Tracking Representation Dynamics in Large Language Models with Persistent Homology
Pith reviewed 2026-06-26 21:01 UTC · model grok-4.3
The pith
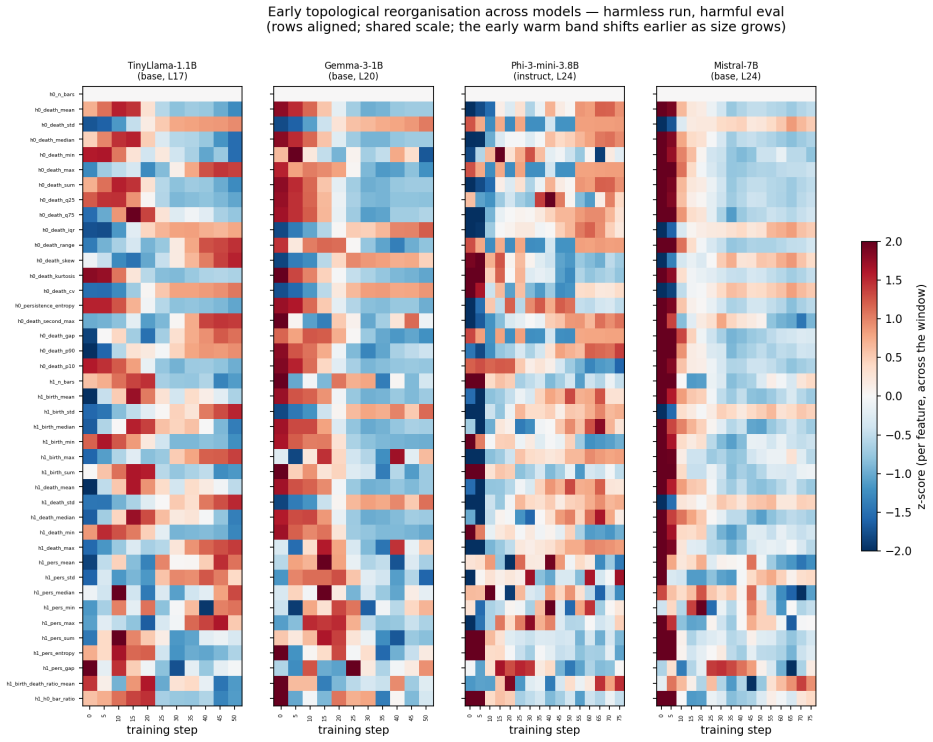
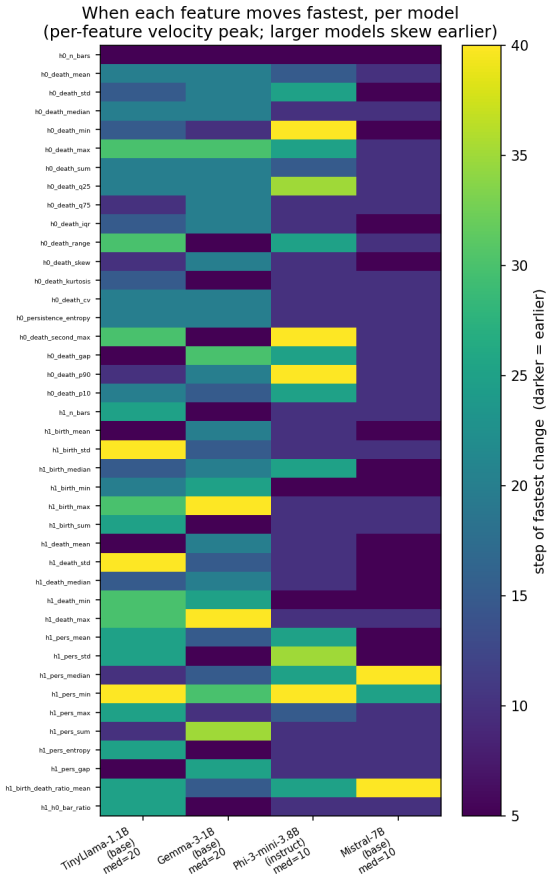
Most topological reorganization in LLM activation spaces occurs during the earliest stages of alignment fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
