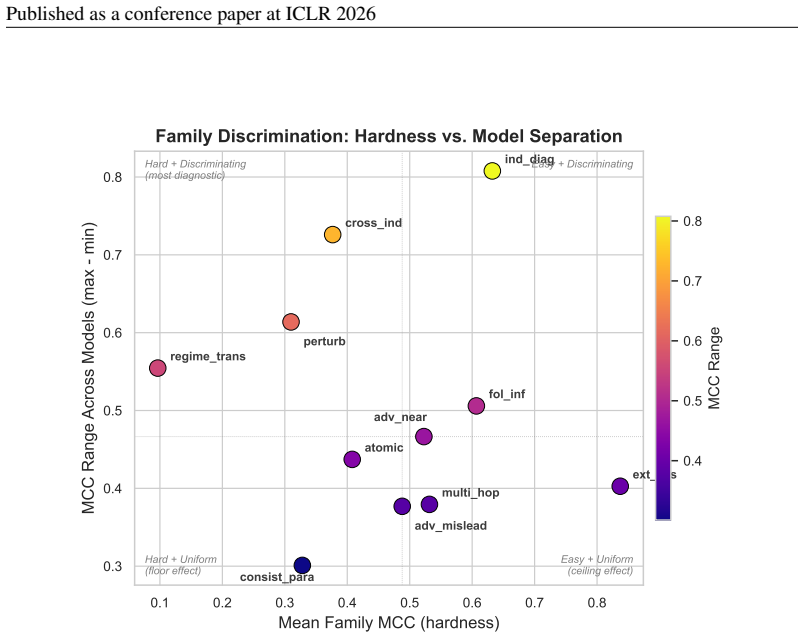
10 Published as a conference paper at ICLR 2026 A FULLLEADERBOARD ANDSUBSETEVALUATIONS 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 MCC (Matthews Correlation Coefficient) Mistral-7B Llama3.1-8B Qwen2.5-7B (1k) Gemma2-9B (5k) LLaMA 3.3-70B Qwen2.5-14B GPT-4o Gemini 2.5 Flash DeepSeek-Chat Qwen2.5-32B GPT-5.2 Claude Sonnet 4.6 o3-mini (5k) 0.228 0.240 0.268 0.280 0.373 ...
2026
-
[7]
Model TP FP TN FN MCC Bal
confusion matrices. Model TP FP TN FN MCC Bal. Acc LLaMA 3.3-70B 9 17 20 22 −0.173 0.415 Mistral-7B(from aggregate) −0.102 – Claude Sonnet 4.6 15 5 32 16 +0.381 0.674 H INVALIDRATES Most models produce zero invalids. Mistral-7B has the highest rate at 1.1%; LLaMA 3.1-8B <0.01%; all others 0.0%. I PROMPTTEMPLATE Answer the following question about the dyna...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.