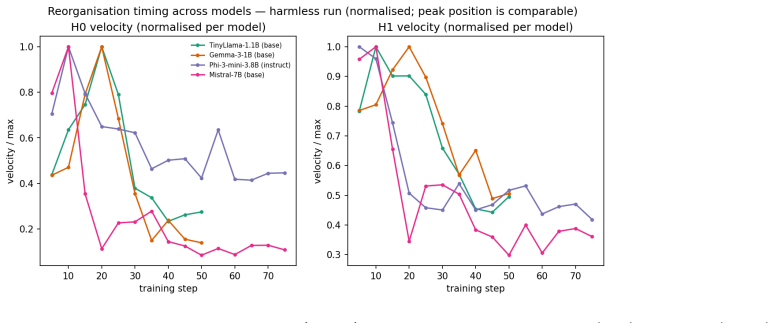
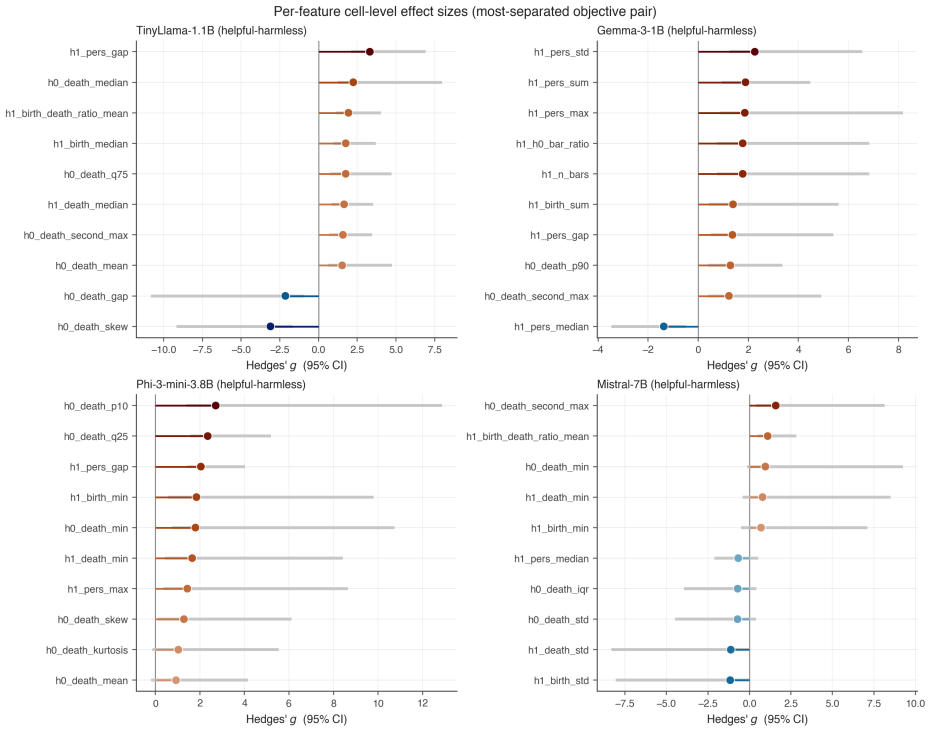
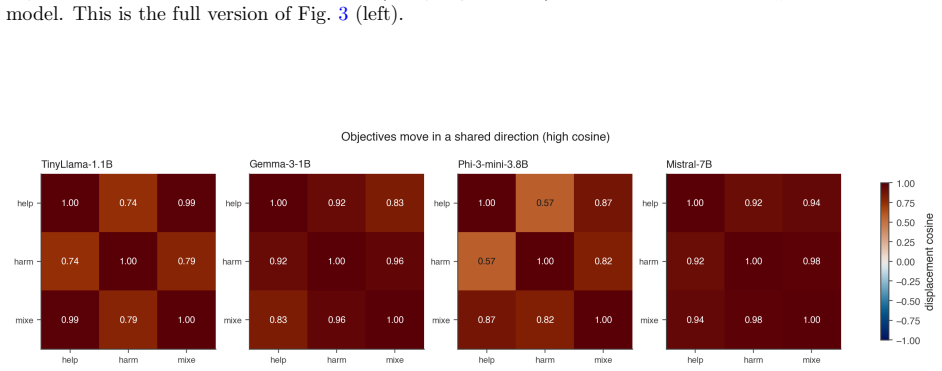
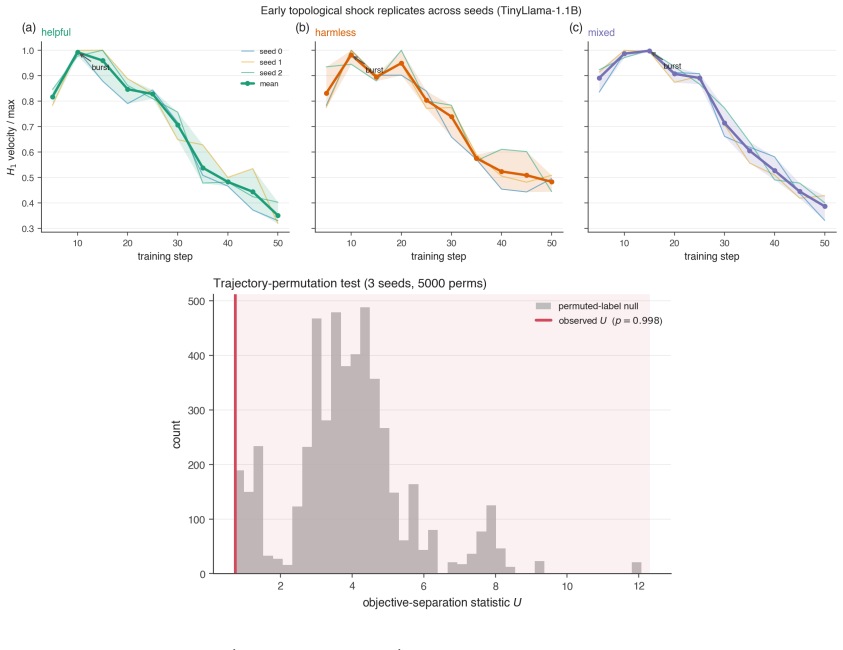
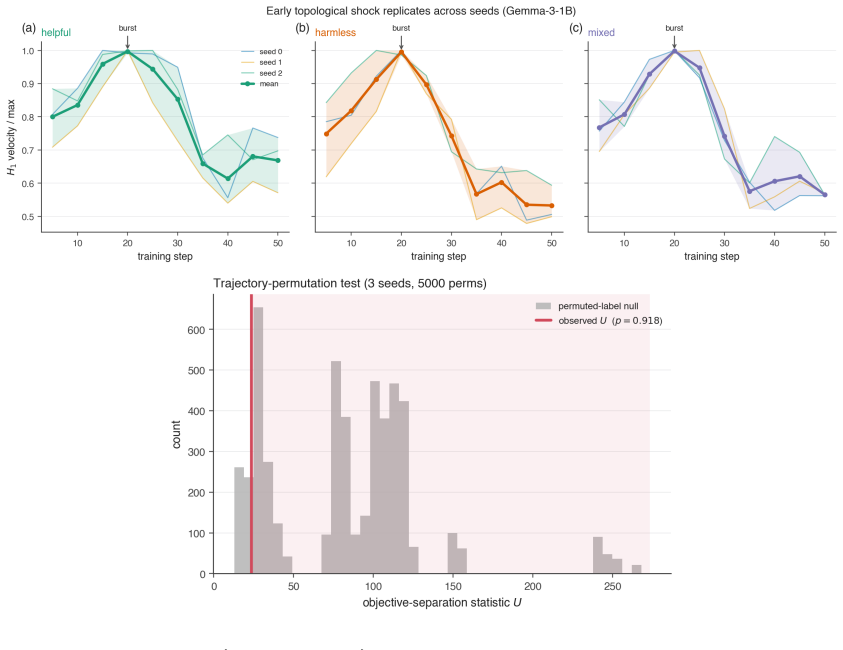
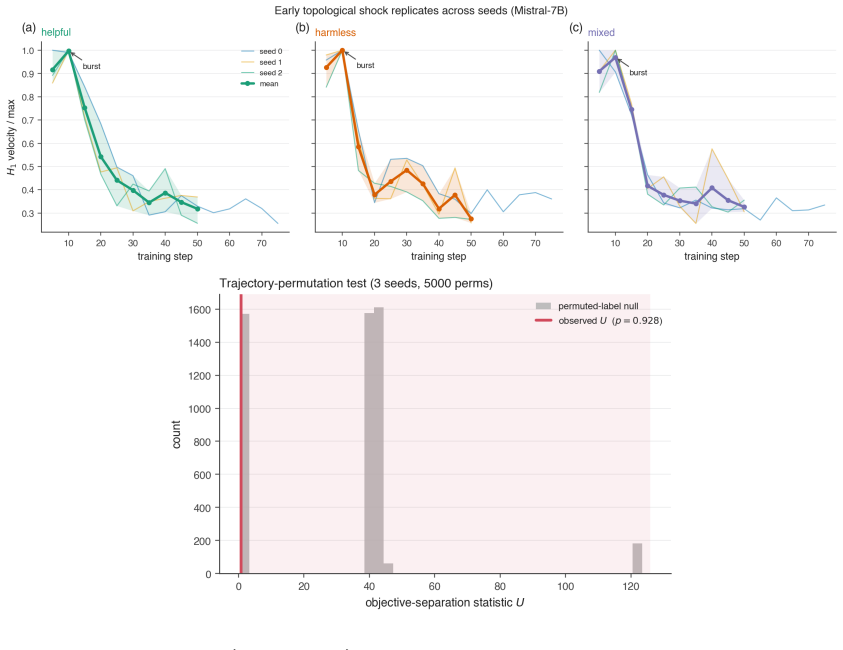
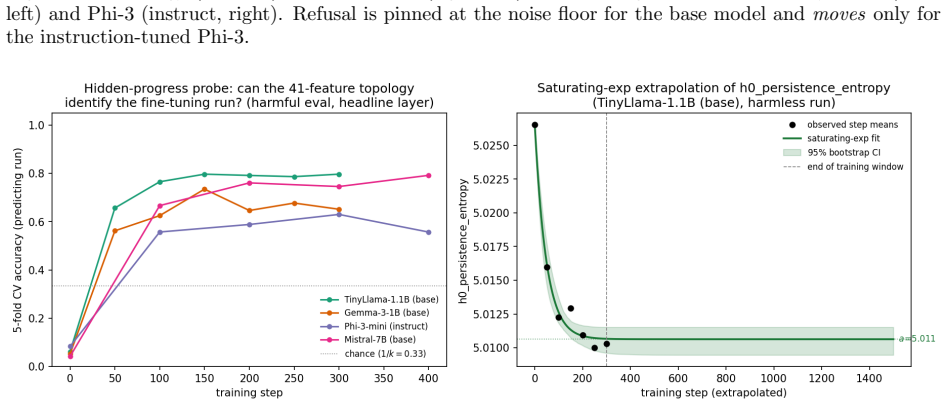
By computing persistent homology on activation spaces throughout fine-tuning, the majority of topological reorganization is found to occur in the earliest stages of training. Dense checkpointing reveals a transient peak in topological activity followed by rapid stabilization. Different alignment objectives produce distinguishable topological trajectories, and instruction-tuned models evolve differently from their pretrained counterparts.
What carries the argument
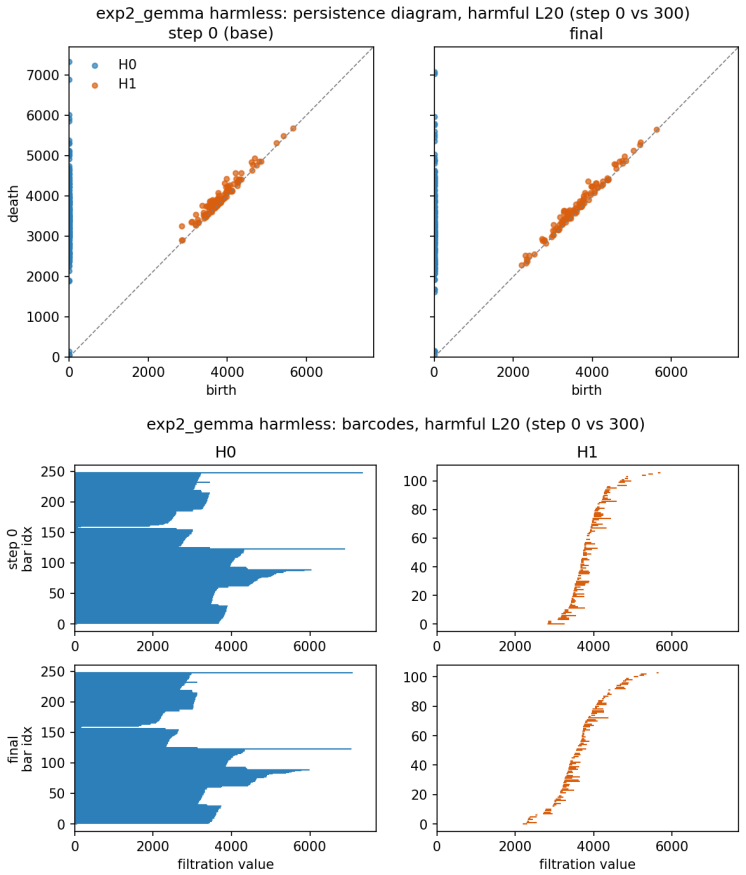
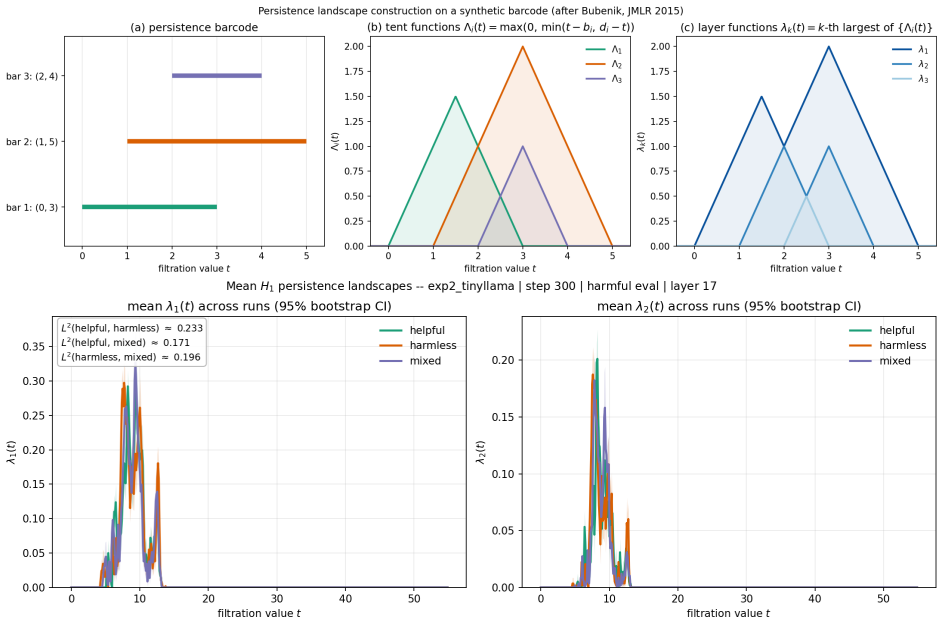
Persistent homology applied to activation spaces to extract topological features such as connected components and cycles across training checkpoints.
If this is right
- Alignment training can be divided into an early high-activity phase and a later stable phase based on topological measures.
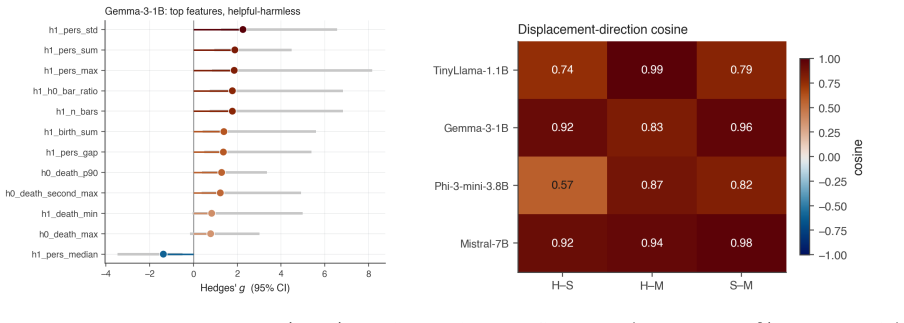
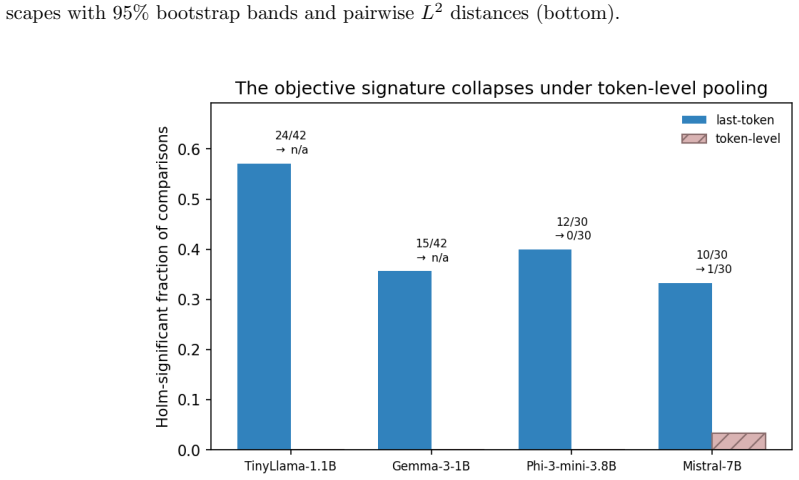
- Different alignment objectives leave distinct topological signatures in the activation spaces.
- Instruction-tuned models follow qualitatively different topological paths than purely pretrained models.
- Behavioral metrics may miss representation-level stabilization that occurs after the initial peak.
Where Pith is reading between the lines
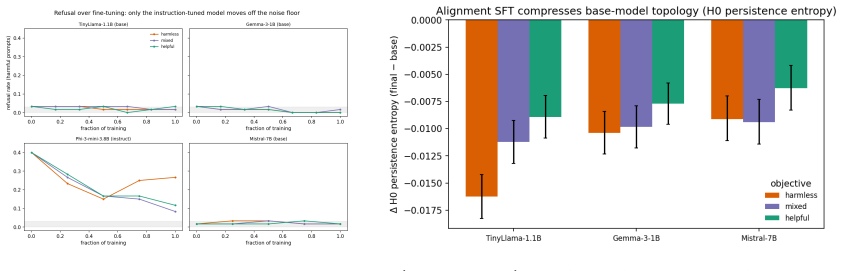
- The early stabilization suggests alignment may largely fix core representational structure after a short initial period.
- Persistent homology could be tested as a monitoring tool to decide when fine-tuning has reached diminishing returns on representation change.
- The approach might extend to comparing topological evolution under reinforcement learning from human feedback versus supervised fine-tuning.
Load-bearing premise
The topological features extracted from activation spaces reflect changes driven by the alignment process rather than incidental effects of model architecture or training geometry.
What would settle it
Running the same persistent-homology analysis on a new set of models and observing continued topological activity throughout the full fine-tuning schedule instead of early stabilization would contradict the central observation.
Figures




read the original abstract
Large language models are commonly aligned through supervised fine-tuning, yet little is known about how their internal representations evolve during this process. We study alignment dynamics using persistent homology by tracking the topology of activation spaces throughout fine-tuning. Across four transformer language models ranging from 1B to 7B parameters and three alignment objectives corresponding to helpful, harmless, and mixed training data, we find that the majority of topological reorganization occurs during the earliest stages of training. A dense checkpoint analysis reveals a transient peak in topological activity followed by rapid stabilization. We further show that different alignment objectives induce distinguishable topological trajectories, while instruction-tuned and pretrained models exhibit qualitatively different patterns of evolution. Our results suggest that persistent homology provides a complementary perspective on alignment, revealing representation-level changes that are not apparent from behavioral metrics alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies persistent homology to activation spaces of transformer LLMs during supervised fine-tuning for alignment. Across four models (1B–7B parameters) and three objectives (helpful, harmless, mixed), it reports that the majority of topological reorganization occurs in the earliest training stages, with a transient peak in activity followed by rapid stabilization. Different alignment objectives produce distinguishable topological trajectories, and instruction-tuned models differ qualitatively from pretrained ones. The work positions persistent homology as a complementary lens on alignment dynamics beyond behavioral metrics.
Significance. If the central observational patterns hold under appropriate controls, the work would be significant for introducing topological data analysis to the study of LLM representation evolution during alignment. The multi-model, multi-objective design and emphasis on early-training dynamics provide a concrete starting point for further investigation of representation-level changes.
major comments (1)
- [Abstract] The central claim that the observed early transient peak and stabilization reflect alignment-specific dynamics requires evidence that these topological signatures are not generic consequences of gradient descent on transformer activations. The manuscript does not report control experiments (continued pretraining on non-instruction data, random-label fine-tuning, or non-alignment distributions) that would isolate the effect of the alignment objective; this absence is load-bearing for interpreting the results as alignment-driven rather than architecture- or optimization-driven.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the opportunity to clarify our work. Below we respond directly to the major comment.
read point-by-point responses
-
Referee: [Abstract] The central claim that the observed early transient peak and stabilization reflect alignment-specific dynamics requires evidence that these topological signatures are not generic consequences of gradient descent on transformer activations. The manuscript does not report control experiments (continued pretraining on non-instruction data, random-label fine-tuning, or non-alignment distributions) that would isolate the effect of the alignment objective; this absence is load-bearing for interpreting the results as alignment-driven rather than architecture- or optimization-driven.
Authors: We agree that the manuscript lacks explicit control experiments of the form suggested (continued pretraining on non-instruction data, random-label fine-tuning, or non-alignment distributions), and that this limits the strength of claims that the observed topological signatures are driven specifically by alignment objectives rather than by generic properties of gradient descent on transformer activations. Our existing design does compare trajectories across three distinct alignment objectives and between pretrained and instruction-tuned models, which produces distinguishable patterns; however, these comparisons do not fully isolate alignment from other optimization effects. We will revise the manuscript to (1) qualify the abstract and discussion language to avoid implying exclusivity to alignment, (2) add an explicit limitations subsection that states the absence of the recommended controls, and (3) outline how such controls could be implemented in follow-up work. We view this as a substantive but addressable limitation rather than a fatal flaw, given the multi-objective and multi-model scope already present. revision: yes
Circularity Check
No circularity: purely observational measurements of topological features
full rationale
The paper reports direct empirical observations obtained by computing persistent homology on activation point clouds at successive fine-tuning checkpoints across multiple models and objectives. No equations, fitted parameters, or predictions are presented that reduce a claimed quantity to a quantity defined from the same data. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central claims. The reported transient peak and stabilization are measurements, not derivations that collapse by construction. This is the expected non-finding for an observational study whose load-bearing steps are external data collection and standard topological computation rather than internal algebraic reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-3 technical report: A highly capable language model locally on your phone.URL https://arxiv
Abdin, Marah, Aneja, Jyoti, Awadalla, Hany, Awadallah, Ahmed, Awan, Ammar Ahmad, Bach, Nguyen, Bahree, Amit, Bakhtiari, Arash, Bao, Jianmin, Behl, Harkirat,et al.2024. Phi-3 technical report: A highly capable language model locally on your phone.URL https://arxiv. org/abs/2404.14219,2(6),
Pith/arXiv arXiv 2024
-
[2]
Refusal in Language Models Is Mediated by a Single Direction.arXiv preprint arXiv:2406.04093. Bai, Yuntao, Jones, Andy, Ndousse, Kamal, Askell, Amanda, Chen, Anna, DasSarma, Nova, Drain, Dawn, Fort, Stanislav, Ganguli, Deep, Henighan, Tom, Joseph, Nicholas, Kadavath, Saurav, Kernion, Jackson, Conerly, Tom, El-Showk, Sheer, Elhage, Nelson, Hatfield- Dodds,...
-
[3]
Barak, Boaz, Edelman, Benjamin L., Goel, Surbhi, Kakade, Sham, Malach, Eran, & Zhang, Cyril
Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862. Barak, Boaz, Edelman, Benjamin L., Goel, Surbhi, Kakade, Sham, Malach, Eran, & Zhang, Cyril
-
[4]
Advances in Neural Information Processing Systems (NeurIPS)
Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit. Advances in Neural Information Processing Systems (NeurIPS). arXiv:2207.08799. Bauer, Ulrich
-
[5]
In: International Conference on Learning Representations (ICLR)
The Shape of Adversarial Influence: Characterizing LLM Latent Spaces with Persistent Homology. In: International Conference on Learning Representations (ICLR). Gardinazzi, Yuri,et al.2024. Persistent Topological Features in Large Language Models.arXiv preprint arXiv:2410.11042. Hu, Edward J, Shen, Yelong, Wallis, Phillip, Allen-Zhu, Zeyuan, Li, Yuanzhi, W...
arXiv 2024
-
[6]
Mechanistically Analyzing the Effects of Fine-Tuning on Procedurally Defined Tasks.In: International Conference on Learning Representations (ICLR). arXiv:2311.12786. Jiang, Albert Q., Sablayrolles, Alexandre, Mensch, Arthur, Bamford, Chris, Chaplot, Devendra Singh, de las Casas, Diego, Bressand, Florian, Lengyel, Gianna, Lample, Guil- laume, Saulnier, Luc...
-
[7]
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity.In: International Conference on Machine Learning (ICML). arXiv:2401.01967. Mesnard, Thomas, Hardin, Cassidy, Dadashi, Robert, Bhupatiraju, Surya, Pathak, Shreya, Sifre, Laurent, Rivi `ere, Morgane, Kale, Mihir Sanjay, Love, Juliette, Tafti, Pouya, Hussenot, L´eonard, Ses...
-
[8]
Moor, Michael, Horn, Max, Rieck, Bastian, & Borgwardt, Karsten
Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295. Moor, Michael, Horn, Max, Rieck, Bastian, & Borgwardt, Karsten
-
[9]
Ouyang, Long, Wu, Jeffrey, Jiang, Xu, Almeida, Diogo, Wainwright, Carroll, Mishkin, Pamela, Zhang, Chong, Agarwal, Sandhini, Slama, Katarina, Ray, Alex,et al.2022
Progress Measures for Grokking via Mechanistic Interpretability.In: International Conference on Learning Repre- sentations (ICLR). Ouyang, Long, Wu, Jeffrey, Jiang, Xu, Almeida, Diogo, Wainwright, Carroll, Mishkin, Pamela, Zhang, Chong, Agarwal, Sandhini, Slama, Katarina, Ray, Alex,et al.2022. Training language models to follow instructions with human fee...
2022
-
[10]
arXiv preprint arXiv:2605.06352
Topological Signatures of Grokking. arXiv preprint arXiv:2605.06352. Zhang, Peiyuan, Zeng, Guangtao, Wang, Tianduo, & Lu, Wei
-
[11]
TinyLlama: An open-source small language model.arXiv preprint arXiv:2401.02385. Zhou, Chunting, Liu, Pengfei, Xu, Puxin, Iyer, Srinivasan, Sun, Jiao, Mao, Yuning, Ma, Xuezhe, Efrat, Avia, Yu, Ping, Yu, Lili, Zhang, Susan, Ghosh, Gargi, Lewis, Mike, Zettle- moyer, Luke, & Levy, Omer
-
[12]
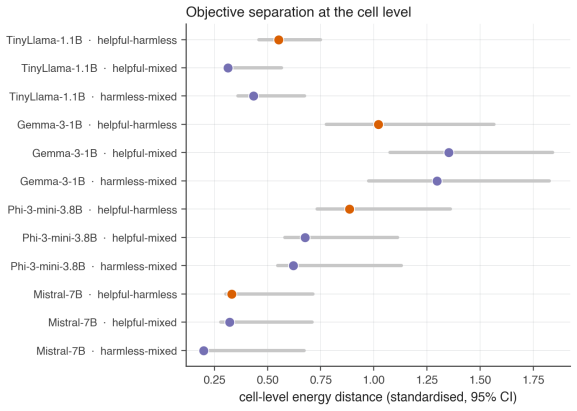
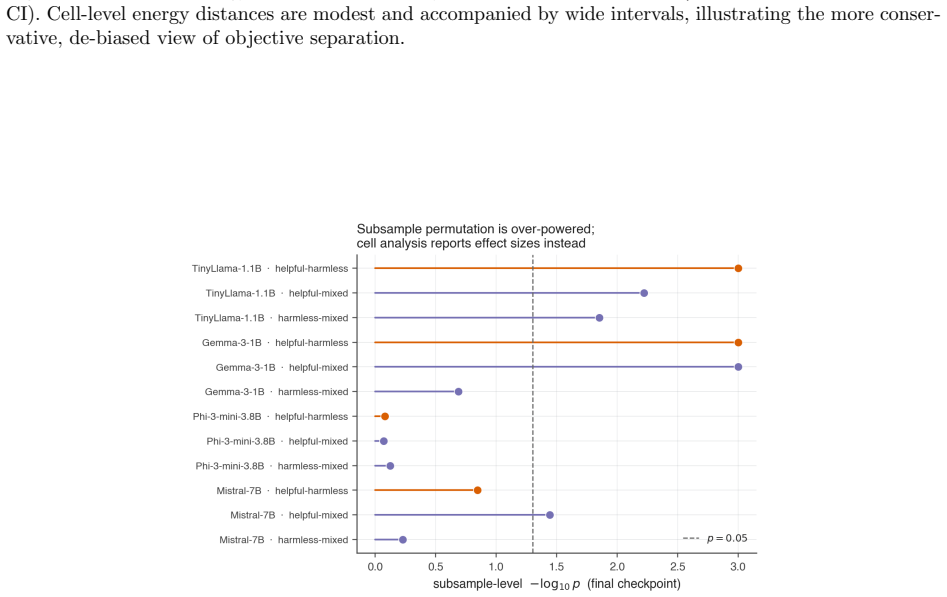
LIMA: Less Is More for Alignment.In: Advances in Neural Information Processing Systems (NeurIPS). arXiv:2305.11206. 9 A Supplementary Results A.1 Robustness Checks and Controls We performed a series of controls to verify that the observed topological phenomena are not artifacts of checkpoint ordering, simple geometric statistics, token selection, or the u...
-
[13]
Device selection follows the hierarchymps>cuda>cpu, allowing the same codebase to execute unchanged on CUDA-enabled systems
Model training and extraction use the Metal Performance Shaders (MPS) backend through PyTorch withbfloat16precision and scaled- dot-product attention (sdpa). Device selection follows the hierarchymps>cuda>cpu, allowing the same codebase to execute unchanged on CUDA-enabled systems. Software.The training and extraction pipeline uses PyTorch, Transformers, ...
2022
-
[14]
The 1B models are trained for 300 steps on 3000 examples with checkpoints every 50 steps
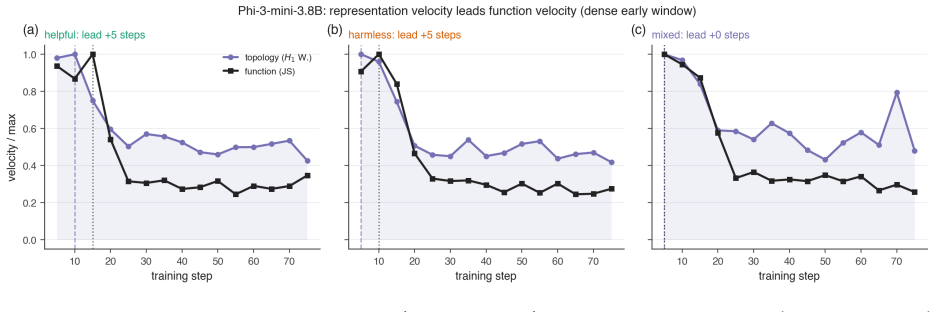
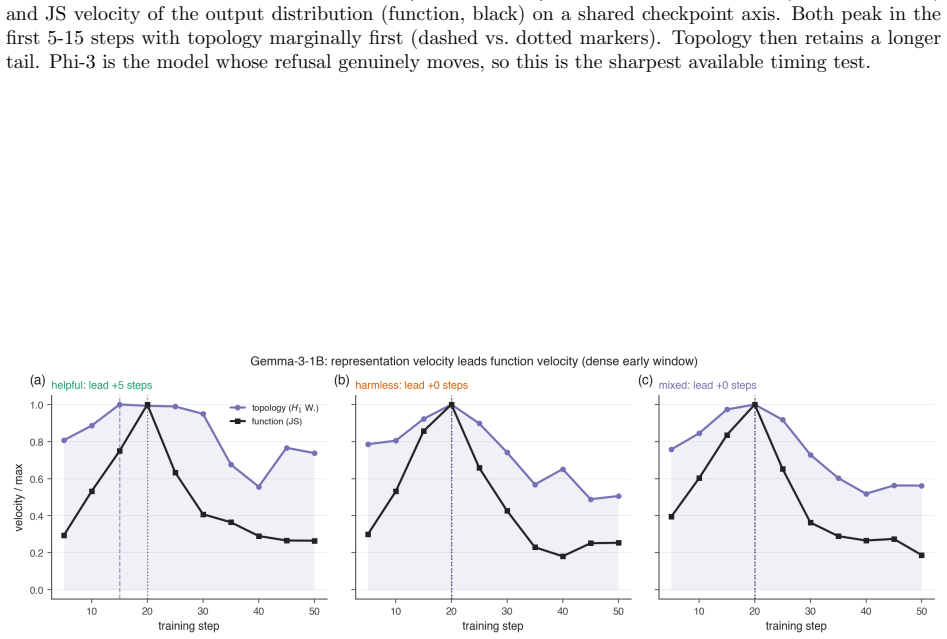
All objectives use identical hyperparameters and random seeds. The 1B models are trained for 300 steps on 3000 examples with checkpoints every 50 steps. The larger models are trained for 400 steps on 6000 examples with checkpoints every 100 steps. To resolve the earliest stages of alignment, we additionally perform a dense early-window analysis that check...
2026
-
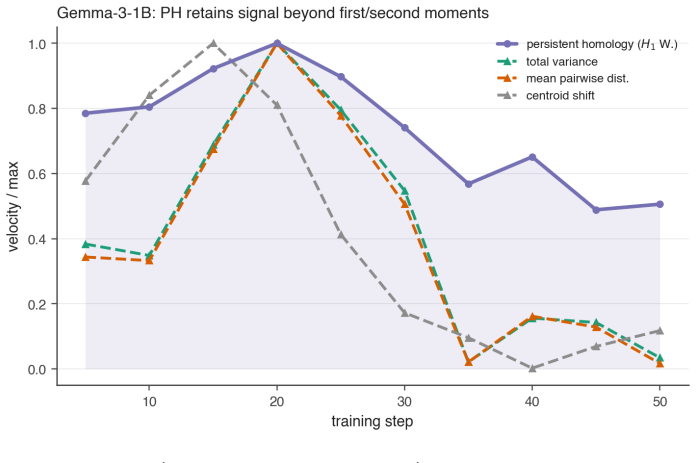
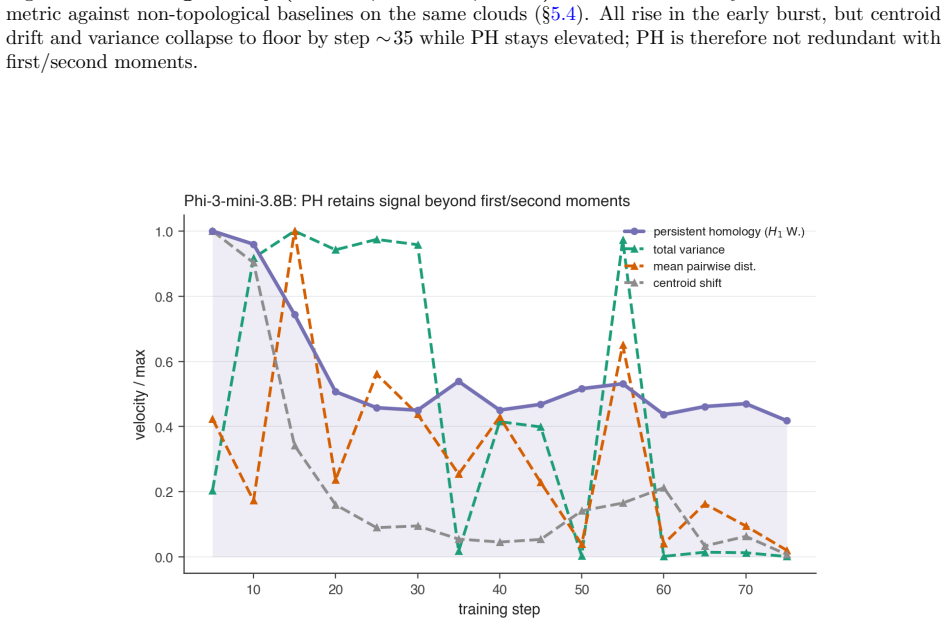
[15]
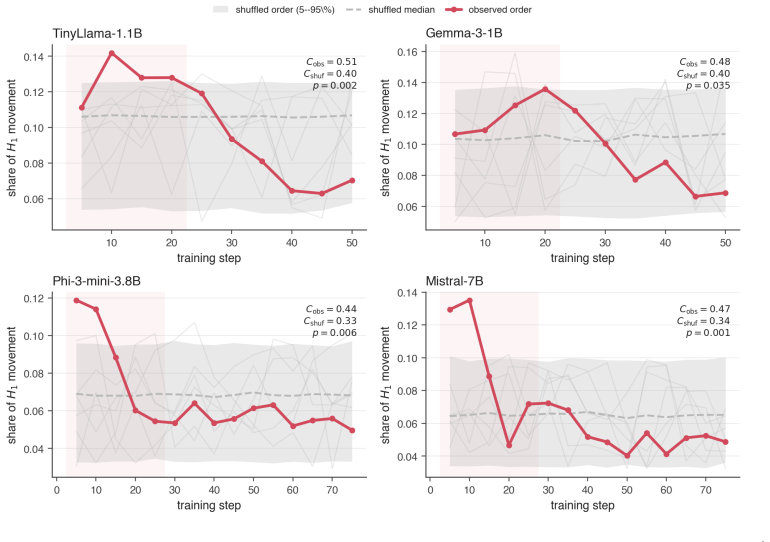
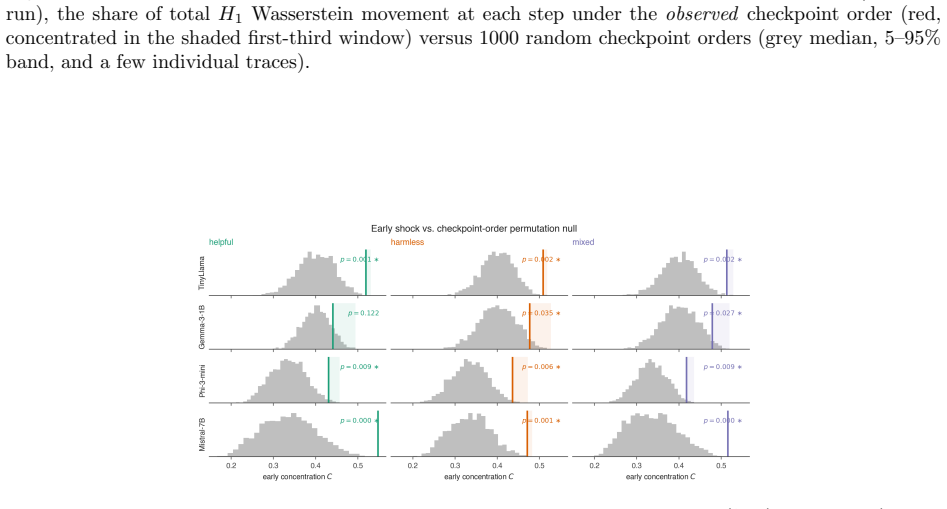
Fine-tuning mildly shortens and thins the bars. 16 Figure 6:Permuting the checkpoint order removes the early peak.For each dense model (harmless run), the share of totalH 1 Wasserstein movement at each step under theobservedcheckpoint order (red, concentrated in the shaded first-third window) versus 1000 random checkpoint orders (grey median, 5–95% band, ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.